














November 5, 2025
|
5 min read

Published: May 19, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
As enterprises push generative AI and large language models (LLMs) into production, managing costs becomes mission-critical. Token-based pricing, common with LLM providers, brings unique complexity:
Without a dedicated LLM cost tracking solution, teams lack visibility until costs balloon unexpectedly. This threatens budgets and impedes scaling efforts.
Here’s how to approach end-to-end tracking, governance, and optimization—along with direct, natural links to TrueFoundry documentation for each core element.
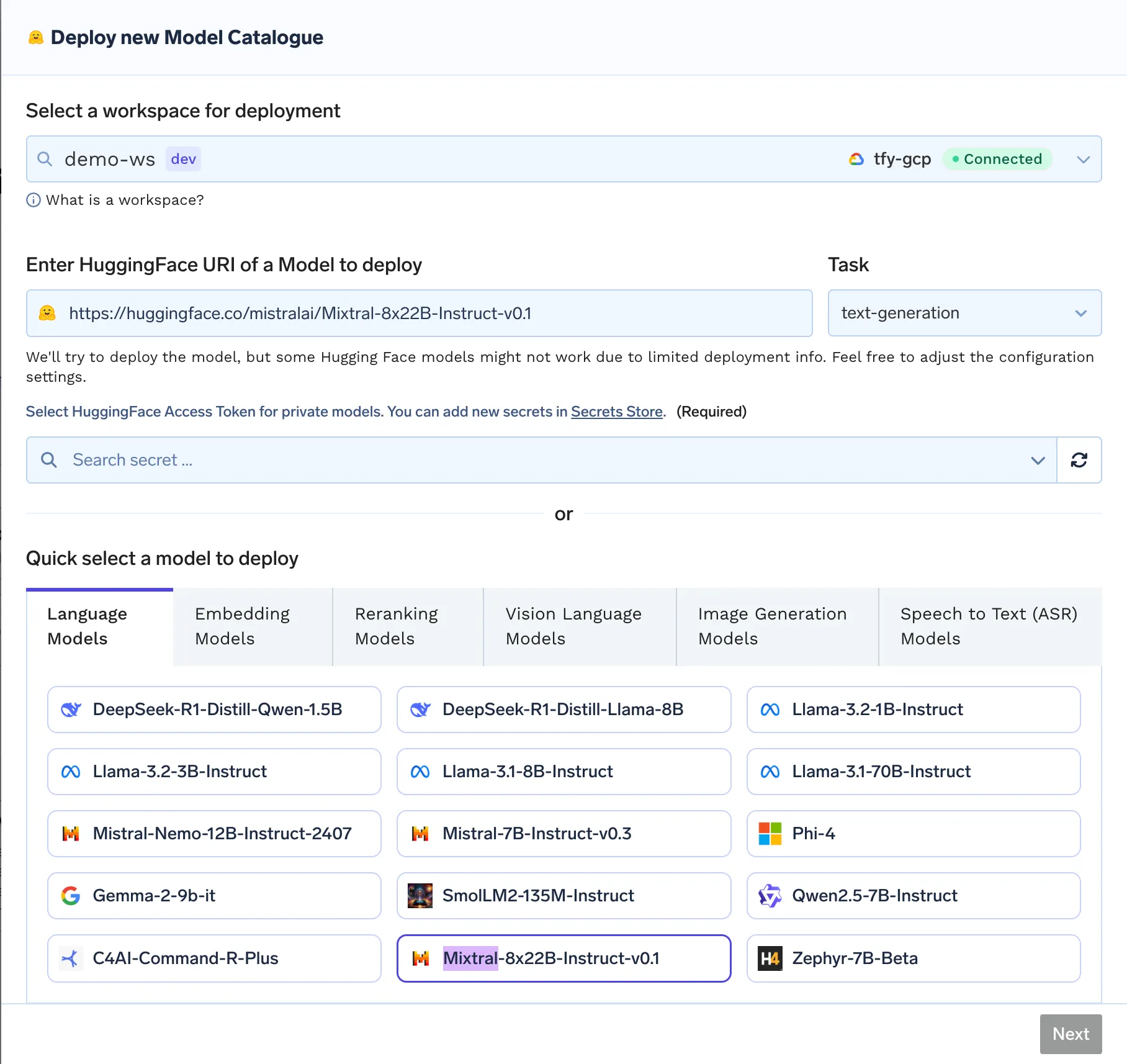
Building robust cost tracking starts by capturing comprehensive, structured data for every LLM request. Using the TrueFoundry AI Gateway, you can route all inference traffic, whether it’s to an API model (like OpenAI, Claude, or Mistral) or to a self-hosted model you operate. This gateway acts as your “single pane of glass” for observability and cost attribution.
With every request, you should:
A comprehensive LLM cost tracking solution must let you enforce boundaries before budgets are exceeded.
Together, these governance capabilities turn logging into a live, enforceable cost tracking solution that prevents overruns by design—not just by retroactive reporting.
After observability and governance, optimization is the ongoing process of reducing spend without sacrificing performance or quality.
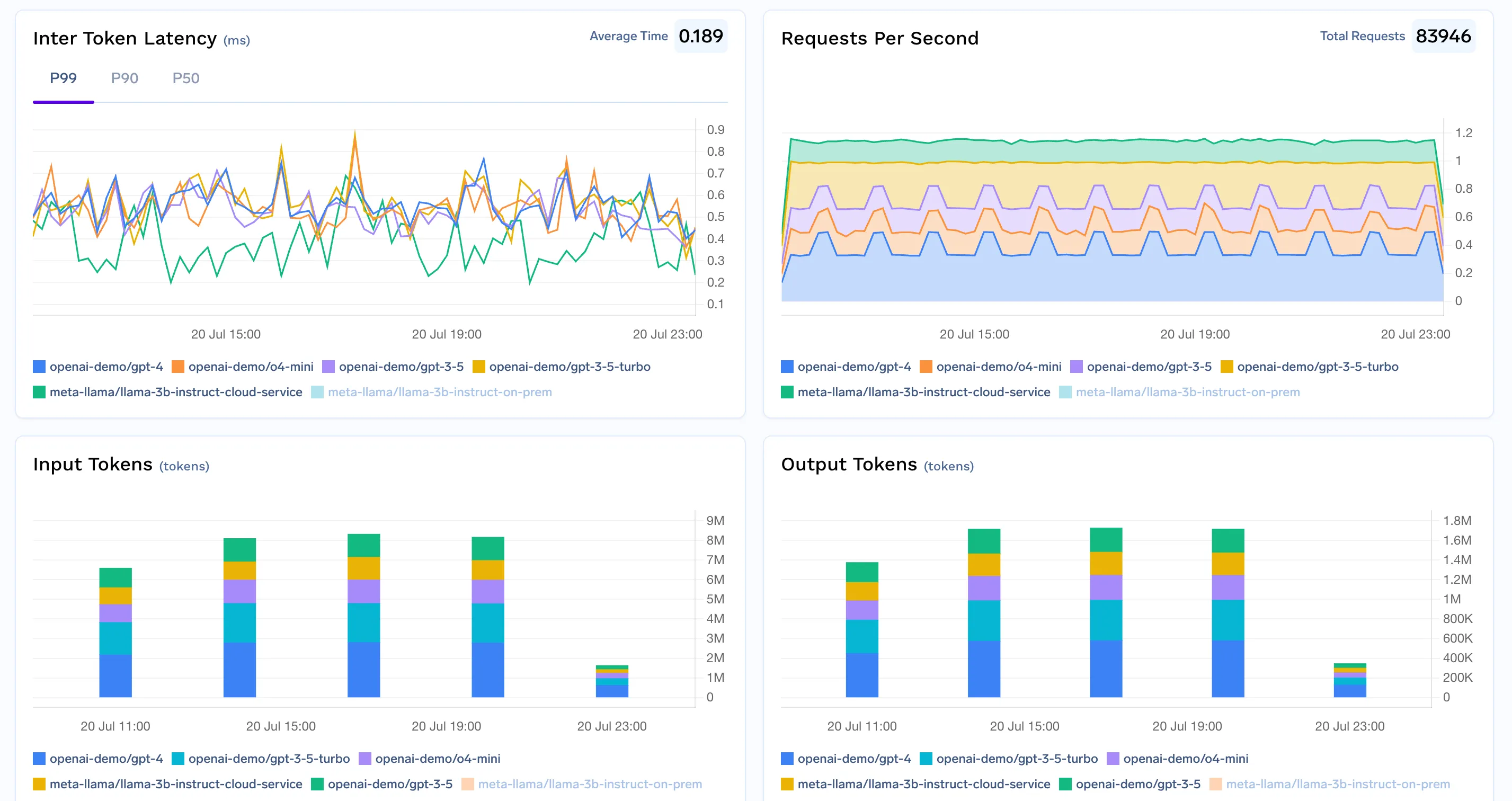
Successful cost optimization relies on vigilant measurement. The following are vital to track across your stack:
A modern LLM cost tracking solution is more than just after-the-fact reporting—it’s a strategic control plane for every phase of AI deployment, from daily governance to ongoing optimization. By leveraging the comprehensive features offered by TrueFoundry’s AI Gateway, teams unlock granular visibility, proactive spend controls, and cost-conscious routing for every LLM they use, whether via API or self-hosted clusters.
For a step-by-step technical deep dive, see:
An LLM cost tracking solution is a strategic control plane designed to monitor, manage, and optimize the unique expenses associated with Large Language Model operations. Unlike traditional cloud infrastructure, it specifically tracks token-based pricing, variable inference loads, and compute-intensive resources. These platforms provide real-time visibility into spending across multiple providers, models, and teams.
Tracking LLM usage costs is critical because AI infrastructure expenses can grow exponentially and silently due to consumption-based token pricing. Without granular monitoring, organizations face massive budget overruns, unpredictable monthly billing, and a lack of financial accountability. Effective tracking ensures sustainable growth by tying every dollar spent back to measurable business value and ROI.
There are several specialized tools and platforms that currently lead the market in managing and tracking LLM costs. TrueFoundry offers a unified AI Gateway for multi-model spend management and governance. Other prominent solutions include LiteLLM, which provides a lightweight proxy for real-time spend visibility, and Portkey, which focuses on detailed cost attribution for generative AI applications.
Yes, most advanced LLMOps platforms natively integrate an LLM cost tracking solution to manage the full model lifecycle. Platforms like TrueFoundry and Weights & Biases capture detailed telemetry data across production environments, displaying token costs alongside performance metrics. This native integration allows developers to optimize both accuracy and financial efficiency within a single, unified workflow.
LLM cost tracking solutions use real-time monitoring to trigger automated notifications via email, Slack, or webhooks when usage hits predefined percentages of a budget. These systems can be configured with automated enforcement rules that throttle traffic or block requests once a hard cap is reached. This proactive alerting prevents "runaway" workloads and ensures financial guardrails remain in place.
TrueFoundry is an ideal LLM cost tracking solution because it combines real-time cost attribution with deep metadata-driven context. It allows enterprises to define custom pricing per model and set granular budget thresholds for specific teams, projects, or environments. Its AI Gateway further optimizes spend through smart routing, semantic caching, and automatic model fallbacks, ensuring high performance at the lowest possible price point.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox










.png)

.webp)
.webp)
.webp)



.webp)
.webp)


