Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Considerações de Custo ao Usar um Gateway de IA: Otimizando os Gastos de IA Empresarial
Gerenciar o custo do uso de modelos de linguagem grandes (LLM) tornou-se uma preocupação de missão crítica para empresas que implementam IA em escala. Ao contrário do software tradicional, os serviços baseados em LLM frequentemente usam precificação baseada em tokens – os provedores cobram por token de entrada/saída – o que torna o orçamento difícil de prever ou controlar. Vários fatores contribuem para essa complexidade:
Precificação de modelos diferentes: Cada provedor de LLM (OpenAI, Anthropic, Cohere, etc.) ou tamanho de modelo tem sua própria taxa por token, com modelos maiores (por exemplo, da classe GPT-4) custando significativamente mais por token do que os menores.
Padrões de uso imprevisíveis: O consumo de tokens pode variar drasticamente por usuário, recurso ou fluxo de trabalho – um recurso pode usar silenciosamente 10 vezes mais tokens do que outro, e o uso pode disparar inesperadamente com o comportamento do usuário.
Pipelines de prompt dinâmicos: Casos de uso avançados como Geração Aumentada por Recuperação (RAG), agentes que usam ferramentas ou cadeias de várias etapas podem expandir inadvertidamente o tamanho do prompt e o comprimento da resposta, multiplicando os tokens (e o custo) necessários por consulta.
O resultado é que, sem visibilidade e controles adequados, as equipes frequentemente não percebem a rapidez com que os custos estão se acumulando até que a fatura chegue. Não é incomum que as despesas aumentem inesperadamente, ameaçando orçamentos de projetos e impedindo esforços de escalonamento. Um relatório recente da Gartner também alerta que a falta de visibilidade e governança de custos pode rapidamente levar a estouros de orçamento em iniciativas de IA. Em suma, à medida que as organizações incorporam LLMs em produtos, controlar o custo de uso é tão crítico quanto a precisão do modelo ou o tempo de atividade. A precificação baseada em tokens introduz incerteza que pode afundar o ROI, a menos que seja ativamente gerenciada.
É aqui que o conceito de um Gateway de IA entra em cena. Um Gateway de IA está emergindo como um componente chave para recuperar o controle sobre o uso e os gastos com LLM. Antes de mergulharmos nos impulsionadores de custos e soluções, vamos definir o que é um Gateway de IA e como ele influencia o custo.
O Que É um Gateway de IA? (E Como Ele Afeta o Custo)
Um Gateway de IA é uma camada de middleware especializada que gerencia todas as interações entre suas aplicações e múltiplos modelos ou provedores de IA. Pense nele como um gateway de API construído especificamente para cargas de trabalho de IA — um que compreende as nuances específicas do modelo, como faturamento baseado em tokens, latência de inferência e roteamento dinâmico. Ele fornece um ponto de extremidade unificado para todas as solicitações de IA, direcionando inteligentemente o tráfego para o backend do modelo correto com base em políticas de custo, desempenho ou disponibilidade.
Embora adicionar um gateway introduza uma sobrecarga menor, como custos de hospedagem e esforço de configuração — estes são superados pelo controle e visibilidade que ele oferece. Ao rotear cada solicitação através de uma única camada, as organizações podem monitorar o uso, impor orçamentos e tomar decisões em tempo real sobre qual modelo oferece a melhor relação custo-desempenho. A Gartner descreve os gateways de IA como “controladores de tráfego inteligentes” que ajudam as empresas a avaliar e otimizar o uso de modelos em todas as aplicações.
O Gateway de IA da TrueFoundry funciona como este plano de controle, unificando o acesso entre modelos e provedores enquanto impõe políticas corporativas como controle de acesso, governança de custos, cache e observabilidade. Ele transforma o consumo de IA de uma despesa imprevisível em um sistema gerenciado, mensurável e otimizável.
Principais Fatores de Custo no Uso de LLMs
Ao usar grandes modelos de linguagem em produção, vários fatores-chave determinam o custo operacional total. Compreender esses fatores é o primeiro passo para gerenciar e reduzir os custos relacionados aos LLMs:
Escolha e tamanho do modelo: A escolha do modelo tem um impacto desproporcional no custo. Modelos maiores e mais avançados (com maior número de parâmetros ou mais capacidades) geralmente têm custos por token muito mais altos. Por exemplo, o GPT-4 ou outros modelos de “raciocínio” podem custar uma ordem de magnitude a mais por token do que modelos menores. Usar um modelo de ponta para cada solicitação – incluindo consultas triviais – inflará os custos desnecessariamente.
Uso de tokens (comprimento do prompt e da resposta): O número de tokens enviados nos prompts mais os tokens gerados nas respostas impulsiona diretamente o faturamento. Conversas ou documentos longos, janelas de contexto extralongas ou prompts não otimizados que incluem informações irrelevantes, tudo isso aumenta a contagem de tokens. Recursos como pedir ao modelo para ser prolixo ou retornar explicações extensas podem aumentar exponencialmente o uso. Uma engenharia de prompt eficaz para manter os prompts sucintos e as saídas focadas pode reduzir significativamente os custos. Cada token importa quando você está pagando frações de centavo por token milhões de vezes.
Volume e padrões de tráfego: A frequência e a amplitude com que os recursos de IA são usados obviamente afetarão o custo – mas não é apenas o volume total, é o padrão. Tráfego irregular e imprevisível pode gerar custos durante o pico de uso que estouram o orçamento mensal. A variabilidade entre usuários ou recursos significa que alguns usuários avançados ou uma ferramenta interna podem estar consumindo secretamente a maioria dos tokens. Picos repentinos de uso (por exemplo, um novo recurso se tornando viral) podem levar a contas não planejadas se não forem controlados. Aumentar o uso sem aumentar a supervisão de custos é uma receita para estouros de orçamento.
Uso de múltiplos modelos e seleção de provedores: Muitas equipes usam uma combinação de modelos – por exemplo, um modelo de código aberto para algumas tarefas e uma API proprietária para outras, ou diferentes provedores para diferentes idiomas. Cada modelo/provedor pode ter diferentes unidades de precificação (alguns cobram por 1000 tokens, outros por solicitação, etc.) e, possivelmente, taxas adicionais. Além disso, se uma equipe sempre opta pelo modelo mais caro “para garantir”, ela perde oportunidades de economizar. Selecionar o modelo certo para cada tarefa é uma grande alavanca de custo: uma consulta simples não precisa de um modelo caro de 175 bilhões de parâmetros quando um modelo menor (e mais barato) seria suficiente. Por outro lado, algumas tarefas complexas podem justificar o custo de um modelo superior. A estratégia (ou a falta dela) no roteamento de tráfego para os modelos é um grande fator de custo.
Infraestrutura e custos indiretos: Há também custos além das taxas por token. Se você hospeda LLMs de código aberto por conta própria para evitar custos de API, você paga em infraestrutura – servidores GPU, memória, manutenção e esforço de MLOps. Como uma análise sucintamente colocou, “LLMs de código aberto não são gratuitos — eles apenas transferem a conta do licenciamento para engenharia, infraestrutura, manutenção e risco estratégico.” Mesmo usando APIs de nuvem, você pode precisar de infraestrutura adicional para lidar com as solicitações (por exemplo, executar um serviço interno ou gateway, bancos de dados vetoriais para RAG, etc.), o que incorre em custos de computação em nuvem. A sobrecarga de integração e o tempo de engenharia são custos “ocultos” que podem surgir sorrateiramente.
Taxas de licença ou assinatura: Alguns modelos e serviços implicam taxas fixas além do uso. Por exemplo, certas APIs de IA empresariais exigem uma assinatura mensal ou compromisso. Mesmo modelos de código aberto podem ter restrições de licenciamento que levam as empresas a opções pagas. Se você adota uma plataforma proprietária de fornecimento de modelos, pode haver custos de licença. Essas taxas precisam ser consideradas no custo total de propriedade para usar um determinado modelo – às vezes, um modelo “mais barato por token” pode exigir uma licença cara, anulando as economias.
Custos de integração e ineficiência: Finalmente, a forma como você integra a IA em seus sistemas pode criar ineficiências de custo. Chamadas redundantes, falta de cache ou má gestão de carga podem desperdiçar tokens. Os primeiros adotantes empresariais descobriram que o uso de um gateway de API padrão ou integração ad-hoc levou a significativos estouros de custo – em alguns casos, 300% acima das projeções iniciais – porque as ferramentas não consideravam otimizações específicas de IA, como cache de prompts semelhantes ou balanceamento de carga entre modelos. Há um custo para construir e manter sua própria infraestrutura para acesso e monitoramento multimodelos. Se cada equipe chama APIs de IA independentemente, você perde economias de escala e supervisão centralizada, muitas vezes levando a gastos agregados mais altos do que o necessário (por exemplo, várias equipes acessando o mesmo modelo com a mesma solicitação e pagando duas vezes).
Compreender esses fatores de custo destaca por que simplesmente dar acesso às equipes a uma API de LLM não é suficiente – o uso não gerenciado em muitos aplicativos e usuários quase inevitavelmente levará a surpresas. Quanto mais crítica para a missão e generalizada for o uso da IA, maior a necessidade de governança.É aqui que os Gateways de IA provam seu valor: eles visam diretamente esses fatores de custo, fornecendo mecanismos para controlar os custos sem sacrificar o desempenho ou a confiabilidade.
Gerenciando e Reduzindo Custos de LLM com um Gateway de IA
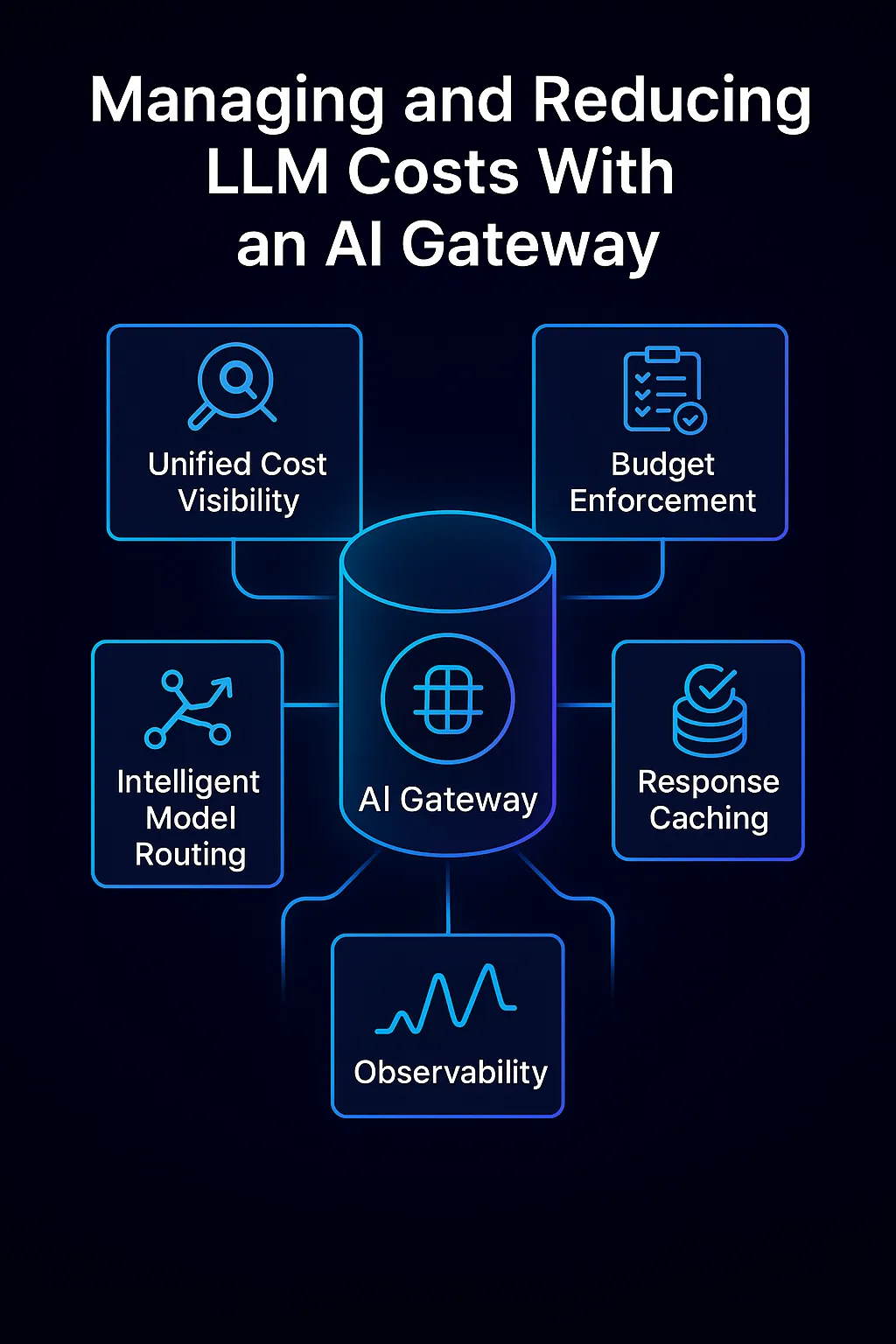
Um Gateway de IA oferece um conjunto de ferramentas e estratégias inteligentes para abordar os fatores de custo mencionados acima. Ele serve como uma camada central de governança de custos para todo o uso de IA. De acordo com o Gartner, os gateways de IA podem mitigar o risco de “custos de IA em espiral devido à má governança” ao atuar como um ponto de controle entre consumidores e provedores de IA. O AI Gateway da TrueFoundry, por exemplo, incorpora inúmeras funcionalidades para monitorar e otimizar custos. Vamos aprofundar em como um gateway de IA ajuda a gerenciar e reduzir os custos de LLM:
Visibilidade unificada de custos: Todas as solicitações passam pelo gateway, o que registra métricas detalhadas de uso para cada chamada – modelo utilizado, tokens consumidos, latência, atribuição de usuário/equipe, etc. Isso proporciona visibilidade granular e em tempo real sobre para onde seus gastos com tokens estão indo. Os líderes podem finalmente responder com precisão à pergunta "quais aplicações ou casos de uso estão gerando a maior parte da nossa fatura OpenAI?". Essa visibilidade entre aplicações é quase impossível de obter quando as equipes chamam os modelos diretamente. Com um gateway, você obtém uma fonte única de verdade painel para uso e gastos com IA. Essa transparência permite a contabilidade de chargeback/showback (alocação de custos aos departamentos), o que, por sua vez, impulsiona a responsabilização.
Aplicação de orçamento e salvaguardas: A visibilidade por si só não é suficiente – o gateway também aplica políticas para evitar uso descontrolado. Você pode definir limites de taxa e cotas (por exemplo, não mais que N tokens ou $X de gasto por dia para um determinado usuário ou recurso) e o gateway rejeitará ou limitará as solicitações que excederem esses limites. Isso garante que um script com mau funcionamento ou um pico de uso inesperado não estoure o orçamento. Você também pode configurar alertas de orçamento ou desligamento automático regras: se o uso mensal de uma equipe exceder um limite, o gateway pode enviar notificações ou cortar temporariamente chamadas adicionais até que sejam aprovadas, evitando faturas inesperadas. Além disso, os gateways permitem controle de acesso e restrições de modelo – por exemplo, você pode permitir que modelos caros como o GPT-4 sejam usados apenas por certos fluxos de trabalho críticos, enquanto usos menos críticos são restritos a modelos mais baratos. Outra forma de salvaguarda é a filtragem de prompts: bloqueando prompts que gerariam saídas extremamente longas ou solicitações ineficientes em termos de custo. Ao aplicar essas regras de governança centralmente, as organizações criam limites rígidos para a exposição a custos.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Roteamento inteligente de modelos: Talvez o maior economizador de custos seja a capacidade do gateway de rotear dinamicamente cada solicitação para o modelo ou provedor ideal com base no contexto. Em vez de uma abordagem única para todos, o gateway pode avaliar fatores como a complexidade da consulta, a precisão necessária, a latência e o custo, e então escolher (ou até mesmo alternar automaticamente) o modelo que melhor atende às necessidades com o menor custo. Por exemplo, uma pergunta factual simples pode ser respondida por um modelo menor e mais barato, sem diferença perceptível na qualidade, enquanto uma tarefa complexa é enviada para um modelo mais poderoso. Esse tipo de seleção de modelo em tempo real reduz custos ao evitar o excesso. O AI Gateway da TrueFoundry implementa isso através de regras de roteamento inteligentes e balanceamento de carga: você pode configurá-lo de forma que, por padrão, as consultas vão para um modelo de código aberto como o Mistral para velocidade e baixo custo, mas se o prompt parecer complexo ou se a confiança do modelo menor for baixa, o gateway roteia essa solicitação para um modelo maior como o GPT-4. Ao longo de centenas de milhares de solicitações, esse roteamento adaptativo pode gerar economias massivas, mantendo a qualidade geral. Ele supera a falsa dicotomia de escolher entre um modelo de alto desempenho ou de baixo custo – você pode ter ambos usando cada um onde faz sentido.
Cache de respostas: Outra otimização de custo é o cache de respostas de IA repetidas ou comuns. Se vários usuários fizerem a mesma pergunta ou seu sistema fizer consultas idênticas repetidamente, um gateway de IA pode retornar uma resposta em cache em vez de chamar o modelo novamente, economizando esses tokens inteiramente. Mesmo o cache de resultados parciais (como etapas intermediárias caras) pode ajudar. Isso é especialmente útil para tarefas de backend ou aplicativos onde o mesmo prompt é usado com frequência. O cache não apenas reduz o custo, mas também melhora a latência para essas consultas. O gateway da TrueFoundry suporta tanto o cache direto quanto o mais avançado cache semântico – onde prompts semanticamente semelhantes podem ser tratados como acertos de cache. (O cache semântico deve ser usado com cuidado, pois diferenças sutis nos prompts podem mudar a resposta, mas nos cenários certos ele pode aumentar as taxas de acerto de cache e reduzir o custo.) Estudos mostraram que mecanismos de cache semântico podem reduzir os custos da API LLM em até 70% em casos de uso empresarial. Na prática, mesmo um cache mais simples para solicitações idênticas oferece uma margem de custo significativa para aplicativos de alto volume
Observabilidade e detecção de anomalias: Como o gateway monitora todas as solicitações, ele também pode detectar padrões de uso anômalos que podem indicar um bug ou abuso. Por exemplo, se esta hora mostrar 5 vezes o uso de tokens da última, ou se um aplicativo de repente começar a enviar prompts grandes para o modelo, o gateway (e seus painéis integrados) irá evidenciar essa anomalia. A detecção precoce significa que você pode intervir antes que o orçamento se esgote. A observabilidade também contribui para a confiabilidade: ela rastreia taxas de erro e latências, ajudando a diferenciar desacelerações relacionadas a custos de problemas do modelo. Alguns gateways, como o da TrueFoundry, se integram a ferramentas como o OpenTelemetry para que você possa mesclar métricas de uso de LLM com sua pilha de monitoramento geral. Essa observabilidade holística garante que você mantenha o custo e metas de desempenho. Também permite o rateio interno de custos – uma vez que a utilização é registrada centralmente, você pode responsabilizar as equipes pela sua parte da fatura de IA, incentivando-as a serem eficientes.
Como um Gateway de IA gerencia e reduz os custos de LLM, combinando visibilidade unificada, controle orçamentário, roteamento inteligente de modelos, cache e observabilidade em uma única camada de controle.
Todas essas capacidades se combinam para garantir a disciplina de custos sem supervisão manual constante. Ao usar um gateway de IA, o gerenciamento de custos torna-se proativo e automatizado: você tem limites em vigor para que não possa gastar em excesso, você tem informações em tempo real para ajustar padrões de uso, e você tem otimizações automatizadas (roteamento, cache) eliminando ineficiências em tempo real. Transforma o que poderia ser um centro de custo opaco e descontrolado em um serviço gerenciado.
O Gateway de IA da TrueFoundry exemplifica esses controles de custo na prática. Ele inclui painéis de acompanhamento de custos, configuração de políticas orçamentárias, roteamento multi-modelo regras e mecanismos de cache, tudo configurável através de uma interface amigável para empresas. O resultado é que as empresas podem adotar mais casos de uso de IA sem o medo de faturas imprevisíveis. Claro, empregar tal gateway introduz algumas considerações sobre desempenho e arquitetura, que discutiremos a seguir.
Equilibrando Custo, Precisão, Latência e Complexidade
Qualquer estratégia para reduzir custos agressivamente deve ser equilibrada com outros requisitos técnicos e de negócio. Compensações são inevitáveis. No contexto de implementações de LLMs, as dimensões chave a equilibrar são custo, precisão (ou qualidade dos resultados), latência (velocidade de resposta) e complexidade arquitetural. Um gateway de IA ajuda a gerenciar essas compensações, mas compreendê-las é importante para definir as políticas corretas:
Custo vs. Precisão: Modelos de maior qualidade geralmente significam custos mais altos, mas nem toda tarefa exige um raciocínio de nível GPT-4. Um modelo menor de 7B pode responder “Qual é a capital da França?” com a mesma precisão que um modelo carro-chefe, mas não uma questão legal complexa. A chave é usar a inteligência de roteamento do gateway para decidir quando a precisão premium vale o preço. Encaminhe tarefas diárias para modelos menores e reserve modelos de ponta para raciocínio complexo. Com o tempo, a análise de dados ajuda a refinar esses limites, atingindo o equilíbrio entre precisão aceitável e economias de custo substanciais.
Custo vs. Latência: Modelos mais baratos geralmente também entregam respostas mais rápidas, especialmente quando hospedados localmente. No entanto, o roteamento ingênuo de múltiplos modelos pode introduzir latência se o sistema tentar um modelo e depois recorrer a outro. O Gateway da TrueFoundry mitiga isso com roteamento baseado em latência e ciente da carga, garantindo que as requisições fluam para o modelo viável mais rápido sem saltos desnecessários. Sua arquitetura adiciona apenas alguns milissegundos de sobrecarga (~3–4 ms por requisição) — negligenciável em comparação com os tempos de inferência do modelo, assim as equipes ganham eficiência sem comprometer a experiência do usuário.
Custo vs. Complexidade Arquitetural: Adicionar um Gateway de IA introduz uma camada extra de infraestrutura, mas também oferece visibilidade, barreiras de proteção e confiabilidade que as configurações de modelo único não possuem. Para pequenas equipes ou protótipos, chamadas diretas ao modelo podem ser suficientes. Mas à medida que o uso escala, roteamento centralizado, cache e governança de custos tornam-se essenciais.
Em última análise, equilibrar esses fatores é um exercício contínuo. A melhor prática é monitorar continuamente o impacto das suas medidas de economia de custos na qualidade da saída do modelo e na experiência do usuário (o que a observabilidade do gateway ajuda a fazer), e ajustar os "botões" (regras de roteamento, configurações de cache, etc.) de acordo. A beleza da abordagem do gateway de IA é que você tem esses botões para girar – você não está preso a um uso de modelo de tamanho único. Você pode aumentar ou diminuir os gastos em certas áreas enquanto preserva o que mais importa para sua aplicação, seja o tempo de resposta ou a precisão da resposta.
Melhores Práticas para Otimização de Custos de LLM Usando um Gateway
Para obter o máximo benefício de um gateway de IA, as organizações devem combinar a tecnologia com estratégias de uso sólidas. Aqui estão algumas melhores práticas práticas para otimizar os custos de LLM enquanto mantém o desempenho:
1. Otimize prompts e saídas. Remova tokens desnecessários e mantenha os prompts focados. Instruções excessivamente longas ou verbosas desperdiçam tokens. Formatos estruturados — como listas de marcadores ou esquemas JSON — mantêm as respostas concisas e previsíveis. Revise e encurte os prompts de contexto comuns que são adicionados a cada chamada. Esta otimização de "custo zero" reduz diretamente os gastos.
2. Usar roteamento de modelo híbrido. Adote uma estratégia de modelos em camadas: direcione consultas simples ou de baixo risco para modelos menores e mais baratos, e as complexas para modelos premium. Muitas equipes seguem um padrão 90/10 — 90% do tráfego para modelos rápidos e de baixo custo; 10% para modelos de alta qualidade para tarefas críticas. O Gateway da TrueFoundry automatiza isso através de roteamento baseado em regras ou em ML, garantindo que você nunca pague a mais por uma capacidade que não precisa.
3. Agrupar e paralelizar chamadas. Ao pagar por token ou por chamada, minimize a sobrecarga agrupando múltiplos prompts em uma única requisição. A API de inferência em lote da TrueFoundry permite agrupar tarefas relacionadas — ideal para trabalhos periódicos como resumir grandes conjuntos de documentos. Em alguns casos, requisições paralelas podem ser enviadas para modelos baratos e caros, cancelando o mais caro se o primeiro retornar um resultado satisfatório.
4. Armazenar em cache consultas de alta frequência. Reutilize resultados em vez de recalculá-los. O Gateway suporta cache de correspondência exata e semântico, onde prompts semelhantes podem reutilizar respostas anteriores. Mesmo taxas de acerto de cache modestas podem economizar um gasto significativo de tokens, ao mesmo tempo em que melhoram a latência — uma grande vantagem para fluxos de trabalho repetidos ou consultas comuns.
5. Ajustar ou especializar modelos. Para tarefas repetitivas e específicas de domínio, o ajuste fino de um modelo menor ou a integração de RAG (geração aumentada por recuperação) pode encurtar prompts e reduzir tokens. A plataforma da TrueFoundry suporta ajuste fino e implantação personalizada, ajudando as equipes a equilibrar precisão e eficiência em escala.
6. Aproveitar modelos de código aberto ou auto-hospedados. Em grandes volumes, pode ser mais barato hospedar modelos de peso aberto em GPUs dedicadas do que pagar por chamada de API. O Gateway permite uma implantação híbrida contínua — roteando parte do tráfego para modelos auto-hospedados, mantendo o registro unificado e os controles de política. Essa configuração híbrida pode gerar economias de custo substanciais, preservando a flexibilidade.
Além dessas práticas, sempre
monitore e itere
. Use os dados do gateway para ver quais estratégias estão tendo o maior impacto (por exemplo, taxas de acerto de cache, tokens economizados por roteamento, etc.) e ajuste-se de acordo. A otimização de custos não é uma tarefa única de "configurar e esquecer", mas o gateway oferece as ferramentas para torná-la um esforço contínuo e gerenciável, em vez de uma surpresa de "apagar incêndios".
A Abordagem da TrueFoundry para Rastreamento de Custos e Governança
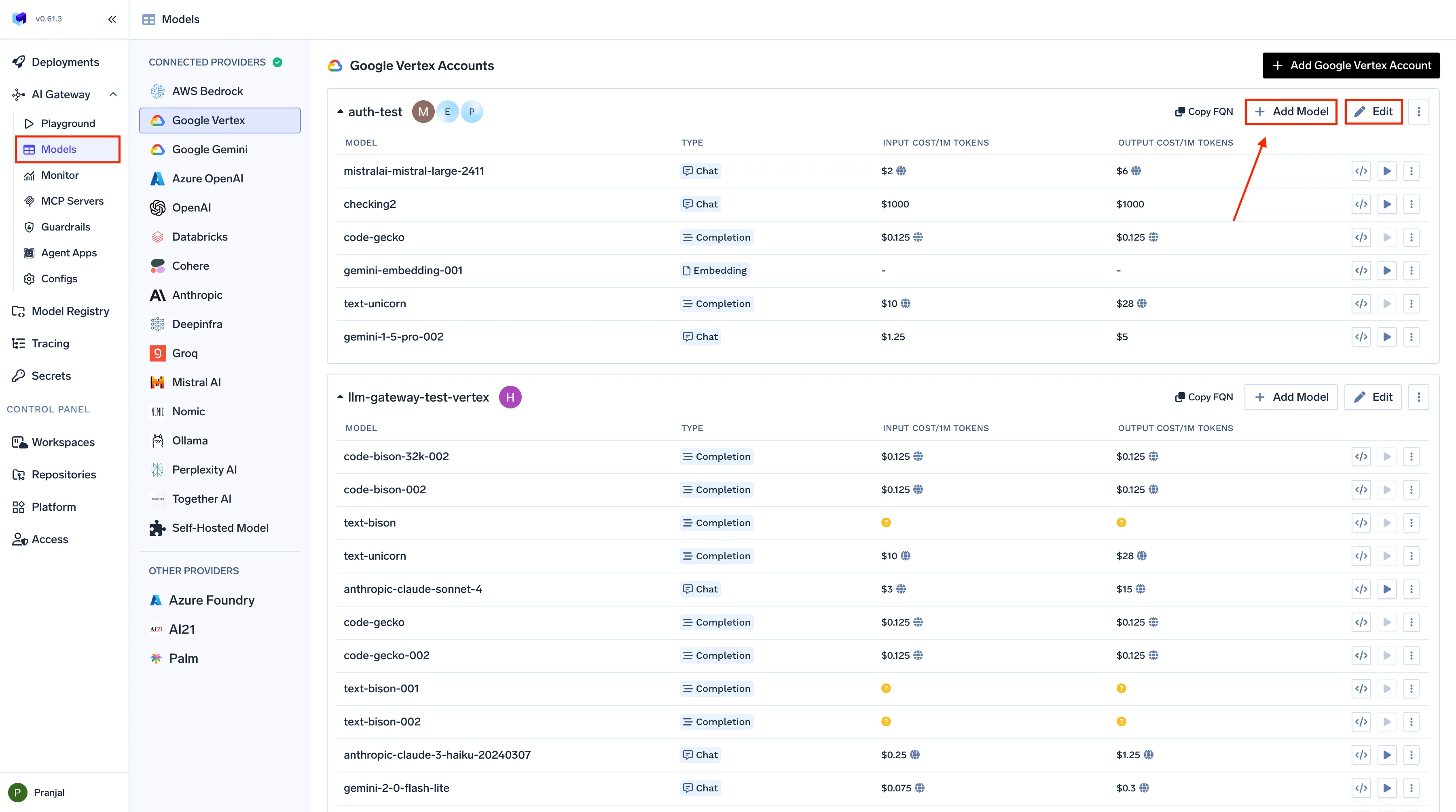
Embora a otimização de custos seja um desafio universal em todas as implantações de LLM, o AI Gateway da TrueFoundry o transforma em um processo estruturado, mensurável e contínuo. Em vez de depender de orçamentos manuais ou relatórios de custos dispersos, a TrueFoundry incorpora a governança diretamente na camada de infraestrutura — garantindo que cada interação de IA seja registrada, precificada e atribuída em tempo real. Esta infraestrutura unificada permite uma solução estruturada de rastreamento de custos de LLM, permitindo que as empresas monitorem os gastos ao nível do modelo, da equipa e do fluxo de trabalho com total transparência.
Interface de Configuração de Custos de Modelo da TrueFoundry
1. Atribuição de Custos em Tempo Real
Cada pedido que passa pelo Gateway da TrueFoundry é automaticamente etiquetado e precificado. O sistema combina contagens de tokens de entrada/saída com dados de preços específicos do modelo, seja de APIs públicas ou de taxas negociadas pela empresa — para calcular o custo exato por inferência. As equipas podem filtrar estas métricas por modelo, equipa, ambiente ou utilizador, dando visibilidade precisa sobre quem ou o que impulsiona os gastos. Isso simplifica a alocação de custos, a execução de estornos internos ou a justificação do ROI para funcionalidades de IA.
2. Preços e Orçamentos de Modelo Configuráveis
A TrueFoundry permite que as empresas definam preços personalizados por modelo, alinhando o acompanhamento interno com contratos reais de fornecedores ou custos de computação auto-hospedados. Os administradores também podem criar limites orçamentais ou quotas para cada aplicação ou ambiente. Quando os gastos excedem um limite definido, o Gateway pode acionar alertas automáticos ou até mesmo impor uma limitação temporária, garantindo a contenção de custos sem intervenção manual.
3. Observabilidade Integrada
TrueFoundry exporta dados de custo e uso para Prometheus e OpenTelemetry, integrando-se perfeitamente com os pipelines de monitoramento existentes. Isso permite que as métricas de custo, latência e confiabilidade da IA apareçam nos mesmos painéis usados para monitoramento de infraestrutura e aplicativos. O resultado é um painel único de controle onde as equipes de engenharia, finanças e produto compartilham uma visão unificada de desempenho e gastos.
4. Governança por Design
Como cada chamada inclui marcação de metadados (equipe, projeto e ambiente), as organizações podem implementar responsabilidade estruturada entre os departamentos. Combinado com controle de acesso baseado em função (RBAC) e permissões em nível de modelo, isso garante que modelos de alto custo ou alto risco sejam acessíveis apenas a equipes aprovadas. Essas salvaguardas tornam a conformidade, a disciplina orçamentária e a transparência automáticas — não manuais.
Quando um Gateway de IA Pode Não Ser Justificado
Gateways de IA entregam um valor imenso em escala, mas nem toda organização precisa de um imediatamente. Para equipes pequenas ou projetos em estágio inicial que usam um único modelo e baixos volumes de requisições, implantar um gateway completo pode ser uma sobrecarga desnecessária. Um protótipo que chama um modelo OpenAI com alguns milhares de tokens por dia pode ser facilmente gerenciado com chamadas diretas de API e monitoramento básico.
A orientação da indústria sugere que, quando o uso é limitado (dezenas de milhares de tokens por mês) e as necessidades de conformidade ou confiabilidade são mínimas, um proxy leve ou rastreamento manual pode ser suficiente. A verdadeira vantagem do gateway surge à medida que as cargas de trabalho escalam ou se diversificam entre modelos e provedores. Se sua organização ainda está experimentando LLMs ou tem infraestrutura mínima, concentre-se primeiro na iteração, mas planeje com antecedência. O Gateway da TrueFoundry, por exemplo, pode ser dimensionado de forma eficiente, oferecendo visibilidade e governança precoces sem uma configuração pesada. Em resumo, avalie sua maturidade e escala de IA: para casos de uso de modelo único e baixo volume, um gateway pode ser prematuro; à medida que a adoção cresce, ele rapidamente se torna essencial para controle de custos, confiabilidade e governança de longo prazo.
Conclusão
Controlar os custos de LLM em ambientes empresariais é complexo, mas os Gateways de IA são construídos para resolver exatamente isso. Em vez de deixar os custos ao acaso, um gateway como o da TrueFoundry incorpora a governança de custos diretamente na sua arquitetura de IA. Através de rastreamento centralizado, limites orçamentários, roteamento inteligente e cache, ele transforma o controle de custos em uma capacidade integrada, em vez de uma reflexão tardia.
Empresas que utilizam gateways de IA relatam reduções de 40–60% nos custos de inferência, juntamente com maior confiabilidade e segurança. O Gateway da TrueFoundry, em particular, oferece responsabilidade desde a concepção — dando às equipes visibilidade detalhada, atribuição de custos e estornos — e redução de riscos em escala através de limites automatizados e mecanismos de segurança. Ele também oferece total transparência nos padrões de uso para que nenhum problema de custo ou latência passe despercebido.
Ao unificar políticas entre regiões e equipes, o Gateway garante governança e conformidade consistentes — essencial para indústrias que lidam com dados sensíveis. O resultado: projetos de IA passam da experimentação para a produção com gastos previsíveis e confiança operacional.
Em resumo, os Gateways de IA tornam a adoção de LLM sustentável. A precificação baseada em tokens pode ser imprevisível, mas com o plano de controle centralizado da TrueFoundry, as empresas podem otimizar gastos, impor limites e escalar de forma responsável. É assim que a inovação e a disciplina fiscal coexistem — transformando a IA em uma capacidade governada, eficiente e pronta para empresas.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




.webp)



























.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




