Built for Speed: ~10ms Latency, Even Under Load Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed Production-ready with full enterprise support 機械学習(ML)や大規模言語モデル(LLM)のワークロードは、クラウドで実行すると非常にコストがかかることで知られています。これは、大量の計算能力、メモリ、ストレージを必要とするためです。しかし、スケーラビリティや信頼性を犠牲にすることなく、ML/LLMワークロードのクラウドコストを削減する方法があります。
コスト削減のための主要原則 DevOpsエンジニアと開発者のための可視性の向上: クラウドコストの可視性を確保することは、特に複数のクラウドにわたって複数のコンポーネントがデプロイされている場合、困難です。TrueFoundryは、クラスター、ワークスペース、デプロイメントレベルでクラウドコストの可視性を提供し、DevOpsチームと開発者がML/LLMライフサイクル全体でコスト削減の機会を特定し、最適化できるようにします。リソース調整の容易さ: TrueFoundryは、DevOpsチームと開発者が得られたコストの可視性に基づいて行動できるようにします。DevOpsチーム プロジェクトレベルでリソース制約を設定でき、各チームのワークロードが必要なリソースにアクセスできることを予算超過なしで保証します。開発者 得られたインサイトに基づいて、リソースを簡単に調整することもできます。さらに、TrueFoundryは非本番環境でアプリケーションやIDEをゼロにスケールダウンすることを容易にし、アイドル状態のリソースのコストを排除し、コスト削減のためのイテレーションサイクルをより効率的にします。コストのためのインフラ最適化: TrueFoundryのKubernetesベースのアーキテクチャとインフラ最適化は、クラウドコストを削減するように設計されています。 全体として、TrueFoundryのコスト削減機能は、DevOpsチームと開発者がML/LLMライフサイクル全体でクラウドコストを削減するために必要な可視性、制御、最適化機能を提供します。
AMIからDockerへの移行: 当社のプラットフォームは、多くの企業がAMIからDockerへ移行するのを容易にし、企業はすでに30〜40パーセントのコスト削減を経験しています。TrueFoundry:コストを最優先するプラットフォーム Truefoundryは コストを最優先する Kubernetesを基盤とするプラットフォームで、効率性、スケーラビリティ、コスト削減を最優先するアーキテクチャで設計されています。
TrueFoundry独自のアーキテクチャが、信頼性とスケーラビリティを最適化しながらコストを削減するのにどのように役立つかを見ていきましょう。プラットフォームの階層構造は以下の通りです。
クラスター: AWS EKS、Azure AKS、GCP GKE、またはオンプレミス環境のクラスターなど、すべてのクラスターをプラットフォームに接続します。これにより、すべてのクラスターを1か所でシームレスに統合できます。これらのクラスターは、幅広いサービス、モデル、ジョブをデプロイするための基盤となります。ワークスペース: クラスター内にワークスペースを導入します。これにより、アクセス制御と分離を合理的に追加し、各プロジェクトや環境が専用のリソースを持ち、不正アクセスから保護されるようにします。これらはデプロイメントのグループと考えることができます。デプロイメント: これらのワークスペース内にはデプロイメントがあり、さまざまな種類のものをデプロイできます。TrueFoundryを使用すると、ML開発ライフサイクルのあらゆる側面を簡単にカバーできます。インタラクティブ開発環境: 共同実験のためにJupyter NotebookとVS Codeをデプロイします。トレーニングおよびファインチューニングジョブ: ジョブとしてデプロイすることで、MLモデルのトレーニングやLLMモデルのファインチューニングを効率的に行います。事前学習済みLLM: モデルカタログを使用して、特定のユースケース向けに事前学習済み大規模言語モデルを迅速にデプロイします。サービスとアプリ: モデル、ウェブアプリなど、さまざまなサービスやアプリケーションをデプロイします。アプリケーションカタログ: Label Studio、Redis、Qdrantなどの人気ソフトウェアを簡単にデプロイできます。クラスターレベルでのコスト削減 Kubernetesベースのインフラストラクチャ Kubernetesは、ビンパッキングを利用してリソース使用率を最適化し、コンテナを効率的に配置することで、インフラコストの削減に貢献します。
TrueFoundryがKubernetesをどのように活用しているかについて、さらに詳しく知るには、こちらをご覧ください。 こちら . 💡
EC2からKubernetesへの移行:
マルチクラウド対応 TrueFoundryのマルチクラウドアーキテクチャにより、様々なクラウドプロバイダーへの接続が容易になります。
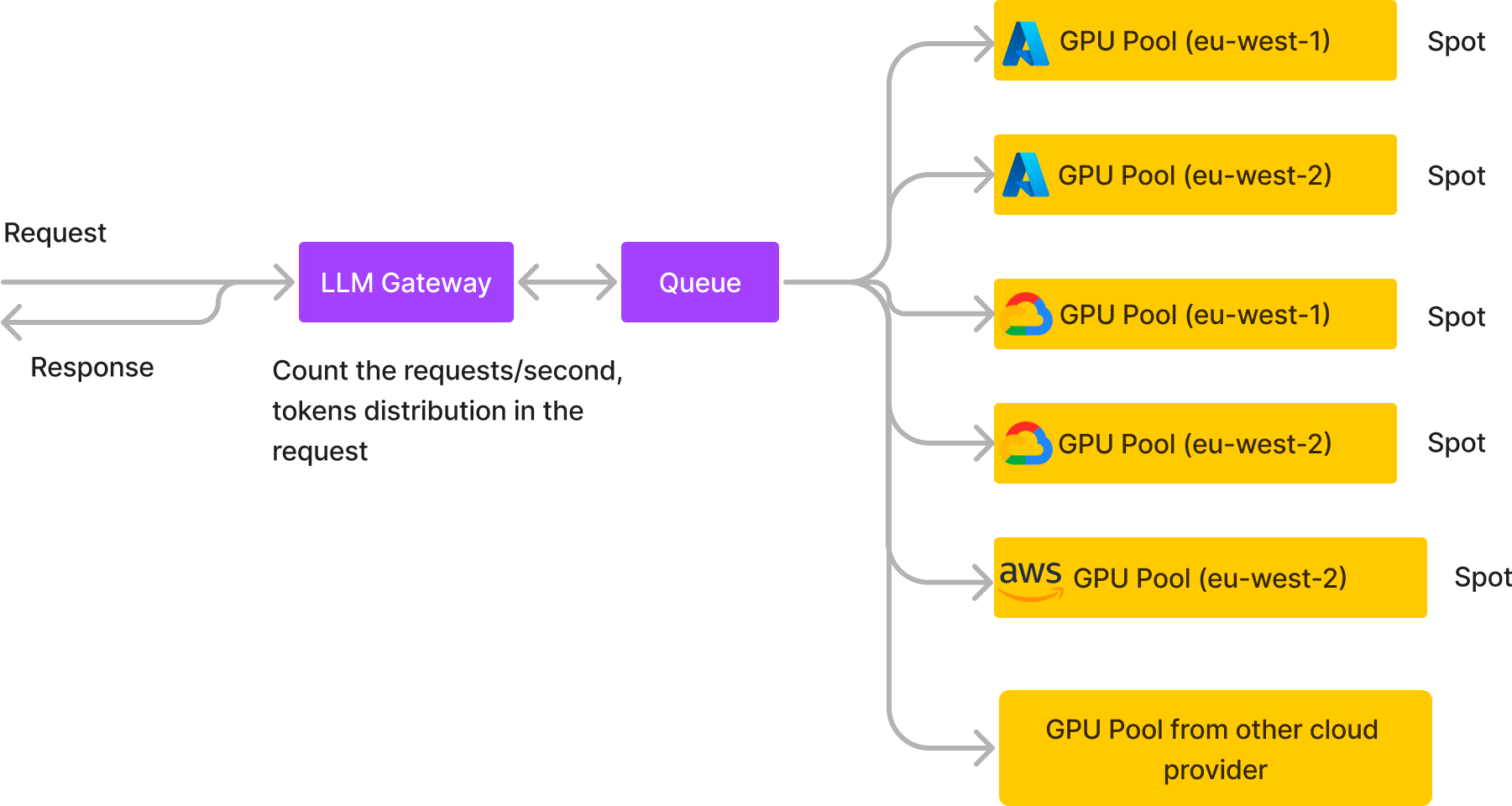
クラウド間の柔軟な切り替え クラウドとリージョンをまたいだワークロードの分散 高いインスタンスクォータの可用性 :複数のクラウドとリージョンにわたるLLMのスケーリング 💡
ユーザー数の多い(20+ RPS、1日あたり200万以上のリクエスト)中規模の会話型AIチャットボットプロバイダーが、当社の非同期サービスを利用し、異なるクラウドとリージョンにまたがる5つのクラスター上で、分散型スポットGPUインスタンスのみで稼働しています。これにより、インフラコストを60%削減しつつ、信頼性とスループットを向上させています。
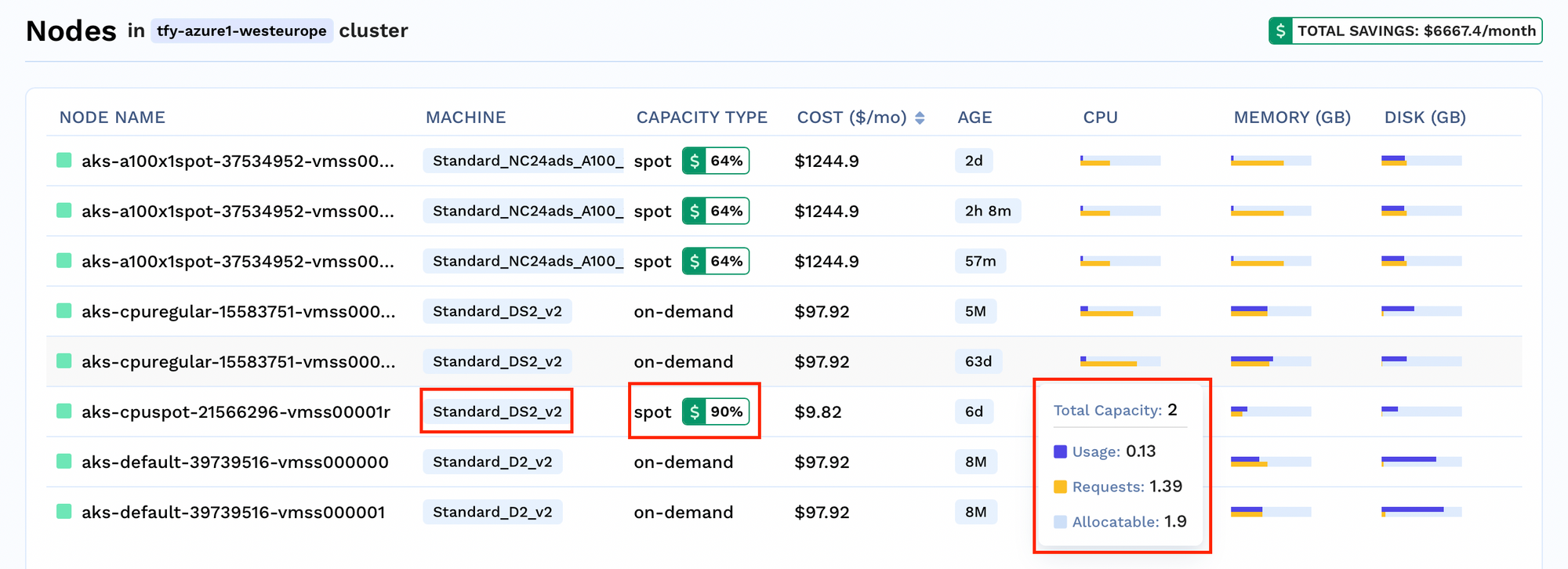
可視性の向上 各クラスターについて、クラスター内で稼働しているノードの数を確認できます。また、ノード固有の詳細情報として、以下のようなインサイトも得られます。
コスト削減分析 :リソース割り当てのインサイト: キャパシティタイプに関するインサイト :ワークスペースレベルでのコスト削減 リソース制限 TrueFoundryでは、1つのクラスター内に複数のワークスペースを作成できます。このセグメンテーションにより、異なるチームや環境向けにデプロイメントを整理できます。
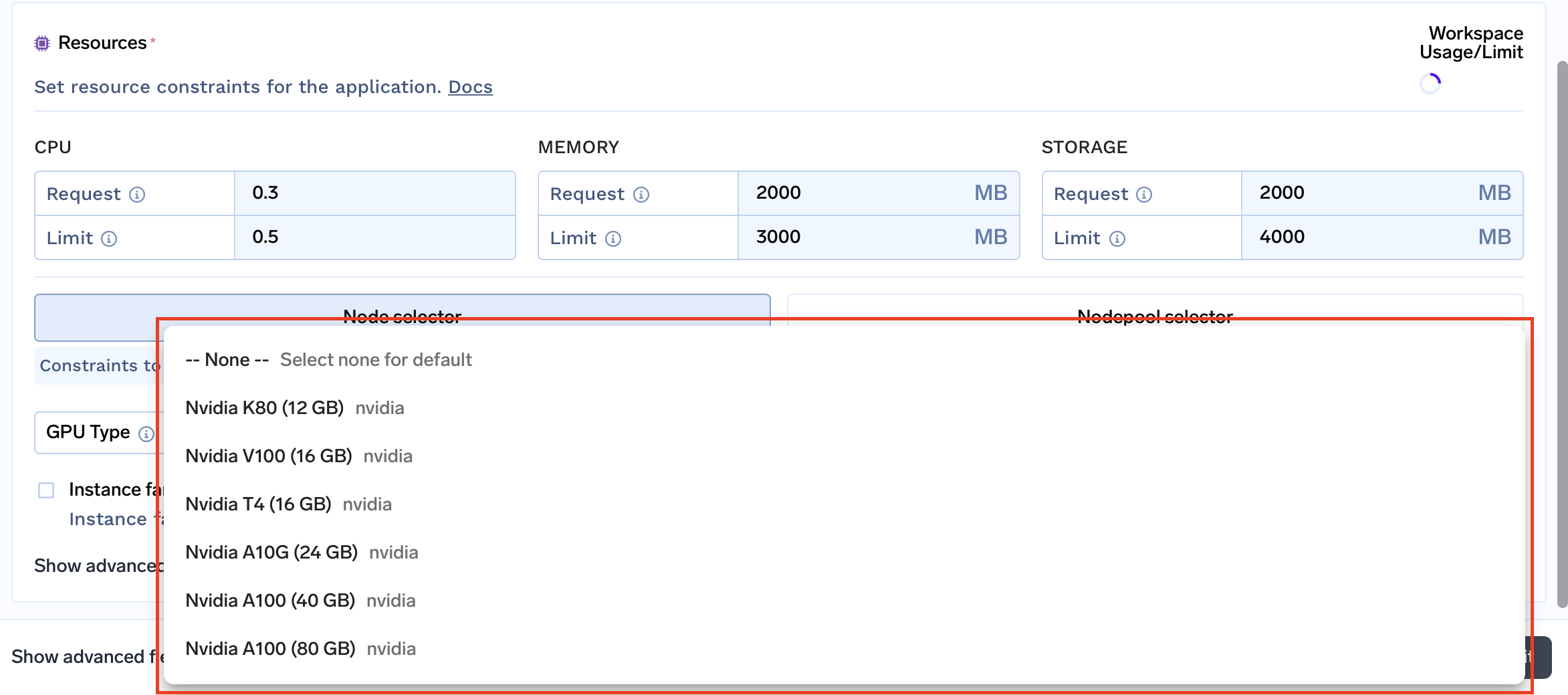
リソース制約 :サポートされているインスタンスファミリー :サポートされているノードプール :ワークスペースレベルのコストを追跡 過去の使用状況に基づいて、ワークスペースレベルのコストを追跡できる可視性も提供します。これにより、どのプロジェクトや環境が最も多くのリソースを使用しているか、どこでコスト削減が可能かを特定できます。
デプロイメントレベルでのコスト削減 アプリケーションレベルで高度な機能を提供し、大幅なコスト削減を実現できるよう支援します。
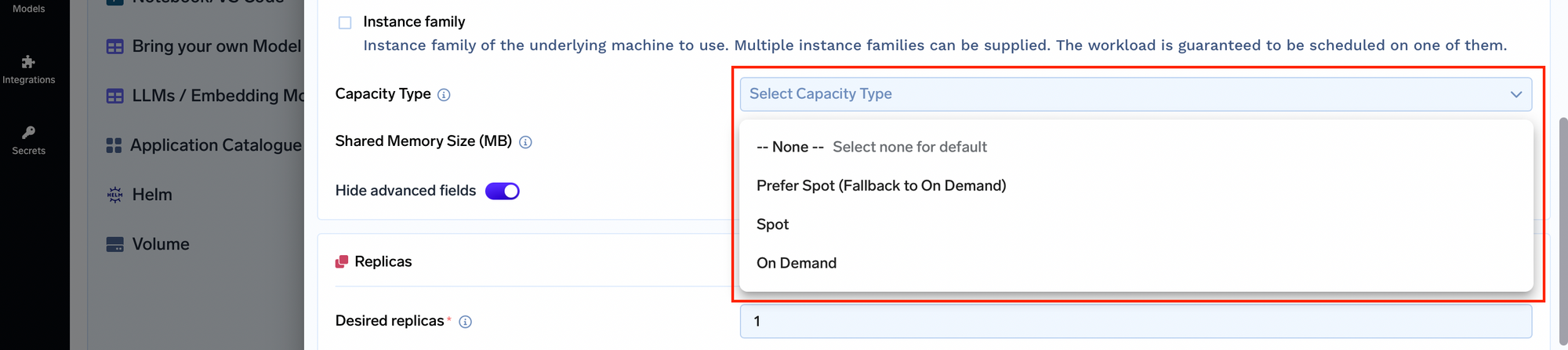
オンデマンドへのフォールバック付きスポットインスタンス : サービスの一時停止 :リソースの最適化 :リソースの監視 :動的なリソース調整 :時間ベースのオートスケーリング :💡
弊社のお客様の多くは、非稼働時間中にシャットダウンをスケジュールすることで、開発環境のクラウドコストを60%以上削減し、週あたり128時間のコンピューティング使用量を削減しています。
コードエディタレベルでのコスト削減 コードエディタ向けに特定の機能を提供しており、NotebookおよびVSCodeレベルで大幅なコスト削減を実現できます。
共有ボリューム :適応型リソース使用: 💡
ビデオ生成分野で事業を展開する生成AI企業は、非本番ワークロード向けに数百のJupyter Notebookをスポットインスタンスで実行しており、必要なときだけGPUをオンにすることで、クラウドコストを約50〜60%削減しました。
手動一時停止: 使用していないときにNotebook/VSCodeインスタンスを簡単に一時停止できます。コードとデータは保持されるため、必要なときにシームレスな再開が可能です。自動一時停止 :💡
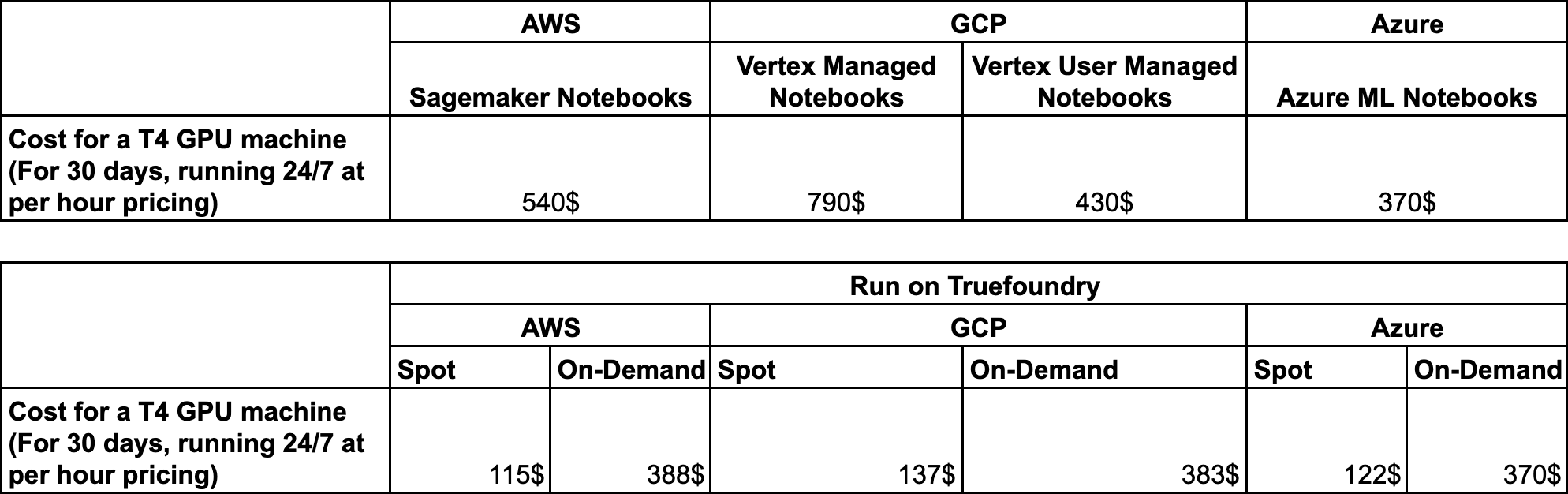
コストベンチマーク
Jupiter Notebooksのコストベンチマーク
大規模言語モデル(LLM)のデプロイとファインチューニングにおけるコスト削減: 当社のモデルカタログは、よく知られた事前学習済みLLMのデプロイとファインチューニングをワンストップで手軽に行えるようにします。これらのLLMのデプロイとファインチューニングを可能な限りコスト効率良く行うため、以下の対策を講じました:
モデルサービング構成の最適化 :効率的なファインチューニング構成 :こちらのブログで 効率的なファインチューニング:
非同期サポートによるスケーラブルなデプロイ: 非同期サポートを活用してLLMを大規模にデプロイすることで、3つのクラウドすべてでGPUクォータを最大限に活用し、ファインチューニングやデプロイに必要なGPUを確実に確保できます。この信頼性の向上により、スポットインスタンスの利用が可能になり、コスト削減につながります。詳細はこちら 非同期デプロイメントによるLLMの大規模デプロイ 💡
ベンチマーク
💡
複数のFortune 100企業や中堅企業が、当社のプラットフォームを利用することで大幅なコスト削減を実現しました。中には、社内のSageMakerやクラウドプラットフォームを当社のシステムに置き換え、30~40%のコスト削減を達成した企業もあります。
また、一連の記事では、多くの一般的なオープンソースLLMのパフォーマンスを、レイテンシー、コスト、1秒あたりのリクエスト数の観点からベンチマークしました。こちらでご確認いただけます。 TrueFoundryブログ
このブログで紹介した全機能のライブデモをご覧いただくために、こちらの動画もご覧いただけます。
VIDEO
TrueFoundry は、Kubernetes上で動作するMLデプロイメントPaaSであり、開発者のワークフローを加速させ、モデルのテストとデプロイにおいて完全な柔軟性を提供しつつ、インフラチームには完全なセキュリティと制御を保証します。当社のプラットフォームを通じて、機械学習チームは デプロイおよび監視 モデルを15分で、100%の信頼性、スケーラビリティ、そして数秒でのロールバック機能を提供し、これにより、コストを削減し、モデルをより迅速に本番環境にリリースすることで、真のビジネス価値の実現を可能にします。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Built for Speed: ~10ms Latency, Even Under Load

















































.webp)




.png)








.webp)
.webp)


