Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
True ML Talks #1 - Machine Learning Workflow @ Gong
Today, TrueFoundry is launching a Machine Learning Deep Dive Series where we talk to ML and Data Science Leaders across Companies using ML to dive into the usecases and workflows of ML within their organizations. As part of this series, we will be hosting and diving deeper into the ML Stack of companies like Gong, StichFix, SalesForce, Gusto, Simpl, and many more.
📌
In this series, we delve into the World of Machine Learning to unveil the Spectrum of ML Applications and Infrastructure Setups Across Industries.
Our conversations will revolve around four key themes: 1. Machine Learning usecases for the business 2. How have they built their Machine Learning stack including Training and Experimentation Pipeline, Deployment and Serving, Monitoring and optimized them for Cost/Latency along the way 3. Challenges faced in the build-out of ML stack with specific challenges that come pertaining to the industry 4. An overview of cutting-edge innovations applied during the process of building and scaling ML infrastructure.
To kick off the first discussion of the series, we talked to Noam Lotner from Gong. Gong is a Revenue Intelligence platform. It enables Revenue teams to realize their fullest potential by unveiling the customer reality from the conversations of the revenue team. Gong analyzes the customer-facing interactions across phone, email, web, etc., to deliver the best insights for the revenue teams so that they can use that to close more deals.
Noam Lotner is Research Operations Team Lead at Gong. He is building the operational platform for the AI/ML research group - automating model release processes, experiment management, and performance tests, building labeling and dataset creation tools, and enabling secure access to production data sources.
Check our conversation below:
Machine Learning Use Cases and WorkFlow @Gong
Why is ML Important to Gong: A Sales Intelligence Platform
Gong analyzes customer-facing interactions across phone, email, web, etc. Machine Learning becomes all the more essential to analyze sales interactions and provide insights to Revenue Teams. ML algorithms can automate tasks that were previously done manually, such as analysis of video calls, transcribing, and analyzing sales phone calls. This saves time and improves the efficiency of the sales process.
Video Call analysis Pipeline → In order to analyze calls, the team processes the video, classifies the frames, and does some processing on certain types of video segments.
Audio Transcript Analysis Pipeline → The voice actually gets automatic transcription along with another pipeline that involves quite a few models, checking where the speech is, detecting which speaker talks when along with the content of the conversation.
Text NLP-Based Pipeline → There is a pipeline to extract information from the slides and call notes. For emails, a different pipeline of NLP processing, messaging, and comments is used.
How are these Models segmented across Customers
While this is a question we asked Gong, we see that invariably all SaaS companies:
Models that are common to all customer: There are some models like the ASR Models, that do automatic recognition of speech. This help in standardized service and maintaining consistency across the platform
Models that are unique to each customer: In the case of SaaS startups, especially in the case of a sales intelligence platform like Gong, each model has to be unique. This is done to ensure data privacy and security as well as offer customization or personalization by training the model on the customer's dataset. This comes with two challenges: serving and data privacy. Since Gong allows customers to do training on the models based on their own data, they have to expose ML Interfaces on their platform, and hence the segregation of data for each customer becomes a challenge.
📌
Number of models: Number of Customers X Models Types
📌
"We use the same base model for everyone. We also let the customers actually do training for specific models for their own content."
In order to optimize costs, Gong uses multi-model serving in the inference layer, as running separate models in separate machines would mean a high-cost system.
Here is a detailed blog from Gong that talks about the use of ML in B2B sales
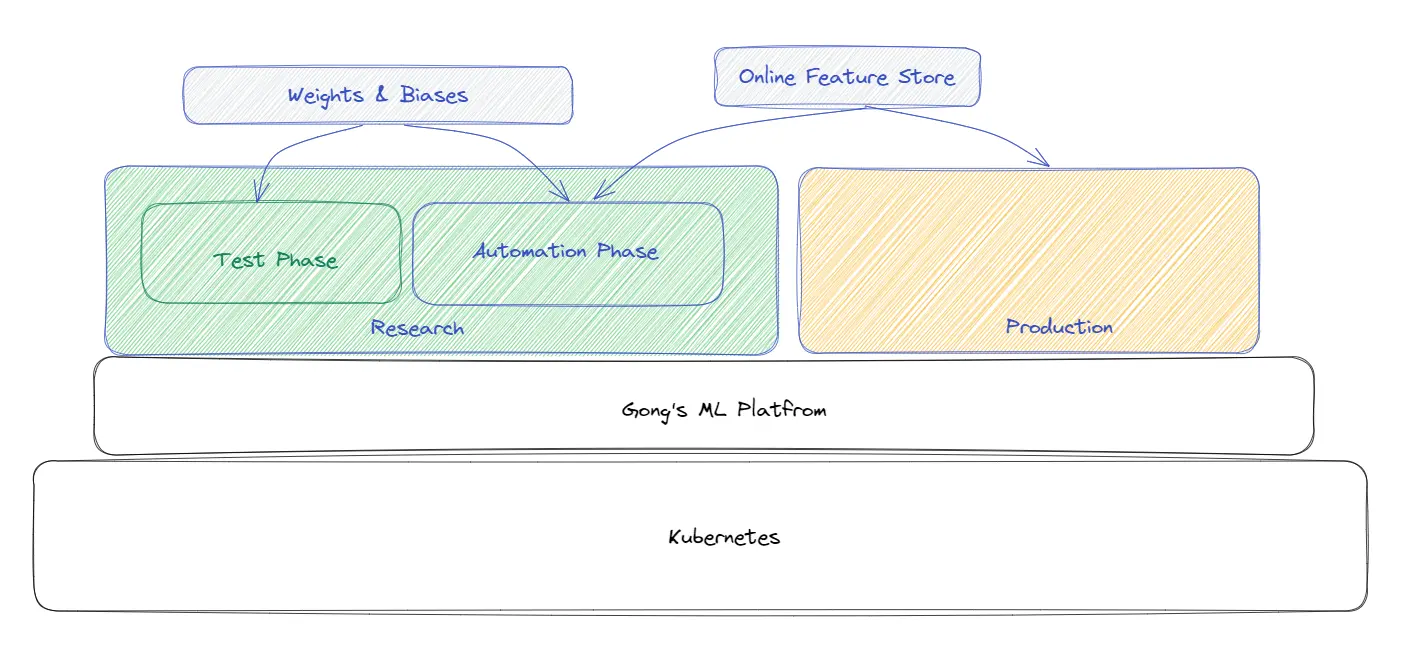
At Gong, the ML system is structured as per the ML org.
Research: There is a separate environment for research. The team works separately - get the data, do the training, finish the training, release the model, and then the model gets sent to the deployment pipeline, handled by engineering.
Production Deployment (part of Engineering): The trained model is deployed to production by the Engineering team.
In this blog (as well as chat series), we will dive more into the challenges of Research Side infra for Gong
How is the ML Researcher Workflow set up at Gong?
Machine Learning System Workflow at Gong
Basic Test Phase: Researchers take data and train on their own machines or using VMs by pulling data from Production to their Machine
Automation Phase: Once the model is finalised, an automatic pipeline is created for processing the data for getting the big amount of data into the researcher's hand.
To enable researchers to spin up machines easily, the entire stack is set up on top of Kubernetes for the Research Infra. Most of the models in the research team are not using online features.
Cloud: The majority of the infrastructure is on AWS and also work with other cloud vendors in a somewhat smaller capacity.
Managing infrastructure: the pipelines are actually running the models specifically for each customer. There's a machine that comes up and handles all the calls of that company
Other Challenges that make ML a complex Problem to solve at Gong
Cost: We also covered it above, cost is a major challenge for Gong as huge amount of data is required to train and then re-train the model. The speech datasets are very large (a few hundred hours of speech translates to a few hundred gigabytes of data). NLP datasets are smaller in size, but they can be of many rows. Since the research is separated from production, it allows the research team to be flexible with the amount of data to use in model training. The research team is doing work to enable optimize the amount of data to be used in training.
Simplifying ML Platform: One important aspect of simplifying the process is to actually hide the complexity of selecting the type of data to use for training with the right access control behind the tools.
It's done differently for different data sources. In the case of large number of databases (each holding a different type of information, and each is accessible differently), a lot of work is done in creating pipelines that are secure and that only let authorized people use data and create a log of who accessed the data and for what purpose. It also includes allowing researchers to mix and match results from different data sources.
Data Security & Privacy: One of the main concerns for Gong is security and privacy i.e. making sure there are no leaks and making sure no one who has no authority can access the data, and no customer gets the data from another customer. This is very complicated owing to a large amount of data.
How Gong solved it: Storing the data in secure locations and having each data point annotated, and having access rights, according to customer tenant ID. Accessed is controlled credential mechanisms, and everything that can be automated is automated
Ensuring there’s no way 1 customer’s data feeds into another model - While using a large language model, it is possible to infer something from one customer, and another customer gets the private information. This is something that needs to be taken into account.
Automatic Retraining is not easy: Re-training is done only when there is really well-versed method of doing all of the pipeline stages. It is very rare. Retraining efforts depend on the type of model e.g. in the case of speech recognition model for a specific language, it is pretty easy to do re-training with the same parameters on new data. Data refresh also changes a lot of the content and also necessitates actually having a researcher do some research again in order to make sure that the new model is actually performing better than what we had before.
Additional Thoughts from Noam
Kubernetes is the way to Go
Everything that is done in the Research team is now being moved to Kubernetes. A part of Noam's work is helping his team get access to resources automatically from the Kubernetes cloud. It is presently an ongoing effort.
📌
"I would recommend to anyone who is getting into this, that really early on in your journey, you need to think of scale and you need think to how your group is going to work"
"I think most MLOps systems require Kubernetes for managing the resources. I don't see any platform in the future that can do anything related to MLOps without using Kubernetes"
Few important things to note:
Scale to Zero is really important in terms of cost management. It is a huge cost dent to have machines that are up and not doing nothing.
The system needs to be agile to handle security and privacy issues efficiently. The data needs to stay where it is and you need to bring your code there.
MLOps: Build vs Buy
📌
"My perspective is that at Gong needed to build this platform"
While building, start on Kubernetes, which is a scalable and flexible platform.
Configure all systems so that you are ready for tenant separation and ready for applying GDPR, and if someone wants to delete the data, you need to delete the data.
Thinking about scale really early is very important. Make your infrastructure agile and flexible, make sure you have scaling capabilities, and you can deploy and fire up as many machines as you want when you need them. But have them taken down as soon as their idol.
Security, Security, Security
Nothing can be more for a SaaS company than security. ML pipeline must prioritize security due to data privacy while handling sensitive data of customers as well as to control unauthorized access.
Hope the 1st Blog series in the TrueML Talks was able to give you valuable insights around how you can think of building your Machine Learning Research Infrastructure to power your ML Teams. #MLOps #MachineLearning #DataScience #DevOps #ModelOps #AIInfrastructure
Read our new blogs in the series
Head to our second episode of the TrueML talks where we talk with Platform Lead at Stitch. Keep watching the TrueML youtube series and find all the episodes of the TrueML blog series here -
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
































.png)

.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




