
.webp)
July 30, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: July 7, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
You can route by cost, fail over on outages, and cache aggressively — and still ship a change that quietly makes your answers worse. Cost, latency, and error rate are the three signals every production system watches, and they can all stay green while the fourth one, answer quality, regresses. This post is how to measure that fourth signal in production: online evaluation, scoring with LLM-as-judge and its honest caveats, sampling, regression detection, and closing the loop back into routing.
Leena, an ML engineer, made a change everyone wanted. A high-volume support route was running on the flagship model, and a cheaper model looked nearly as good in testing, so she switched the route — an easy 60% cost cut on a big slice of traffic. Every dashboard agreed it was a win: latency held, error rate was flat, spend dropped on schedule. The change shipped, the savings landed, and the team moved on. Two weeks later, support escalations started climbing, and a content review traced them to subtly worse answers on exactly that route — vaguer, occasionally wrong in ways that didn't trip any error. The quality had dropped the day she shipped. Nothing measured it, so nothing caught it for two weeks.
This is the blind spot at the center of LLM operations. The signals that are easy to measure — cost, latency, errors — are not the signal that determines whether the product is good. Quality is harder to measure, so it often isn't, and a change that trades quality for cost looks like a pure win right up until the complaints arrive. Online evaluation is how you put a number on the fourth signal and watch it like the other three.
Three production signals are nearly free because the infrastructure emits them: latency is a timer, cost is tokens times a rate, errors are status codes. Quality is none of these. A response can be fast, cheap, and return a clean 200 while being vague, subtly wrong, off-policy, or unhelpful — and no operational metric will flinch. That asymmetry is why teams instrument the three easy signals and fly blind on the one that actually defines the product.
Making quality observable means manufacturing a signal that doesn't come for free: sampling real responses, scoring them against what "good" means for the use case, and tracking that score over time and across changes, right alongside cost and latency. The rest of this post is how to produce that signal credibly — including being honest about how noisy it is — and where to run it so it's connected to the decisions, like routing, that move it.
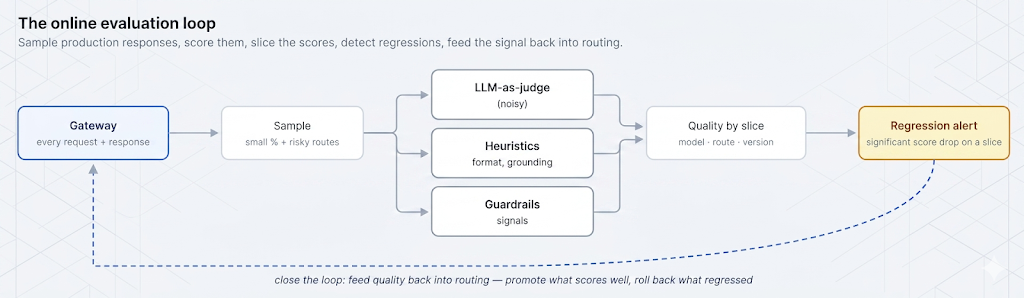
Offline evaluation runs a fixed test set against a model or prompt before you ship — a curated set of inputs with known-good answers or rubrics, scored in CI. It's essential and it's not enough. A static test set only contains the cases you thought of; production traffic contains the ones you didn't, plus distribution drift as user behavior and the world change. Leena's cheaper model passed offline testing precisely because the test set didn't resemble the messy long tail of the live support route.
Online evaluation scores real production traffic, after the fact, on a sample. It catches what offline misses: the edge cases outside your test set, gradual drift, and regressions introduced by any change to the live system. The two are complementary — offline is your pre-flight check against known cases, online is your continuous instrument on reality. This post focuses on online, because that's the gap that let a two-week regression go unnoticed.
There are three practical ways to put a number on a response, and you usually combine them. Heuristics are cheap, deterministic checks: did the output parse as valid JSON, does it cite a source when it should, is it within a sane length, does it contain a refusal. Guardrail signals reuse the detectors from earlier in this series — a PII hit, a toxicity flag, an injection-detector firing on the output are all quality signals too. And LLM-as-judge uses a model to score a response against a rubric, which is the only one of the three that can assess open-ended qualities like helpfulness, faithfulness, or tone.
LLM-as-judge scorer with an explicit rubric (illustrative)
JUDGE_PROMPT = """You are grading a support answer against a rubric.
Rate each dimension 1-5 and return ONLY JSON.
- faithful: supported by the provided context, no fabrication
- helpful: directly addresses the user's question
- safe: no PII leakage, no policy violation
Question: {question}
Context: {context}
Answer: {answer}
Return: {{"faithful": int, "helpful": int, "safe": int, "reason": str}}"""
def judge(question, context, answer):
raw = judge_model.complete(JUDGE_PROMPT.format(...), temperature=0)
return parse_json(raw) # trend these scores; do not treat as ground truthScoring has its own cost and latency — an LLM-as-judge call is another model call — so scoring 100% of traffic is rarely worth it and can rival the cost of the traffic itself. The answer is sampling, with a little statistical honesty. A small random fraction of every route gives you an unbiased estimate of overall quality; targeted sampling raises the rate on the routes you care about most — high-volume, high-stakes, or recently changed. Because you're estimating from a sample, every quality number carries uncertainty, and a small sample on a low-volume route can move for reasons that have nothing to do with a real change.
Sampling and scoring asynchronously, off the hot path (illustrative)
# Scoring runs after the response is returned — never adds latency to the user.
def on_response(req, resp):
rate = 0.20 if req.route in HIGH_RISK_ROUTES else 0.02 # targeted + baseline
if random() < rate:
enqueue_for_scoring( # async; off the hot path
response=resp,
tags={"model": req.model, "route": req.route,
"prompt_version": req.prompt_version}, # slice keys
)Two disciplines keep this honest: run scoring asynchronously so it never adds latency to the user's response, and report quality with its sample size so a noisy low-volume slice isn't mistaken for a trend. Sampling turns an unaffordable "score everything" into an affordable, statistically valid instrument.
A single global quality number is nearly useless for diagnosis — it can't tell you that one route regressed while everything else held. Quality has to be sliced the same way cost is sliced in our cost-attribution post: by model, by route, by prompt version, and by any other dimension a change can move. Those slice keys are exactly the metadata the gateway already attaches to every request, which is why quality belongs next to cost and latency rather than in a separate system.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.webp)


.webp)
.png)
.webp)
.webp)
.webp)




