














November 5, 2025
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
On June 9, 2026, Anthropic did something it had never done before: it handed the public a model from its top-secret "Mythos" tier, the class of models that, until now, only cyber-defense partners and a handful of biology researchers were allowed to touch. The public-safe version is called Claude Fable 5, and it doesn't sit in the Opus family. It sits above it.
If you've spent the last year watching models inch forward half a point at a time on a benchmark, Fable 5 is a jolt. It posts 80.3% on SWE-Bench Pro while the next-best model sits 11 points behind. It finished a migration in a 50-million-line codebase in a day. And Andrej Karpathy called it "a major-version-bump-deserving step change forward." This guide covers what it is, how it benchmarks, what it costs, and exactly how to put it into production, with every figure traced back to Anthropic's launch materials.
Think of Anthropic's lineup as a ladder: Haiku for speed, Sonnet for balance, Opus for hard problems, and now Mythos-class for the genuinely brutal ones. Fable 5 is the first Mythos-class model released for general use. It's designed for ambitious, long-running, asynchronous tasks: large-scale code migrations, multi-day agentic sessions, deep research, and dense knowledge work that previous models simply couldn't hold together.
Anthropic's own framing is the key insight: "the longer and more complex the task, the larger Fable 5's lead over our other models." On a quick one-shot question, you might not notice the difference. Hand it a problem that takes hours and dozens of steps, and the gap becomes obvious.
One wrinkle worth understanding up front: Fable 5 shares its underlying weights with Claude Mythos 5, a restricted release for vetted cybersecurity and biology partners that runs the same model with certain safeguards removed. Fable 5 is the safe-for-everyone twin. (Anthropic notes the name comes from the Latin fabula, "that which is told", a cousin of the Greek mythos. The safeguards are the only thing separating the two.)
Here's the complete benchmark set Anthropic published at launch. A few things to read carefully:
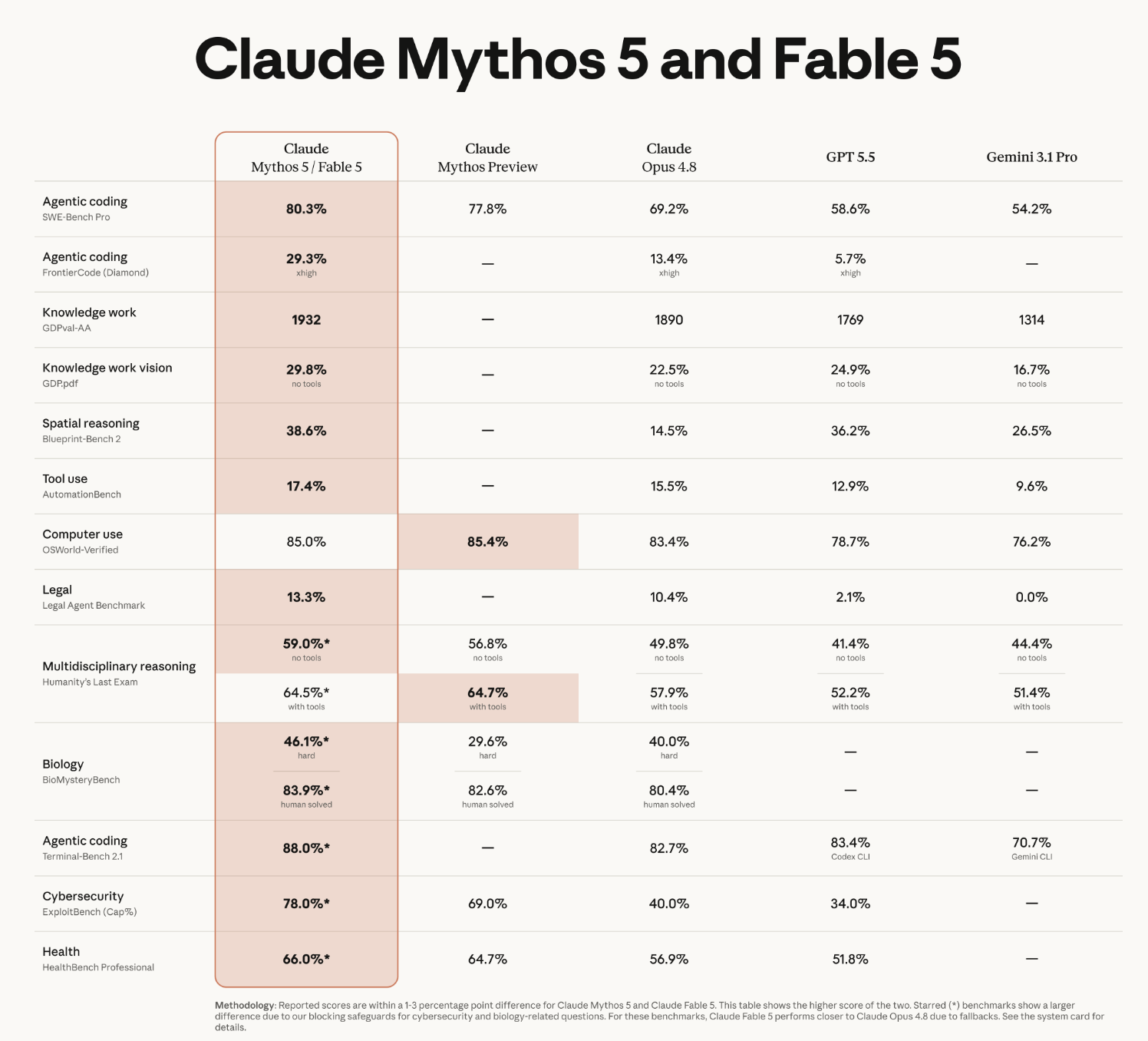
Andrej Karpathy's launch-day reaction captured the mood, and notably backed up the "step change" framing with a qualitative read, not just the scores:

"The benchmarks are great and it's SOTA on everything by a margin but I'll add that qualitatively also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model 'gets it' and it will just go..."
He also flagged the catch that early users are running into: the launch-day safeguards are "configured to be a little too trigger happy," something Anthropic itself acknowledges and says it will tune over time. Which brings us to the part of Fable 5 every API builder needs to understand.
Because Mythos-class capabilities carry real misuse risk, Fable 5 ships with classifiers covering cybersecurity, biology/chemistry, and distillation. When a request trips one, it's automatically answered by Claude Opus 4.8 instead, and the user is told. Anthropic reports this happens in fewer than 5% of sessions; over 95% of Fable sessions involve no fallback at all.
This is also exactly why the starred benchmark rows above matter: on those cyber/bio tasks, the published high score is Mythos 5's, while Fable 5, with safeguards active, performs closer to Opus 4.8.
What you need to know as a developer:
A gateway helps here: you can log which requests fell back, route them consistently, and keep the behavior uniform across your app.
Fable 5 is a premium model, roughly 2x the price of Claude Opus 4.8. Full token economics:
The nuances that decide your real bill:
Because Fable 5 is both expensive per token and token-hungry on long tasks, cost control isn't optional. Routing it through a gateway lets you cap spend, cache aggressively, and reserve Fable 5 for the jobs that actually justify it.
Fable 5 is available today on:
ClaudeコンソールからAPIキーを取得し、以下の文字列でモデルを呼び出します claude-fable-5。Anthropicのクイックスタートでは、認証と最初のリクエストの手順が説明されています。詳細は Claude APIドキュメントをご覧ください。
APIを直接呼び出す方法は、簡単なテストや単一のアプリケーションには最適です。しかし、Fable 5が複数のチームで本番環境に導入されると、アクセス制御、予算管理、フォールバックが必要になります。そこでゲートウェイの出番です。
APIへの直接アクセスはプロトタイプ作成には十分です。しかし、Fable 5のようなプレミアムでトークン消費の多いモデルを組織全体で運用するのは別の問題です。誰が利用できるかを制御し、費用を制限し、セーフガードのフォールバックを一貫して処理し、プロバイダー全体のコストを一元的に把握する必要があります。ゲートウェイはアプリケーションとモデルの間に位置し、これらすべてを処理します。
実際には、プラットフォームチームはFable 5を数分で全社的に有効にできます。費用管理とフォールバックはすでに設定されており、各チームが生のAPIを接続し、費用が妥当な範囲に収まることを願う必要はありません。
TrueFoundryゲートウェイで、接続済みの Anthropic プロバイダーを検索し、 claude-fable-5 を モデル選択 画面で有効にし(その$10 / $50の料金はインラインで表示されます)、そして アクセス制御 を使用して、どのチームと仮想キーがそれを呼び出せるかを決定します。
を開きます。 プレイグラウンド、選択し、 claude-fable-5、既製の 利用コードスニペット。TrueFoundryは、OpenAI、LangChain、Node.js、cURL、LlamaIndexなど向けに、ストリーミングモードと非ストリーミングモードの両方でこれを生成します。
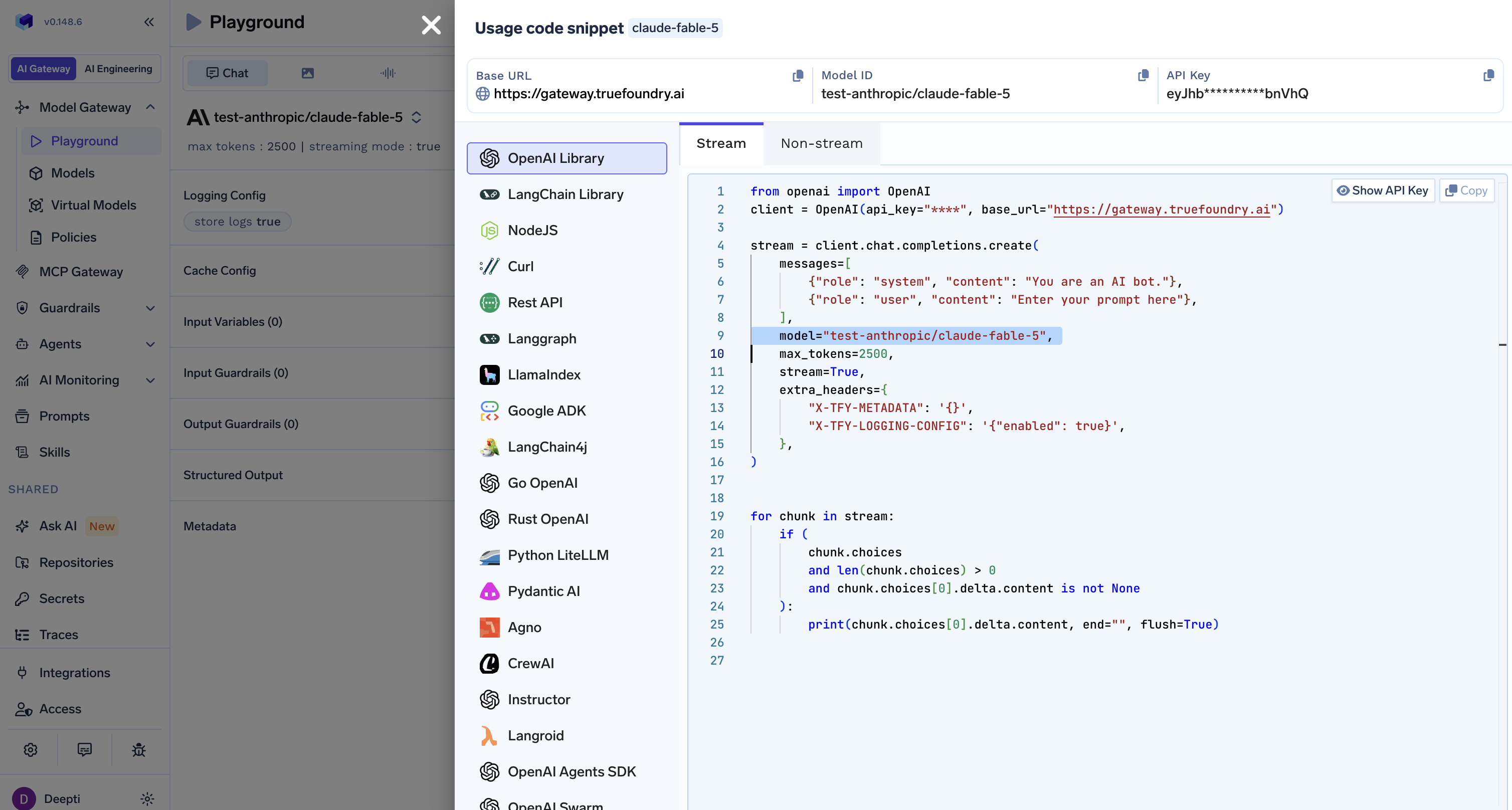
メリットは、Fable 5、Opus 4.8、GPT-5.5、またはその他のモデル間の切り替えが1行の変更で済み、すべての呼び出しが管理され、ログに記録され、監視可能であることです。 X-TFY-LOGGING-CONFIG と X-TFY-METADATA ヘッダーを追加して、チームごとまたは機能ごとの費用をタグ付けし、追跡します。
コスト管理とフォールバック機能を初日から備えたFable 5を本番環境に導入する準備はできていますか? TrueFoundry AI GatewayでClaude Fable 5をお試しください。
Fable 5は、大規模な移行、多段階エージェントワークフロー、詳細な調査、複雑な文書分析など、Karpathy氏の言う「もっと野心的なタスクを与える」ことが実際に報われるような、本当に困難で時間がかかるタスクに利用してください。より短く、レイテンシーに敏感な、または大量の作業には、Opus 4.8(半額)またはより小さなモデルを使用する方が、通常は賢明な選択です。ほとんどのチームが落ち着くパターンは次のとおりです。 タスクの複雑さでルーティングする、困難で価値の高いジョブはFable 5へ、それ以外のすべてはより安価なモデルへ、すべて1つのゲートウェイから行います。
Claude Fable 5のAPIモデル名は何ですか? claude-fable-5は、Claude APIおよび主要なクラウドマーケットプレイスを通じて利用可能です。
Claude Fable 5の料金はいくらですか? 入力トークン100万あたり10ドル、出力トークン100万あたり50ドルです。入力には90%のプロンプトキャッシュ割引が適用され、Claude Opus 4.8の約2倍の料金となります。
コンテキストウィンドウはどのくらいですか? 100万トークンで、テキスト、画像、ファイル入力に対応しています。
Claude Fable 5はGPT-5.5より優れていますか? SWE-Bench Proでは、Fable 5 (80.3%) はGPT-5.5 (58.6%) を上回り、Anthropicが公開したほぼすべてのベンチマークで優位に立っています。導入を決定する前に、ご自身のワークロードで検証してください。
Fable 5とMythos 5の違いは何ですか? 基盤となるモデルは同じです。Fable 5は一般利用向けに安全性が確保されたリリースであり、Mythos 5は特定のセーフガードを解除し、厳選されたパートナーに限定されています。
私のリクエストがOpus 4.8の応答を返したのはなぜですか? Fable 5のセーフガードが、サイバーセキュリティ、生物学、化学、蒸留に関するクエリをOpus 4.8にルーティングしました(セッションの5%未満)。これらのクエリに対してFableの料金は請求されません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


