

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 20, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
En 2026, les entreprises ne peuvent plus se permettre de transformer une passerelle LLM en une passerelle IA improvisée. L'IA ne fera que s'intégrer de plus en plus dans les flux de travail orientés vers les clients, rendant ainsi une couche de passerelle dédiée non négociable pour des applications fiables alimentées par l'IA. L'infrastructure d'IA d'entreprise typique est souvent multimodèle, multi-équipes et multicloud, ce qui entraîne une conformité et une responsabilisation des coûts complexes.
Gartner définit une passerelle d'IA comme une technologie ou une plateforme qui sert d'intermédiaire entre les applications et divers services ou modèles d'intelligence artificielle (IA). Son objectif est de simplifier et de gérer l'accès aux fonctionnalités d'IA, en fournissant un point central pour assurer la sécurité, la gouvernance et l'observabilité des charges de travail d'IA. Lire l'intégralité Guide du marché Gartner pour les passerelles IA 2025 pour en savoir plus.
Au cours de l'année écoulée, trois grandes catégories ont émergé pour résoudre le problème de la gouvernance et de la résilience de GenAI :
Chaque catégorie est optimisée pour une phase différente de l'adoption de l'IA. Des problèmes surviennent lorsque des outils optimisés pour une phase sont sollicités pour en gérer une autre.
Dans ce blog, nous rassemblons toutes les études sur la concurrence dans un paysage définitif, expliquant la place de chaque plateforme, sa répartition et ce que les entreprises doivent prendre en compte lorsqu'elles choisissent le fournisseur qui répond le mieux à leurs besoins.
1. Kong AI : passerelle API traditionnelle adaptée à l'IA
Kong est une passerelle d'API, souvent utilisée dans les architectures de microservices basées sur Kubernetes. Kong AI s'appuie sur cette base en introduisant des plugins et des intégrations conçus pour acheminer le trafic vers de grands modèles linguistiques.
Ce que Kong AI fait bien
Où Kong AI tombe en panne
À mesure que l'utilisation de l'IA augmente, ces lacunes deviennent de plus en plus visibles. L'attribution des coûts, les stratégies de sélection des modèles et la gouvernance spécifique à l'IA doivent être gérées en dehors de la passerelle, souvent dans le code de l'application.
Conclusion : Kong AI est efficace en tant que passerelle d'API, mais l'IA reste une préoccupation secondaire plutôt qu'une abstraction native.
2. Portkey : passerelle LLM au niveau de l'application
Portkey est une passerelle IA conçue spécifiquement pour les applications LLM. Au lieu de traiter les requêtes d'IA comme des appels HTTP génériques, Portkey introduit un routage et une observabilité rapides et tenant compte des modèles.
Ce que Portkey fait bien
Là où Portkey n'est pas à la hauteur
La conception de Portkey est délibérément axée sur les applications, ce qui introduit des contraintes à l'échelle de l'entreprise
L'IA devenant une fonctionnalité interne partagée plutôt qu'une fonctionnalité d'application unique, ces limites nécessitent souvent des couches d'infrastructure supplémentaires.
Idéal pour : Les applications LLM à équipe unique entrent en phase de production initiale.
3. LiteLM : première passerelle open source destinée aux développeurs
LiteLM est une passerelle LLM open source qui fournit une API unifiée compatible avec OpenAI permettant d'accéder à des dizaines de fournisseurs de modèles.
Ce que LiteLM fait bien
Là où LitellM ne suffit pas
Idéal pour : LitellM est un point d'entrée efficace mais nécessite une augmentation significative pour les environnements réglementés ou multi-équipes.
Lisez également : Portkey contre LiteLM
4. AWS Bedrock : API de modèles sans serveur
AWS Bedrock propose un accès géré et sans serveur aux modèles de base de fournisseurs tels qu'Anthropic et Amazon. Il résume entièrement l'infrastructure et facture uniquement en fonction de l'utilisation de jetons.
Ce que fait bien AWS Bedrock
Les compromis cachés d'AWS Bedrock
Ces compromis prennent souvent les équipes par surprise lorsque les charges de travail passent de l'expérimentation à une utilisation en production soutenue.
Conclusion : Bedrock optimise la rapidité et la simplicité, et non la rentabilité ou le contrôle à long terme.
5. AWS SageMaker : infrastructure de machine learning gérée
SageMaker fournit une suite complète pour la formation, le réglage et le déploiement de modèles d'apprentissage automatique. Contrairement à Bedrock, il expose les choix d'infrastructure directement aux utilisateurs.
Ce que fait bien AWS Sagemaker
Inconvénients d'AWS Sagemaker
Conclusion : SageMaker offre le contrôle, mais au détriment de la simplicité opérationnelle.
6. Databricks : la plateforme Lakehouse ML
Databricks aborde l'IA dans une perspective axée sur les données, en intégrant les fonctionnalités ML et GenAI dans son architecture Lakehouse.
Ce que Databricks fait bien
Là où Databricks fait défaut
Conclusion : Databricks excelle dans l'ingénierie des données, et non dans l'intelligence artificielle.
Le fil conducteur : des passerelles sans gouvernance
À travers Kong contre LiteLM, Portkey et même Bedrock, le même problème se pose : ils gèrent les demandes, pas les systèmes d'IA.
Sur l'ensemble des passerelles et des services gérés, un problème récurrent apparaît : la plupart des outils se concentrent sur les demandes, et non sur les systèmes.
Ils répondent à des questions telles que :
Ils sont aux prises avec :
Il s'agit de préoccupations au niveau de l'infrastructure.
TrueFoundry occupe une couche différente de la pile. Au lieu de se concentrer uniquement sur le routage des API ou les services gérés, elle traite les charges de travail d'IA (modèles, agents, services et tâches) comme des objets d'infrastructure de premier ordre. Cela déplace la responsabilité du code de l'application vers la plate-forme elle-même.
La passerelle TrueFoundry AI repose sur les principes fondamentaux suivants :
Cela signifie que l'AI Gateway fait partie d'un système plus vaste, permettant aux entreprises de faire évoluer leurs cas d'utilisation de l'IA de manière fluide.
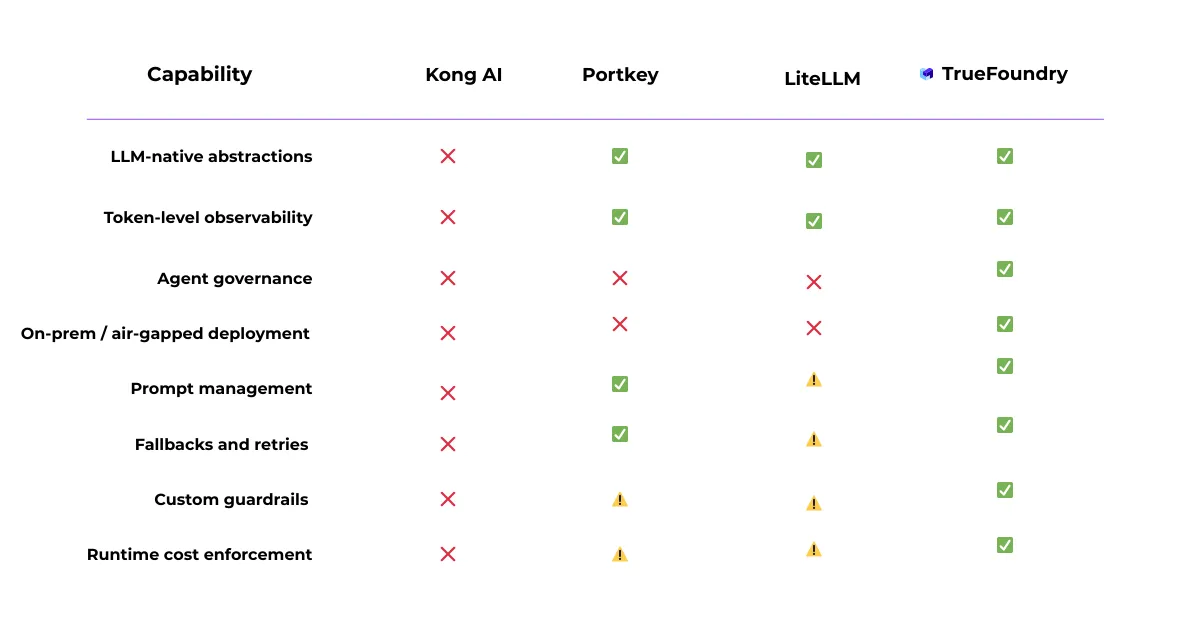
La passerelle TrueFoundry AI devient essentielle lorsque l'utilisation de l'IA va au-delà des applications isolées et devient une fonctionnalité partagée essentielle à la production. À ce stade, les défis concernent souvent moins les appels de modèles individuels que la cohérence opérationnelle entre les équipes et les environnements.
Voici en quoi la passerelle IA de TrueFoundry se distingue des autres solutions :
De nombreux outils d'IA se concentrent sur les problèmes liés aux demandes, tels que le routage, les nouvelles tentatives et l'observabilité de base. Cela est généralement suffisant dans les premiers stades.
Cependant, à mesure que l'utilisation augmente, les modèles et les agents commencent à se comporter davantage comme des services de longue durée. Les équipes ont besoin d'une propriété, d'une gestion du cycle de vie et de limites opérationnelles plus claires. TrueFoundry est conçu pour gérer les charges de travail d'IA (modèles, services et tâches) en tant que composants d'infrastructure dotés de caractéristiques de déploiement et d'exécution définies.
Dans de nombreuses piles, les contrôles d'accès et les politiques d'utilisation sont configurés au niveau de l'application ou du SDK. Au fil du temps, cela peut entraîner des incohérences à mesure que le nombre de services augmente.
TrueFoundry applique des contrôles au niveau de l'environnement, séparant le développement, le staging et la production par défaut. Les politiques définies à cette couche s'appliquent de manière uniforme à toutes les charges de travail déployées au sein d'un environnement, réduisant ainsi le recours à la configuration par application.
Les coûts de l'IA augmentent souvent en raison de la simultanéité, des nouvelles tentatives ou des charges de travail en arrière-plan plutôt que des demandes individuelles. TrueFoundry résout ce problème en imposant des limites à la simultanéité, au débit et à l'utilisation des ressources lors de l'exécution.
Cela permet aux entreprises de gérer l'infrastructure partagée de manière plus prévisible à mesure que l'utilisation évolue.
Bien que les mesures au niveau des jetons soient utiles, elles n'expliquent pas complètement le comportement du système en production. TrueFoundry met en corrélation les signaux au niveau des demandes avec des indicateurs d'infrastructure tels que l'utilisation du CPU/GPU et le comportement de mise à l'échelle automatique, aidant ainsi les équipes à comprendre les performances et les inducteurs de coûts dans leur contexte.
Certaines organisations sont soumises à des contraintes qui nécessitent un réseau privé, des déploiements sur site ou une stricte résidence des données. TrueFoundry est conçu pour fonctionner dans ces environnements, ce qui permet de gérer les charges de travail de l'IA en utilisant les mêmes normes d'infrastructure que celles appliquées ailleurs dans l'organisation.
Conclusion
Le paysage actuel des plateformes d'IA reflète la vitesse à laquelle l'IA générative a évolué. De nombreux outils permettent de résoudre des problèmes réels (routage, accès aux modèles, observabilité ou formation), mais ils le font à partir de différents points de départ. Par conséquent, aucune catégorie ne couvre naturellement l'ensemble des exigences opérationnelles qui apparaissent lorsque l'IA devient essentielle à la production.
TrueFoundry offre le meilleur rapport qualité-prix lorsque les charges de travail d'IA doivent être gérées avec la même discipline que les autres systèmes de production, dans le cadre de politiques partagées et avec un comportement prévisible des ressources.
Les entreprises qui comparent des fournisseurs commencent souvent par rechercher meilleure passerelle LLM, mais le véritable facteur de différenciation réside dans la capacité de la plateforme à gérer les systèmes d'IA à grande échelle. Il est essentiel de comprendre où se situe chaque plateforme et où ses hypothèses de conception commencent à s'effondrer. Le bon choix dépend moins des fonctionnalités individuelles que de la manière dont une organisation s'attend à ce que son utilisation de l'IA évolue au fil du temps.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


