














November 13, 2025
|
5 min read

Published: March 30, 2026

Blazingly fast way to build, track and deploy your models!
The rise of Large Language Models (LLMs) has transformed AI capabilities—but fine-tuning these massive models remains a costly, resource-intensive challenge. Enter LoRA (Low-Rank Adaptation), a breakthrough technique that enables efficient fine-tuning of pre-trained models by drastically reducing the number of trainable parameters. Instead of updating the entire model, LoRA injects lightweight, trainable modules—making fine-tuning faster, cheaper, and more accessible. Whether you're building domain-specific LLMs or optimizing edge deployments, LoRA has become a go-to method in modern ML workflows. In this guide, we’ll break down what LoRA is, how it works, and why it’s changing the fine-tuning game.
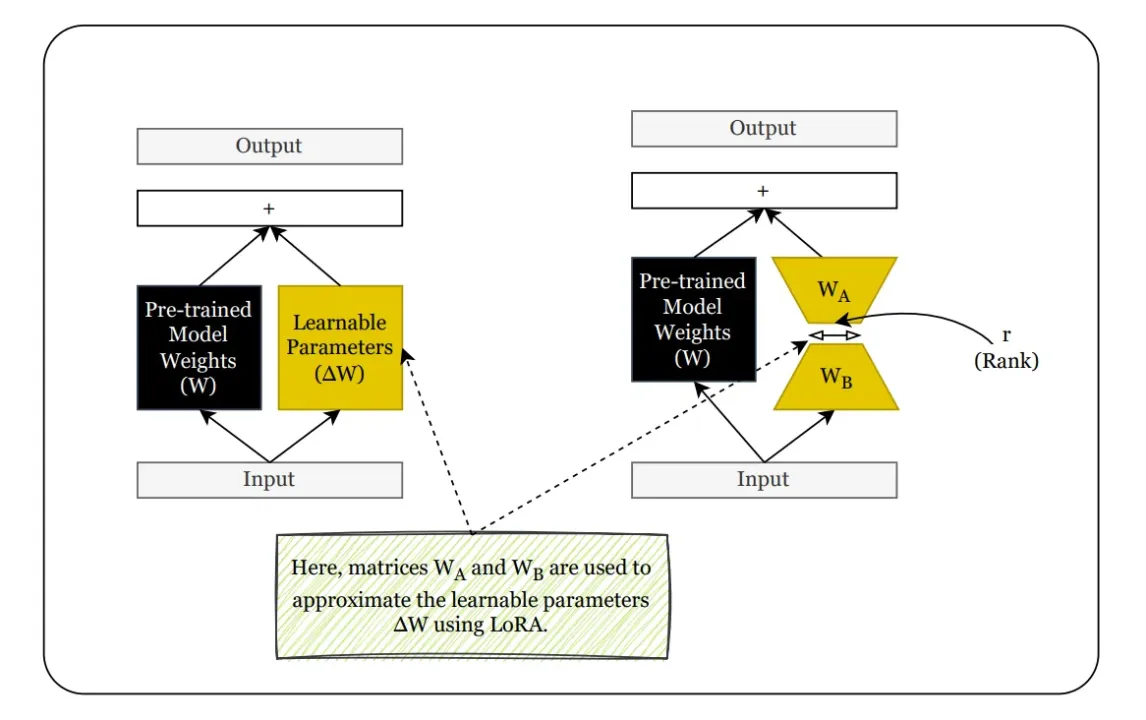
LoRA, short for Low-Rank Adaptation, is a parameter-efficient fine-tuning technique designed to adapt large pre-trained models without updating their full-weight matrices. Instead of modifying the original model parameters—which can number in the billions—LoRA introduces small trainable rank decomposition matrices into existing layers. These modules learn the fine-tuning task while the base model remains frozen.
The core idea behind LoRA is rooted in linear algebra. Instead of directly learning a large weight update matrix ΔW, LoRA approximates it as the product of two smaller matrices:
ΔW≈A⋅B
where A∈Rd×r and B∈Rr×k, with r≪min(d,k). This low-rank factorization drastically reduces the number of parameters that need to be trained, often by several orders of magnitude.
In practice, LoRA modules are inserted into specific layers of a transformer model (typically attention and feedforward layers). During training, only the LoRA parameters are updated, while the original model weights stay frozen. This makes LoRA not only efficient in terms of compute and memory usage but also modular—you can train different LoRA adapters for different tasks and swap them in and out as needed.
Originally introduced for NLP tasks, LoRA has since been adopted in vision models, speech recognition, and multi-modal architectures—demonstrating its versatility across domains.
LoRA fine-tuning is a method of adapting large pre-trained models—like BERT, GPT, or LLaMA—by training only a small number of additional parameters, rather than updating the entire model. It leverages the core principle of LoRA (Low-Rank Adaptation) to make fine-tuning more computationally efficient, memory-friendly, and deployment-ready, especially in environments where full model retraining is impractical. Among modern fine tuning tools, LoRA stands out for its ability to adapt large models efficiently without updating all parameters.
In traditional fine-tuning, all model weights are updated, requiring significant GPU memory, compute time, and storage. This becomes challenging when working with multi-billion parameter models. LoRA solves this by freezing the pre-trained model weights and inserting lightweight trainable adapters into specific layers—usually the query and value projection layers in transformer-based architectures.
During LoRA fine-tuning:
Because of this structure, LoRA fine-tuning is especially attractive for:
Once trained, these LoRA adapters can be saved separately and merged back into the base model for inference—or kept modular and swapped dynamically depending on the use case.
LoRA fine-tuning doesn’t compromise performance either. In many benchmarks, models fine-tuned using LoRA achieve results on par with or even better than full fine-tuning—while being significantly more resource-efficient.
LoRA fine-tuning unlocks the ability to personalize and adapt large models with minimal computing, maximum flexibility, and no compromise on accuracy.
The technical brilliance of LoRA (Low-Rank Adaptation) lies in its use of linear algebra to reduce the number of trainable parameters required during fine-tuning—without sacrificing model capacity or downstream performance. To understand how it works, let’s break down the underlying mechanics.
The Problem with Full-Rank Updates
In standard fine-tuning, a pre-trained model learns a new task by adjusting its weight matrices WWW. These matrices, particularly in large transformer models, are massive (e.g., hundreds of millions of parameters per layer). Updating them directly leads to high memory usage, long training times, and difficulties in multi-task adaptation or deployment.
The LoRA Insight: Low-Rank Decomposition
LoRA proposes that the change in weights required to adapt a model to a new task doesn’t need to be high-dimensional. Instead, these updates can be approximated using low-rank matrices.
Rather than learning a full update matrix ΔW, LoRA introduces two smaller matrices:
ΔW=A⋅B
where, r≪min(d,k)
These matrices are initialized with small random values and are the only parameters updated during training. The original matrix WWW remains frozen.
Integration into Transformer Layers
LoRA is typically applied to attention projections in transformer architectures—specifically the query (Q) and value (V) projection matrices. During fine-tuning, the adapted output becomes:
W(x)+α⋅A⋅B(x)
where α is a scaling factor (often set empirically) and A⋅B(x) represents the learned low-rank adaptation applied to the input.
Efficiency and Backpropagation
Because only the low-rank matrices are trainable, the number of trainable parameters is reduced by orders of magnitude. This reduces:
Backpropagation occurs only through the LoRA modules, keeping gradients lightweight and updates focused.
By applying mathematical principles to model architecture, LoRA offers a highly efficient, modular, and elegant solution to large-model adaptation—making it ideal for modern LLM fine-tuning workflows.
LoRA has emerged as one of the most impactful techniques in the field of parameter-efficient fine-tuning (PEFT), and for good reason. It offers a range of practical advantages that make it especially attractive in scenarios involving large language models (LLMs), multi-task learning, or edge deployment. Let’s explore the key benefits of using LoRA for fine-tuning.
Significant Reduction in Trainable Parameters
One of LoRA’s standout advantages is its ability to reduce the number of trainable parameters by up to 10,000×, depending on model size and rank configuration. By learning only a small set of adapter parameters, LoRA minimizes memory consumption and computational overhead—allowing fine-tuning on consumer-grade GPUs or even CPUs in some cases.
Preservation of Pretrained Knowledge
Since LoRA keeps the base model frozen, it avoids “catastrophic forgetting,” where full fine-tuning may overwrite useful general-purpose knowledge. This makes LoRA particularly useful when adapting large models to niche domains (e.g., legal, medical, finance) while preserving their original language understanding.
Modularity and Reusability
With LoRA, different adapters can be trained for different tasks and stored separately. This enables:
This modularity is ideal for multi-tenant platforms or use cases where switching contexts is frequent.
Improved Scalability and Deployment
LoRA adapters are small in size and require no architectural changes to the base model. This makes it easy to plug into existing model deployment pipelines. They’re also friendly to edge computing environments where model size and memory are constrained.
Competitive Performance
Despite its lightweight nature, LoRA often matches or exceeds full fine-tuning performance on downstream tasks—particularly when paired with modern base models and good data.
LoRA offers a compelling trade-off: near full-model performance at a fraction of the cost and complexity. It democratizes fine-tuning, making advanced LLM customization accessible to a broader range of teams and developers.
In this section, we’ll walk through how to fine-tune large language models using LoRA with Hugging Face’s PEFT library. This approach allows you to inject trainable adapters into pre-trained models with minimal code changes—making LoRA both accessible and production-ready.
1. Install the required libraries
Install the core libraries you'll need for model loading, tokenization, training, and LoRA injection.
pip install transformers peft accelerate datasets
2. Load the base model and tokenizer
Here we load a causal language model (e.g., LLaMA 2) and its tokenizer using Hugging Face’s Transformers library. This serves as our frozen base model.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
3. Inject LoRA adapters into the model
We define a LoRA configuration specifying:
This wraps the base model and adds trainable LoRA layers.
from peft import get_peft_model, LoraConfig, TaskType
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.05,
target_modules=["q_proj", "v_proj"]
)
model = get_peft_model(model, lora_config)
4. Tokenize your dataset for training
We load a sample dataset (e.g., Alpaca format) and preprocess it by joining instructions and inputs into a flat text format, then tokenize with padding and truncation.
from datasets import load_dataset
dataset = load_dataset("yashishdua/alpaca-cleaned")
def tokenize(example):
return tokenizer(example["instruction"] + example["input"], truncation=True, padding="max_length", max_length=512)
tokenized_dataset = dataset.map(tokenize)
5. Fine-tune the model with Hugging Face’s Trainer
This sets up the training loop using Trainer, specifying batch size, number of epochs, logging, and saving strategy.
from transformers import Trainer, TrainingArguments
trainer = Trainer(
model=model,
args=TrainingArguments(
output_dir="./lora-peft-checkpoint",
per_device_train_batch_size=2,
num_train_epochs=3,
logging_steps=10,
save_strategy="epoch"
),
train_dataset=tokenized_dataset["train"],
tokenizer=tokenizer
)
trainer.train()
6. Save the LoRA adapter weights
After training, we save just the LoRA adapter layers (not the full base model) to keep things lightweight and modular.
model.save_pretrained("./lora-peft-checkpoint")
7. Load the adapter weights for inference
To run inference, reload the base model and attach the saved LoRA adapter using PeftModel. This recreates the fine-tuned version efficiently.
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
model = PeftModel.from_pretrained(base_model, "./lora-peft-checkpoint")
model.eval()
You can use this code as a starting point to fine-tune any supported transformer model using LoRA. Just plug in your preferred dataset, tweak the LoRA config or training hyperparameters, and run the script as-is. It’s designed to be modular—so you can expand it for evaluation, logging, or deployment as needed. Perfect for quick experimentation or lightweight production fine-tuning.
As LoRA gains widespread adoption, its real-world applications are expanding rapidly across industries and use cases. From reducing infrastructure costs to enabling personalization at scale, LoRA has proven its value in both research and production environments. Below are a few notable scenarios where LoRA has made a measurable impact.
Domain-specific fine-tuning in Healthcare and Legal AI
Organizations working with sensitive or specialized data—such as healthcare providers or legal tech startups—often need to adapt large language models to their domain. Using full fine-tuning would require massive computation and raise privacy concerns. With LoRA, teams can fine-tune pre-trained models on domain-specific corpora (e.g., medical terminology or legal contracts) while freezing the base weights. This results in lightweight, task-optimized models that remain secure and easy to deploy internally.
Multi-Task Fine-Tuning at Scale
Large AI platforms often need to support multiple downstream tasks—such as summarization, classification, and dialogue generation. Instead of maintaining separate copies of the full model for each task, LoRA allows them to train and store lightweight adapters for each use case. These adapters can be loaded dynamically based on user needs, making it easy to serve personalized or multi-functional models from a single shared base.
On-Device & Edge AI
Resource-constrained environments like mobile devices, IoT gateways, or edge inference platforms benefit significantly from LoRA. By training only a few million parameters instead of billions, LoRA enables quick adaptation without exhausting memory or computing budgets. Some teams have used LoRA to fine-tune models like Whisper or DistilBERT for voice assistants or document scanners running entirely on-device.
Community and Open-Source Ecosystem
Open-source projects like Alpaca, Dolly, and Vicuna have all relied on LoRA to fine-tune open base models (e.g., LLaMA) for instruction-following or dialogue tasks—demonstrating that even individual developers or small teams can create powerful models without access to expensive hardware.
Across these use cases, LoRA consistently delivers on its promise: cost-effective fine-tuning without sacrificing performance—and with the flexibility to scale across domains, tasks, and environments.

LoRA’s true power extends well beyond lightweight fine-tuning. When scaled properly, it enables a range of advanced configurations ideal for production deployment, multi-domain systems, and research workflows. Below are some of the most impactful and technically important ways to extend LoRA in real-world systems.
Merging LoRA Adapters into the Base Model
By default, LoRA adapters remain separate from the base model, acting as residual layers applied during inference. However, in latency-sensitive environments or for deployment on inference-optimized runtimes (e.g., vLLM, ONNX, TensorRT), it's advantageous to merge the low-rank LoRA weights into the original model weights post-training. This eliminates the need for adapter logic and reduces inference complexity, allowing for:
The merging process is typically done via a linear operation:
Wmerged=W+α⋅A⋅B
Selective Module Application
LoRA need not be applied across all transformer layers. In many cases, fine-tuning only specific parts of the architecture—such as the query (Q) and value (V) projection matrices in attention layers—achieves comparable performance with fewer parameters.
Advanced users may target:
This approach gives you more control over the model’s behavior, allows for parameter budgeting, and opens up interpretability at the layer level.
LoRA with Quantization: QLoRA
QLoRA is a powerful extension that combines LoRA with 4-bit or 8-bit quantization, allowing models with billions of parameters to be fine-tuned on a single GPU. It works by:
QLoRA enables fine-tuning of models like LLaMA-65B on consumer-grade hardware without sacrificing accuracy.
Multi-Adapter Inference and Routing
In production scenarios with multi-task or multi-tenant requirements, LoRA allows for the creation of multiple adapters, each tuned for a different use case or customer. These can be:
This allows a single base model to serve many domains while keeping memory usage low and latency manageable. Adapter selection logic can be integrated with external orchestration layers or prompt parsers.
Modular Agent and RAG Components
In more complex systems like Retrieval-Augmented Generation (RAG) or multi-agent architectures, different submodules may perform document retrieval, tool selection, summarization, or dialogue. LoRA enables component-level fine-tuning, where each submodel can be trained independently with its own adapter.
This is especially powerful in scenarios where:
LoRA ensures isolation, maintainability, and adaptability within such modular systems.
While LoRA brings significant benefits in terms of efficiency and modularity, it’s not without its challenges. Understanding these limitations is crucial when designing robust fine-tuning workflows or scaling LoRA across multiple use cases.
Limited Capacity for Extreme Adaptation
Since LoRA updates only a small subset of parameters (via low-rank matrices), it may struggle when the task requires substantial changes in model behavior. For tasks that involve reasoning in very different domains from the pre-trained distribution, full fine-tuning or additional layers might still be necessary.
Adapter Configuration Trade-offs
Choosing the right LoRA configuration—such as the rank (r), alpha scaling factor, and target modules—requires experimentation. A rank that's too low might underfit, while too high may lead to overfitting or reduce the parameter savings. Additionally, targeting the wrong modules (e.g., using LoRA on all layers indiscriminately) can introduce unnecessary complexity and cost without performance gains.
Compatibility with Quantization and Serving
While tools like QLoRA support quantized fine-tuning, not all inference platforms handle LoRA adapters or merged weights gracefully. Some serving frameworks (especially edge or low-level C++ runtimes) may require adapter merging or re-exporting into a compatible format—adding steps to the deployment pipeline.
Debugging and Evaluation
Debugging LoRA-tuned models can be more complex than expected. Since the base model is frozen, it can be difficult to interpret whether failures are due to under-training the LoRA modules or inherent limitations of the frozen backbone. Proper evaluation across multiple tasks and datasets is important to understand when LoRA is the right tool for the job.
Despite these challenges, LoRA remains a highly effective and flexible approach when used thoughtfully—especially in environments where efficiency, scale, and modularity are key priorities.
LoRA has redefined how we fine-tune large language models—making it possible to adapt powerful models efficiently, without the need for extensive computing or full retraining. Its low-rank approach brings modularity, scalability, and cost-effectiveness to modern ML workflows. In this guide, we explored LoRA’s foundations, real-world use cases, advanced techniques, and practical implementation using Hugging Face’s PEFT. As LLMs continue to grow in size and adoption, LoRA offers a practical path to personalization and performance. For teams aiming to scale intelligently, LoRA is more than just efficient—it’s a strategic advantage in building adaptable AI systems.
LoRA fine tuning is an efficient method for adapting large pre-trained models without updating all parameters. It freezes the base model weights and trains only small, lightweight adapter modules. This technique significantly reduces computational resources and memory, making model adaptation faster, cheaper, and more accessible for specific tasks and deployments.
LoRA fine tuning significantly reduces the data required compared to full model fine-tuning. While no fixed amount exists, LoRA leverages a pre-trained base, meaning you can achieve strong results with smaller, task-specific datasets. This makes adapting large models more efficient and accessible for specialized use cases, optimizing resource usage.
The main advantage of LoRA fine-tuning is its remarkable efficiency. It drastically reduces trainable parameters, making the process faster, more cost-effective, and less memory-intensive. This allows for adapting large language models across various tasks with minimal computing resources, ensuring accessible and high-performance AI solutions for US businesses.
LoRA fine-tuning freezes the original model’s large weights and inserts small, trainable adapter matrices into specific layers. Only these lightweight adapter parameters are updated during training, not the entire model. This process makes LoRA fine-tuning significantly more efficient, reducing computational resources and speeding up model adaptation for US teams.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.








.png)
.webp)



.webp)
.webp)


.webp)
.webp)
.webp)
.png)




