













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
大規模言語モデル(LLM)はAIの世界に旋風を巻き起こしましたが、それはまだ始まりに過ぎません。本当の魔法は、LLMがエージェントへと進化するときに起こります。エージェントとは、自律的に推論し、意思決定し、行動できる、インテリジェントで目標駆動型のシステムです。LLMエージェントは、AI製品の構築方法を変革し、自動化されたリサーチアシスタントから複雑な多段階タスク解決システムまで、あらゆるものを可能にしています。この究極のガイドでは、LLMエージェントとは何か、その仕組み、種類、実際のユースケース、そして直面する課題について詳しく解説します。開発者、創業者、AI愛好家を問わず、このガイドはインテリジェントエージェントの未来について明確な理解をもたらすでしょう。
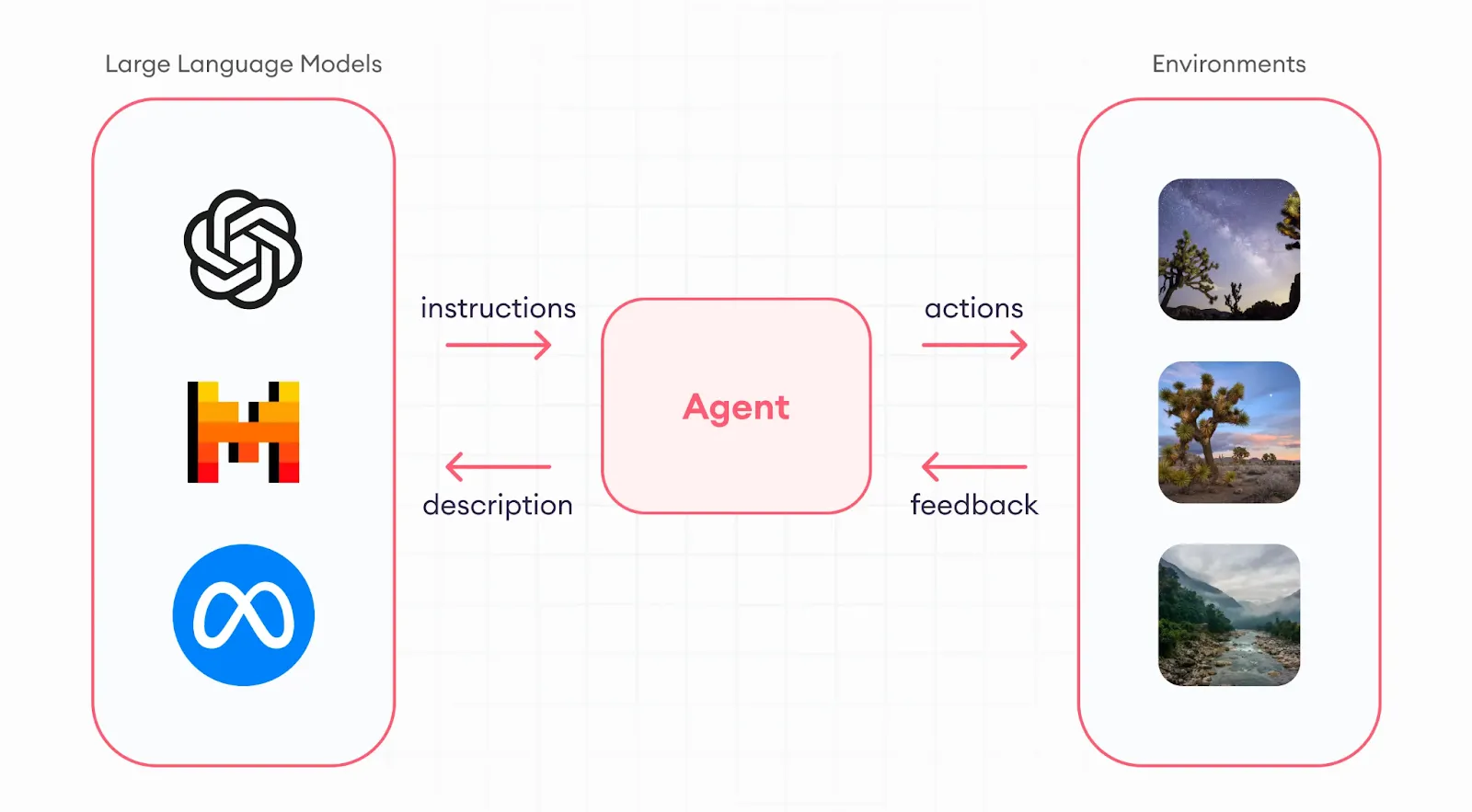
LLMエージェントは、大規模言語モデルの上に構築されたインテリジェントなシステムであり、単にプロンプトに応答するだけでなく、行動を起こすように設計されています。計画を立て、推論し、ツールを使用し、メモリを維持し、自律的に動作して多段階のタスクを完了できます。簡単に言えば、受動的なLLMを目標指向のAIエンティティに変えるものです。
GPT-4やClaudeのような標準的なLLMが単一のプロンプトに単独で応答するのに対し、LLMエージェントは目的とループプロセスを持っています。タスクを評価し、次に行うべきことを決定し、アクションを実行し(ツールを呼び出したり、データベースを検索したりするなど)、結果を観察し、目標が達成されるまで続行します。
これは、エージェントが基盤となる言語モデルの周りに複数の層を追加することで可能になります。
LLMエージェントは、基盤となる大規模言語モデルの上に、構造、メモリ、意思決定機能を重ねることで動作します。大まかに言えば、LLMエージェントは「感知-思考-行動」のループに従い、環境や入力を観察し、次のステップについて推論し、定義された目標に向かって行動を実行します。
ワークフローは通常、ユーザーのクエリまたはタスクから始まります。従来のLLMのように即座に応答するのではなく、エージェントはタスクを分解し、外部ツールが必要かどうかを判断し、どのような行動を取るべきかを決定し、目標が達成されるまで環境との対話を続けます。これらの各ステップは、繰り返される LLM推論、モデルが中間コンテキストを評価し、次の行動を決定するものです。
LLMエージェントのワークフローにおける主要なステップ:
タスク初期化
エージェントは入力を受け取るか、目標を割り当てられます。例えば、「競合他社レポートを作成する」や「メールのコンテキストに基づいて会議を予約する」といった目標です。
計画
LLMを使って計画を生成します。多くの場合、自然言語で手順を検討したり、事前定義された選択肢から選んだりすることで行われます。
ツール選択と実行
検索エンジン、API、コードインタープリター、データベースなどのツールが利用可能な場合、エージェントはどれを使用するかを決定し、それらにアクセスするための構造化された呼び出しを形成します。
観察とフィードバックループ
ツールが結果を返すと、エージェントはその出力を評価します。情報が十分であるか、さらなる行動が必要か、またはタスクが完了したかを判断します。
メモリ(オプション)
より高度な設定では、エージェントは以前のやり取りを追跡したり、知識を保存したり、ユーザープロファイルを構築したりするために、短期または長期のメモリを保持します。
目標達成までの反復
このループ(計画、実行、観察)は、エージェントが意図した結果を達成するか、終了条件に達するまで続きます。
LLMエージェントは進化を続けるにつれて、複雑さ、自律性、目的に基づいてさまざまな形で設計されています。すべてのエージェントは大規模言語モデルを基盤としていますが、計画の立て方、ツールとの連携方法、タスクの処理方法は大きく異なります。広く言えば、LLMエージェントはいくつかのタイプに分類できます。
タスク特化型エージェント
これらのエージェントは、明確に定義された狭いタスクを実行するために構築されています。事前に設定されたワークフローやロジックに従いますが、エッジケースや曖昧さを処理するためのLLMの柔軟性から恩恵を受けます。例:
これらはテスト、検証、制御が容易であるため、本番環境でよく使用されます。
自律型エージェント
これらのエージェントは、人間の介入を最小限に抑えて動作し、タスクへのアプローチ方法を決定できます。「市場トレンドを調査し、レポートを作成する」といった広範な目標が与えられた場合、エージェントはプロセスを計画し、データを収集し、分析し、レポートを生成します。これらすべてを自律的に行います。
自律型エージェントは通常、メモリ、再帰ループ、さらには自己修正メカニズムを含みます。AutoGPTやBabyAGIは、この種のエージェントの動作を示すオープンソースプロジェクトの例です。
ツール利用エージェント
このカテゴリには、外部ツール、API、環境に大きく依存して目的を達成するエージェントが含まれます。これらは完全に自律的ではないかもしれませんが、必要に応じて関数を呼び出したり、データを取得したり、スクリプトを実行したりする能力に優れています。
これらのエージェントは、ReAct(Reasoning + Acting)やOpenAIの関数呼び出しのような戦略を用いて、以下のことを決定します。
これらは、エージェントがCRM、データベース、または社内APIと連携する必要があるエンタープライズシナリオに最適です。
マルチエージェントシステム
1つのエージェントがすべてを行うのではなく、専門的な役割を持つ複数のエージェントが協力して複雑なタスクを達成します。例えば、あるエージェントは調査を行い、別のエージェントはデータを検証し、3番目のエージェントは洞察を要約するといった具合です。これらは必要に応じて、互いに通信し、コンテキストを渡し、競合を解決します。
CrewAIやMetaGPTのようなフレームワークは、このようなマルチエージェントの連携を可能にします。
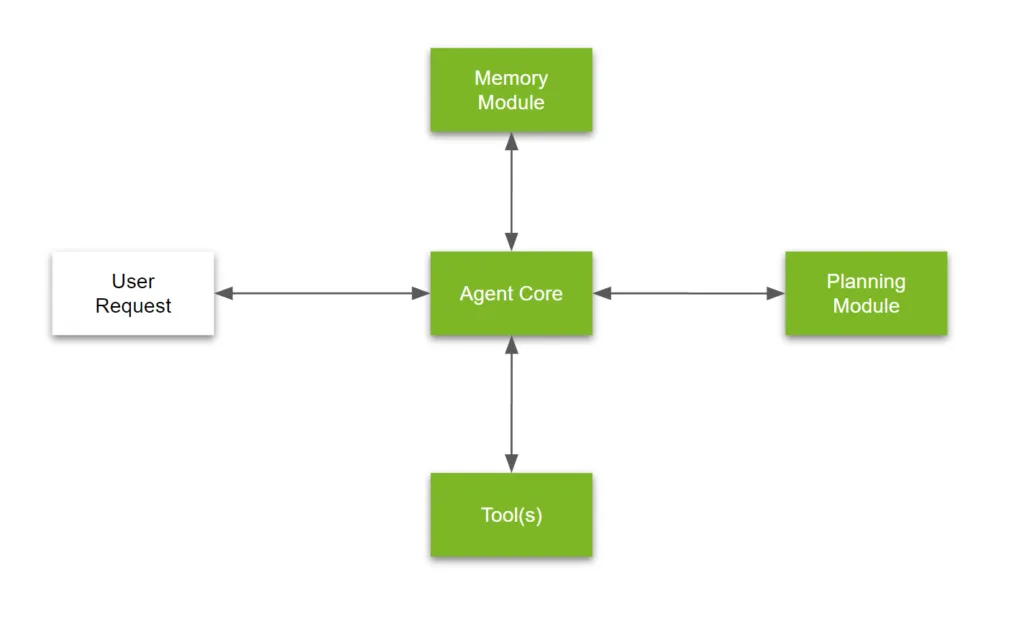
LLMエージェントは、単一のモデルやスクリプトではなく、自律的に思考し、記憶し、対話し、行動するように設計されたモジュール式のシステムです。このアーキテクチャは通常、エージェントコア、メモリモジュール、ツール、プランニングモジュールの4つの主要コンポーネントで構成されています。これらの部分は連携して、生の言語モデルを能力のある目標駆動型エージェントへと変貌させます。
1. エージェントコア
エージェントの中心にあるのは、GPT-4、Claude、LLaMA 2、Mistralなどの基盤モデルであることが多い言語モデルそのものです。このコンポーネントは、入力を理解し、応答を生成し、タスクを推論する役割を担います。
強力ではありますが、モデル単体では受動的です。能動的になるためには、サポートロジックが必要です。エージェントコアは「脳」として機能し、プロンプトや指示を解釈しますが、アクションを実行し、コンテキストを記憶し、複雑な問題を解決するためには他のモジュールに依存します。
2. メモリモジュール
メモリは、エージェントがステップ、インタラクション、またはセッションをまたいで情報を保持することを可能にします。これにより、エージェントは時間とともに適応性が高まり、パーソナライズされます。
このモジュールは、エージェントのニーズに応じて、ベクトルデータベース、ドキュメントストア、あるいは構造化されたキーバリューストレージを使用して実装される場合があります。
3. ツール
ツール層は、エージェントに現実世界での実用性をもたらします。これにより、エージェントは言語生成の域を超え、実際にアクションを起こすことが可能になります。
ツールには以下が含まれます。
エージェントは自身の知識や能力に不足があることを認識すると、ツールを呼び出し、その結果を処理し、タスクを続行できます。これにより、LLMエージェントはプラグインのような拡張性を持ち、エンタープライズのユースケースにも対応できるようになります。
4. プランニングモジュール
ここでは、エージェントが目標指向になります。プランニングモジュールにより、複雑なタスクを分解し、実行順序を決定し、アクションをインテリジェントに反復することが可能になります。
担当するのは次の通りです。
プランニングがなければ、エージェントは単発的な応答しかできません。プランニングがあれば、不確実性を乗り越え、反復し、自己修正することができます。
LLMエージェントを標準的な言語モデルと区別する最も重要な能力の一つは、ツールを活用する能力です。これにより、エージェントは現実世界と対話できるようになります。具体的には、最新情報の取得、計算の実行、データベースへのアクセス、アクションのトリガーなどが可能です。ツールがなければ、エージェントは事前学習済みの知識に限定され、純粋に受動的なままでしょう。ツールがあれば、対話型でタスクを完了するシステムへと進化します。
大まかに言えば、LLMエージェントにおけるツール利用はシンプルなサイクルに従います。
ツールの抽象化と呼び出し
ツールは通常、関数シグネチャまたはツールスキーマとしてエージェントに公開されます。これらは、LangChain、OpenAIのFunction Calling、ReAct、AgentOpsなどのフレームワークを介してカスタム定義または登録できます。エージェントはコードを直接実行するのではなく、構造化された関数呼び出し(JSONオブジェクトなど)を生成し、それがバックエンドの実行レイヤーによって処理されます。
例えば、天気確認ツールを考えてみましょう。
{
"tool": "get_weather",
"inputs": {
"location": "New York City"
}
}
エージェントは天気情報が必要であると判断し、このツール呼び出しを構築します。その後、バックエンドがその関数(この場合はAPI呼び出し)を実行します。その結果はエージェントコアにフィードバックされ、エージェントコアは推論を続行します。
ツールが使用されるタイミングと理由
LLMエージェントは、次の場合にツールを呼び出します。
ツールは、エージェントが外部システムと連携するための橋渡し役です。それらはエージェントの能力を、 「スマートなテキスト生成器」 へと 行動実行型アシスタント.
ツール利用戦略:ReActとプランニング
ほとんどの最新エージェントはReAct(Reason + Act)パラダイムを採用しています。エージェントは次に行うべきことを推論し、ツールを選択し、その出力を観察し、タスクが完了するまで処理を続けます。この密なループにより、多段階の問題解決、検証、修正が可能になります。
より高度なシステムでは、プランニングモジュールがワークフローの各ステップでどのツールを使用するかを決定します。これは、タスクのコンテキストに基づいて動的に構築される意思決定ツリーのようなものです。
LLMエージェントは、AIが現実世界のタスクに適用される方法において、大きな進歩を意味します。大規模言語モデルの推論能力に、記憶、プランニング、ツール利用を組み合わせることで、エージェントは静的なアシスタントから自律的な共同作業者へと進化します。このアーキテクチャの転換は、技術分野とビジネス分野の両方で、具体的なメリットをもたらします。
自律性と多段階推論
単一のプロンプトに応答する従来のLLMとは異なり、エージェントはタスクを分解し、ツールを呼び出し、作業が完了するまで反復することで、複雑なワークフローを管理できます。この自律性により、データセットの分析、インサイトの要約、プレゼンテーションの生成、結果のメール送信といった多段階のビジネスプロセスを、人間の介入なしに実行するのに適しています。
システムとのリアルタイム連携
ツール連携を通じて、エージェントはリアルタイムデータを取得し、APIと対話し、さらにはファイルやデータベースを操作することもできます。最新情報にアクセスできるこの能力は、事前学習済みモデルに内在する静的な知識の限界を解消します。ビジネスにおいては、エージェントがCRM、分析システム、カレンダー、社内ツールと連携できることを意味し、導入後すぐに運用に役立つものとなります。
コンテキスト認識とパーソナライゼーション
メモリモジュールにより、エージェントは複数のインタラクションにわたってコンテキストを維持できます。これにより、ユーザーの好みや以前のステップを記憶し、出力をパーソナライズすることが可能になります。時間の経過とともに、エージェントは学習したユーザーの行動に基づいて、トーン、コンテンツ、推奨事項を調整し、より人間らしい体験を提供できるようになります。
さまざまなユースケースへのスケーラビリティ
LLMエージェントは高い構成可能性を持っています。同じエージェントコアは、周囲のツールやプランニングロジックを変更することで、部門(例:営業、マーケティング、財務)を越えて再利用できます。このモジュール性により、価値実現までの時間が短縮され、重複する開発作業が削減されます。
効率の向上とコスト削減
反復的なタスクや分析タスクを自動化することで、エージェントは人間のリソースを解放します。チームはより価値の高い戦略や意思決定に集中でき、エージェントが運用タスクを処理することで、生産性と運用コストの測定可能な改善につながります。
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

LLMエージェントは強力なシステムですが、その複雑さゆえに、いくつかのエンジニアリング上および運用上の課題が生じます。意思決定の精度からシステムの信頼性に至るまで、堅牢で本番環境に対応できるエージェントを構築するには、LLMをプロンプトループに接続するだけでは不十分です。以下に、最も一般的な課題のいくつか—およびその影響を示す簡単な例—を挙げます。
ハルシネーションと意思決定エラー
LLMは、確信に満ちていながら不正確または誤解を招く情報を生成することがあります。これはハルシネーションとして知られる現象です。エージェントのパイプラインでは、これが連鎖的に誤った行動につながる可能性があります。
ツールの誤用と呼び出しの失敗
エージェントは、構造化された入力を使用してAPIやツールを正確に呼び出す必要があります。しかし、正しい形式を生成したり、エッジケースを動的に処理したりすることはエラーが発生しやすいものです。
レイテンシーとコストのオーバーヘッド
多段階の推論とツール連携は、特に各ステップで大規模モデルが使用される場合、高いレイテンシーとモデルのトークンコストを発生させます。
メモリの複雑性
何を記憶し、何を忘れ、関連する記憶をいかに効率的に取得するかを管理することは、継続的な課題です。
セキュリティ、プライバシー、ガードレール
エージェントは機密性の高いシステムやデータに触れることがよくあります。ガードレールがないと、内部ロジックを公開したり、応答でプライベートデータを漏洩させたりする可能性があります。
デバッグと可観測性
エージェントは決定論的ではありません。適切なツールがなければ、エージェントがなぜ失敗したのか、どのように意思決定したのかを追跡することは困難です。
LLMエージェントはもはや単なる理論上の概念ではありません。すでに様々な業界で、自律的なタスクの実行、ワークフローの自動化、ユーザーとのインテリジェントな対話のために活用されています。LLMエージェントが実際の環境でどのように機能するかを示すいくつかの実用的な例を見てみましょう。
AutoGPTとBabyAGI
これらのオープンソースプロジェクトは、人間の監視なしにタスクを実行できる自律型エージェントのアイデアを示しました。「競合他社を分析し、戦略を策定する」といった高レベルの目標が与えられると、AutoGPTはステップを計画し、ウェブを検索し、要約を作成し、結果を評価し、計画を繰り返し調整します。これらのエージェントはまだ実験段階であり、ガードレールが必要ですが、自律的なタスク実行ループに大きな関心を引き起こしました。
LangChainエージェント
LangChainは、プロンプトテンプレート、ツールインターフェース、メモリ、プランナーなどのモジュール型コンポーネントを使用してエージェントを構築するためのフレームワークを提供します。例えば、エージェントは関連文書を取得し、内容を要約し、回答を統合することで、PDFのコレクションに対する複雑なクエリに答えることができます。LangChainは、ワークフローを定義し、APIを統合することで、タスク固有のエージェントとツール使用エージェントの両方を簡単に作成できるようにします。 LangChain vs LangGraph チームが多段階のエージェント実行においてグラフベースのオーケストレーションがより適している時期を判断するのに役立ちます。
OpenAI関数呼び出しエージェント
OpenAIの関数呼び出しにより、構造化されたツール利用エージェントが可能になります。開発者はツールをJSONスキーマとして定義し、モデルはいつ、どのようにそれらを呼び出すかを選択します。実用的なユースケースとしては、顧客サービスエージェントが意図を認識すると、手動でのAPIエンジニアリングなしに、注文状況を自動的に取得したり、配送情報を更新したり、サポートチケットを提出したりする、といったものがあります。
CrewAIとMetaGPT
これらのフレームワークはマルチエージェントコラボレーションを導入しており、エージェントには開発者、レビュー担当者、戦略立案者などの特定の役割が割り当てられ、複雑なタスクを解決するために互いに通信します。例えばMetaGPTでは、プロジェクトマネージャーエージェントが要件を作成し、開発者エージェントがコードを記述し、テスターエージェントがそれを検証します。これは、実際のソフトウェアチームのワークフローを効果的に模倣しています。
ほとんどのLLMエージェントはサンドボックスではうまく機能しますが、実際の環境ではすぐに破綻します。ハルシネーションを起こしたり、ツール呼び出しに失敗したり、レイテンシーに苦しんだり、問題が発生した際の可視性が低かったりします。スマートなエージェントを構築するのは簡単ですが、それを本番環境で信頼性があり、スケーラブルで、安全なものにすることが難しいのです。
そこでTrueFoundryの出番です。エンドツーエンドの LLMOpsプラットフォーム を提供し、有望なプロトタイプを、高速で、可観測性があり、コンプライアンスに準拠し、スケーラブルに構築されたエンタープライズグレードのエージェントシステムへと変革します。
TrueFoundryを利用することで、チームはLangChain、AutoGen、CrewAI、またはカスタムアーキテクチャを使用して構築されたエージェントを、インフラの複雑さを心配することなくデプロイできます。シングルエージェントのユースケースであろうと、マルチエージェントのパイプラインであろうと、TrueFoundryはクラウドまたはオンプレミス環境全体でワークフローを管理するためのオーケストレーション基盤を提供します。
リアルタイムのエージェントインタラクションを強化するため、このプラットフォームはvLLMやSGLangのような高性能バックエンドを使用した最適化されたモデルサービングを提供します。オートスケーリングとインテリジェントなリソースプロビジョニングと組み合わせることで、エージェントは推論コストを抑えながら、より速く応答できます。
外部ツールやサードパーティAPIを呼び出すエージェントは、TrueFoundryの統合APIゲートウェイから恩恵を受けます。これにより、以下の機能が提供されます。
LLMエージェントは、反応型チャットボットから、推論、計画、行動が可能な自律システムまで、AIとの関わり方を再構築しています。言語モデル、ツール、メモリ、オーケストレーションによって強化されたそのアーキテクチャは、より複雑な現実世界のタスクをサポートするために急速に進化しています。可能性は広大である一方で、本番環境でエージェントをデプロイするには、巧妙なプロンプト以上のものが必要であり、スケーラブルなインフラ、可観測性、そして慎重なシステム設計が求められます。
企業は、動的な意思決定を必要とする複雑な多段階ワークフローを自動化するためにLLMエージェントを導入します。これらのシステムは、言語モデルを使用して問題を推論し、外部ツールを使用してアクションを実行します。これらは、従来の静的なチャットボットではスケーラブルな本番環境で達成できない自律的な実行機能を提供します。
LLMエージェントは、制約のない環境で動作する際、推論ループ、ツールエラー、またはデータハルシネーションに陥ることがよくあります。これらの失敗は通常、エージェントに明確な指示がない場合や、予期せぬAPI応答に遭遇した場合に発生します。ディープオブザーバビリティを導入することで、チームはエージェントのステップを追跡し、これらの論理的な破綻を修正して、本番環境での信頼性を確保できます。
LLMエージェントの信頼性は、タスクの複雑さと基盤となるモデルの能力に依存します。単純なデータ取得は非常に信頼性が高い一方で、複雑な推論には厳格な評価フレームワークが必要です。プラットフォームレベルの監視により、チームはこれらの成功率を測定し、エージェントのプロンプトを体系的に改善して、推論精度を向上させることができます。
LLMエージェントは、大規模言語モデルを中核的な推論エンジンとして利用する自律システムを具体的に指します。「AIエージェント」はさまざまなアルゴリズムを含むより広範なカテゴリですが、LLMベースのバージョンは自然言語理解と複雑なタスクの計画に優れています。これらは、テキストベースの指示を統合されたソフトウェアツール全体で実行可能なステップに変換します。
多くの現代のシステムはLLMエージェントですが、一部のAIエージェントは従来の強化学習や固定されたルールベースのロジックを利用しています。しかし、LLMを統合することで、エージェントははるかに多様で非構造化された情報を処理できるようになります。TrueFoundryのようなエンタープライズプラットフォームはハイブリッドアーキテクチャをサポートしており、チームは特定の、リスクの高いワークフローに最適なインテリジェンスを選択する柔軟性を得られます。
MCPエージェントは、モデルコンテキストプロトコルを介してLLMを外部ツールやデータに接続することに重点を置き、制御された仲介役として機能します。一方、LLMエージェントは自律的に動作し、直接的な人間の指示なしに意思決定、タスク実行、または複数のツールとの対話を行い、推論とワークフローオーケストレーションを活用します。
リスクには、不正確または偏った出力の生成、機密情報の漏洩、ポリシーに違反する自律的な意思決定、または統合されたツールの誤用が含まれます。適切な監視がなければ、LLMエージェントはエラーを伝播させ、法的責任を生じさせ、セキュリティを危険にさらす可能性があるため、エンタープライズ展開においてはガバナンス、監視、および安全メカニズムが不可欠です。
監視なしで放置されると、LLMエージェントはプログラムされた制約内で割り当てられたタスクの実行を継続します。ワークフローを反復したり、接続されたツールにクエリを実行したり、自律的に出力を洗練したりする可能性があります。しかし、人間の監視やガードレールがなければ、意図された目標から逸脱したり、一貫性のないまたは安全でない結果を生成したり、コンテキストの変化を検出できなかったりする可能性があります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


