













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
2026年には、企業はLLMゲートウェイを間に合わせの AIゲートウェイに改造する余裕はもはやありません。AIは顧客対応ワークフローにますます深く組み込まれるようになり、信頼性の高いAI搭載アプリケーションには専用のゲートウェイ層が不可欠となります。一般的な企業のAIインフラは、多くの場合、マルチモデル、マルチチーム、マルチクラウドであり、これがコンプライアンスとコスト説明責任を複雑にしています。
ガートナーはAIゲートウェイを、アプリケーションと様々な人工知能(AI)サービスまたはモデルとの間の仲介役として機能するテクノロジーまたはプラットフォームと定義しています。その目的は、AI機能へのアクセスを簡素化・管理し、AIワークロードのセキュリティ、ガバナンス、可観測性を実現するための一元的なポイントを提供することです。全文は ガートナー マーケットガイド for AIゲートウェイ 2025 をご覧ください。
昨年1年間で、GenAIのガバナンスとレジリエンスの問題に対処するため、主に3つのカテゴリが出現しました。
各カテゴリは、AI導入の異なるフェーズに最適化されています。あるフェーズに最適化されたツールを別のフェーズに無理に適用しようとすると問題が生じます。
このブログでは、すべての競合調査をまとめ、決定版の全体像として提示します。各プラットフォームがどこに適合し、どこで限界を迎えるのか、そして企業が自社の要件に最適なベンダーを選ぶ際に考慮すべき点について解説します。
1. Kong AI:AI向けに適合した従来のAPIゲートウェイ
Kongは、Kubernetesベースのマイクロサービスアーキテクチャでよく使用されるAPIゲートウェイです。Kong AIは、この基盤の上に、大規模言語モデルへのトラフィックルーティングを目的としたプラグインと統合機能を導入しています。
Kong AIの強み
Kong AIの限界
AIの利用が拡大するにつれて、これらの課題はより顕著になります。コストの帰属、モデル選択戦略、AI固有のガバナンスは、ゲートウェイの外、多くの場合アプリケーションコード内で処理する必要があります。
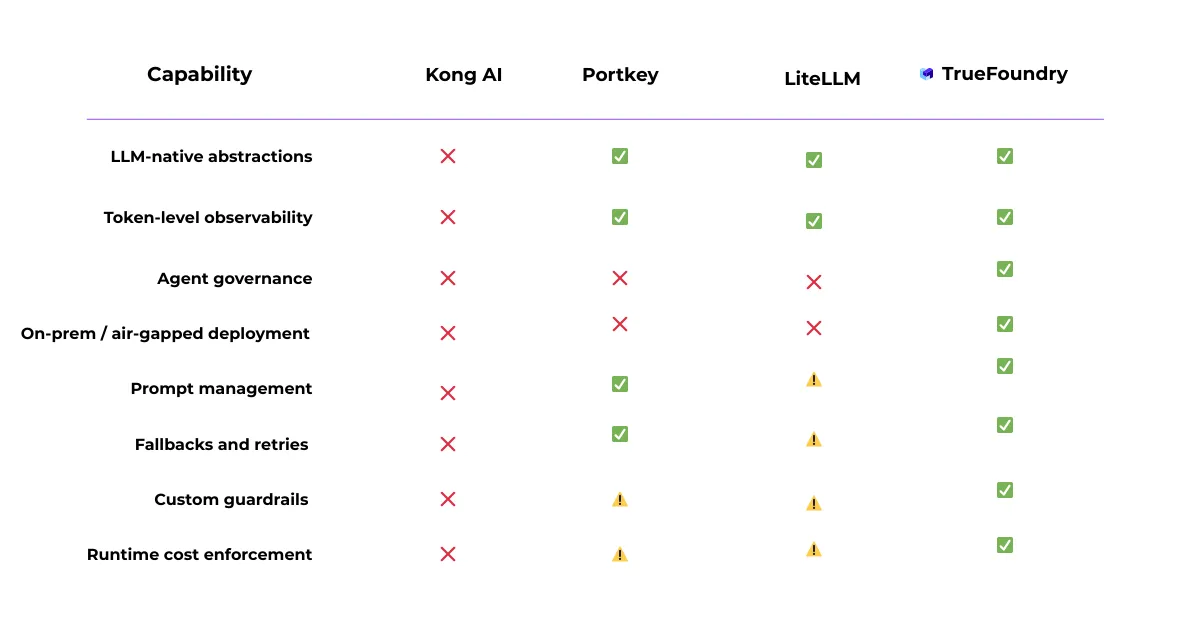
要するに: Kong AIはAPIゲートウェイとしては効果的ですが、AIはネイティブな抽象化というよりも、副次的な懸念事項に留まっています。
2. Portkey:アプリケーションレベルのLLMゲートウェイ
Portkeyは、LLMアプリケーション向けに特化して設計されたAIゲートウェイです。AIリクエストを一般的なHTTP呼び出しとして扱うのではなく、Portkeyはプロンプトとモデルを意識したルーティングと可観測性を提供します。
Portkeyの強み
Portkeyの限界
Portkeyの設計は意図的にアプリケーションに焦点を当てており、それがエンタープライズ規模での制約を生み出しています。
AIが単一のアプリケーション機能ではなく、共有の社内機能となるにつれて、これらの制約により追加のインフラ層が必要となることがよくあります。
最適な用途: 初期プロダクション段階に移行する単一チームのLLMアプリケーション
3. LiteLLM:開発者優先のオープンソースゲートウェイ
LiteLLMはオープンソースの LLMゲートウェイ であり、数十のモデルプロバイダーにアクセスするための統一されたOpenAI互換APIを提供します。
LiteLLMの強み
LiteLLMの弱点
最適: LiteLLMは効果的な導入点ですが、規制された環境や複数チームでの利用には大幅な拡張が必要です。
あわせて読みたい: Portkey vs LiteLLM
4. AWS Bedrock: サーバーレスモデルAPI
AWS Bedrockは、AnthropicやAmazonなどのプロバイダーが提供する基盤モデルへのマネージド型サーバーレスアクセスを提供します。インフラストラクチャを完全に抽象化し、トークン使用量のみで課金されます。
AWS Bedrockの優れた点
AWS Bedrockの隠れたトレードオフ
これらのトレードオフは、ワークロードが実験段階から持続的な本番利用へと移行する際に、チームを驚かせることがよくあります。
結論: Bedrockは速度とシンプルさを最適化しており、長期的なコスト効率や制御には向きません。
5. AWS SageMaker: マネージド型MLインフラストラクチャ
SageMakerは、機械学習モデルのトレーニング、チューニング、デプロイのための包括的なスイートを提供します。Bedrockとは異なり、インフラの選択肢をユーザーに直接提示します。
AWS Sagemakerの強み
AWS Sagemakerの課題
結論: SageMakerは制御性を提供する一方で、運用のシンプルさを犠牲にします。
6. Databricks:レイクハウスMLプラットフォーム
Databricksは、データファーストの視点からAIに取り組み、MLとGenAIの機能をレイクハウスアーキテクチャに統合しています。
Databricksの強み
Databricksの弱点
要するに: Databricksはデータエンジニアリングには優れているが、AIサービングは苦手である。
共通の課題:ガバナンスのないゲートウェイ
~全体にわたって KongとLiteLLM、Portkey、さらにはBedrockにおいても、同じ問題が浮上します。それらはAIシステムではなく、リクエストを管理しているのです。
ゲートウェイやマネージドサービス全体で、共通の課題が見られます。ほとんどのツールはシステムではなくリクエストに焦点を当てているのです。
それらは次のような質問に答えます。
しかし、次のような点には苦慮します。
これらはインフラレベルの懸念事項です。
TrueFoundryはスタックの異なる層に位置します。APIルーティングやマネージドサービスのみに焦点を当てるのではなく、AIワークロード(モデル、エージェント、サービス、ジョブ)を第一級のインフラオブジェクトとして扱います。これにより、責任がアプリケーションコードからプラットフォーム自体へと移行します。
TrueFoundry AI Gatewayは、以下の主要な原則に基づいて構築されています。
これは、AI Gatewayがより大規模なシステムの一部であり、企業がAIユースケースをシームレスに拡張できるようにすることを意味します。
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

TrueFoundry AI Gatewayは、AIの利用が個別のアプリケーションを超え、共有され、本番環境で不可欠な機能となる場合に重要になります。その段階では、課題は個々のモデル呼び出しよりも、チームや環境全体での運用の一貫性に関するものになることがよくあります。
TrueFoundryのAI Gatewayが他のソリューションとどう異なるかをご紹介します。
多くのAIツールは、ルーティング、リトライ、基本的な可観測性といったリクエストレベルの懸念事項に焦点を当てています。これは通常、初期段階では十分です。
しかし、利用が拡大するにつれて、モデルやエージェントは、より長期間稼働するサービスのように振る舞うようになります。チームは、より明確な所有権、ライフサイクル管理、および運用上の境界を必要とします。TrueFoundryは、AIワークロード(モデル、サービス、ジョブ)を、定義されたデプロイメントとランタイム特性を持つインフラストラクチャコンポーネントとして管理するように設計されています。
多くのスタックでは、アクセス制御と利用ポリシーは、アプリケーションまたはSDKレベルで設定されます。時間が経つにつれて、サービスの数が増えるにつれて、これは一貫性の欠如につながる可能性があります。
TrueFoundryは環境レベルで制御を適用し、デフォルトで開発、ステージング、本番環境を分離します。このレイヤーで定義されたポリシーは、環境内にデプロイされたすべてのワークロードに一様に適用され、アプリケーションごとの設定への依存を減らします。
AIのコストは、個々のリクエストよりも、並行処理、リトライ、バックグラウンドのワークロードによって増加することがよくあります。TrueFoundryは、実行中の並行処理、スループット、リソース使用量に制限を設けることで、この問題に対処します。
これにより、利用規模が拡大するにつれて、組織は共有インフラストラクチャをより予測可能に管理できるようになります。
トークンレベルのメトリクスは有用ですが、本番環境でのシステム動作を完全に説明するものではありません。TrueFoundryは、リクエストレベルのシグナルをCPU/GPU使用率やオートスケーリングの挙動といったインフラストラクチャメトリクスと関連付け、チームがパフォーマンスとコストの要因を文脈の中で理解できるよう支援します。
一部の組織は、プライベートネットワーク、オンプレミスデプロイメント、または厳格なデータレジデンシーを必要とする制約の下で運用されています。TrueFoundryはこれらの環境で動作するように設計されており、組織内の他の場所で適用されているのと同じインフラストラクチャ標準を使用してAIワークロードを管理できます。
まとめ
現在のAIプラットフォームの状況は、生成AIが進化してきた速度を反映しています。多くのツールは、ルーティング、モデルアクセス、可観測性、トレーニングといった実際の問題に対処していますが、それぞれ異なる出発点からアプローチしています。その結果、AIが本番環境で不可欠になるときに生じる運用要件のすべてを、単一のカテゴリで自然にカバーすることはできません。
TrueFoundryは、AIワークロードを他の本番システムと同じ規律で運用する必要がある場合に、最大の価値を提供します。これは、環境をまたぎ、共有ポリシーの下で、予測可能なリソース挙動を実現することを意味します。
ベンダーを比較する企業は、多くの場合、まず「最高の LLMゲートウェイ」を探すことから始めますが、真の差別化要因は、プラットフォームがAIシステムを大規模にどれだけうまく統制できるかにあります。各プラットフォームがどこに適合し、その設計上の前提がどこで破綻し始めるかを理解することは、 最高のAIゲートウェイ を企業規模のデプロイメントにとって評価する上で不可欠です。適切な選択は、個々の機能よりも、組織がAIの使用を時間とともにどのように進化させたいかにかかっています。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


The best AI gateway depends on the organization's specific requirements. TrueFoundry's AI Gateway stands out for enterprises needing multi-provider routing, centralized governance, cost tracking, and MCP integration in a single platform. Other strong options include LiteLLM for open-source flexibility and Kong AI Gateway for teams already invested in Kong's API management ecosystem.
An AI gateway is a middleware layer that sits between applications and LLM providers (such as OpenAI, Anthropic, or Google). Its architecture typically includes a routing engine that directs requests to the appropriate model, a policy layer for enforcing rate limits and access controls, an observability stack for logging and cost tracking, and a caching layer to reduce redundant API calls. This architecture allows organizations to manage multi-model deployments from a single control plane.
TrueFoundry differentiates itself by combining AI gateway capabilities with a full ML infrastructure platform including model serving, fine-tuning, and MCP server management in a unified solution. Its AI Gateway offers enterprise-grade features such as per-team budget controls, audit logging, model fallback routing, and native MCP support, making it particularly well-suited for organizations looking to govern and scale Claude Code and other agentic AI deployments






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


