













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
ほとんどの企業AIプログラムにおいて、サードパーティAPIにデータを送信できないワークロードが発生する瞬間があります。規制対象のデータセット、主権要件、あるいは大規模運用で恐ろしいほど高騰したコスト曲線などです。その答えは、自社で運用するオープンウェイトモデルです。チームがそれを嫌がる理由はモデル自体ではなく、セルフホスティングが通常、第二の異なるスタックを意味するからです。商用APIを中心に構築されたプラットフォームに、OpenAI以外のAPI、サービングレイヤー、GPU運用などが追加される形です。この記事では、ゲートウェイがどのようにしてこの問題を解決し、セルフホストされたLlamaやMistralを、既存の商用モデルと並行して簡単に導入できるようにするかを説明します。
MLプラットフォームエンジニアのラビは、 予想していたリクエストを受け取りました。新しいワークロードが、ポリシー上、会社のクラウドから外に出せないレコードを処理するというものでした。商用APIは選択肢になりませんでした。自社のVPCで動作するオープンウェイトモデルが明白な解決策でした。しかし、ラビは少しがっかりしました。なぜなら、それを必要とするアプリケーションはOpenAI API向けに書かれており、チームにはサービングスタックがなく、彼はすでに、第二のSDK、第二のダッシュボード、そして誰も解決していないGPUオートスケーリング問題という並行世界を想像できたからです。モデルの選択は簡単な決断でした。その周りのスタックこそが懸念事項だったのです。
ラビの状況を一変させたのは、セルフホストモデルが全く異なるスタックである必要はないと気づいたことでした。もしそれが商用モデルと同じゲートウェイの背後にあり、同じOpenAI互換APIを話すのであれば、アプリケーションにとっては単なる別のモデル名に過ぎず、プラットフォームにとっては同じルールで管理されるもう一つのエンドポイントとなるからです。アーキテクチャを分岐させることなく、主権要件が満たされました。この記事では、それがどのように機能するのか、そして真のエンジニアリングがどこに存在するのかを説明します。
オープンウェイトモデルのセルフホスティングは、品質が理由となることは稀です。最先端のAPIは優れており、常に改善されています。それは、他の4つの理由によるものです。 主権: 法的に、または契約上、一部のデータが自社の環境外に出せない場合。これは、自社のVPCまたはオンプレミスで動作するモデルによって、構造的に満たされます。 大規模運用時のコスト: 一定の安定したボリュームを超えると、償却済みのGPUは、特に高スループットで予測可能なワークロードにおいて、トークンあたりの価格を下回ることができます。 制御: モデルのバージョンを選択でき、独自のデータでファインチューニングが可能で、プロバイダーがモデルを非推奨にしたり、変更したりすることに左右されません。 可用性: 推論パスがモデルAPIプロバイダーの稼働時間に直接依存しなくなります。ただし、今度は自社のインフラストラクチャとデプロイメントサプライチェーンに依存することになります。
正直なところ、その代償として、GPU容量、サービングスタック、スケーリング、信頼性といった推論運用を自社で管理することになります。これらは商用APIが完全に隠蔽してくれる作業です。セルフホスティングは、これら4つの要因のいずれかが現実的で、運用コストが抑えられる場合に価値があります。ほとんどの企業はハイブリッドな運用に行き着きます。一般的なトラフィックには商用APIを、主権要件がある場合や大量のトラフィックにはセルフホストモデルを使用します。目標は一方を他方に置き換えることではなく、すべてを二重に運用することなく両方を実行することです。
カスタマイズは、そのリストから特に切り離して考えるべきです。なぜなら、チームがオープンウェイトモデルに傾倒する主な要因となることが多いからです。商用APIは、誰かが皆のためにトレーニングしたモデルを提供しますが、オープンウェイトモデルは、どこにも送信できない、あるいは送信したくないデータでファインチューニングすることで、自社のドメイン、フォーマット、トーン、エッジケースに適応させることができます。狭く反復的なタスクの場合、より小さなファインチューニングされたオープンモデルは、はるかに大きな汎用モデルに匹敵するか、それを上回り、サービングコストも大幅に削減できます。これにより、カスタマイズの要因がコストの要因に再び組み込まれます。ただし、ファインチューニングには独自のパイプラインが必要です。データ準備、トレーニング実行、評価、バージョン管理、そして他のモデルと同様に結果をサービングする作業です。TrueFoundryは、ノーコードおよびフルコードのファインチューニングをサービングスタックと連携してサポートしているため、チューニングされたモデルは、手動で運用する必要がある別のアーティファクトになるのではなく、他のすべてと同じゲートウェイエンドポイントの背後に配置されます。重要なのは、ファインチューニングが常に価値があるわけではないということです。多くの場合そうではなく、強力なプロンプトを持つ優れたベースモデルが勝つこともよくあります。しかし、価値がある場合、ウェイトを所有していることがそれを可能にするのです。
この決定において、後ではなく事前に考慮すべき注意点が一つあります。オープンウェイトだからといって、義務がないわけではありません。セルフホストまたはファインチューニングを行う前に、モデルのライセンス、許容利用ポリシー、再配布条件、帰属表示要件、および規制対象または商用利用に関する制限を必ず確認してください。一部の人気のあるオープンウェイトモデルには、企業規模で重要となる利用しきい値や利用分野の制限があります。ライセンスの確認は、モデルがすでに本番稼働した後で発見される脚注ではなく、デプロイメントチェックリストの一部として扱ってください。
Raviの懸念はもっともでした。なぜなら、セルフホスティングの素朴な方法は、まさにその「第二のスタック」を生み出すからです。オープンウェイトモデルは独自のAPI形状を公開するため、アプリケーションにはそれに対応するコードパスが必要です。また、独自の運用面を持つサービングエンジンが必要です。ステートレスなウェブサービスのスケールとは全く異なる振る舞いをするGPUオートスケーリングも必要です。そして、商用APIのダッシュボードでは見えないため、独自の可観測性も必要となります。これをいくつかのモデルに適用すると、既存のプラットフォームとは異なることだけが目的の並行プラットフォームができてしまいます。
この問題を解決する洞察は、その違いのほとんどがアプリケーションやプラットフォームの制御インターフェースに到達する必要がないということです。サービングエンジンとGPUスケーリングは現実的で避けられないものであり、セルフホスティングの真の作業です。しかし、APIの形状、ルーティング、ガバナンス、可観測性は、同じゲートウェイを前面に配置することで、商用パスと同一にすることができます。この記事の残りの部分では、本質的な違い(サービング、GPU)と付随的な違い(ゲートウェイが吸収できるすべて)を区別します。
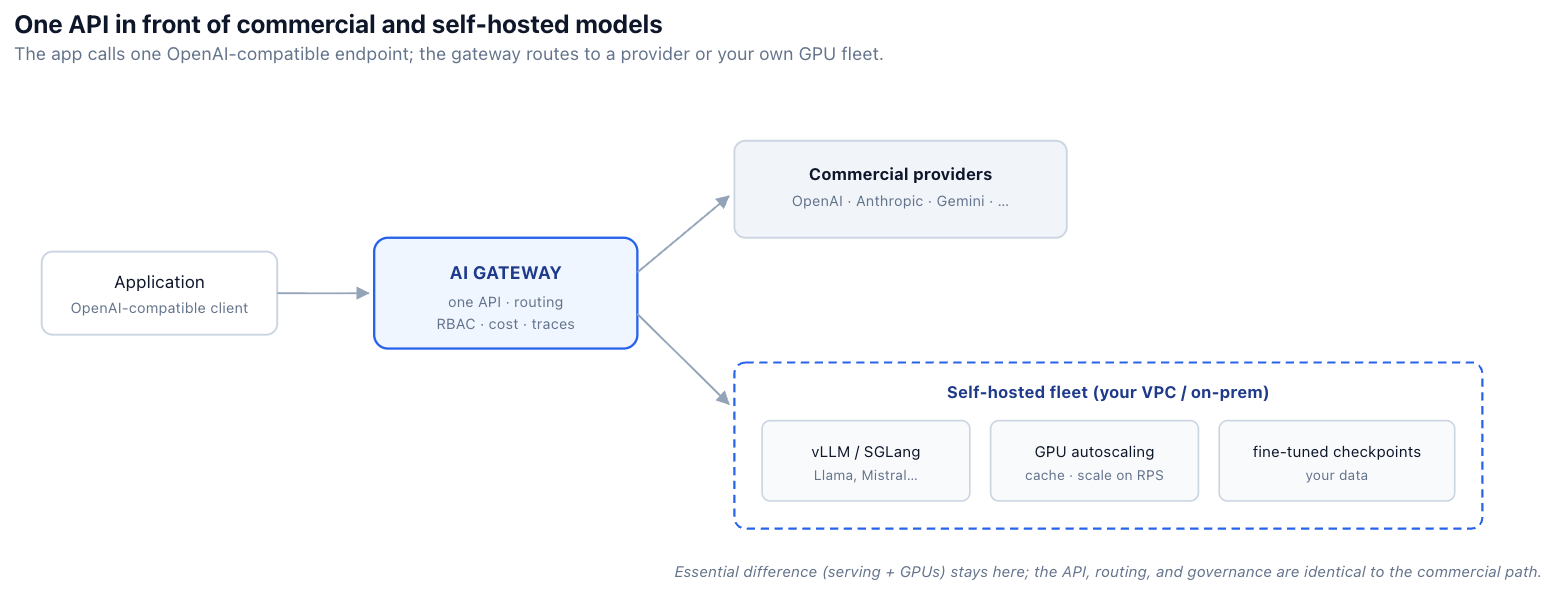
セルフホスティングを容易にするのは、アプリケーションが既に利用しているOpenAI互換APIを通じて、セルフホスト型モデルを公開することです。セルフホスト型のLlamaが商用モデルと同じリクエスト形式に応答する場合、それらの切り替えはコード変更ではなく設定変更で済みます。そして、ルーティング、フォールバック、RBAC、予算、トレーシングはすべて一貫して適用されます。なぜなら、ゲートウェイの視点から見れば、それは同じインターフェースの背後にある単なる別のモデルだからです。
同じクライアント、同じ呼び出し — モデル名だけが変わります(イメージ)
# Commercial model:
client.chat.completions.create(model="commercial-chat-model", messages=msgs)
# Self-hosted open-weight model — same API, same code, different name:
client.chat.completions.create(model="llama-3-70b-internal", messages=msgs)
# The gateway resolves the name to a commercial provider or your GPU fleet,
# and applies the same routing, RBAC, budgets, and tracing either way.これは、当社の ルーティングに関する記事 で扱っているのと同じ統合であり、セルフホスト型ケースに適用されます。つまり、アプリケーションはモデルが物理的にどこで実行されているかから切り離されます。Raviの規制対象ワークロードはセルフホスト型モデル名を指し、彼のプラットフォームの他のすべては変更なく機能し続けます。TrueFoundryのAI Gatewayは、セルフホスト型モデルとサードパーティモデルの両方にとって、まさにこの中心的なインターフェースとなるように構築されています。
ここが、真にあなたが管理すべき違いです。オープンウェイトモデルはそれ自体ではサービスを提供しません。推論エンジン内で実行され、選択するエンジンがスループット、レイテンシー、メモリ効率に大きく影響します。vLLMは、高スループットのために連続バッチ処理とページド・アテンションを普及させました。SGLangは構造化された高並行性ワークロードに強く、TGIは成熟した広く展開されているサーバーです。TRT-LLM(Triton)はNVIDIA GPUでハードウェア固有の性能を最大限に引き出します。どれも万能ではありません。
重要なのはベンチマークです。実際のモデルを、実際のシーケンス長と並行性で、候補となるエンジンとGPU上で実行し、評判ではなく数値に基づいて選択することです。TrueFoundryの LLMデプロイメントのドキュメント では、vLLM、SGLang、TRT-LLMがサポートされているモデルサーバーとして挙げられており(TGIとTritonはゲートウェイのセルフホスト型バックエンドに含まれます)、プラットフォームは特定のモデルに対して適切なGPU構成を自動的に選択することを目指しています。これにより、「どのエンジンと何台のGPUを使うか」という問いは、研究プロジェクトから、独自のベンチマークで検証する選択肢へと変わります。エンジンは本質的な複雑さですが、その選択と運用を日常的なものにすることが目標です。
セルフホスト型LLMのオートスケーリングは、ウェブサービスのオートスケーリングとは異なります。その頑固な理由の一つは、重みが非常に大きいことです。数ギガバイトから100ギガバイト以上にもなります。レプリカを追加するたびに100GBのモデルをダウンロードするような単純なオートスケーラーでは、新しいPodが単一のトークンを提供するまでに数分間と多大なネットワークコストを費やし、トラフィックスパイク時のスケールアップはほとんど役に立ちません。コールドスタートは、セルフホスト型推論における決定的な運用上の問題です。
解決策は地味ながらも決定的なものです。モデルキャッシングは、重みを一度ダウンロードしてすべてのPodにマウントするため、新しいレプリカは新規ダウンロードではなくローカルコピーから起動します。イメージストリーミングは、コールドプルよりもはるかに高速にサービングイメージをプルします。共有モデルボリュームは、各イメージから重みを完全に分離します。これらを組み合わせることで、コールドスタートを「すべてをゼロからダウンロードする」状態から、RPSベースのオートスケーリングが需要に追従できるほど高速なスケールアップパスへと移行させることができます。ただし、実際の起動時間は、モデルサイズ、ストレージクラス、レジストリの場所、ノードのウォームアップ状態、GPUスケジューリングに依然として依存します。TrueFoundryの ドキュメント では、モデルキャッシング(重みを一度ダウンロードしてすべてのPodにマウント)、vLLMおよびSGLangイメージのプルを著しく高速化するイメージストリーミング、そしてまさにこの理由のための共有ボリュームについて説明しています。これこそが、機能するオートスケーリングと理論上のオートスケーリングとの違いです。
セルフホスティングは、サプライチェーンの責任もあなたに近づけます。重み、サービングイメージ、およびそれらの依存関係は、あなたが所有し、提供する成果物となります。動的なタグを追跡するのではなく、モデルとイメージのバージョンを固定し、ソースが提供する場合はチェックサムや署名を検証し、誰がモデルのチェックポイントやサービングイメージをあなたのレジストリに公開できるかを管理し、他の本番コンテナと同様にそれらのイメージをスキャンし、エンジンと重みの両方についてロールバックパスを確保してください。ゲートウェイは誰がモデルを呼び出せるかを管理しますが、これはその背後で実際に何が実行されているかを管理する規律です。
ガバナンスされたデプロイメントとしてのセルフホスト型モデル(設定例)
name: llama-3-70b-internal
model: meta-llama/Llama-3-70B # from Hugging Face / private registry
server: vllm # or sglang / tgi / trt-llm — benchmark first
gpu: { type: H100, count: 2 }
cache: shared_volume # download once, mount to all pods
autoscaling:
metric: rps # scale on requests/sec
min_replicas: 1
max_replicas: 8
scale_to_zero_after: 30m # idle policy — release GPUs when unused
セルフホスティングは、商用APIがほとんど隠している最適化、つまりリクエストがGPUにどのようにマッピングされるかを制御する機能をもたらします。モデルがシーケンスを処理する際、アテンション計算のキーバリューキャッシュを構築します。次のリクエストがプレフィックス(同じシステムプロンプト、これまでの会話など)を共有している場合、それを同じGPUインスタンスにルーティングすることで、エンジンはそのキャッシュされた計算を再計算する代わりに再利用できます。これにより、プレフィックスが多いトラフィックにおいてレイテンシを大幅に削減できます。
その利点を享受するには、プレフィックス認識型のスティッキールーティングが必要です。ゲートウェイは、共有プレフィックスを持つリクエストをラウンドロビンで分散させるのではなく、同じインスタンスにルーティングします。TrueFoundryの ドキュメント はまさにこれを説明しています。KVキャッシュ最適化を活用するために、同じプレフィックスを持つリクエストを同じGPUマシンに送信するスティッキールーティングです。これは、当社のゲートウェイレベルのセマンティックキャッシングにおける、セルフホスト型GPUレベルの類似機能と言えます。 キャッシングに関する記事。一方はサービングエンジン内で計算を再利用し、もう一方はゲートウェイで応答全体を再利用します。会話型または共有システムプロンプトのワークロードでは、この2つが相乗効果を発揮します。
セルフホスト型モデルと商用モデルが1つのAPIの背後で稼働するようになると、本シリーズの以前の回で説明したルーティングと信頼性のメカニズムが、フリート全体に一度に適用されます。ポリシーに基づいて主権的なワークロードをセルフホスト型モデルにルーティングしたり、一般的なトラフィックを商用APIに送信したりできます。そして、決定的に重要なこととして、境界を越えてフォールバックすることも可能です。例えば、スパイク時にセルフホスト型フリートが飽和状態になった場合、キューに入れるのではなく商用モデルにバーストさせ、プロバイダーに障害が発生した場合はセルフホスト型モデルにフェイルオーバーできます。
セルフホスト型と商用を1つのフリートとして扱うルーティング(図解)
routes:
- match: { tag: "regulated" } # sovereignty: must stay in-VPC
target: llama-3-70b-internal
fallback: [] # no commercial fallback for this class
- match: { tag: "general" }
target: llama-3-70b-internal # prefer self-hosted for cost
fallback: [commercial-chat-model] # burst to commercial under load/outageこれは ルーティング と フェイルオーバー に関するブログ11と12で説明した内容で、今や商用/セルフホスト型の境界をまたぐものですが、ポリシーで明示された1つの重要な制約があります。規制されたルートは 決して 商用プロバイダーにフォールバックしてはなりません。なぜなら、可用性が主権を上回ることは決してないからです。誰もがそれを覚えていると信頼するのではなく、ルールとして明文化することが、ゲートウェイが強制するために存在するガードレールの一種なのです。
一貫したテーマは、セルフホスティングが2種類の作業に明確に分かれるということです。本質的な種類、つまりサービングエンジンとGPUは実在し、このペアの次の記事ではその経済性について説明します。一方、付随的な種類、つまり異なるAPI、個別のルーティング、個別のガバナンス、個別の可観測性は、ゲートウェイがアプリケーションと、どこで実行されていようとすべてのモデルとの間の単一の境界となることで吸収されるものです。
ゲートウェイを導入すれば、セルフホスト型モデルは並行プラットフォームではなくなり、統制されたエンドポイントの一つとなります。OpenAI互換API、ルーティングとフォールバックルール、RBACと予算、トレースはすべて同じです。 トゥルーファウンドリー はまさにこの区分に基づいて構築されています。vLLM、SGLang、TGI、TRT-LLM上での高性能なサービングは、GPUとキャッシュ機構によって運用可能となり、AIゲートウェイによって前面に配置されることで、その結果はアップストリームのすべてにとって商用モデルと区別がつかないものとなります。ラヴィにとって、これは主権要件を満たすことと、そのためにプラットフォームを再構築することの違いです。
セルフホスティングは商用APIよりも安価ですか?
あるしきい値を超えれば、そうなることもあります。安定した大量の予測可能なトラフィックの場合、償却されたGPU(特に部分共有やスポット容量を利用した場合)は、トークンあたりの価格を下回ることができます。スパイク状のトラフィックや少量の場合、アイドル状態のGPUに料金を支払う必要がないため、通常は商用APIの方が安価です。正直な答えは、ご自身のトラフィック量をモデル化することです。これは、この投稿と対になるGPU経済学に関する投稿の主題でもあります。コストはセルフホストする4つの理由の1つであり、唯一の理由ではありません。
セルフホスト型モデルを使用するために、アプリケーションを書き直す必要がありますか?
モデルがOpenAI互換ゲートウェイによって前面に配置されている場合は、その必要はありません。アプリケーションは同じAPIを呼び出し続け、モデル名だけが変更されます。ゲートウェイはその名前をGPUフリートに解決し、商用モデルと同じルーティング、RBAC、トレースを適用します。重要なのは、アプリケーションがモデルがどこで実行されているかを知る必要も、気にする必要もないということです。
どのサービングエンジンを使用すべきですか?
ベンチマークで決定してください。普遍的な勝者はいません。ドキュメント化されているバックエンド(vLLM、SGLang、TRT-LLM、さらにKServeとTriton)は、スループット、レイテンシ、メモリ効率、機能サポートが異なり、適切な選択はモデル、シーケンス長、同時実行性によって異なります。候補となるバックエンドで実際のワークロードを実行し、測定された数値に基づいて選択してください。これらすべてをサポートするプラットフォームであれば、再設計することなく切り替えることができます。
最も難しい運用上の課題は何ですか?
コールドスタートです。LLMの重みは大きいため、レプリカごとにモデルを再ダウンロードするオートスケーラーでは、需要に追いつくのが遅すぎます。モデルキャッシュ、イメージストリーミング、共有ボリュームがスケーリングを実用的にします。これらにより、数分かかるコールドスタートが、RPSベースのオートスケーリングやスケール・トゥ・ゼロのアイドルポリシーが実際に機能するのに十分な速さに変わります。
セルフホスト型モデルと商用モデルを混在させることはできますか?
それが一般的な最終形態であり、1つのゲートウェイで両方を前面に配置することの強みです。主権要件のあるトラフィックや大量のトラフィックはセルフホスト型モデルに、一般的なトラフィックは商用APIにルーティングし、負荷や障害時には境界を越えてフェイルオーバーします。ただし、規制対象のルートは商用プロバイダーにフォールバックしてはならないという明確な例外があります。1つのフリート、1つのルールセット、2種類のバックエンドです。
ラヴィの主権問題は、決して2つ目のプラットフォームを必要としませんでした。特定の場所で1つのモデルを実行し、それ以外はすべて同じままであることを必要としたのです。それがゲートウェイがもたらすものです。主権、コスト、制御、または可用性が要求する場所にモデルを配置する自由を、アプリケーションとプラットフォームが常に一貫したインターフェースを見ることを可能にしながら提供します。サービングとGPUを所有してください。それらが本当の作業であり、残りはゲートウェイに任せましょう。
「Ravi」は例示です。TrueFoundryのサービングおよびゲートウェイ機能(サポートされる推論エンジン、モデルキャッシュ、画像ストリーミング、プレフィックス認識型スティッキールーティング、オートスケーリング)は、2026年半ば時点の公開製品ドキュメントから要約されており、今後変更される可能性があります。詳細については最新のドキュメントでご確認ください。セルフホスト型モデルと商用モデルのコスト比較は、お客様のボリュームとハードウェアに完全に依存するため、直接モデル化する必要があります。コードおよび設定サンプルは、文書化されたパターンを示すものであり、参照実装からコピーされたものではありません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


.webp)