


















November 5, 2025
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
このブログでは、 TrueFoundryプラットフォームでの機械学習モデルのトレーニングについてご紹介します。TrueFoundryでトレーニングジョブを実行する方法について説明します。さらに、機械学習モデルのハイパーパラメータチューニングを簡単に行う方法や、GPUでジョブを実行する方法もご紹介します。
まずは問題設定から始めましょう。例えば、年齢、BMI、血圧などの様々な特徴に基づいて、患者の糖尿病がどのように進行するかを予測したいとします。このブログでは、 糖尿病データセット のscikit-learn機械学習モデルをトレーニングします。
機械学習モデルのトレーニングといえば、 ローカル のお使いのマシンでトレーニングしたり、 Jupyter Notebooksでトレーニングするなどがあります。しかし、トレーニングプロセスには、ローカルマシンで利用可能なリソースよりも多くのリソースが必要になる場合があります。
ここでTrueFoundryのジョブが役立ちます。これにより、トレーニングコードをリモートマシンにデプロイして実行し、ログやメトリクスを追跡できます。
注: この糖尿病データセットを使用していますが、このブログで説明されている手順は、他の機械学習モデルや深層学習モデルにも適用できます。
ジョブは、クラスター内で短期間実行される並列またはシーケンシャルなバッチタスクを実行する方法を提供します。ジョブは、長時間実行されるサービスや継続的に実行されるアプリケーションではなく、完了まで実行されるように設計されています。ジョブが完了すると、計算リソースとメモリリソースが解放されるため、追加費用は発生しません。
前述の通り、 糖尿病データセット をscikit-learnで使用します。このデータセットには442のサンプル(患者)と10個の数値特徴量が含まれています。これらの特徴量は、患者の糖尿病の進行に影響を与える可能性のある様々な要因を表しています。目的変数も数値であり、各患者のベースラインから1年後の疾患進行度を定量的に測定したものです。
機械学習モデルのトレーニングに進む前に、セットアップ手順を確認しましょう。
TrueFoundryダッシュボードにアクセスし、アカウントを作成してください。ログインするとすぐに、ワークスペースの作成を促されます。ジョブはこのワークスペースにデプロイされます。

ワークスペースを作成したら、ダッシュボードからMLリポジトリを作成してください。
MLリポジトリは、機械学習プロジェクトを表す実行、モデル、およびアーティファクトの集合体です。アーティファクト、モデル、メタデータを格納する点を除けば、Gitリポジトリのようなものだと考えることができます。すべてのアクセス制御は、MLリポジトリのレベルで設定できます。
MLリポジトリが作成されたら、ワークスペースに移動し、ワークスペースを編集して「ML Repo Access」を有効にしてください。「Add ML Repo Access」をクリックして、このワークスペースにMLリポジトリを追加します。これにより、ワークスペースで実行されているジョブがMLリポジトリへの書き込みと読み取りを行えるようになります。
pip install servicefoundry
--host: TrueFoundryダッシュボードのURLをここに指定してください
sfy login --host <YOUR-HOST-URL-HERE>
上記のセットアップ手順が完了したら、実装セクションに進むことができます。
ディレクトリ構造
このブログでは、以下のディレクトリ構造を使用します。
❯ tree
.
├── deploy.py
├── requirements.txt
└── train.py
それでは、糖尿病モデルのトレーニングコードを見ていきましょう。
モデル学習の手順
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"精度: {accuracy:.2f}")
モデル学習の完全なコード
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
def train(kernel: str, n_quantiles: int):
# データセットをロードし、訓練セットとテストセットを作成
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルを初期化
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
# モデルを訓練し、テスト
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}"
return regressor, model, X_test, y_test
機械学習モデルをトレーニングするコードを見てきたので、次に、そのようなモデルを将来使用するために保存(またはログ記録)する方法について学ぶことができます。
モデルはモデルファイルといくつかのメタデータで構成されます。各モデルは複数のバージョンを持つことができます。モデルオブジェクトを自動的にシリアル化、保存、バージョン管理するには、 save_model_metadata メソッドを使用します。その手順は以下の通りです。
モデルのログ記録手順
import mlfoundry
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
実行(Run)は単一の実験を表し、機械学習の文脈では、これは特定のモデル(例えばロジスティック回帰)と固定されたハイパーパラメータのセットを指します。メトリクスとパラメータ(詳細は後述)はすべて特定の実行の下にログ記録されます。
run.log_params(regressor.get_params())
run.log_metrics({"score": model.score(X_test, y_test)})
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
ログ記録された各モデルは、指定された name に関連付けられ、現在の実行にリンクされた新しいバージョンを生成します。モデルの複数のバージョンは、同じ 名前.
モデルロギング完了コード
import mlfoundry
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
# truefoundryのml_repoで実行を作成
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
# モデルのハイパーパラメータをログに記録
run.log_params(regressor.get_params())
# モデルのメトリクスをログに記録
run.log_metrics({"score": model.score(X_test, y_test)})
# モデルをログに記録
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
モデルのトレーニングとロギングのプロセスを確認したので、これらを1つの train.py ファイル。最終的な内容は train.py ファイルは次のようになります。
train.py
# 両方の関数に必要なインポート文
def train(kernel, n_quantiles):
...
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
...
regressor, model, X_test, y_test = train(kernel="linear", n_quantiles=100)
save_model_metadata(regressor, model, X_test, y_test, ml_repo="YOUR ML REPO NAME")
これでモデルのトレーニングとロギングのコードは完成です。次に、モデルトレーニングのコードをジョブとしてデプロイする必要があります。 deploy.py には、上記のモデルトレーニングコードをデプロイするためのコードが以下のように含まれています。
deploy.py
from servicefoundry import Build, Job, PythonBuild, LocalSource
# ジョブの仕様を定義
job = Job(
name="diabetes-train-job",
image=Build(
build_spec=PythonBuild(command="python train.py", requirements_path="requirements.txt"),
build_source=LocalSource(local_build=False)
),
)
deployment = job.deploy(workspace_fqn="YOUR WORKSPACE FQN HERE")
` requirements.txt `には以下のパッケージを含める必要があります。
requirements.txt
pandas==1.3.5
scikit-learn==1.2.1
mlfoundry>=0.7.2,<0.8.0
上記の deploy.py コードでは、呼び出された際に学習済みモデルの精度スコアをログに表示し、学習済み機械学習モデルもログに記録するジョブがデプロイされます。このジョブオブジェクトは、 servicefoundry.Job クラスを使用して作成されます。ジョブ名は diabetes-train-job とされています。
注: 「YOUR ML REPO NAME」をMLリポジトリ名に置き換えてください。 train.py と「YOUR WORKSPACE FQN HERE」をご自身のワークスペースFQNに置き換えてください。 deploy.py ファイルで。
train.py ファイルで、 作成したMLリポジトリの名前を save_model_metadata() 関数に渡す必要があります。 deploy.py ファイルでは、 作成したワークスペースのFQNを job.deploy() 関数に渡す必要があります。次に、ジョブをデプロイするために以下のコマンドを実行してください。
python deploy.py
トレーニングジョブをデプロイした後、「Deployments」セクションの「Jobs」サブセクションに移動すると、以下のように表示されるはずです。
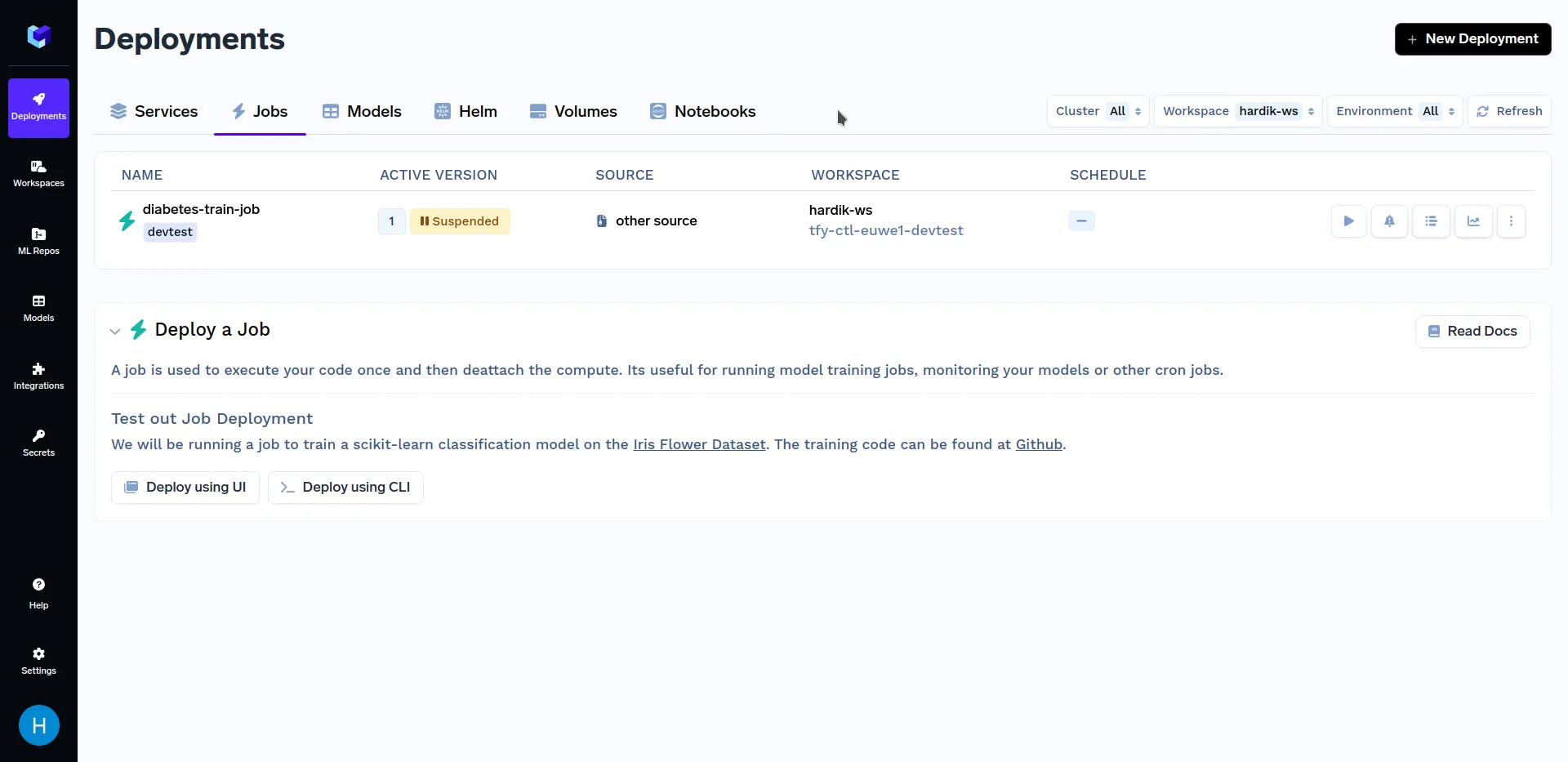
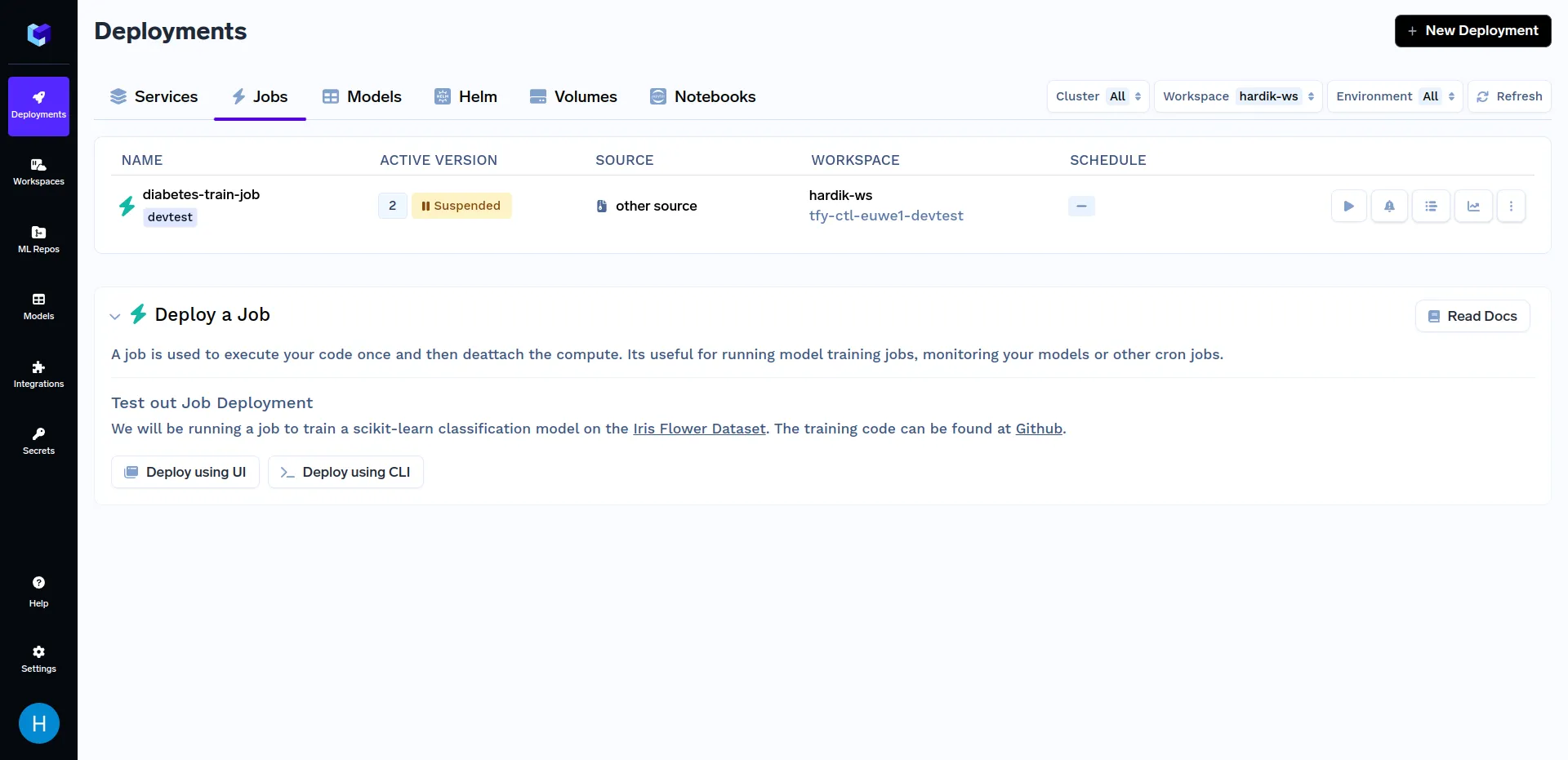
ジョブのデプロイが完了したので、次はジョブをトリガーします。これは、弊社のどちらかの方法で実行できます。 Python SDK or the TrueFoundry Dashboard. Firstly, we will talk about triggering jobs from TrueFoundry Dashboard. To know about other methods of triggering jobs, refer to the Triggering Jobs from Python SDK section.
After the above training job has finished deploying, go to the "Jobs" sub-section in the "Deployments" section, click on the "diabetes-train-job", and click on the "Run Job" to configure the job before triggering. It should look similar to this:
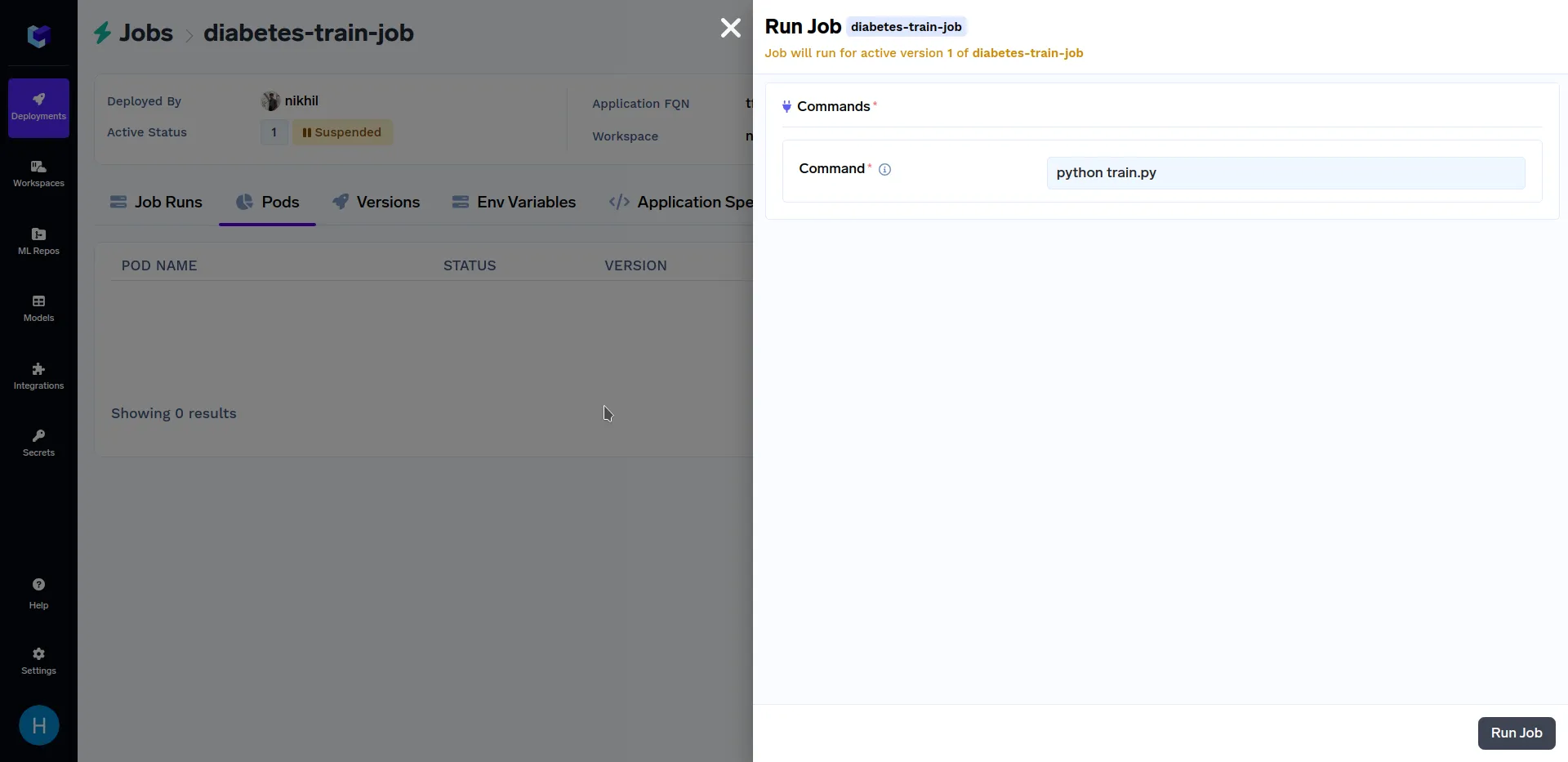
When at the above screen, click on "Run Job" at the bottom right corner to trigger this job. After the training job has finished running, go to the "Jobs" sub-section in the "Deployments" section, and click on the "diabetes-train-job", it should look similar to this:
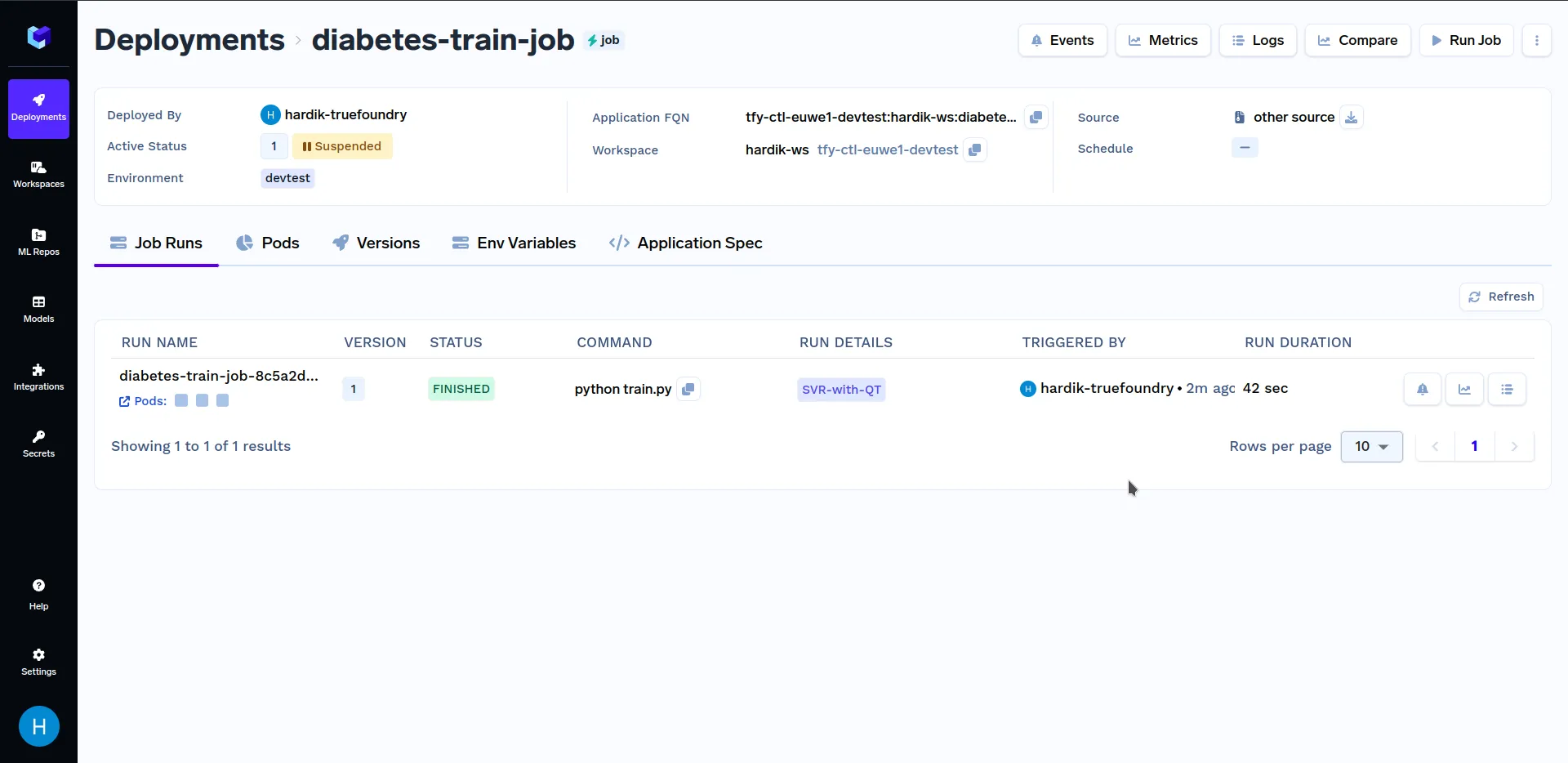
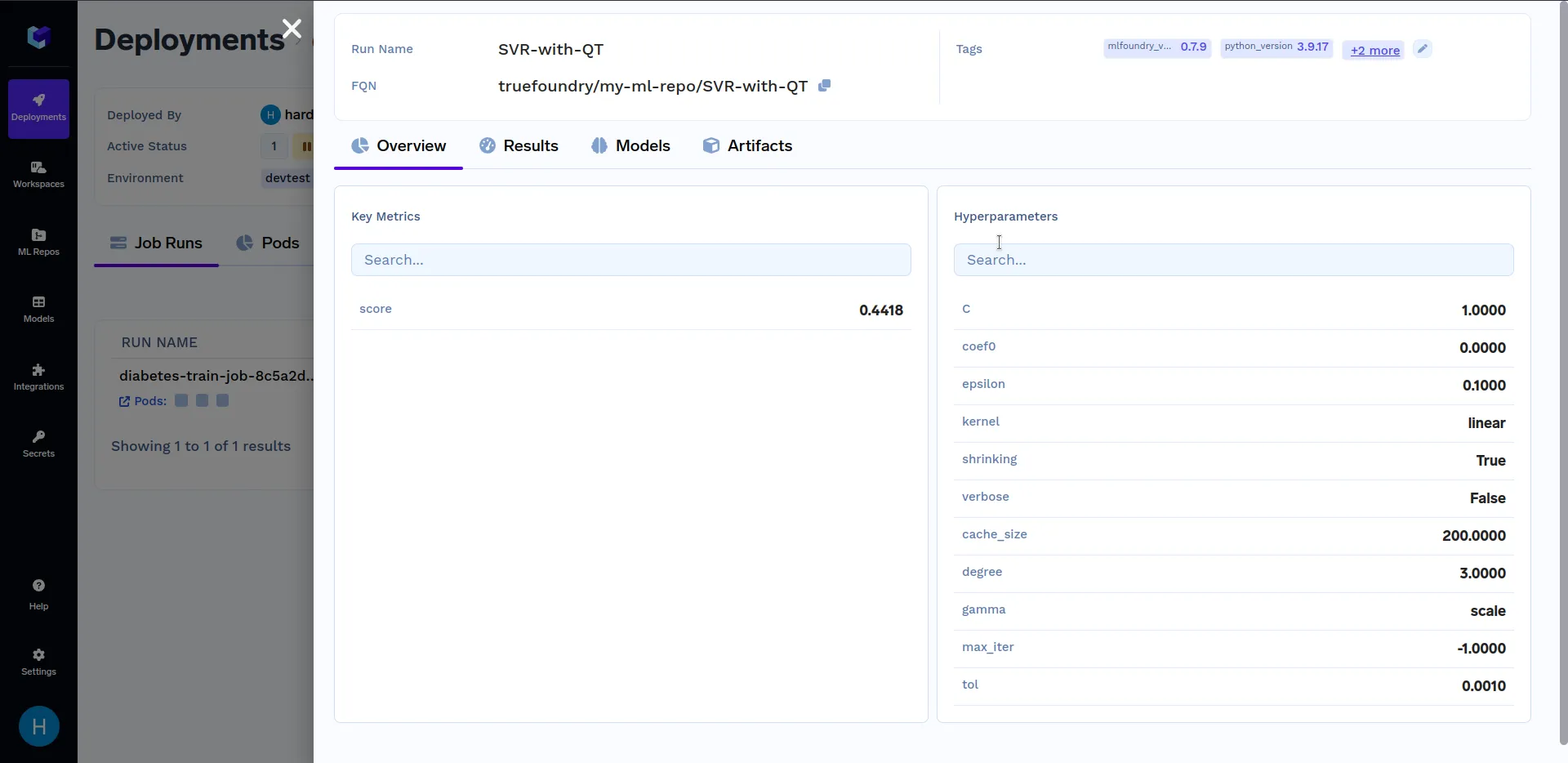
Under "Run Details", click on "SVR-with-QT" to see key metrics and hyperparameters that were logged in the train.py file. It should look similar to this:
Imagine that you have large-scale data processing or batch processing tasks where running a single job with different configurations is essential to not only streamline your workflow but also ensure consistency in job execution. In such cases, a Parameterized job will come in handy.
A Parameterized Job is a type of job that allows you to create multiple instances (pods) with different parameters or inputs. The primary goal of a Parameterized Job is to provide flexibility in job execution by customizing its behavior for different scenarios.
As an example, a job with command as python main.py --n_quantiles {{n_quantiles}} is a parameterized job as it takes n_quantiles as input before running. We can simplify the job deployed above using parameters.
To parse the command-line arguments, we will use the argparse module. The following code shows the updated code for the train.py and deploy.py files, where the default values of kernel and n_quantiles are linear and 100 respectively:
train.py
import os, argparse
def train(kernel, n_quantiles):
...
def log_model(regressor, model, X_test, y_test, ml_repo):
...
parser = argparse.ArgumentParser()
parser.add_argument("--kernel", default="linear", type=str)
parser.add_argument("--n_quantiles", default=100, type=int)
args = parser.parse_args()
regressor, model, X_test, y_test = train(kernel=args.kernel, n_quantiles=args.n_quantiles)
log_model(regressor, model, X_test, y_test, ml_repo=os.environ.get("ML_REPO_NAME"))
deploy.py
import argparse
from servicefoundry import Build, Job, PythonBuild, Param, LocalSource
parser = argparse.ArgumentParser()
parser.add_argument("--workspace_fqn", type=str, required=True)
parser.add_argument("--ml_repo", type=str, required=True)
args = parser.parse_args()
cmd = "python train.py --kernel {{kernel}} --n_quantiles {{n_quantiles}}"
# Defining the job specifications
# Only the command changes in 'image' attribute
job = Job(
...
image=Build(build_spec=PythonBuild(command=cmd, ...), ...),
params=[
Param(name="n_quantiles", default='100'),
Param(name="kernel", default='linear', description="svm kernel"),
],
env={ "ML_REPO_NAME": args.ml_repo }
)
deployment = job.deploy(workspace_fqn=args.workspace_fqn)
NOTE: Make sure you replace "YOUR ML REPO NAME" with your ML Repo Name and "YOUR WORKSPACE FQN HERE" with your workspace FQN in the below command.
Now execute the following command to deploy the parameterized job:
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
Alternatively, you can execute directly from our Github repository.
git clone https://github.com/truefoundry/truefoundry-examples.git
cd training-job-example
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
Version 2 of the Job will be created after deployment has finished. After the training job has finished deploying, the next step is to trigger this job.
Click on the "diabetes-train-job", and click on the "Run Job" to configure the job before triggering. You can now change the n_quantiles and kernel parameters. It should look similar to this:
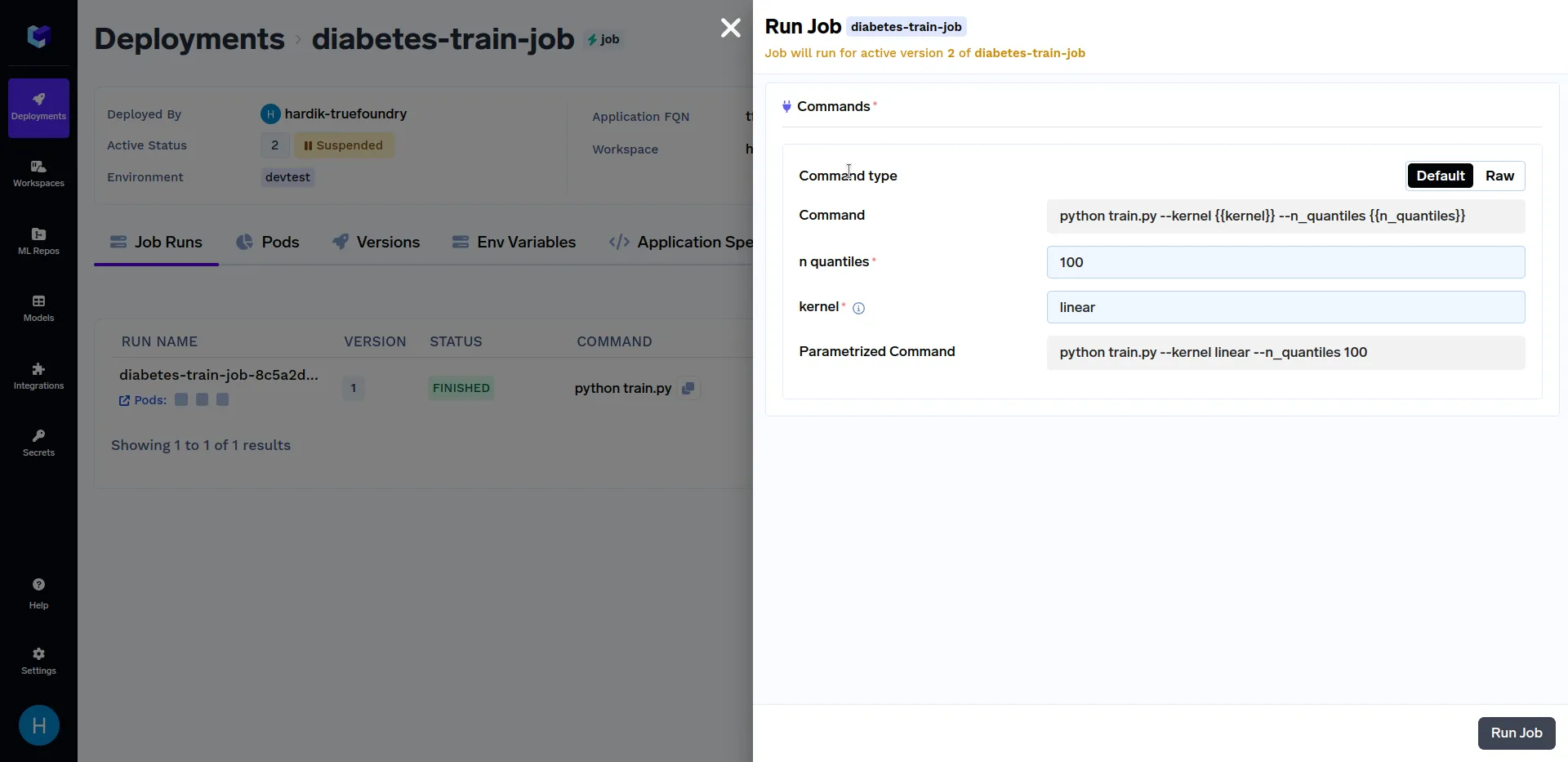
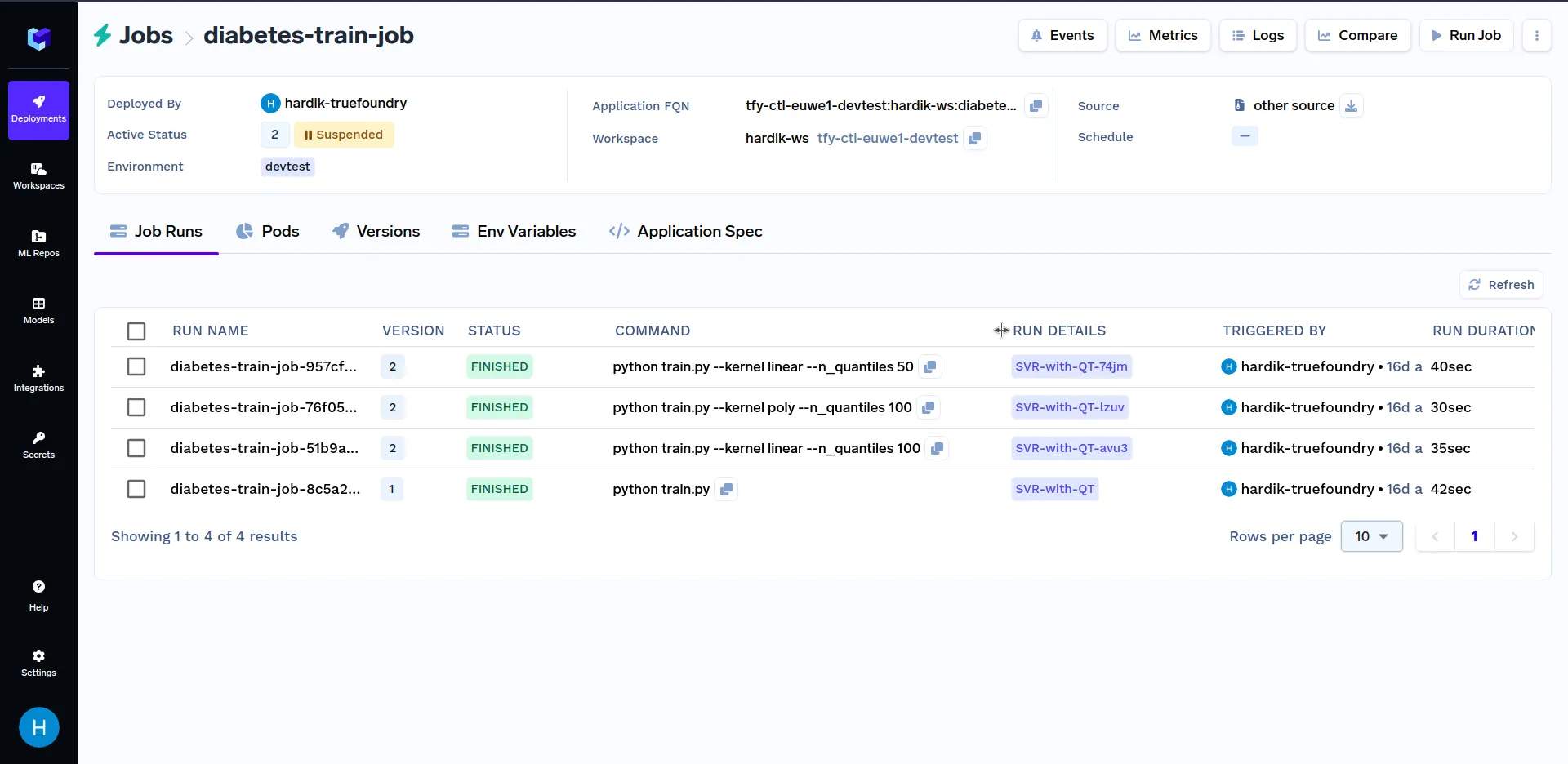
Try triggering job runs with different values of the カーネル パラメータ、例えば リニア、 シグモイド、 ポリ および RBF。同様に、異なる値の n_quantiles パラメータ(例:50、80、100など)を使用できます。様々なジョブ実行は、次のようになります。
ダッシュボードの右上にある比較ボタンをクリックすることで、異なるジョブ実行のメトリクスを比較できます。以下に示すとおりです。
パラメータ化されたジョブデプロイメントについては、こちらで詳細をご覧いただけます。
これまでは、からのジョブ実行のトリガーのみを見てきました。 TrueFoundryダッシュボード。しかし、 トリガー ジョブの は 必ずしも UI経由で望ましいとは限りません。そのため、ここでは、〜を介してプログラムでジョブをトリガーする方法について説明します。 Python SDK。
ジョブをプログラムでトリガーするには、 trigger_job 関数を以下のように使用します。
from servicefoundry import Job, trigger_job
# Configure a Job Deployment
job = Job(...)
# Deploy a Job
job_deployment = job.deploy(workspace_fqn="YOUR WORKSPACE FQN")
# Trigger/Run a Job
trigger_job(
application_fqn=job_deployment.application_fqn,
params={"n_quantiles":"80"}
)
を取得することも可能です。 application_fqn は、ダッシュボードから簡単に取得できます。Deployments --> Jobs に移動し、ワークスペースでジョブ名を探してください(例: diabetes-train-job)。
以下に、プログラムでジョブをトリガーする別の例を示します。まず、 YOUR_APPLICATION_FQN を Application FQN の 上記でデプロイされたジョブ に置き換えてください。以下のコードに示されている Application FQN は、アプリケーションのものです。以下にハイライト表示されています。
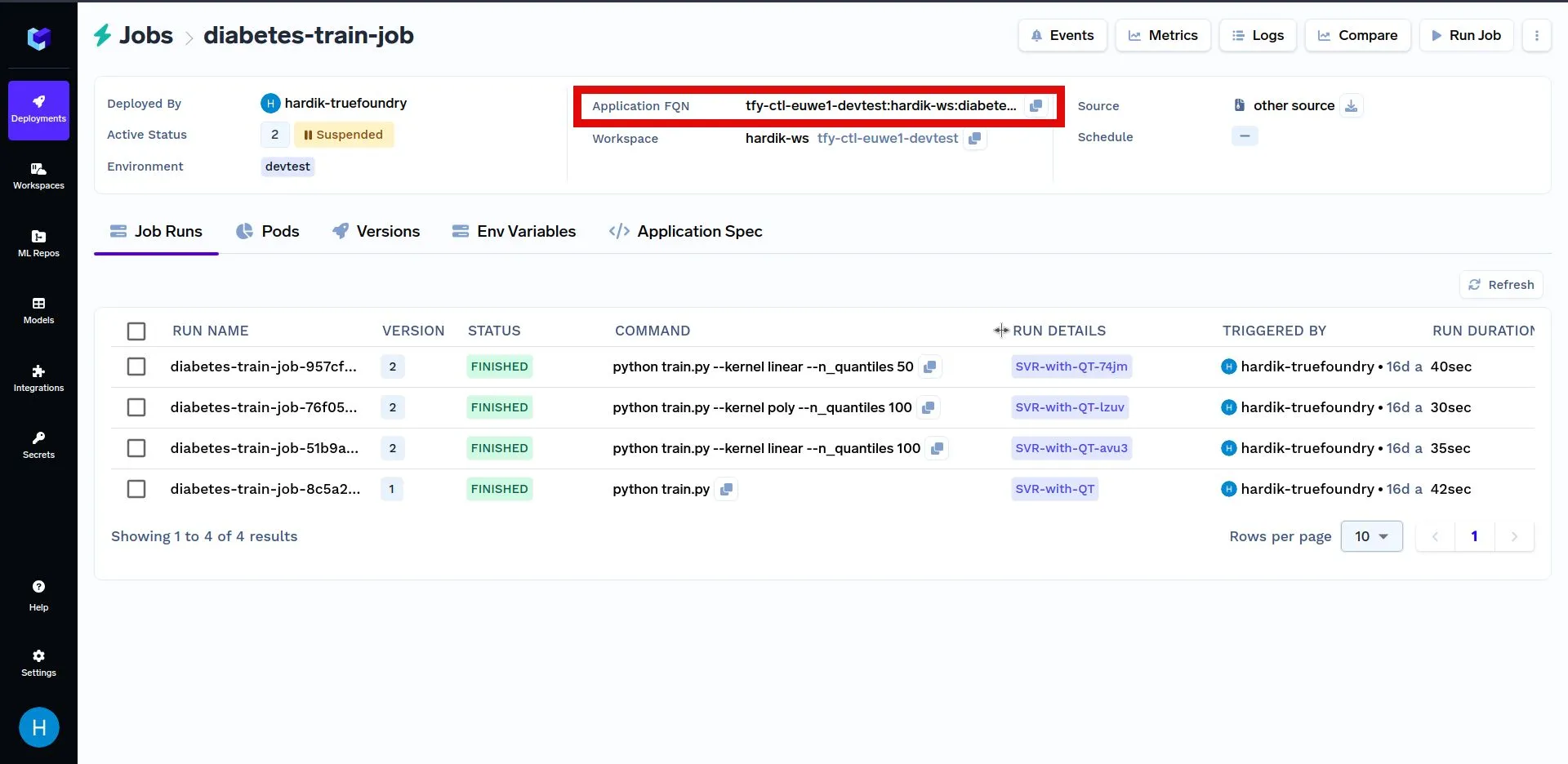
以下のコードでは、モデルパラメータの値をランダムに選択し、そのパラメータを使用してジョブ実行をトリガーしています。その後、ジョブ実行を検索して、最大の スコアを持つ実行を見つけます。最大スコアのジョブ実行は、より最適なモデルパラメータの選択を示します。
import random
import mlfoundry as mlf
from servicefoundry import trigger_job
# デプロイされたジョブを見つけ、ジョブのアプリケーションFQNに置き換えてください。
application_fqn = "YOUR_APPLICATION_FQN"
# パラメータをランダムに生成
n_quantiles = random.randint(50, 100)
kernel_values = ['linear', 'sigmoid', 'poly', 'rbf']
kernel = kernel_values[random.randrange(0, len(kernel_values))]
# ジョブをトリガー/実行
triggered_job = trigger_job(
application_fqn=application_fqn,
params={
"n_quantiles": str(n_quantiles),
"kernel": kernel
}
)
print(f'Triggered job run with n_quantiles={n_quantiles} and kernel={kernel} and name as', triggered_job.jobRunName)
client = mlf.get_client()
ml_repo_name = "YOUR ML REPO NAME HERE"
runs = client.search_runs(ml_repo=ml_repo_name)
max_score = 0
for run in runs:
metrics = run.get_metrics()
print(f'{run.run_name}"という名前の実行のすべてのメトリクス:', metrics)
if 'score' in metrics:
max_score = max(max_score, metrics['score'][0].value)
print("モデルの最大スコア: ", max_score)
注記: 以下のコマンドで「YOUR ML REPO NAME HERE」をあなたのMLリポジトリ名に、「YOUR WORKSPACE FQN HERE」をあなたのワークスペースFQNに置き換えてください。
ジョブのトリガーについてはこちらをご覧ください:
異なるジョブ実行のメトリクスをプログラムで比較するには、 mlfoundry.search_runs 関数を、以下のコードで示すように使用します。
import mlfoundry as mlf
client = mlf.get_client()
ml_repo_name = "YOUR-ML-REPO-NAME"
# すべての実行を返します
runs = client.search_runs(ml_repo=ml_repo_name)
# ログに記録された精度メトリックが0.7より大きい実行のサブセットを検索
filter_string = "metrics.score > 0.7"
runs = client.search_runs(ml_repo=ml_repo_name, filter_string=filter_string)
search_runs 関数については、 search_runs こちらをご覧ください。
数百万、数十億ものパラメータを持つ大規模モデルを扱うことを想像してみてください。このようなモデルを従来のCPUでトレーニングすると、非常に時間がかかり、メモリの制約により実現不可能になることさえあります。
例えば、CIFAR-10データセットに基づいたCNNモデルをCPU環境で10エポックトレーニングすると36分31秒かかりますが、同じモデルをGPU(NVIDIA K80)環境でトレーニングすると、わずか4分6秒でした。これは9倍の改善です( こちら参照)。
GPUは大規模モデルのトレーニングにおいて極めて重要な役割を果たします。GPUは、大規模なモデルサイズと複雑なアーキテクチャを効率的に処理するために必要なメモリ帯域幅と並列処理能力を提供します。ここでは、ジョブでGPUを使用する方法について説明します。
上記の例でGPUを使用するには、deploy.py ファイルでジョブを構成する方法にわずかな変更が必要です。 deploy.py 以下のコードは、GPU利用とカスタムCPUおよびメモリリソース割り当てのための更新された Job 構成を示しています。
deploy.py
from servicefoundry import Job, NodeSelector, GPUType, Resources
job = Job(
resources=Resources(
# GPUを設定
gpu_count=1,
node=NodeSelector(gpu_type=GPUType.T4)
# (オプション) CPUとメモリリソースを設定
cpu_request=0.2,
cpu_limit=0.5,
memory_request=128,
memory_limit=512,
),
...
)
注: コードの残りの部分は変更されません
これまでに、いくつかのジョブデプロイオプションを見てきました。例えば、 イメージ, params、および env。高度なオプションを使用してジョブをカスタマイズする方法はいくつかあります。その一部を以下に示します。
TrueFoundryダッシュボードまたはPython SDKを介して手動でトリガーできるジョブについて説明しました。しかし、ジョブをスケジュール(cronジョブなど)で実行したい場合はどうでしょうか?
cronジョブは、定義されたジョブを繰り返しスケジュールで実行します。これは、モデルを定期的に再トレーニングしたり、レポートを生成したりするのに役立ちます。このようなジョブは、その トリガー タイプを次のように変更することで実装できます。
from servicefoundry import Job, Schedule
job = Job(
trigger=Schedule(
schedule="0 8 1 * *",
concurrency_policy="Forbid" # Values: ["Forbid","Allow", "Replace"]
),
concurrency_limit=3,
...
)
cronジョブの場合、スケジュールされた時間のために、ジョブの以前の実行が完了していないにもかかわらず、すでにジョブを再度実行する時間になっている可能性があります。このような場合、 concurrency_policy 以下の通りです。
禁止: これがデフォルトです。。同時実行は許可しません。許可: ジョブの同時実行を許可します。オプションとして、同時実行するジョブの最大数は、 concurrency_limit を希望の値に設定することで変更できます。 置き換え: 現在のジョブを新しいジョブに置き換えます。同時実行は手動でトリガーされたジョブには適用されません。その場合、常に新しいジョブ実行が作成されます。
ジョブのステータスには、以下の3種類があります。 FINISHED、 TERMINATED、および FAILED。ジョブは、失敗時に複数回リトライするように設定できます。
ジョブは 失敗 とマークされます。これは、設定されたリトライ回数を経ても正常に完了しない場合です。 リトライ は、ジョブに対して次のように設定できます。
from servicefoundry import Job
job = Job(
retries=6, # default = 1
...
)
特定のユースケースでは、ジョブの実行を継続する最大時間を指定する必要がある場合があります。
timeout を使用すると、ジョブが失敗したかどうかにかかわらず、実行される最大時間(秒単位)を指定できます。これは、 retries の制限よりも優先されます。デフォルトでは、これは 1000 秒に設定されています。
例えば、もしあなたが再試行回数 を 6 および タイムアウト が 480 秒に設定されている場合、ジョブは実行を試みた回数にかかわらず、480秒後に終了します。
from servicefoundry import Job
job = Job(
timeout=480,
...
)
このブログで説明したジョブデプロイオプション以外にも、本ブログでは触れないものがいくつかあります。例えば、
.... その他にもいくつかあります。弊社の ドキュメント を以下にご参照ください。上記の質問への回答がわかります :)
弊社の公開リポジトリ truefoundry-examples には、このブログのジョブのソースコードが含まれており、以下のような様々な例も紹介しています。 LLMファインチューニング、 ノートブック入門、 エンドツーエンドの例 など、TrueFoundryプラットフォームが提供する機能の幅広い活用例をご覧いただけます。
まとめると、TrueFoundryのジョブは、スケーラブルで、フォールトトレラントかつリソース効率の高い方法でトレーニングタスクを管理・実行するための強力なフレームワークを提供します。
これらにより、機械学習ワークロードの実行を分散・制御し、その進捗を監視し、トレーニングモデルが効果的かつ確実に学習されるようにすることができます。そのため、単発またはオンデマンドのタスクを実行するのに理想的です。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


