














November 5, 2025
|
5 min read

Published: July 4, 2026
%20(11).webp)
Blazingly fast way to build, track and deploy your models!
プロンプティング、ファインチューニング、Retrieval-Augmented Generation (RAG) は、最も一般的なLLM学習手法です。適切な手法を選択するには、プロジェクトの要件、リソース、および望ましい成果を慎重に評価する必要があります。
以下のセクションでは、それぞれの技術について詳しく掘り下げ、その詳細、応用例、そしてあなたのニーズに最も適したものをどのように決定するかについて議論します。

プロンプティング、ファインチューニング、RAGのいずれかを選択する最初のステップは、利用可能なデータと解決を目指す具体的な問題を綿密に検討することです。あなたのタスクが一般的な知識、専門的な情報、または外部ソースからの最新データを必要とするかどうかを考慮してください。問題の複雑さ、望ましい出力のスタイルとトーン、および必要なカスタマイズのレベルも重要な要素です。
非常に専門的またはニッチなトピックを扱う場合、望ましい精度と関連性を達成するためにはファインチューニングまたはRAGが必要になるかもしれません。一方、プロジェクトがより一般的なクエリやコンテンツ作成に関わる場合は、プロンプティングで十分であり、費用対効果も高くなる可能性があります。
プロンプティング、ファインチューニング、RAGの選択は、予算の制約にも左右されます。プロンプティングは、モデルをそのまま使用するため、一般的に最もリソースを消費しません。ファインチューニングは、トレーニングに追加のデータと計算リソースを必要とし、より高いコストにつながります。RAGも、特に検索用の外部データベースのセットアップと維持が必要な場合、リソースを大量に消費する可能性があります。
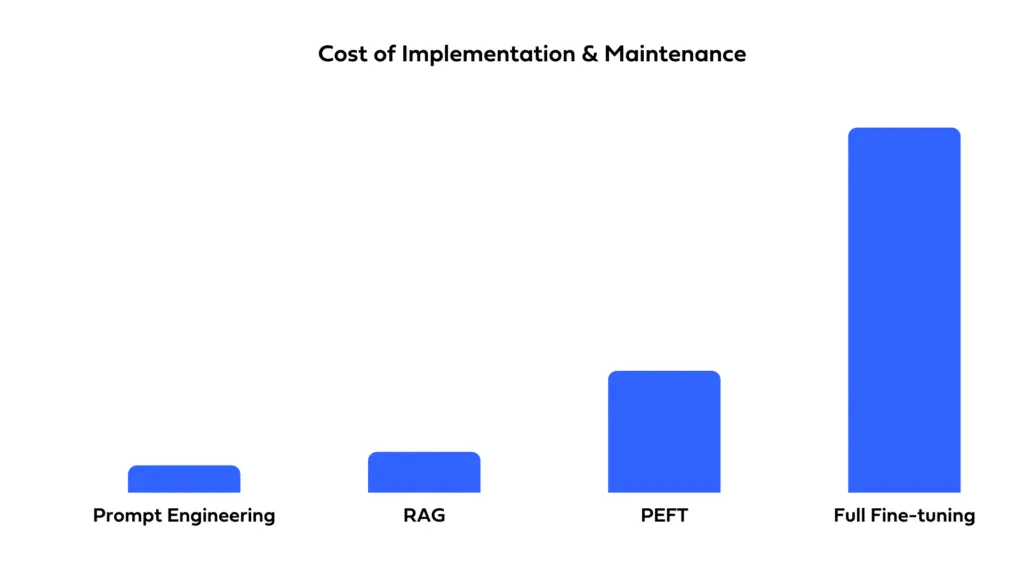
ソリューションをどれだけ迅速にデプロイする必要があるか、そして利用可能なリソースを考慮してください。プロンプティングは、最小限のセットアップ時間で迅速なデプロイを可能にします。ファインチューニングは、より良いパフォーマンスを提供する可能性がありますが、トレーニングと最適化に時間がかかります。RAGは、外部データソースを統合する複雑さを伴い、開発期間を延長し、専門的な知識を必要とする場合があります。
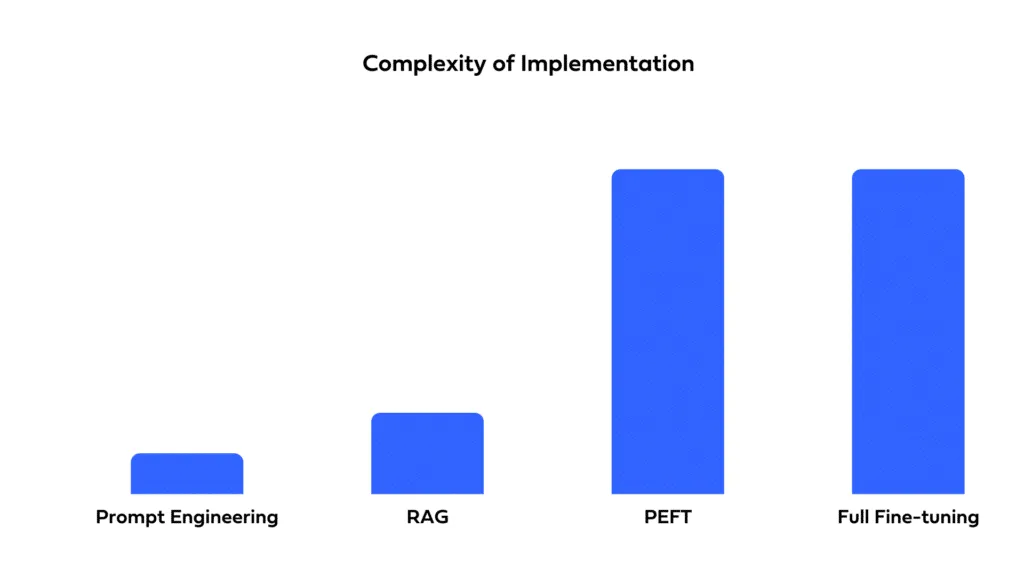
RAGはソースの帰属を容易にし、ユーザーが応答生成に利用された情報の起源を識別できるようにします。プロンプティングとファインチューニングはブラックボックスとして機能するため、応答を遡って追跡することが困難です。

プロンプティングは、迅速で費用対効果の高いソリューションを必要とし、事前学習済みモデルの一般的な知識ベースに依存できるプロジェクトに最適です。次のようなアプリケーションに適しています。
プロンプトは非常に手軽ですが、専門的なタスクに必要な精度やカスタマイズ性を提供できない場合があります。出力の品質はプロンプトの設計によって大きく異なり、慎重な作成とテストが求められます。
ファインチューニングは、プロジェクトが高度な具体性を要求する場合や、特定のスタイル、トーン、またはドメイン固有の知識に密接に合わせる必要がある場合に最適な方法です。特に以下のケースで効果的です。
ファインチューニングの決定は、パフォーマンスの向上と、それに伴う追加コストおよび必要なリソースとのトレードオフを考慮して行うべきです。カスタマイズと精度の価値がこれらの考慮事項を上回るプロジェクトにとって不可欠です。
RAGは、最新情報や特定のドメインからの詳細なデータで回答を補強する必要がある状況で特に優れています。具体的には、以下の用途に適しています。
RAGは、複雑なクエリや専門的な知識領域において優れた結果をもたらしますが、その分、複雑さとリソース要件が増加します。リアルタイムのデータ取得に必要なインフラストラクチャのセットアップと維持への投資がプロジェクトの範囲によって正当化される場合に、適切な選択肢となります。
プロンプティングは、当社の LLM Gateway モジュールによって実現され、本番環境のLLMアプリケーションで使用される 最高のプロンプトエンジニアリングツール と関連付けられることが多いワークフローをサポートします。LLM Gatewayは、統合されたAPIを提供し、ユーザーが単一のプラットフォームを介して、自社でホストするモデルを含むさまざまなLLMプロバイダーにアクセスできるようにします。一元化されたキー管理、認証、コスト配分機能が特徴です。さらに、フォールバック、リトライ、およびガードレールとの統合もサポートしています。
数回のクリックでRAGをセットアップできるワークフローをテンプレート化しました。デプロイ方法については、当社のブログをご覧ください。 RAGベースのチャットボット TrueFoundryを使用することで、ベクトルデータベース、埋め込みモデル、LLMなどのエンドツーエンドの構築プロセスを処理し、ニーズに合わせてワークフローをカスタマイズするための適切な制御機能を提供します。
TrueFoundryは、 ファインチューニング プロセスを、すべての複雑さを抽象化し、LoRA/QLoRA技術に適切なリソース構成を設定することで簡素化しました。実験用にファインチューニングのJupyterノートブックをデプロイしたり、専用のファインチューニングジョブを起動したりできます。詳細なガイドは こちら。
弊社 TrueFoundry では、プロンプティング、RAG、ファインチューニングという3つのLLM学習技術すべてを、極めて合理化された方法でサポートしています。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


