














May 8, 2024
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
組織がチーム全体でLLMを活用したアプリケーションをより多く展開するにつれて、新しいインフラストラクチャ層が不可欠なものとして浮上しています。それは、 AIゲートウェイ。AIゲートウェイは、アプリケーションと基盤となるAIサービスまたはモデルの間に位置し、AIトラフィックの中央制御プレーンとして機能します。これにより、数十から数百のモデルへの統合されたアクセスを提供しつつ、セキュリティ、コスト、可観測性に関する企業ポリシーを適用します。利用規模が拡大するにつれて、この重要性は増しています。2026年までに80%以上の企業が生成AIを利用すると予想されており、ガートナーは2028年までにマルチモデルアプリを構築するエンジニアリングチームの70%が、信頼性の向上とコスト管理のためにAIゲートウェイに依存すると予測しています。ゲートウェイがない場合、各AIクライアント呼び出しは個別に管理する必要があり、トークン消費の無管理、ログの断片化、セキュリティギャップにつながります。このような環境において、適切に設計されたAIゲートウェイは、 新しい制御層 エンタープライズAIにとって、従来のAPIゲートウェイにはない一貫性、ガバナンス、効率性を提供します。
AIゲートウェイは アプリケーションとAIモデル間のトラフィックを管理する特殊なミドルウェア層です。従来のAPIゲートウェイとは異なり、AIワークロード向けに特化して構築されています。これは、 AI固有の懸念事項 トークンレベルのレート制限、ストリーミング応答、プロンプトのセキュリティチェックなど、通常のHTTPゲートウェイでは対応できないAI固有の懸念事項を処理します。実際には、アプリケーションはすべてのAIリクエストをまずゲートウェイに送信します。ゲートウェイはリクエストを認証し、コンテンツフィルターやガードレールを適用し、適切なモデルにルーティングし、最終的に(独自の事後処理を加えて)応答をアプリケーションに返します。この集中管理層により、モデルオーケストレーション(異なるAIプロバイダー間での負荷分散やフェイルオーバー)や統合請求などの機能が可能になります。
ガートナーは、4つの 基盤となるタスク を現代の企業においてAIゲートウェイが実行すべきであると特定しました。 ルーティング、 セキュリティ/ガードレール、 コスト管理、および 可観測性。
これらの機能を統合することで、AIゲートウェイはAIトラフィックを プログラマブルなポリシープレーン に変えます — Kubernetesがコンテナに対して行ったように。これは、AI実験から本番環境へ移行する際の主要な問題を解決します。ゲートウェイがなければ、トークン消費の可視性を失い、一貫性のないセキュリティ制御を適用し、断片的なパフォーマンスデータを持つことになりがちです。ゲートウェイは、 すべての AIリクエストが管理され、測定可能であることを保証します。あるアナリストガイドが指摘するように、「このレイヤーがなければ、組織はコスト管理、セキュリティ維持、大規模なパフォーマンス監視に苦労するでしょう」。要するに、AIゲートウェイは、大規模なチームが必要とする制御とテレメトリを追加することで、AI利用をエンタープライズ対応にします。
すべての小規模なAIプロジェクトが完全なゲートウェイを必要とするわけではありませんが、複数のチーム、モデル、または使用パターンが出現するとすぐに、ゲートウェイは価値を持つようになります。以下の場合には、AIゲートウェイが必要となるでしょう。
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

AIゲートウェイソリューションを比較する際は、以下の点を保証する機能に注目してください。 スケーラビリティ、セキュリティ、可観測性、 および コスト効率です。重要な機能には以下が含まれます。
要約すると、評価では以下を網羅する必要があります。 ルーティング/オーケストレーション、 パフォーマンス、 可観測性、 セキュリティ、 コスト管理、および デプロイ。実践的なステップとして、構造化されたチェックリストを使用して、これらの側面に基づいて各ゲートウェイを評価してください。
TrueFoundry独自のAIゲートウェイは、これらのエンタープライズ要件を念頭に置いてゼロから構築されました。これは、 1000以上のLLMに対する統合インターフェース (OpenAI、Anthropic、Gemini、Bedrock、オープンソースモデルなど)を提供し、セキュリティ、可観測性、ガバナンスをその核に組み込んでいます。アーキテクチャは、コントロールプレーン機能(UI、ポリシーデータベースなど)と、推論トラフィックを処理するステートレスなゲートウェイポッドを分離しています(下図参照)。
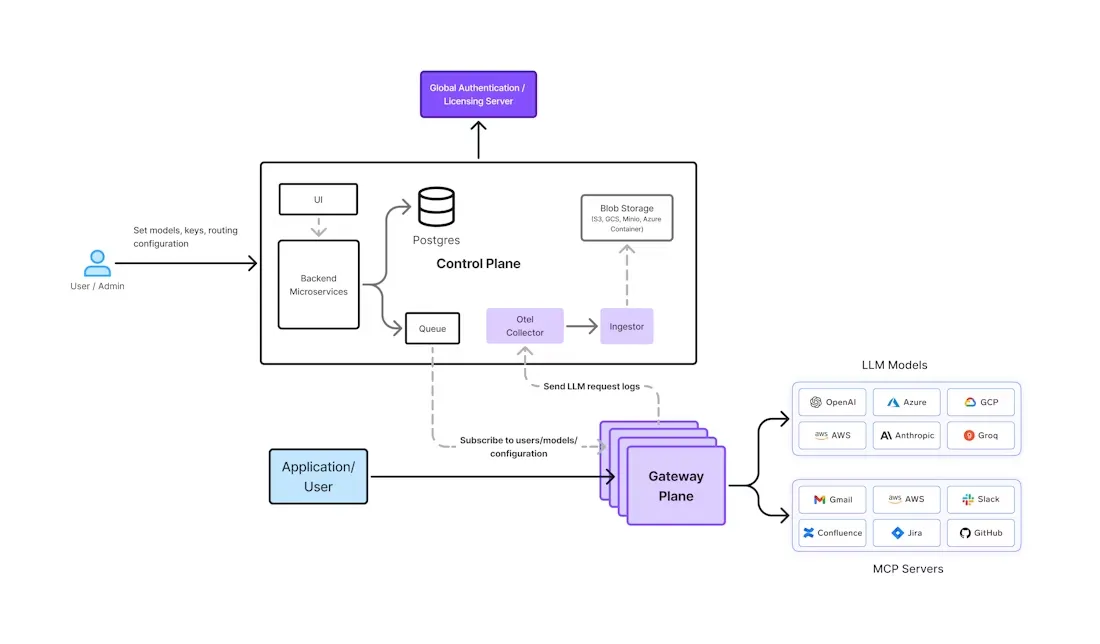
図1:TrueFoundryのAIゲートウェイのアーキテクチャ。中央のコントロールプレーン(左)が、グローバルに分散されたゲートウェイポッド(右)に設定をプッシュします。すべてのポリシーチェック(認証、レート制限、ルーティング)は、各ポッドのメモリ内で実行されます。
TrueFoundryの ゲートウェイポッドは、コントロールプレーンからのNATSメッセージストリームを購読します。新しいユーザー権限、モデル構成、バランシングルールなどのポリシー変更はNATSに公開され、すべてのポッドで即座に利用可能になります。ゲートウェイポッドにリクエストが到着すると、 すべての重要なチェックはインメモリで実行され、余分なネットワークホップは発生しません これには、JWT認証、RBACチェック、レート制限の適用、モデルの負荷分散決定が含まれます。その結果、TrueFoundryのテストでは、リクエストあたりのレイテンシーオーバーヘッドはわずか数ミリ秒程度であることが示されています。フル・トレーシング(各プロンプトとトークン数をログに記録)下でも、最新のハードウェアはポッドあたり毎秒数百のリクエストを処理し、ポッドを追加することでシステムは線形にスケーリングします。
舞台裏では、承認されたリクエストは選択されたAIプロバイダーまたはモデルのエンドポイントにルーティングされます。応答が成功した場合、それは直ちにクライアントに返送されます。同時に、リクエストと応答からのメタデータ(使用されたトークン、レイテンシー、ユーザー、モデル)は、非同期的にメッセージキューに公開されます。バックエンドの分析サービスは、これらのイベントをClickHouse(ブロブストレージ経由)に取り込み、使用量とコストのメトリクスを計算します。この非同期パイプラインにより、ロギングと分析がライブトラフィックパスをブロックすることはありません。ダッシュボードとAPIクライアントは、集約されたテレメトリー(OpenTelemetry標準経由)をクエリして、モデル、チーム、または期間ごとの使用状況を追跡できます。
セキュリティは全体にわたって適用されます。TrueFoundryのゲートウェイは、きめ細かな RBAC により、チームは許可されたモデルのみを表示および呼び出すことができます。すべてのAPIキーとトークンは一元的に管理でき、詳細な 監査ログ はすべてのアクション(タイムスタンプ、ユーザーID、使用されたモデルなど)を記録します。カスタムコンテンツ ガードレール はポータルで定義でき(例えば、キーワードフィルターやコンテキスト認識ルールなど)、ゲートウェイはポリシーに違反する応答をブロックまたはフラグ付けします。TrueFoundryはエンタープライズIDプロバイダーとも統合されており、IdP(SAML/OIDC経由のSSO)からロールを同期し、それらをゲートウェイの権限に自動的に適用できます。
その他の機能には、マルチモーダルサポート(同じAPIでテキスト、画像、音声、埋め込みをシームレスに処理)と、組み込みのプロンプト管理システムがあります。ゲートウェイは プロンプトプレイグラウンド を提供しており、プロンプトを一元的にバージョン管理およびテストするためのもので、特に本番プロンプトを反復処理するチームにとって役立ちます。また、グローバルな予算およびレート制限制御も提供します。例えば、チームごとに月額ドルクォータを設定したり、プロジェクトごとにトークンベースの予算を適用したりできます。実際には、TrueFoundryのゲートウェイを使用する組織は、トークンの使用状況(プロバイダーやモデルごとに内訳も表示)を即座に把握でき、予算を超過した場合には自動的に停止したりユーザーに通知したりできます。
デプロイの柔軟性は、TrueFoundryの設計の特長です。AIゲートウェイは、マネージドSaaS(低レイテンシーと高可用性のために複数のクラウドリージョンにノードを持つ)として実行することも、独自のクラウド/オンプレミス環境にインストールすることもできます。どちらの場合も、パフォーマンスへの影響は最小限です。最近のFAQによると、TrueFoundryのSaaSはリクエストあたり5ミリ秒未満のオーバーヘッドしか追加しません。任意のKubernetesクラスター(またはエッジ)にデプロイできるため、ゲートウェイポッドをアプリケーションやデータソースの近くに配置して、ラウンドトリップ時間をさらに短縮できます。TrueFoundryはセキュアなオンプレミス運用もサポートしています。クラウドライセンスサーバーに送信されるデータは匿名化された使用状況メトリクスのみであり、必要に応じて完全なコントロールプレーンのデプロイメントをファイアウォールの内側に維持できます。
どのAIゲートウェイもすべてのシナリオに完璧というわけではありません。優先順位に合わせて選択してください。
いずれの場合も、これらの要件を評価チェックリストと照合してください。プロジェクトにとって最も重要な要素(セキュリティ、コスト、機能など)に基づいて、基準に重みを割り当ててください。TrueFoundryの評価フレームワークはカスタマイズ可能であり(公開CSVとして利用可能)、必要な機能を正確に比較してベンダーを評価できます。目標は、今日のニーズを満たすだけでなく、AIイニシアチブとともに成長できるゲートウェイを選択することです。
AIの導入が進むにつれて、専用のゲートウェイは必須の制御レイヤーとなりつつあります。これは、API、コスト、セキュリティリスクが混沌と混在する状況に秩序をもたらします。ルーティング、可観測性、予算管理、コンプライアンスを1か所で処理することで、AIゲートウェイはAIインフラストラクチャを信頼性の高い、統制されたプラットフォームに変えます。 TrueFoundryのAIゲートウェイ はこれらの原則に基づいて構築されており、エンタープライズグレードのセキュリティ、監視、ポリシー制御を備えた数百のモデルへの統合インターフェースを提供します。
ゲートウェイを選択する際は、構造化されたアプローチを使用してください。ワークロードを理解し、評価チェックリストを参照し、ルーティングの柔軟性、パフォーマンス、可観測性、コスト管理、ガバナンス機能に関して各オプションがどのように優れているかを比較します。そうすることで、組織のLLMおよびエージェントベースのアプリケーションの「AIコントロールプレーン」として機能するソリューションを選択できます。堅牢なゲートウェイは、予算とデータを保護するだけでなく、すべてのAIサービスに一貫性のあるスケーラブルな基盤を提供することで開発を加速します。最終的に、適切なAIゲートウェイに投資することは、AIユースケースを実験段階からエンタープライズ規模の現実へと安全に移行させる道を開きます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。





.webp)




.png)








.webp)
.webp)


