



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Em 2026, as empresas não podem mais se dar ao luxo de modificar um Gateway LLM para um improvisado Gateway de IA. A IA só se tornará mais integrada em fluxos de trabalho voltados para o cliente, tornando uma camada de gateway dedicada inegociável para aplicações confiáveis impulsionadas por IA. A infraestrutura de IA empresarial típica é frequentemente multi-modelo, multi-equipe e multi-nuvem, levando a uma conformidade complexa e responsabilidade de custos.
A Gartner define um gateway de IA como uma tecnologia ou plataforma que atua como intermediário entre aplicações e vários serviços ou modelos de inteligência artificial (IA). Seu propósito é simplificar e gerenciar o acesso às capacidades de IA, fornecendo um ponto central para habilitar segurança, governança e observabilidade de cargas de trabalho de IA. Leia o Gartner Market Guide para Gateways de IA 2025 para saber mais.
No último ano, vimos surgir três grandes categorias para abordar o problema de governança e resiliência da GenAI:
Cada categoria otimiza para uma fase diferente da adoção de IA. Problemas surgem quando ferramentas otimizadas para uma fase são estendidas para lidar com outra.
Neste blog, reunimos toda a pesquisa competitiva em um cenário definitivo, explicando onde cada plataforma se encaixa, onde elas falham e o que as empresas precisam considerar ao escolher um fornecedor que melhor atenda às suas necessidades.
1. Kong AI: Gateway de API Tradicional Adaptado para IA
Kong é um gateway de API, frequentemente usado em arquiteturas de microsserviços baseadas em Kubernetes. O Kong AI se baseia nessa fundação, introduzindo plugins e integrações projetados para rotear o tráfego para grandes modelos de linguagem.
O Que o Kong AI Faz Bem
Onde o Kong AI falha
À medida que o uso de IA cresce, essas lacunas se tornam mais visíveis. A atribuição de custos, as estratégias de seleção de modelo e a governança específica de IA devem ser tratadas fora do gateway, muitas vezes dentro do código da aplicação.
Em resumo: O Kong AI é eficaz como um gateway de API, mas a IA permanece uma preocupação secundária em vez de uma abstração nativa.
2. Portkey: Gateway LLM em Nível de Aplicação
Portkey é um gateway de IA projetado especificamente para aplicações LLM. Em vez de tratar as requisições de IA como chamadas HTTP genéricas, o Portkey introduz roteamento e observabilidade com reconhecimento de prompt e modelo.
O que o Portkey faz bem
Onde o Portkey fica aquém
O design do Portkey é intencionalmente focado na aplicação, o que introduz restrições em escala empresarial
À medida que a IA se torna uma capacidade interna compartilhada, em vez de um recurso de aplicativo único, essas limitações frequentemente exigem camadas de infraestrutura adicionais.
Melhor para: Aplicativos LLM de equipe única que estão entrando em produção inicial.
3. LiteLLM: Gateway de Código Aberto Focado no Desenvolvedor
LiteLLM é um de código aberto gateway LLM que oferece uma API unificada e compatível com OpenAI para acessar dezenas de provedores de modelos.
Pontos Fortes do LiteLLM
Pontos Fracos do LiteLLM
Melhor para: O LiteLLM é um ponto de entrada eficaz, mas exige um reforço considerável para ambientes regulamentados ou com várias equipas.
Leia também: Portkey vs LiteLLM
4. AWS Bedrock: APIs de Modelo Sem Servidor
O AWS Bedrock oferece acesso gerido e sem servidor a modelos de base de fornecedores como Anthropic e Amazon. Abstrai completamente a infraestrutura e cobra puramente com base no uso de tokens.
O que o AWS Bedrock faz bem
Compromissos Ocultos do AWS Bedrock
Estes compromissos frequentemente surpreendem as equipas à medida que as cargas de trabalho passam da experimentação para o uso de produção sustentado.
Em resumo: O Bedrock otimiza para velocidade e simplicidade, não para eficiência de custos a longo prazo ou controlo.
5. AWS SageMaker: Infraestrutura de ML Gerida
O SageMaker oferece um conjunto completo para treinar, ajustar e implantar modelos de machine learning. Ao contrário do Bedrock, ele expõe as escolhas de infraestrutura diretamente aos usuários.
O que o AWS Sagemaker faz bem
Desvantagens do AWS Sagemaker
Em resumo: O SageMaker oferece controle, mas ao custo da simplicidade operacional.
6. Databricks: A Plataforma ML Lakehouse
O Databricks aborda a IA a partir de uma perspectiva de dados, integrando recursos de ML e GenAI em sua arquitetura Lakehouse.
O que o Databricks faz bem
Onde o Databricks fica aquém
Em resumo: A Databricks se destaca em engenharia de dados, não em servir IA.
O Fio Condutor: Gateways Sem Governança
Entre Kong vs LiteLLM, Portkey, e até mesmo Bedrock, o mesmo problema surge: eles gerenciam requisições, não sistemas de IA.
Entre gateways e serviços gerenciados, um problema recorrente aparece: a maioria das ferramentas foca em requisições, não em sistemas.
Eles respondem a perguntas como:
Eles têm dificuldade com:
Estas são preocupações de nível de infraestrutura.
O TrueFoundry ocupa uma camada diferente na pilha. Em vez de focar apenas no roteamento de API ou em serviços gerenciados, ele trata as cargas de trabalho de IA — modelos, agentes, serviços e tarefas — como objetos de infraestrutura de primeira classe. Isso transfere a responsabilidade do código da aplicação para a própria plataforma.
O TrueFoundry AI Gateway é construído com os seguintes princípios fundamentais:
Isso significa que o AI Gateway é um componente de um sistema maior, permitindo que as empresas escalem seus casos de uso de IA de forma contínua.
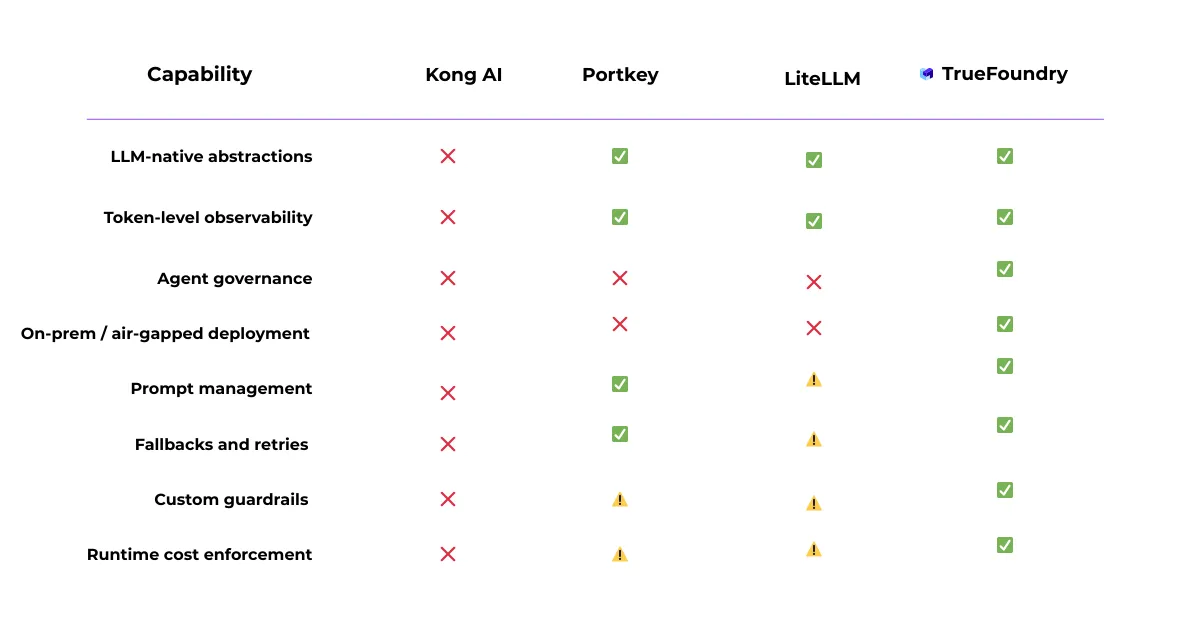
O TrueFoundry AI Gateway torna-se crítico quando o uso de IA vai além de aplicações isoladas e se torna uma capacidade compartilhada e crítica para a produção. Nessa fase, os desafios são frequentemente menos sobre chamadas de modelo individuais e mais sobre consistência operacional entre equipes e ambientes.
Veja como o AI Gateway do TrueFoundry difere de outras soluções:
Muitas ferramentas de IA focam em preocupações no nível da requisição, como roteamento, novas tentativas e observabilidade básica. Isso geralmente é suficiente nos estágios iniciais.
À medida que o uso se expande, no entanto, modelos e agentes começam a se comportar mais como serviços de longa duração. As equipes precisam de propriedade mais clara, gerenciamento de ciclo de vida e limites operacionais. O TrueFoundry é projetado para gerenciar cargas de trabalho de IA — modelos, serviços e tarefas — como componentes de infraestrutura com características de implantação e tempo de execução definidas.
Em muitas pilhas, os controles de acesso e as políticas de uso são configurados no nível da aplicação ou do SDK. Com o tempo, isso pode levar à inconsistência à medida que o número de serviços aumenta.
O TrueFoundry aplica controles no nível do ambiente, separando desenvolvimento, homologação e produção por padrão. As políticas definidas nesta camada são aplicadas uniformemente a todas as cargas de trabalho implantadas em um ambiente, reduzindo a dependência de configurações por aplicação.
Os custos de IA frequentemente aumentam devido à concorrência, novas tentativas ou cargas de trabalho em segundo plano, em vez de requisições individuais. A TrueFoundry aborda isso aplicando limites de concorrência, taxa de transferência e uso de recursos durante a execução.
Isso permite que as organizações gerenciem a infraestrutura compartilhada de forma mais previsível à medida que o uso aumenta.
Embora as métricas em nível de token sejam úteis, elas não explicam completamente o comportamento do sistema em produção. A TrueFoundry correlaciona sinais em nível de requisição com métricas de infraestrutura, como utilização de CPU/GPU e comportamento de autoescalonamento, ajudando as equipes a entender o desempenho e os fatores de custo em contexto.
Algumas organizações operam sob restrições que exigem redes privadas, implantações on-premise ou residência de dados rigorosa. A TrueFoundry foi projetada para operar nesses ambientes, permitindo que as cargas de trabalho de IA sejam governadas usando os mesmos padrões de infraestrutura aplicados em outras partes da organização.
Conclusão
O cenário atual das plataformas de IA reflete a velocidade com que a IA generativa evoluiu. Muitas ferramentas abordam problemas reais — roteamento, acesso a modelos, observabilidade ou treinamento — mas o fazem a partir de diferentes pontos de partida. Como resultado, nenhuma categoria única cobre naturalmente o conjunto completo de requisitos operacionais que surgem quando a IA se torna crítica para a produção.
A TrueFoundry oferece o maior valor quando as cargas de trabalho de IA precisam ser operadas com a mesma disciplina de outros sistemas de produção — em diferentes ambientes, sob políticas compartilhadas e com comportamento de recursos previsível.
Empresas que comparam fornecedores frequentemente começam procurando pelo melhor gateway LLM, mas o verdadeiro diferencial reside na forma como a plataforma governa os sistemas de IA em escala. Compreender onde cada plataforma se encaixa e onde suas premissas de design começam a falhar é essencial ao avaliar o melhor gateway de IA para implantações em escala empresarial. A escolha certa depende menos de recursos individuais e mais de como uma organização espera que o uso de sua IA evolua ao longo do tempo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


O melhor gateway de IA depende dos requisitos específicos da organização. O AI Gateway da TrueFoundry se destaca para empresas que precisam de roteamento multiprovedor, governança centralizada, rastreamento de custos e integração MCP em uma única plataforma. Outras opções robustas incluem o LiteLLM para flexibilidade de código aberto e o Kong AI Gateway para equipes já investidas no ecossistema de gerenciamento de API da Kong.
Um gateway de IA é uma camada de middleware que se situa entre aplicações e provedores de LLM (como OpenAI, Anthropic ou Google). A sua arquitetura geralmente inclui um motor de roteamento que direciona as requisições para o modelo apropriado, uma camada de políticas para aplicar limites de taxa e controles de acesso, uma pilha de observabilidade para registro de logs e acompanhamento de custos, e uma camada de cache para reduzir chamadas de API redundantes. Essa arquitetura permite que as organizações gerenciem implantações multi-modelo a partir de um único painel de controle.
A TrueFoundry diferencia-se ao combinar capacidades de gateway de IA com uma plataforma completa de infraestrutura de ML, incluindo serviço de modelos, ajuste fino e gestão de servidores MCP, numa solução unificada. O seu Gateway de IA oferece funcionalidades de nível empresarial, como controlo de orçamento por equipa, registo de auditoria, encaminhamento de fallback de modelos e suporte nativo a MCP, tornando-o particularmente adequado para organizações que procuram governar e escalar o Claude Code e outras implementações de IA agentiva.






As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




