July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 12, 2026

Blazingly fast way to build, track and deploy your models!
Arthur AI integration with Truefoundry AI Gateway
Every team shipping an LLM application runs into the same wall. Developers want to move fast and connect to whatever model gets the job done. Security and risk teams want assurance that nothing toxic, manipulated, or hallucinated slips through to a user. Both are right. The hard part is doing both at once, across every model your teams are using, without bolting a different SDK onto every app. The big question: how do you validate every prompt and every response your AI produces without turning safety into an engineering project?
We are excited to announce that Arthur AI now integrates with the TrueFoundry AI Gateway. By bringing the Arthur Engine to the Gateway as a custom guardrail, you can validate AI inputs and outputs in real time across all your models from one place, with consistent policy and a single integration.
The Power of the TrueFoundry AI Gateway
The TrueFoundry AI Gateway is how developers and platform teams manage, monitor, and scale their AI applications. It brings unified access to hundreds of large language models, deep observability, and smart routing together in one layer. As AI adoption grows, the real challenge stops being access to models and becomes managing everything that comes after: multiple providers, shifting APIs, and strict compliance requirements that can quietly slow teams to a crawl.
The Gateway brings order to that complexity. It acts as the command center for enterprise AI, unifying access, enforcing security policy, and giving full visibility into every model and environment. Guardrails plug into this layer once and apply everywhere, so a safety decision made in the dashboard is enforced on every request that flows through.
Arthur AI: Real-Time Validation
Arthur AI sits between your application and your models as a validation layer. The ArthurEngine inspects prompts and completions in real time and returns a clear verdict on whether they are safe to proceed.
Out of the box, Arthur checks for the risks that matter most in production. It detects prompt injection, where an attacker crafts input designed to hijack the model and pull it off its instructions. It flags toxic content on both the way in and the way out, so harmful language never reaches your model or your users. And it runs hallucination checks against grounding context you supply, catching responses that drift from the facts before they are trusted as answers.
One important detail shapes how Arthur fits in: it is validate-only. It tells you, fast and statelessly, whether something passed or failed. It reports problems rather than silently rewriting text, which keeps its behavior predictable and easy to audit.
Better Together: One Contract, Every Model
The integration connects Arthur to TrueFoundry through a lightweight deployable wrapper and the Gateway's Custom Guardrail contract. You deploy a small FastAPI service, point the Gateway at it, and register two guardrail configs in the dashboard: one for input, one for output. From that moment, any model behind the Gateway can be validated by Arthur with no per-app code changes.
That is the real payoff. Instead of wiring Arthur into every application by hand, you attach it once at the Gateway. Pin it to a model so every caller is protected, or opt in per request with a single header when you only want it on specific calls. The same policy travels with every team, model, and environment, and every verdict is captured alongside TrueFoundry's request tracking for a clean audit trail.
How the Arthur AI and TrueFoundry Integration Works
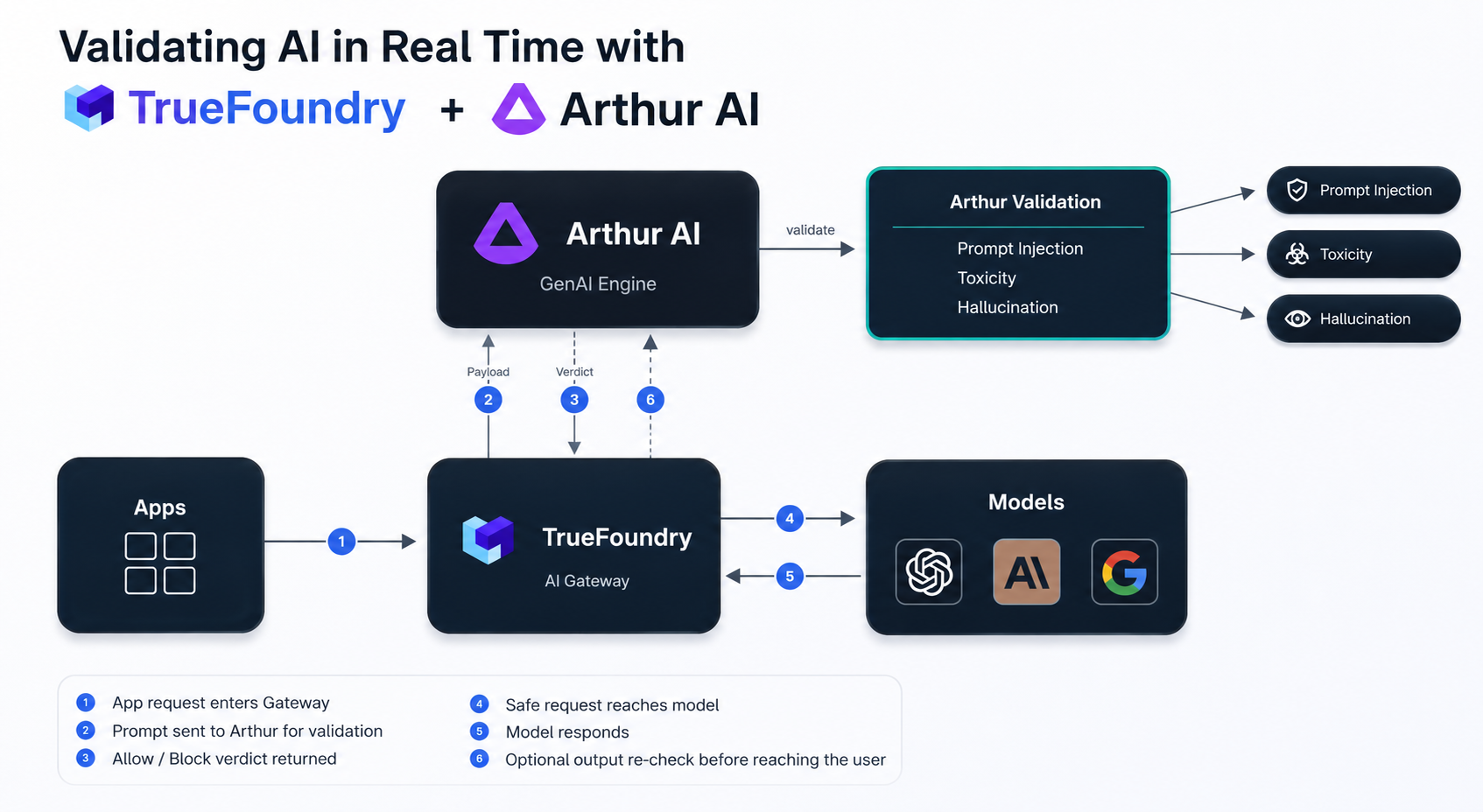
The integration introduces a layered validation flow that is easy to follow:
A subtle but important design choice makes this robust: policy decisions ride on a normal HTTP 200 with a verdict field, while genuine infrastructure failures surface as 5xx errors. With the recommended Enforce But Ignore On Error strategy, a transient outage passes traffic through, but a real policy block always stops the request. For safety-critical rails, you can switch to strict enforcement and fail closed instead.
Get Started
Securing your AI should not feel like a rebuild. With Arthur AI on the TrueFoundry AI Gateway, real-time validation is closer to flipping a switch than a wiring project: deploy the wrapper, add two guardrail configs, attach them to your models, and you are validating prompts and responses across your stack.
To see exactly how it works, head to the Arthur AI integration guide in the TrueFoundry docs, where the full setup, response contract, and custom check configuration are laid out step by step.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada




.webp)