Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Mapeando o Mercado de IA On-Prem: De Chips a Planos de Controle
À medida que as empresas impulsionam a GenAI para a produção, muitas estão redescobrindo os benefícios das implementações on-premise — seja para conter os custos da nuvem, atender a requisitos rigorosos de conformidade ou oferecer latência ultrabaixa. Mas uma pilha de IA on-premise não é um único aparelho que você pode instalar e esquecer. É um ecossistema em camadas de hardware, orquestração, plataformas de dados e frameworks de serviço que devem funcionar em conjunto.
Este guia explora cada camada da moderna pilha de IA on-premise e mostra a proposta de valor para cada componente.
Por Que a IA On-Premise Está Ganhando Força
Empresas dos setores financeiro, de saúde, manufatura e governo estão enfrentando regulamentações de soberania de dados mais rigorosas, contas de nuvem crescentes e SLAs de desempenho que a nuvem pública nem sempre consegue atender. Juntas, essas camadas formam a base de uma plataforma de IA on-premise que as empresas podem escalar, governar e operar independentemente das restrições da nuvem pública.
Controle e Conformidade de Dados: Mantenha dados sensíveis inteiramente atrás do seu firewall. Quando os dados são enviados para uma nuvem pública, sua localização física exata e a jurisdição legal a que estão sujeitos podem se tornar ambíguas, criando riscos significativos de conformidade e complicando auditorias. Uma configuração on-premise permite que uma organização adapte toda a sua pilha de IA para cumprir essas regulamentações, fornecendo uma estrutura defensável que adere aos padrões legais e evita as complexidades das questões de transferência de dados transfronteiriças.
Desempenho e Latência: Co-localizar computação e armazenamento para inferência em tempo real. Ao processar dados localmente, a IA on-premise pode oferecer latência significativamente menor e, mais importante, mais previsível. Este desempenho consistente e de alta taxa de transferência é essencial para aplicações que exigem tomada de decisão instantânea e intermodal, como a análise de um fluxo de dados de sensores enquanto os cruza com registros históricos. Essa vantagem de desempenho se estende à integração com sistemas empresariais existentes. Soluções on-premise, devido à sua flexibilidade e capacidade de personalização, podem ser frequentemente integradas de forma mais fácil e confiável com bancos de dados legados, sistemas ERP e outras tecnologias operacionais que podem não ser compatíveis com ambientes de nuvem padronizados.
Previsibilidade de Custos: Mude de taxas variáveis de pagamento conforme o uso para investimentos fixos em infraestrutura. Taxas ocultas para egresso de dados, chamadas de API, camadas de armazenamento e preços de computação flutuantes podem rapidamente corroer os benefícios iniciais de baixo CapEx, levando ao que algumas análises chamaram de "desperdício puro" nos gastos com a nuvem. Em contraste, uma implementação on-premise, apesar de seu alto custo inicial, oferece OpEx de longo prazo previsível e gerenciável. Para organizações com uso sustentado de IA, a infraestrutura on-premise frequentemente se mostra a opção mais econômica em um horizonte de três a cinco anos.
Integração Personalizada: Conecte-se perfeitamente a sistemas legados, dispositivos de borda ou hardware proprietário.
No entanto, construir e operar esta pilha internamente acarreta despesas de capital, requisitos de talentos especializados e custos de manutenção contínuos.
O Que É Uma Pilha de IA On-Premise Moderna?
Uma pilha de IA on-premise moderna é um sistema complexo e multicamadas onde cada componente desempenha um papel crucial. Não é uma entidade monolítica, mas um ecossistema interdependente de hardware e software projetado para fornecer capacidades de IA robustas, escaláveis e eficientes. Compreender esta pilha requer uma desconstrução camada por camada, desde a infraestrutura física que fornece a energia bruta até as plataformas de alto nível que permitem o fluxo de trabalho de IA.
Cada camada deve ser arquitetada para maximizar a utilização, garantir a confiabilidade e permitir uma escalabilidade contínua — sem prender você a um único fornecedor.
Hardware e Infraestrutura Física
Este é o alicerce de toda a pilha de IA, a manifestação física do poder computacional. Compreende os motores de computação que realizam os cálculos, os sistemas de armazenamento que guardam os vastos conjuntos de dados e a malha de rede que conecta tudo. O desempenho e as limitações desta camada ditam o potencial de todas as camadas subsequentes
Motores de Computação
GPUs: Originalmente projetadas para renderização de gráficos 3D, as GPUs tornaram-se o motor da revolução da IA devido à sua arquitetura massivamente paralela. A NVIDIA estabeleceu uma posição dominante neste mercado com suas GPUs para data centers, como as séries A100, H100 e a futura B200. Esses chips, equipados com milhares de núcleos especializados (por exemplo, Tensor Cores), podem oferecer um desempenho para o treinamento de IA até 20 vezes mais rápido do que as CPUs tradicionais. Eles são o padrão de facto atual para a construção de clusters de treinamento de IA de alto desempenho no local.
CPUs: Embora as GPUs lidem com o trabalho pesado do processamento paralelo, as CPUs permanecem componentes essenciais do servidor de IA. Elas gerenciam as operações gerais do sistema, lidam com tarefas de processamento sequencial e orquestram o fluxo de dados para e das GPUs. A última geração de CPUs multi-core da Intel e AMD fornece o poder de computação de uso geral necessário para suportar os aceleradores especializados
ASICs/TPUs: A tendência emergente e disruptiva na computação de IA é a ascensão dos Circuitos Integrados de Aplicação Específica (ASICs). São chips projetados do zero para um único propósito: executar cargas de trabalho de IA. As Unidades de Processamento de Tensor (TPUs) do Google são um excelente exemplo, otimizadas para as operações de matriz no cerne das redes neurais. No mercado local, uma nova classe de startups está desafiando o monopólio das GPUs com ASICs especializados. Empresas como Groq estão desenvolvendo chips para inferência de latência ultrabaixa, enquanto SambaNova Systems e Cerebras estão criando arquiteturas inovadoras (Unidades de Fluxo de Dados Reconfiguráveis e Motores em Escala de Wafer, respectivamente) que prometem maior TCO e eficiência energética para treinamento e inferência em larga escala. Esses aceleradores especializados representam o futuro do hardware de IA, oferecendo um caminho além das limitações de energia e custo das GPUs de uso geral.
Servidores e Armazenamento Empresariais
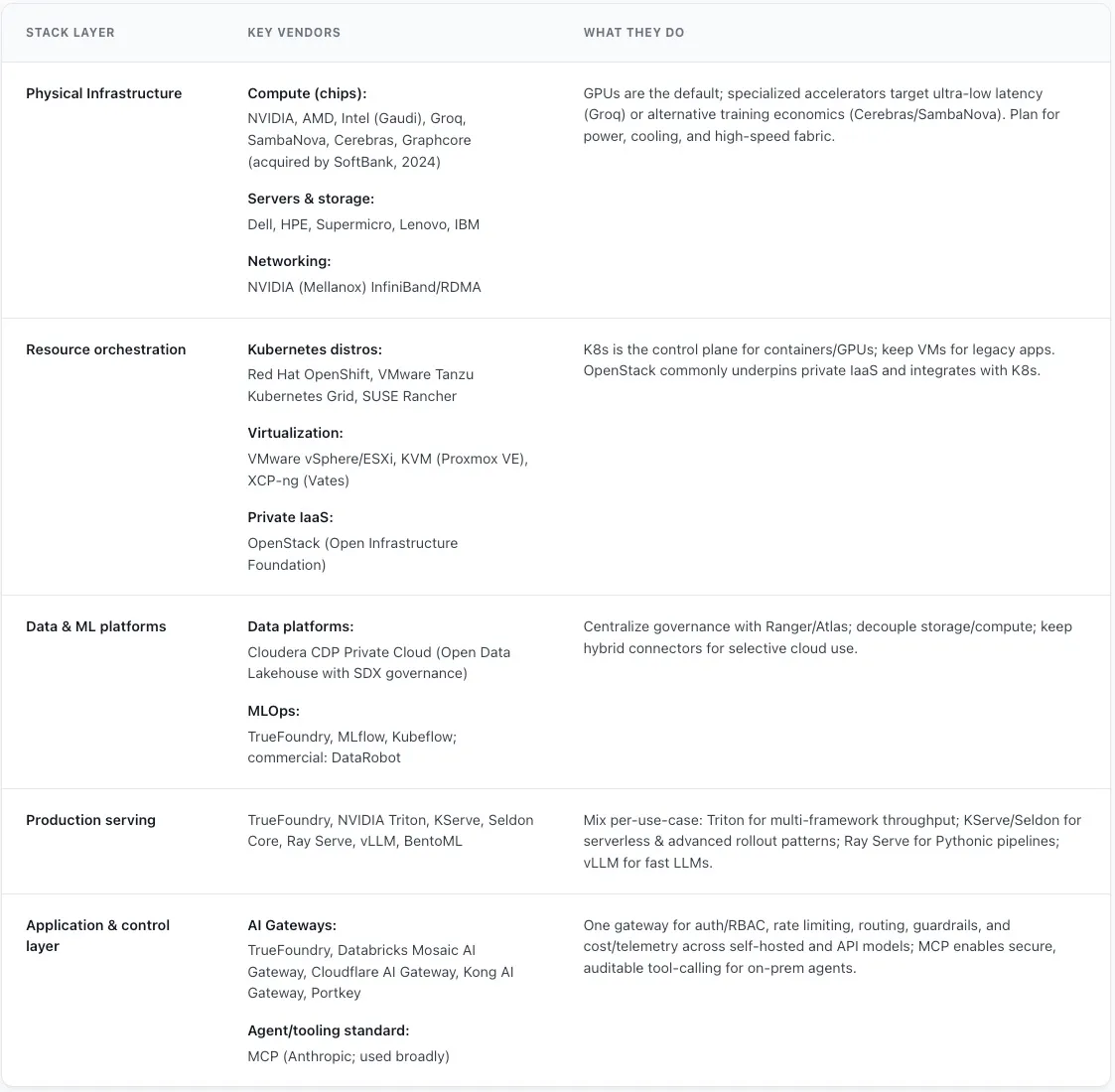
Servidores de Alto Desempenho: Principais fornecedores de hardware empresarial, como Hewlett Packard Enterprise (HPE) com suas linhas ProLiant e Apollo, Dell Technologies com seus servidores PowerEdge, Supermicro, e IBM com seus Power Systems, fornecem o chassi do servidor para IA on-premise. Estes não são servidores padrão; são projetados especificamente para acomodar múltiplas GPUs de alta potência, fornecer grandes quantidades de memória de alta velocidade (RAM) e incorporar soluções avançadas de refrigeração para lidar com a saída térmica dos aceleradores.
Armazenamento de Alto Desempenho: A IA é alimentada por dados, e a camada de armazenamento deve fornecer acesso rápido e concorrente a grandes conjuntos de dados sem criar um gargalo. Isso exige ir além do armazenamento tradicional. Soluções de armazenamento de alto desempenho e baixa latência, como SSDs NVMe (Non-Volatile Memory Express) e sistemas de arquivos distribuídos são essenciais. Os próprios dados são tipicamente organizados em data lakes para armazenar grandes quantidades de dados brutos e não estruturados (imagens, texto, logs) e data warehouses para dados estruturados e prontos para análise. Um componente emergente crítico, especialmente para IA generativa, é o banco de dados vetorial, que é otimizado para armazenar e consultar os embeddings vetoriais de alta dimensão que representam dados não estruturados.
Rede de Alta Velocidade
InfiniBand e RDMA fornecem até 400 Gbps de taxa de transferência de baixa latência, garantindo que as GPUs permaneçam alimentadas com dados durante o treinamento distribuído ou inferência paralela. A camada de rede é o "sistema nervoso" do data center de IA, responsável pela transferência contínua de dados entre os sistemas de armazenamento e os nós de computação. Para IA em larga escala, particularmente treinamento distribuído onde um único modelo é treinado em centenas ou milhares de GPUs, a rede Ethernet padrão é insuficiente e pode se tornar um grande gargalo de desempenho. Para evitar que as poderosas GPUs fiquem ociosas enquanto esperam por dados, os clusters de IA on-premise dependem de malhas de rede de alta largura de banda e baixa latência. Tecnologias como InfiniBand e RDMA (Remote Direct Memory Access) são críticas. InfiniBand, por exemplo, pode suportar uma taxa de transferência de até 400 gigabits por segundo, garantindo que os dados possam ser movidos entre servidores e armazenamento na velocidade necessária para manter os motores de computação totalmente utilizados. Este interconexão de alta velocidade é um componente inegociável de qualquer infraestrutura de IA on-premise séria.
A Camada de Orquestração e Gerenciamento
Situada sobre o hardware físico, a camada de orquestração e gerenciamento consiste no software que abstrai, particiona e gerencia os recursos subjacentes. Esta camada transforma uma coleção rígida de servidores físicos em uma plataforma flexível, escalável e eficiente para desenvolver e executar aplicações de IA.
O Papel da Virtualização e Contentorização
As tecnologias fundamentais para a gestão de recursos são a virtualização e a contentorização. Elas permitem o particionamento e isolamento eficientes de cargas de trabalho.
Máquinas Virtuais (VMs): A virtualização tem sido um pilar do centro de dados há décadas. Um hipervisor cria múltiplas máquinas virtuais num único servidor físico, cada uma com o seu próprio sistema operativo completo. Embora robustas e bem compreendidas, as VMs têm um maior consumo de recursos e tempos de inicialização mais lentos em comparação com os contentores. No entanto, continuam relevantes, especialmente para modernizar aplicações legadas juntamente com novas cargas de trabalho de IA. Plataformas como IBM Fusion e Vates VMS são especificamente concebidas para fornecer uma plataforma unificada no local que pode gerir tanto VMs como contentores, muitas vezes com funcionalidades como GPU direta.
Contentores (ex: Docker): A contentorização é a abordagem moderna e leve para o isolamento de cargas de trabalho. Um contentor empacota uma aplicação e todas as suas dependências (bibliotecas, ficheiros de configuração) numa única unidade portátil que partilha o kernel do sistema operativo anfitrião. Isto resulta numa pegada muito menor, tempos de inicialização mais rápidos e maior eficiência de recursos do que as VMs. Para a IA, isto significa que um modelo e o seu ambiente específico podem ser encapsulados numa imagem de contentor imutável. Esta imagem pode então ser implementada de forma consistente no portátil de um programador, num servidor de testes e no cluster de produção, eliminando o problema "funcionou na minha máquina" e garantindo a reprodutibilidade.
Kubernetes: O SO do Centro de Dados de IA
Enquanto o Docker fornece o formato de contentor, Kubernetes fornece a gestão em larga escala. Kubernetes é uma plataforma de código aberto que automatiza a implementação, escalabilidade, rede e gestão de aplicações contentorizadas num cluster de máquinas. Tornou-se o padrão incontestável para a orquestração de contentores e é o motor por trás da maioria das aplicações nativas da cloud modernas, seja na cloud pública ou no local.
Para a IA no local, Kubernetes é a ligação crítica entre a camada de aplicação e o hardware. Distribuições Kubernetes de nível empresarial como Red Hat OpenShift são especificamente concebidas para implementações no local e em cloud híbrida, fornecendo a segurança, gestão e suporte que as empresas exigem.
Os benefícios de usar Kubernetes para cargas de trabalho de IA são profundos:
Escalabilidade Automática e Balanceamento de Carga: Kubernetes pode escalar automaticamente o número de réplicas de contentores para cima ou para baixo com base na demanda computacional e distribuir pedidos de inferência entre eles, garantindo alta disponibilidade e desempenho.
Gestão e Agendamento de Recursos: Kubernetes possui capacidades de agendamento com reconhecimento de GPU, permitindo-lhe colocar inteligentemente cargas de trabalho de IA em nós que possuem o hardware acelerador necessário disponível, maximizando a utilização destes recursos caros.
Resiliência e Autorrecuperação: Se um contêiner ou um nó falhar, o Kubernetes pode reiniciá-lo automaticamente ou reagendá-lo em um nó saudável, proporcionando a resiliência necessária para trabalhos de treinamento de modelos de longa duração e serviços de inferência de missão crítica.
Em essência, o Kubernetes fornece o sistema operacional dinâmico, automatizado e resiliente para o data center de IA local.
Capacitação de Dados e ML
Plataformas de Dados e Governança
Esta é a camada de software mais alta da pilha, contendo as ferramentas e plataformas especializadas que cientistas de dados e engenheiros de machine learning utilizam para executar o ciclo de vida de IA de ponta a ponta. Esta camada aproveita o hardware e a orquestração subjacentes para gerenciar dados e para construir, treinar, implantar e monitorar modelos de IA.
A Malha de Dados (Plataformas de Dados)
Antes que qualquer modelo possa ser construído, os dados devem ser gerenciados. Plataformas de dados fornecem um ambiente unificado para todo o ciclo de vida dos dados, desde a ingestão e processamento até o armazenamento e a governança.
Cloudera Data Platform (CDP): Um player dominante no cenário de dados on-premise e híbrido, a Cloudera evoluiu de suas raízes no ecossistema Hadoop para se tornar uma plataforma de dados corporativa abrangente. O CDP Private Cloud é especificamente projetado para rodar on-premise, tipicamente sobre um cluster Kubernetes como o Red Hat OpenShift. Ele fornece uma arquitetura unificada de open data lakehouse que pode lidar com dados estruturados e não estruturados em escala de petabytes. Crucialmente para a IA corporativa, ele integra segurança robusta e centralizada através do Apache Ranger e uma estrutura unificada de governança e metadados chamada Shared Data Experience (SDX), garantindo que políticas de segurança consistentes sejam aplicadas a todos os dados e análises em todo o ambiente híbrido.
Databricks e Conectividade Híbrida: Embora o Databricks seja principalmente uma plataforma nativa da nuvem, sua proeminência no espaço da IA significa que muitas organizações estão desenvolvendo soluções para conectar suas fontes de dados locais, como um cluster Cloudera, ao seu ambiente Databricks. Essa realidade ressalta a natureza híbrida da IA empresarial moderna, onde a gravidade dos dados frequentemente exige a manutenção de grandes conjuntos de dados no local, enquanto se aproveitam ferramentas baseadas em nuvem para certas análises ou tarefas de colaboração.
MLOps e Experimentação
MLOps (Machine Learning Operations) é um conjunto de práticas que visa implantar e manter modelos de machine learning em produção de forma confiável e eficiente. As plataformas MLOps são as ferramentas que possibilitam essas práticas, automatizando todo o ciclo de vida do ML e preenchendo a lacuna entre a ciência de dados (construção de modelos) e as operações de TI (execução em produção).
As principais funções de uma plataforma MLOps incluem: rastreamento de experimentos (registro de todos os parâmetros, métricas e artefatos), versionamento e registro de modelos, construção de pipelines automatizados de CI/CD (Integração Contínua/Implantação Contínua) para modelos, gerenciamento de implantação de modelos e monitoramento do desempenho do modelo para problemas como desvio de dados (data drift).
O mercado de MLOps on-premise apresenta uma mistura de poderosas plataformas de código aberto e comerciais:
Código Aberto:MLflow é uma plataforma MLOps de código aberto líder, amplamente adotada por sua flexibilidade, abordagem agnóstica a frameworks e recursos abrangentes para rastreamento de experimentos e gerenciamento de modelos. Ela permite que as equipes construam fluxos de trabalho MLOps robustos sem dependência de fornecedor (vendor lock-in).
Plataformas Comerciais: Plataformas gerenciadas de ponta a ponta como DataRobot, Iguazio (adquirida pela McKinsey), oferecem soluções abrangentes que cobrem todo o ciclo de vida, muitas vezes com foco na facilidade de uso, automação e suporte de nível empresarial.
Aumente a escolha da plataforma com o RBAC, guardrails e orçamentos do AI Gateway da TrueFoundry para garantir que as políticas sejam aplicadas de forma contínua entre equipes e modelos.
Servindo e Escalando IA em Produção
Uma vez que um modelo é treinado e validado, ele deve ser implantado em um ambiente de produção onde pode receber dados de entrada e retornar previsões — um processo chamado inferência. O serviço de modelos é uma tarefa especializada que requer software otimizado para alto rendimento e baixa latência.
NVIDIA Triton Inference Server: Um servidor de inferência de alto desempenho e código aberto da NVIDIA. Seus principais pontos fortes são a capacidade de executar modelos de praticamente qualquer framework (TensorFlow, PyTorch, ONNX, etc.) e sua capacidade de execução concorrente de modelos, que permite que múltiplos modelos ou múltiplas instâncias do mesmo modelo sejam executados em uma única GPU, maximizando a utilização do hardware.
KServe: Um padrão para servir modelos no Kubernetes. O KServe oferece uma plataforma escalável e extensível para implantação de modelos. Seus recursos de destaque incluem capacidades de inferência serverless (com autoescalonamento que pode reduzir os pods a zero quando não estão em uso, economizando recursos) e um "InferenceGraph" que suporta estratégias avançadas de implantação, como lançamentos canary, testes A/B e conjuntos de modelos.
Seldon Core: Outra poderosa plataforma de código aberto para servir modelos no Kubernetes. O Seldon Core também é conhecido por seu suporte robusto a padrões avançados de implantação, incluindo testes A/B, implantações canary e multi-armed bandits (MABs), tornando-o uma forte escolha para organizações que precisam testar e otimizar modelos rigorosamente em produção.
Outros Frameworks: O ecossistema também inclui outras ferramentas poderosas de código aberto, como Haystack, que é um framework para construir pipelines complexos de agentes e RAG, e Ray, um motor de computação distribuída frequentemente usado como a espinha dorsal para treinar e servir aplicações de IA em larga escala.
A TrueFoundry opera como um gateway/controle plano acima desses servidores, para que você possa misturar e combinar (Triton para modelos de Visão Computacional, vLLM para LLMs, KServe para bordas serverless) mantendo uma interface, política e camada de telemetria consistentes.
A Camada de Aplicação e Controle: AI Gateway e MCP
As camadas descritas até agora fornecem a base para construir e executar modelos de IA. No entanto, para tornar esses modelos acessíveis de forma segura e eficiente a aplicativos de usuário final e para habilitar fluxos de trabalho complexos e agênticos, é necessária uma camada de software final: a Camada de Aplicação e Controle. Esta camada atua como o sistema nervoso central para todas as interações de IA, fornecendo governança, segurança e uma interface padronizada para comunicação. Ela consiste em dois componentes críticos e emergentes: o Gateway de IA e o Protocolo de Contexto de Modelo (MCP).
O Gateway de IA: Um Plano de Controle Centralizado
Um Gateway de IA é um middleware especializado que serve como um ponto de controle único e centralizado para todo o tráfego relacionado à IA entre aplicativos e os modelos de IA subjacentes. Implantado no ambiente local (on-premise), frequentemente no Kubernetes, ele fornece um conjunto crítico de funções para gerenciar a IA em escala empresarial.
Acesso Unificado e Roteamento Inteligente: O gateway oferece um único e consistente endpoint de API para desenvolvedores, abstraindo a complexidade de interagir com múltiplos modelos diferentes (por exemplo, uma mistura de modelos de código aberto ajustados e modelos comerciais especializados). Ele pode realizar roteamento baseado em contexto, direcionando as solicitações para o modelo mais apropriado com base em fatores como custo, requisitos de desempenho ou o caso de uso específico, otimizando tanto a eficiência quanto os resultados.
Segurança Robusta e Governança: Para IA local (on-premise), a segurança é primordial. O Gateway de IA atua como um ponto de aplicação de políticas, integrando-se à arquitetura de segurança empresarial para gerenciar autenticação, autorização e controle de acesso baseado em função (RBAC). Ele inspeciona tanto os prompts de entrada quanto as respostas de saída em tempo real para prevenir ataques de injeção de prompt e vazamento de dados sensíveis, como Informações de Identificação Pessoal (PII), garantindo a conformidade com regulamentações como GDPR e HIPAA.
Observabilidade Abrangente e Controle de Custos: O gateway fornece um painel unificado para monitorar todas as interações de IA, rastreando métricas chave como latência, taxas de erro e uso de tokens. Essa observabilidade centralizada é crucial para a solução de problemas e otimização de desempenho. Além disso, ele permite um controle de custos granular ao impor limites de taxa baseados em tokens e orçamentos de uso, prevenindo custos descontrolados e permitindo estornos precisos para diferentes unidades de negócio.
O Protocolo de Contexto de Modelo (MCP): A Linguagem Universal para Agentes de IA
Enquanto o Gateway de IA gerencia o fluxo de solicitações, o Protocolo de Contexto de Modelo (MCP) é um padrão aberto que revoluciona o que essas solicitações podem fazer. O MCP fornece uma maneira padronizada para modelos de IA descobrirem e interagirem com ferramentas, dados e serviços externos, transformando-os de "cérebros" isolados em agentes capazes e integrados.
Uma Interface Padronizada para Ferramentas: Em vez de construir código frágil e personalizado para cada integração, o MCP permite que sistemas empresariais (como bancos de dados, CRMs ou APIs internas) anunciem suas capacidades através de um "servidor MCP" leve. O aplicativo de IA, atuando como um "host MCP", pode então consultar esses servidores para entender quais ferramentas estão disponíveis e como usá-las, criando efetivamente um ecossistema plug-and-play para agentes de IA.
Habilitando IA Agêntica Local (On-Premise): Uma vantagem chave do MCP é que ele é um protocolo aberto e auditável que pode ser implantado inteiramente dentro do firewall de uma organização. Isso permite que as empresas construam agentes de IA poderosos e autônomos que podem interagir de forma segura com sistemas internos proprietários sem expor dados sensíveis a serviços externos.
Prevenindo o Bloqueio de Fornecedor (Vendor Lock-In): Como o MCP é um padrão agnóstico de modelo suportado por grandes players como Anthropic, OpenAI e Microsoft, ele desvincula o modelo de IA das integrações de ferramentas. Isso oferece às empresas a flexibilidade de trocar o LLM subjacente — por exemplo, passando de uma API comercial para um modelo auto-hospedado e ajustado — sem ter que reconstruir toda a pilha de integração, preservando assim a soberania tecnológica.
Juntos, o AI Gateway e o MCP formam uma poderosa camada de controle e aplicação que torna a IA on-premise não apenas possível, mas também segura, gerenciável e verdadeiramente integrada ao tecido da empresa.
O MCP Gateway da TrueFoundry combina ambos: governança e observabilidade para cada solicitação, além de chamadas de ferramentas seguras e auditadas via MCP, para que os agentes possam atuar nos seus sistemas internos sem que os dados saiam da sua rede.
Mapeamento de Fornecedores em Toda a Pilha de IA On-Premise
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




