.webp)
April 22, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Mis à jour : April 7, 2026




Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
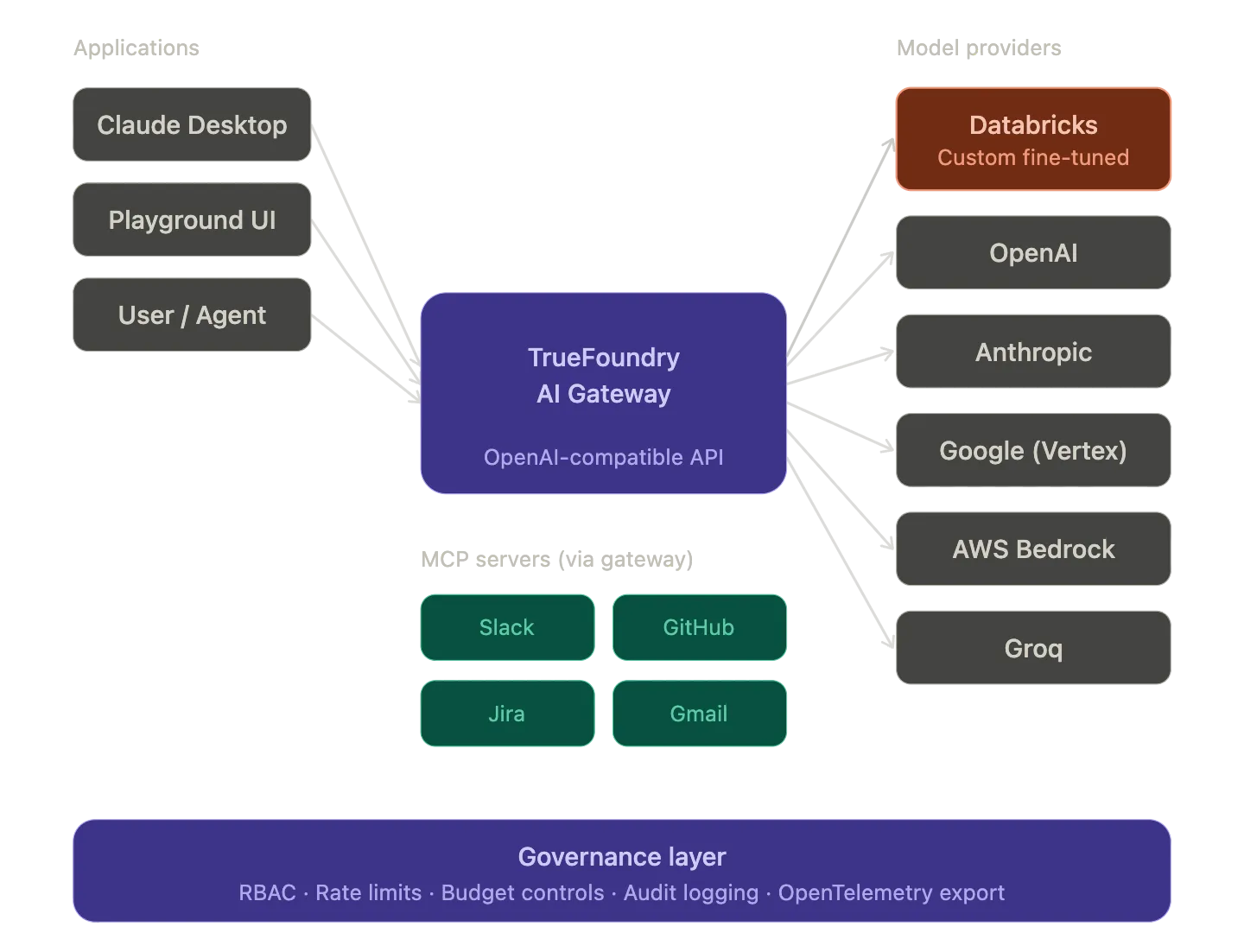
TrueFoundry AI Gateway enregistre Databricks Model Serving en tant que fournisseur de premier ordre et achemine le trafic d'inférence vers celui-ci via le même point de terminaison compatible OpenAI qui gère tous les autres fournisseurs de votre stack. L'intégration va au-delà du routage des modèles. La passerelle MCP de TrueFoundry se trouve en face des serveurs MCP gérés par Databricks pour renforcer l'authentification, le contrôle d'accès au niveau des outils et la journalisation des audits pour les flux de travail des agents qui interrogent Unity Catalog.
Cet article passe en revue quatre points d'intégration : la couche d'enregistrement et de routage du fournisseur AI Gateway pour les points de terminaison de Databricks Model Serving. La couche de gouvernance de MCP Gateway pour les serveurs MCP gérés par Databricks. Le plan de routage du modèle virtuel qui permet le basculement multifournisseur entre les modèles hébergés de Databricks et les API commerciales. Et la couche d'orchestration des flux de travail qui déclenche les jobs Databricks en tant que tâches natives dans les pipelines TrueFoundry. Chaque section comprend une configuration fonctionnelle et suffisamment de détails architecturaux pour évaluer si cette intégration convient à votre stack.
TrueFoundry AI Gateway utilise une architecture divisée. Un plan de contrôle gère la configuration, y compris les modèles et les utilisateurs, ainsi que les règles de routage et les limites de débit. Un plan de passerelle traite les demandes d'inférence réelles. Le plan de contrôle enregistre son état dans PostgreSQL et ClickHouse et synchronise toute la configuration avec les pods de passerelle via un NATS file d'attente de messages. Les mises à jour se propagent en temps réel sans redémarrage.
Le plan de passerelle est construit sur le Cadre Hono et effectue toutes les vérifications d'authentification, d'autorisation et de limitation de débit en mémoire. Un seul module de passerelle sur 1 processeur virtuel et 1 Go de RAM gère plus de 250 demandes par seconde avec environ 3 ms de latence supplémentaire. Le pod peut atteindre plus de 350 images par seconde avant la saturation du processeur. La mise à l'échelle horizontale via des pods supplémentaires étend le débit à des dizaines de milliers de requêtes par seconde.
Lorsqu'une requête atteint la passerelle, le traitement suit une séquence stricte, sans appel externe dans le hot path :
Le seul appel externe sur ce chemin est l'appel réel du fournisseur LLM. Les journaux et les métriques sont écrits dans le NATS de manière asynchrone une fois la réponse terminée. La passerelle ne fait jamais échouer une demande, même si la file d'attente NATS est temporairement inaccessible.
Vous enregistrez Databricks Model Serving en tant que fournisseur dans AI Gateway en fournissant des informations d'authentification et l'URL de votre espace de travail. TrueFoundry prend en charge deux méthodes d'authentification.
Authentification du principal de service est l'approche recommandée pour la production. Vous fournissez l'ID client et le secret OAuth générés dans les paramètres de votre espace de travail Databricks sous Service Principals. Cela utilise le flux d'informations d'identification du client OAuth 2.0.
Authentification par jeton d'accès personnel travaille pour le développement et les tests. Vous fournissez directement un PAT Databricks.
Dans les deux cas, vous fournissez également l'URL de base de l'espace de travail (par exemple <workspace_id>https://.cloud.databricks.com).
Une fois le fournisseur enregistré, vous ajoutez des modèles individuels. Le ID du modèle dans TrueFoundry doit correspondre exactement au nom du point de terminaison du serveur dans votre espace de travail Databricks. Tout modèle desservi par Databricks devient routable via la passerelle. Cela inclut les modèles de base disponibles via Databricks et les modèles personnalisés et affinés de Mosaic AI et des modèles tiers accessibles via Databricks Model Serving.
Le code de l'application atteint une URL quel que soit le fournisseur sous-jacent. La passerelle assure la traduction entre le format compatible OpenAI et les attentes du fournisseur en aval.
depuis openai, importez OpenAI
client = OpenAI (
base_url= » https://your-truefoundry-gateway.com/api/llm «,
api_key="your-truefoundry-api-key »
)
# Cette demande est acheminée via la passerelle vers Databricks Model Serving.
# Le code de l'application ne sait pas ou ne se soucie pas du fournisseur qui le dessert.
réponse = client.chat.completions.create (
model="databricks-main/custom-finetuned-lama »,
messages= [{"role » : « user », « content » : « Analysez les tendances de désabonnement au troisième trimestre"}]
)
Le modèle le champ utilise le format <provider-account-name>/<model-id> où l'ID du modèle correspond au nom de point de terminaison du serveur Databricks que vous avez configuré.
UNE Modèle virtuel est un identifiant de modèle logique qui correspond à plusieurs fournisseurs physiques avec des règles de routage. Votre application appelle un nom de modèle unique et la passerelle gère automatiquement la sélection de la cible et le basculement.
# Cela atteint un modèle virtuel. The Gateway le résout au mieux
# fournisseur physique en fonction de votre configuration de routage.
réponse = client.chat.completions.create (
modèle="assistant de production »,
messages= [{"role » : « user », « content » : « Résumer ce contrat"}]
)
TrueFoundry prend en charge trois stratégies de routage pour les modèles virtuels.
Routage basé sur le poids répartit le trafic selon des pourcentages assignés entre les cibles. Vous pouvez configurer 80 % sur votre modèle affiné hébergé sur Databricks et 20 % sur Claude pour les tests de comparaison. Le routage basé sur le poids prend également en charge le routage permanent qui associe les sessions à une cible à l'aide d'en-têtes de demande ou de métadonnées pour assurer la cohérence des conversations à plusieurs tours.
Routage basé sur les priorités envoie tout le trafic vers la cible saine la plus prioritaire (la priorité 0 est la plus élevée). Si cette cible échoue ou n'est pas disponible, la passerelle revient à la priorité suivante. Cela prend en charge une option Coupure du SLA qui surveille le temps moyen par jeton de sortie sur une fenêtre continue de 3 minutes et marque les cibles comme insalubres lorsqu'elles dépassent un seuil configuré.
Routage basé sur la latence achemine automatiquement vers la cible dont la latence récente est la plus faible. La passerelle utilise temps par jeton de sortie (latence entre jetons) comme métrique. Il prend en compte les demandes des 20 dernières minutes avec un maximum de 100 échantillons. Si moins de 3 demandes existent pour une cible, celle-ci est considérée comme la plus rapide à collecter plus de données. Les cibles sont considérées comme étant aussi rapides si leur latence est inférieure à 1,2 fois la plus rapide afin d'éviter une commutation rapide.
La passerelle surveille en permanence chaque cible et marque les cibles comme étant défectueuses lorsque les défaillances dépassent un certain seuil. Les réponses aux erreurs suivies incluent les codes d'état 5xx et 429 et 401 et 403. Le seuil de défaillance par défaut est de 2 défaillances ou plus au cours d'une fenêtre d'évaluation continue de 2 minutes. Lorsqu'une cible est marquée comme étant défectueuse, elle est déplacée à la fin de la liste de routage et les cibles saines sont toujours essayées en premier. La restauration est automatique une fois que les erreurs ont disparu de la fenêtre d'évaluation.
Chaque cible prend également en charge la configuration des nouvelles tentatives par cible. Les valeurs par défaut sont de 2 tentatives avec un délai de 100 ms entre les tentatives. La nouvelle tentative est déclenchée sur les codes d'état 429 et 500 et 502 et 503. Le retour à une autre cible se déclenche sur 401 et 403 et 404 et 429 et 500 et 502 et 503.
Chaque demande via la passerelle est tracée avec une attribution complète : quel utilisateur et quel modèle, quel fournisseur et quelle latence des demandes, nombre de jetons et coût estimé. La passerelle est conforme à OpenTelemetry et exporte les traces de manière asynchrone via NATS vers un point de terminaison OTEL configurable (gRPC ou HTTP). Vous pouvez les acheminer vers la pile d'observabilité que vous exécutez. Vous disposez ainsi d'un tableau de bord unique pour tous les fournisseurs au lieu de regrouper des indicateurs spécifiques à chaque fournisseur.
Databricks a lancé le support des serveurs MCP gérés à la mi-2025. Ces serveurs permettent aux agents d'accéder en toute sécurité aux ressources du catalogue Unity via le protocole Model Context. Databricks fournit des serveurs gérés pour Génie (accès aux données structurées via le langage naturel) et Recherche vectorielle (données non structurées issues d'index vectoriels) et Fonctions UC (fonctions personnalisées enregistrées dans Unity Catalog). Les autorisations du catalogue Unity sont appliquées automatiquement afin que les agents puissent accéder uniquement aux outils et aux données pour lesquels leur identité est autorisée.
Le défi de la gouvernance est de savoir ce qui se passe entre l'agent et ces serveurs MCP. Sans plan de contrôle, chaque développeur configure ses propres connexions, gère ses propres informations d'identification et crée ses propres politiques d'outils. Il n'existe aucune piste d'audit centralisée permettant de savoir quel agent a appelé quel outil. Aucun moyen d'appliquer l'accès au moindre privilège entre les équipes. Aucun endroit central pour révoquer l'accès lorsque quelqu'un part.
TrueFoundry MCP Gateway se situe entre vos agents (Claude Code et Cursor et frameworks d'agents personnalisés) et vos serveurs MCP (y compris les serveurs MCP gérés par Databricks). Il agit comme un proxy inverse avec authentification, autorisation et journalisation des audits.
Flux d'authentification. Les agents s'authentifient une seule fois auprès de la passerelle MCP à l'aide d'une clé API TrueFoundry ou d'un jeton IdP externe (Okta, Azure AD et Auth0 sont pris en charge). La passerelle gère l'authentification sortante vers chaque serveur MCP en aval. Pour Databricks, cela signifie que la passerelle contient les informations d'identification OAuth ou PAT du Service Principal et que les agents individuels ne touchent jamais aux informations d'identification Databricks brutes.
Contrôle d'accès au niveau de l'outil. La passerelle vous permet d'activer ou de désactiver de manière sélective des outils individuels par équipe. Vous pouvez également regrouper des outils provenant de plusieurs serveurs MCP dans un Serveur MCP virtuel qui n'expose qu'un sous-ensemble sélectionné. Par exemple, votre équipe de data science peut avoir accès à Genie et Vector Search depuis Databricks, ainsi qu'à un serveur de recherche Web, tandis que votre équipe d'ingénierie dispose d'un ensemble d'outils différent.
Rambardes. Le Gateway soutient des garde-corps à quatre crochets. Outil MCP Pre des garde-corps s'exécutent avant que l'outil ne soit appelé et peuvent valider les requêtes SQL, vérifier la présence de données sensibles et appliquer des politiques d'autorisation. Si un garde-corps pré-outil tombe en panne, l'outil ne s'exécute jamais. Outil MCP Post les garde-corps inspectent et réécrivent éventuellement les sorties de l'outil avant de renvoyer les résultats au modèle. Vous pouvez les configurer pour rechercher des informations personnelles et des secrets dans les résultats. Les flux de travail d'approbation des utilisateurs peuvent être configurés pour les opérations à haut risque. Trois stratégies d'application sont disponibles : Faire appliquer (blocage en cas de violation ou d'erreur de garde-corps) et Appliquer mais ignorer en cas d'erreur (bloquer en cas de violation mais autoriser en cas d'erreur de service de garde-corps) et Audit (connectez-vous uniquement et ne bloquez jamais).
Piste d'audit. Chaque appel d'outil est suivi avec l'utilisateur appelant et le serveur MCP, ainsi que la charge utile et la latence de l'outil et de la demande spécifiques, ainsi que la charge utile et la latence. Cela est exporté via OpenTelemetry en même temps que vos traces de requêtes LLM, vous donnant un journal unifié de tout ce que font vos agents.
Si vos développeurs utilisent Claude Code, vous configurez la passerelle MCP en tant que serveur MCP distant. La gouvernance d'entreprise nécessite deux fichiers de configuration distincts déployés via MDM sur les appareils de l'entreprise.
Le paramètres-gérés.json le fichier contrôle les serveurs MCP auxquels Claude Code est autorisé à se connecter :
{
« Serveurs MCP autorisés » : [
{« URL du serveur » : « https://mcp-gateway.your-company.com/ * »}
],
« Marchés connus stricts » : []
}
Réglage Marchés connus stricts vers un tableau vide bloque toutes les installations MCP provenant du marché. Combiné avec Serveurs MCP autorisés cela crée une configuration verrouillée dans laquelle les agents ne peuvent accéder aux outils que via votre passerelle gérée.
Le managed-mcp.json Le fichier définit les connexions réelles au serveur MCP. Déployez-le via MDM sur le chemin au niveau du système (/Bibliothèque/Support des applications/Claudecode/Managed-MCP.json sur macOS ou /etc/claude-code/managed-mcp.json sous Linux) :
{
« databricks-unity-catalog » : {
« tapez » : « http »,
« url » : « https://mcp-gateway.your-company.com/mcp/v1/databricks-uc/mcp »
},
« databricks-sql » : {
« tapez » : « http »,
« url » : « https://mcp-gateway.your-company.com/mcp/v1/databricks-sql/mcp »
}
}
Quand managed-mcp.json est déployé via MDM, il en prend le contrôle exclusif. Les développeurs ne peuvent pas ajouter ou utiliser de serveurs MCP au-delà de ce qui est défini dans ce fichier. Les décisions en matière de contrôle d'accès sont prises au niveau de la passerelle. Il vous suffit donc de mettre à jour le fichier MDM déployé lorsque vous ajoutez ou supprimez des intégrations de serveurs complètes.
Pour un guide complet sur la sécurisation de Claude Code dans les environnements d'entreprise, y compris les scripts de déploiement MDM et l'application du sandbox, ainsi que le schéma complet des paramètres gérés, consultez le Sécurité d'entreprise pour Claude documentation.
Ce point d'intégration s'adresse spécifiquement aux équipes qui peaufinent les modèles sur Databricks à l'aide de Mosaic AI Training et qui souhaitent les proposer parallèlement à des modèles d'API commerciaux via un point de terminaison unique.
La configuration est la suivante. Vous affinez et déployez le modèle via Databricks Model Serving afin qu'il soit disponible en tant que point de terminaison de service. Vous enregistrez Databricks en tant que fournisseur dans AI Gateway comme décrit ci-dessus. Vous créez un modèle virtuel avec un routage basé sur les priorités qui essaie d'abord votre modèle hébergé Databricks et revient à une API commerciale :
configuration_de_routage :
type : routage basé sur les priorités
objectifs_de_balance de charge :
- cible : databricks-main/custom-finetuned-llama-3
priorité : 0
- cible : anthropic-main/claude-sonnet-4-5
priorité : 1
Par défaut, tout le trafic est dirigé vers votre modèle personnalisé hébergé par Databricks. Si Databricks renvoie une erreur de serveur, expire ou atteint une limite de débit, la passerelle réessaie automatiquement sur Claude Sonnet. Les codes d'état de secours qui déclenchent ce comportement sont 401 et 403 et 404 et 429 et 500 et 502 et 503. Le code de l'application ne sait jamais que le basculement s'est produit. Il voit une réponse positive de la part de l'identifiant du modèle virtuel.
Ce modèle est utile lors de l'évaluation du modèle. Vous pouvez gérer les deux fournisseurs en parallèle en utilisant un routage basé sur le poids avec une répartition 50/50, enregistrer les réponses et comparer la qualité avant de vous engager dans le modèle affiné pour l'ensemble du trafic. Les traces par demande de la passerelle incluent le fournisseur résolu qui a fourni chaque réponse (renvoyé dans le modèle résolu x-tfy en-tête de réponse) afin que vous puissiez filtrer et analyser par fournisseur dans votre pile d'observabilité.
Les flux de travail TrueFoundry sont basés sur Flyte et permettent d'orchestrer des pipelines en plusieurs étapes sous forme de graphiques acycliques orientés de tâches. Chaque tâche s'exécute dans son propre conteneur avec des ressources et des dépendances définies. L'intégration de Databricks ajoute un type de tâche natif qui déclenche les tâches Databricks existantes à partir de ces flux de travail, de sorte que le traitement des données basé sur Spark et la formation des modèles puissent être associés à des tâches natives TrueFoundry telles que le déploiement et l'évaluation des modèles.
Une tâche Databricks utilise la norme @task décorateur avec DataBricksJobTaskConfig qui spécifie l'espace de travail Databricks et la tâche à déclencher. Sous le capot, la tâche appelle l'API Databricks Jobs. exécuter_maintenant () point de terminaison avec un jeton d'idempotence dérivé de l'ID d'exécution de Flyte. Cela garantit que la même exécution logique de flux de travail ne soumet jamais de tâches Databricks dupliquées, même si le module de tâches essaie à nouveau.
depuis truefoundry.workflow import (
DataBricksJobTaskConfig,
tâche Python Build,
tâche,
flux de travail,
)
@task (
task_config=DataBricksJobTaskConfig ()
image=TaskPythonBuild (
pip_packages= ["truefoundry [flux de travail]"],
),
<your-workspace>workspace_host="https ://.cloud.databricks.com »,
service_account="flyte-databricks-fr »,
job_id="123",
timeout_seconds=2000,
)
)
def run_databricks_training () :
print (« Le stage de formation de Databricks est terminé »)
@task
def deploy_model () :
# Déployez le modèle entraîné en tant que point de terminaison d'API
passer
@workflow ()
def train_and_deploy () :
run_databricks_training ()
model_déploiement ()
Le processus de tâche lui-même s'exécute dans un conteneur léger défini par image champ. L'exécution proprement dite des tâches se fait entièrement dans Databricks. Par défaut, la tâche interroge jusqu'à la fin de l'exécution de Databricks ou jusqu'à ce que timeout_seconds s'écoule. Si le délai est atteint, l'exécution de Databricks est annulée et un Erreur d'exécution est augmenté. Si vous définissez skip_wait_for_completion pour Vrai la tâche revient immédiatement après le déclenchement de la tâche sans attendre sa fin.
Le DataBricksJobTaskConfig accepte les champs suivants.
La tâche prend en charge deux méthodes d'authentification. Jeton d'accès personnel l'authentification fonctionne lorsque DATABRICKS_PERSONAL_ACCESS_TOKEN est défini dans l'environnement de la tâche. Vous injectez le PAT via env champ dans la configuration de la tâche en utilisant une référence secrète afin que le jeton ne soit jamais codé en dur.
Fédération de jetons OAuth est l'alternative lorsqu'aucun PAT n'est défini. Cela nécessite DATABRICKS_SERVICE_PRINCIPAL_CLIENT_ID dans l'environnement et dans Kubernetes compte_service dans le module de tâches. Le jeton de compte de service Kubernetes est échangé contre un jeton d'accès Databricks via le point de terminaison OIDC de l'espace de travail. La fédération OIDC doit être configurée dans l'espace de travail Databricks pour que ce chemin fonctionne.
La fédération de jetons OAuth évite de stocker entièrement les informations d'identification Databricks de longue durée. Le jeton de compte de service Kubernetes est de courte durée et limité au module de tâches. L'échange OIDC a lieu au moment de l'exécution, il n'y a donc aucun secret à faire pivoter ou à gérer.
Le cas d'utilisation typique est un pipeline dans lequel la préparation des données et la formation des modèles s'exécutent dans Databricks (car c'est là que résident vos données Delta Lake et que vos clusters Spark sont provisionnés) et des étapes en aval telles que l'enregistrement, le déploiement et l'évaluation des modèles s'exécutent dans TrueFoundry. La tâche Databricks relie les deux environnements au sein d'une définition de flux de travail unique. Vous obtenez la résolution des dépendances de Flyte et réessayez la sémantique et la mise en cache sur l'ensemble du pipeline plutôt que d'assembler des systèmes d'orchestration distincts.
L'intégration entre Databricks et TrueFoundry fonctionne à trois niveaux. La couche AI Gateway enregistre Databricks Model Serving en tant que fournisseur et achemine le trafic d'inférence via le même point de terminaison unifié qui gère tous les autres fournisseurs. Les modèles virtuels permettent un routage multifournisseur avec un basculement automatique entre les modèles hébergés de Databricks et les API commerciales. La couche MCP Gateway se trouve devant les serveurs MCP gérés par Databricks et centralise l'authentification, le contrôle d'accès au niveau des outils et la journalisation des audits pour les flux de travail des agents. La couche Workflow déclenche les tâches Databricks en tant que tâches natives dans les pipelines basés sur Flyte, de sorte que les charges de travail Spark sont composées avec les étapes de déploiement et d'évaluation de TrueFoundry dans un seul DAG.
Aucun side-car n'est requis. Aucune modification du SDK n'est requise dans le code de l'application. La couche d'adaptation de la passerelle assure la traduction entre le format compatible OpenAI et le format Databricks Model Serving de manière transparente. La seule configuration requise est l'enregistrement du fournisseur avec les informations d'authentification et le mappage des points de terminaison du modèle.
La conception qui rend cette intégration propre est l'architecture zéro appel externe du plan de passerelle. Toutes les décisions d'authentification, d'autorisation et de routage sont prises en fonction de l'état en mémoire synchronisé via NATS. Le seul saut réseau ajouté à une demande est le pod de passerelle lui-même, qui ajoute environ 3 ms de latence. Tout le reste, y compris la limitation du débit et l'application du budget, le suivi de l'état et la collecte de données télémétriques, se fait de manière asynchrone sans toucher au chemin de la demande.
Pour consulter la documentation complète d'AI Gateway, consultez Documents TrueFoundry. Pour la configuration du fournisseur Databricks, voir Modèles Databricks. Pour la configuration de MCP Gateway, voir Présentation de MCP Gateway. Pour l'intégration des flux de travail, voir Création d'une tâche Databricks.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.







Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2025 Tous droits réservés.





.png)


.webp)


.webp)