














November 5, 2025
|
5 min read

Published: July 4, 2026
%20(10).webp)
Blazingly fast way to build, track and deploy your models!

この例では、花弁と萼片のサイズ測定に基づいて、アヤメ属の花を3つの種のうちの1つに分類できるモデルを学習します。
この例は、 Google Colaboratory ノートブックでも試すことができます。
アイリスデータセット には、3つの異なる種が含まれています。
以下のパラメータに基づいて、花の種を識別できる分類器を構築する必要があります。
TrueFoundry MLワークフローを簡素化するための2つのライブラリを提供しています。
mlfoundry ライブラリは、MLトレーニング実験を追跡するために使用されます。
なぜ実験の追跡が必要なのでしょうか? ある問題を解決するために複数のMLモデルをトレーニングしている場合、複数のフレームワーク、ハイパーパラメータ、複数のデータセットを使用して、複数のモデルをトレーニングすることになるでしょう。のようなライブラリを使用して実験を追跡することは、 mlfoundry ML実験を整理するのに役立ちます。
MLFoundryを使用して、ハイパーパラメータ、メトリクス、データセット、モデルのログを記録できます。その後、で異なる実験を比較し、 TrueFoundryダッシュボード 本番環境にデプロイするモデルを選択したり、モデルを再トレーニングするかどうかを決定したりできます。
この例では、MLFoundryの5つの異なるAPIを使用します。それらは次のとおりです。
Using the servicefoundry ライブラリを使用すると、モデルをパッケージ化、コンテナ化し、Kubernetesクラスターに簡単にデプロイできます。
IPythonノートブックを開きます。ローカルマシンで実行されているJupyter、またはクラウド上のGoogle Colabノートブックのいずれかを使用できます。
必要なライブラリをインストールします。
TrueFoundryにログインします。設定ページからAPIキーを作成し、コピーします。このAPIキーを使用してMLFoundryクライアントを初期化し、実行(run)を作成します。実行(run)とは、単一の実験を表すエンティティです。
Irisデータセットをthe sklearn.datasets モジュールを使用して取得します。次に、それをテストデータセットとトレーニングデータセットに分割します。
ターゲット名を確認しましょう。これを使って、モデルからの整数出力を実際の種の名前とマッピングします。
モデルを初期化します。次に、MLFoundryを使用してモデルのパラメータをログに記録し、この実験実行(run)用のタグを作成します。
次に、トレーニングデータセットでモデルを学習させます。学習が完了したら、様々なメトリクスを計算し、MLFoundry using log_metricsを使ってMLFoundryにログを記録します。
精度スコアやその他のメトリクスに満足できれば、現在のモデルをデプロイすることを選択できます。そのためには、モデルを保存し、 現在のrun IDをコピーします.
すべての実行を確認し、メトリクスを比較できます。 TrueFoundry 実験追跡ダッシュボード。

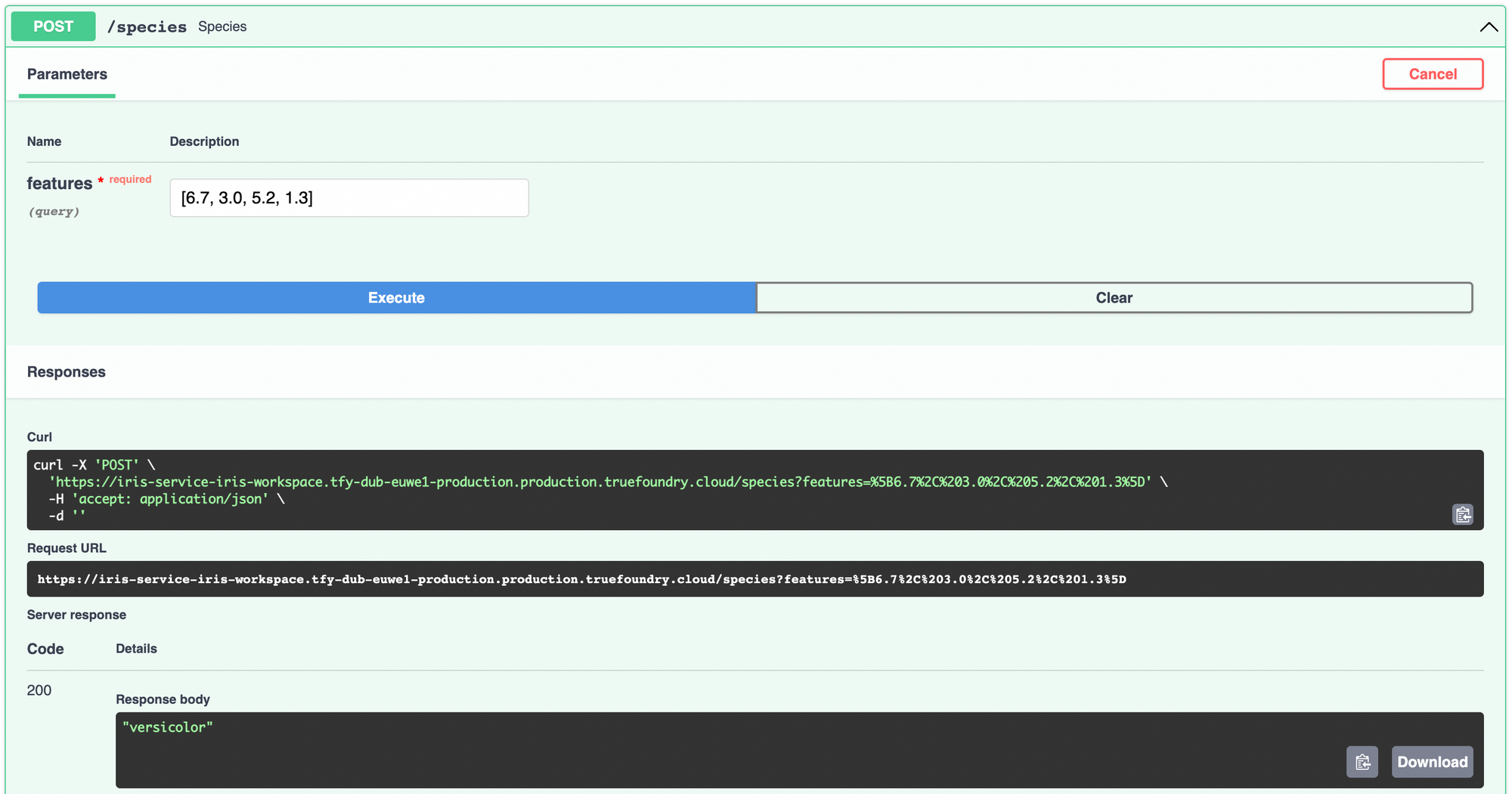
ServiceFoundry を使用してモデルをデプロイするには、エンドポイントとして公開したい関数を含むPythonファイルを作成する必要があります。
そのPythonファイル内で、実行IDを使用して、先ほどトレーニングして保存したモデルを mlfoundryを使用して取得します。なお、 mlfoundry が必要とするAPIキーは、環境変数 TFY_API_KEYとして利用できます。
IPythonノートブックで、以下の内容のブロックを作成し、実行してという名前のPythonファイルを作成します。 predict.py。Jupyterマジックコマンド %%writefile を使用してノートブック環境でファイルを作成します。
species関数内で、特徴量をにロードします。 pandas DataFrameを作成し、モデルを使って予測を行います。整数クラスから種名への変換には、 target_names トレーニング中に表示したものを利用します。
これで必要な作業はほぼ完了です。次に、このモデルをAPIサービスとしてデプロイしましょう。まず、 servicefoundry をノートブックにインストールしてインポートします。そして servicefoundryにログインします。
TrueFoundry ダッシュボード にアクセスし、サービスをデプロイするためのワークスペースを作成します。ワークスペースは、TrueFoundry内で関連するプロジェクトをグループ化するためのものです。ワークスペースが作成されたら、FQNをコピーして、 servicefoundry にモデルをどこにデプロイするかを伝えます。 ダッシュボードからワークスペースを作成する

servicefoundryライブラリを使用すると、作成したファイルのすべての依存関係を gather_requirements 関数を使って収集できます。
Now create a sfy.Service オブジェクトで、ワークスペースのFQNを指定し、呼び出すことでデプロイします。 .deploy()
このデプロイの進捗状況は、 ダッシュボードで確認できます。デプロイが完了したら、そこからデプロイされたサービスにアクセスして試すことができます。
TrueFoundryダッシュボードには、TrueFoundryのデプロイに標準で含まれるメトリクスやログがGrafanaダッシュボードの形式でリンクされています。詳細については、 こちら。

IPythonノートブックから、インタラクティブなUIアプリケーションやGradioアプリケーションを servicefoundryを使って簡単にデプロイすることもできます。この ガイド を読んで方法を確認してください。
実験トラッキングとデプロイの連携をさらに密接にし、より快適な体験を提供できるよう取り組んでいます。TrueFoundryでできるその他のことについては、 ドキュメントでご確認いただけます。機械学習モデルをトレーニングして問題を解決しようとしている場合、TrueFoundryはさまざまな実験を追跡するのに役立ち、ベストプラクティスに沿ってモデルを簡単かつ直感的にデプロイし、数分で一般公開できるようにします。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


