

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 13, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
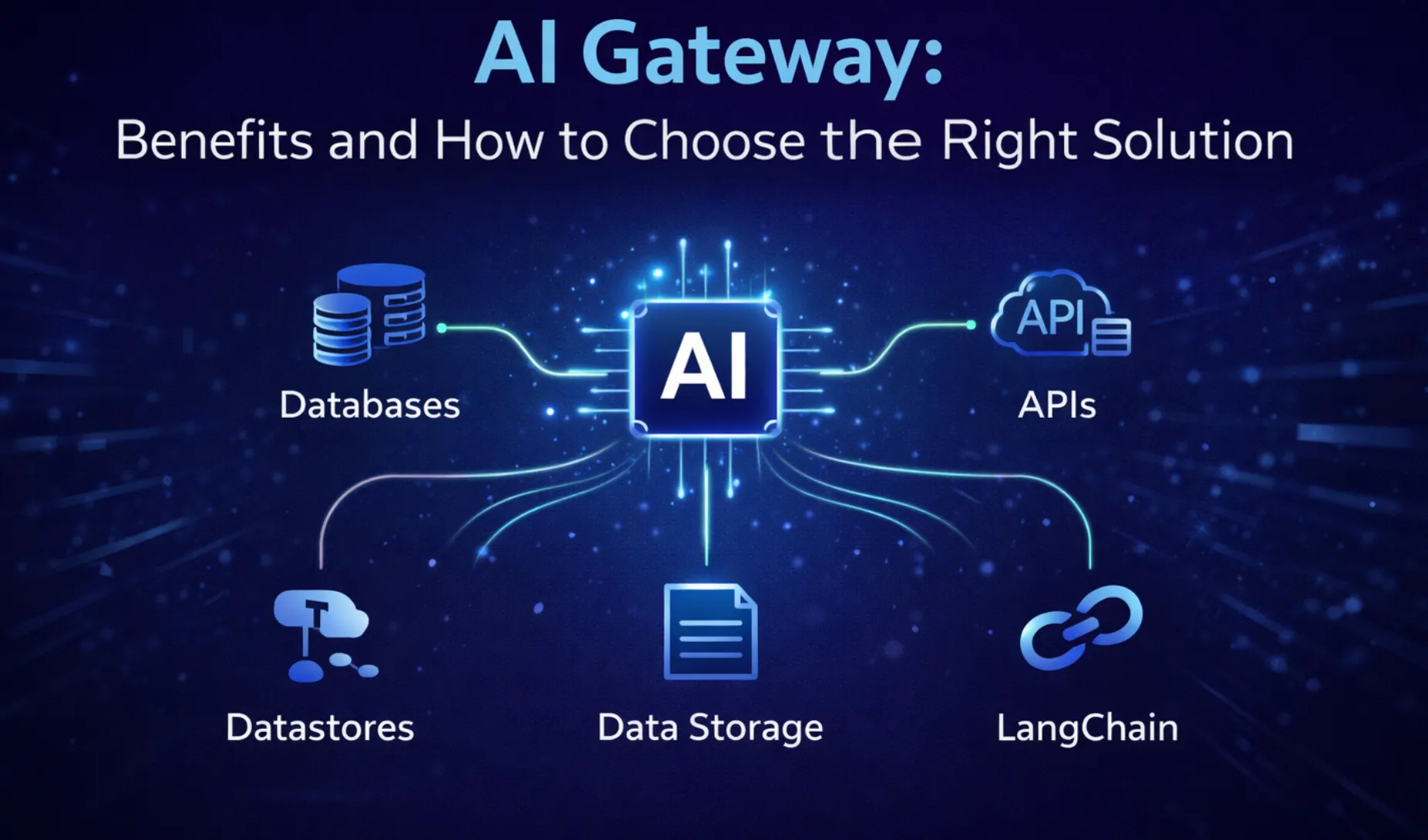
Alors que l'IA dépasse les environnements POC et de développement, de nombreuses équipes sont confrontées au même problème : créer et intégrer un modèle est facile, mais l'exécuter de manière fiable à grande échelle est difficile. Les passerelles AI résolvent ce problème en agissant comme un plan de contrôle centralisé pour toutes les utilisations du LLM, en normalisant la façon dont les équipes interrogent, surveillent et redimensionnent les modèles en production.
Ils unifient plusieurs fournisseurs (tels qu'OpenAI, Anthropic, Mistral et les LLM open source) au sein d'une seule API, appliquent des politiques d'authentification, suivent l'utilisation et permettent l'attribution des coûts. La passerelle IA de TrueFoundry est l'une de ces solutions d'entreprise conçue pour les applications GenAI modernes, offrant l'observabilité, la limitation du débit, un versionnage rapide, etc., aidant les entreprises à déployer l'IA de manière fiable, sécurisée et à grande échelle.
Dans ce guide, nous aborderons l'architecture de base d'une passerelle d'IA, les fonctionnalités essentielles de gouvernance, les indicateurs d'évaluation des fournisseurs et les principales différences entre l'IA et les passerelles API traditionnelles.
Un Passerelle IA est une couche d'abstraction qui unifie l'accès à plusieurs grands modèles de langage (LLM) via une interface API unique. Il fournit un moyen cohérent, sécurisé et optimisé d'interagir avec des modèles provenant de différents fournisseurs tels que OpenAI, Anthropic, Cohere, Together.ai, ou des modèles open source tels que Mistral et LLama 2 déployés sur votre propre infrastructure.
À la base, une passerelle IA gère la lourde tâche d'intégration, de routage, d'authentification et de surveillance de l'utilisation du LLM sur différents points de terminaison. Au lieu de gérer plusieurs SDK, jetons d'authentification, limites de débit et modèles de tarification, les équipes peuvent acheminer toutes les demandes de modèles via la passerelle. Cela rationalise le développement et permet une gouvernance à grande échelle.
La passerelle IA de TrueFoundry est conçue pour offrir des performances et une observabilité de niveau professionnel. Il permet aux équipes de :
En outre, la passerelle prend en charge les modes streaming et non-streaming, l'appel d'outils (appel de fonctions), la création de modèles rapides et le balisage pour la ventilation des coûts au niveau de l'équipe. Grâce à l'observabilité intégrée, TrueFoundry permet de suivre non seulement la latence et l'utilisation des jetons, mais également l'accès spécifique à l'utilisateur, les tendances du trafic et les performances par point de terminaison.
À mesure que l'utilisation du LLM augmente au sein des équipes, des cas d'utilisation et des environnements, une passerelle d'IA devient la base de l'opérationnalisation de l'IA générative en production. Il assure le contrôle, la visibilité et l'optimisation tout au long du cycle de vie des interactions LLM.
L'augmentation du nombre de passerelles IA est principalement due à une complexité croissante. La plupart des équipes n'utilisent plus un modèle unique provenant d'un seul fournisseur. Ils testent plusieurs modèles, équilibrent performances et coûts et prennent en charge différents cas d'utilisation entre les équipes. Sans couche d'abstraction, cette situation peut rapidement devenir fragile et difficile à gérer.
La pression sur les coûts a également eu un impact significatif. À mesure que l'utilisation de l'IA augmente, la consommation de jetons et la latence ne sont plus des problèmes techniques mais des préoccupations commerciales. Les passerelles d'intelligence artificielle permettent aux équipes d'acheminer le trafic de manière intelligente, de faire respecter les budgets et d'obtenir des informations sur les dépenses réelles.
La gouvernance est un autre facteur important. Les systèmes gérant des données de plus en plus sensibles et des flux de travail réglementés, les organisations ont besoin de contrôles plus stricts en matière d'accès, d'audit et de conformité. Une passerelle constitue un point naturel pour appliquer ces politiques.
Lisez également : OpenRouter contre AI Gateway
Une passerelle IA propose une approche structurée et évolutive de la gestion de l'utilisation du LLM au sein des équipes et des environnements. Vous trouverez ci-dessous les principales caractéristiques qui le rendent essentiel pour les flux de travail GenAI modernes :
Accès unifié : Les passerelles AI offrent une interface API unique pour accéder à plusieurs LLM provenant de fournisseurs tels qu'OpenAI, Anthropic ou des modèles internes. Il n'est donc plus nécessaire de gérer des API, des SDK ou des clés individuels pour chaque fournisseur.
Authentification et autorisation : Les passerelles AI garantissent un accès sécurisé grâce à une gestion centralisée des clés. Les développeurs reçoivent des clés d'API délimitées tandis que les clés racine restent protégées, intégrées à des gestionnaires de secrets tels qu'AWS SSM, Google Secret Manager ou Azure Vault.
Contrôle d'accès basé sur les rôles (RBAC) : Garantit que seuls les utilisateurs autorisés peuvent accéder à des modèles ou à des actions spécifiques, conformément aux normes de sécurité de l'entreprise.
Surveillance des performances : Suivez la latence, les taux d'erreur et le débit des jetons pour chaque point de terminaison du modèle. Cela permet de détecter les problèmes à un stade précoce, d'optimiser le routage et de maintenir les SLA.
Analyses d'utilisation : Des journaux et des tableaux de bord détaillés indiquent qui a utilisé quel modèle, quand et comment, offrant ainsi une transparence entre les projets et permettant l'attribution des coûts par utilisateur, équipe ou fonctionnalité.
Gestion des coûts : Les passerelles suivent l'utilisation des jetons et associent les coûts aux utilisateurs, aux équipes ou aux terminaux. Cela fournit une visibilité claire sur les habitudes de dépenses et permet d'éviter les dépassements de coûts.
Intégrations d'API : La prise en charge d'API et d'outils externes tels que les pipelines d'évaluation, les garde-fous rapides ou les bases de données vectorielles permet une intégration transparente avec des écosystèmes AI/ML plus larges.
Support de modèle personnalisé : Les utilisateurs peuvent intégrer leurs propres modèles affinés ou propriétaires à la passerelle, en acheminant le trafic parallèlement aux modèles commerciaux.
Mise en cache : Stockez et réutilisez des réponses LLM identiques ou similaires pour enregistrer les jetons et réduire la latence.
Routage et solutions de secours : Routage intelligent des demandes basé sur la latence, le coût ou la fiabilité. Inclut des mécanismes de repli et de nouvelles tentatives automatiques pour améliorer la résilience.
Limitation de débit et équilibrage de charge : Prend en charge les quotas au niveau de l'utilisateur, la limitation du débit et l'équilibrage de charge entre les fournisseurs de modèles pour un débit et une stabilité optimaux.
L'évaluation d'une passerelle IA nécessite une évaluation complète de ses capacités en matière de contrôle d'accès, d'intégration de modèles, d'observabilité et de gouvernance des coûts.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Une passerelle IA robuste devrait simplifier l'utilisation des modèles tout en garantissant l'évolutivité, les performances et la sécurité des applications de production.
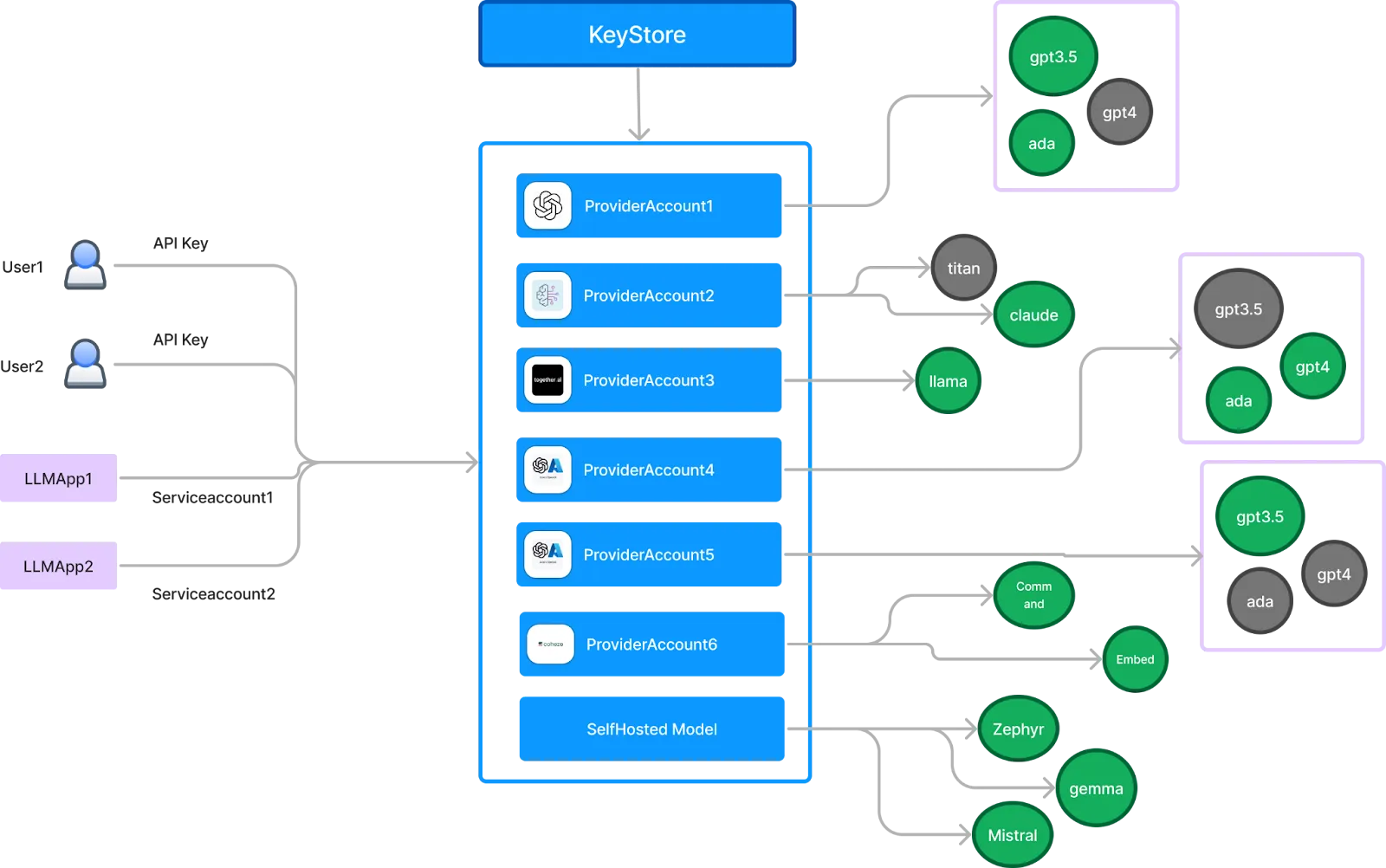
Une passerelle IA puissante centralise la gestion des clés d'API en attribuant des clés individuelles à chaque utilisateur ou service tout en protégeant les clés racine à l'aide de gestionnaires secrets tels qu'AWS SSM, Google Secret Store ou Azure Vault.
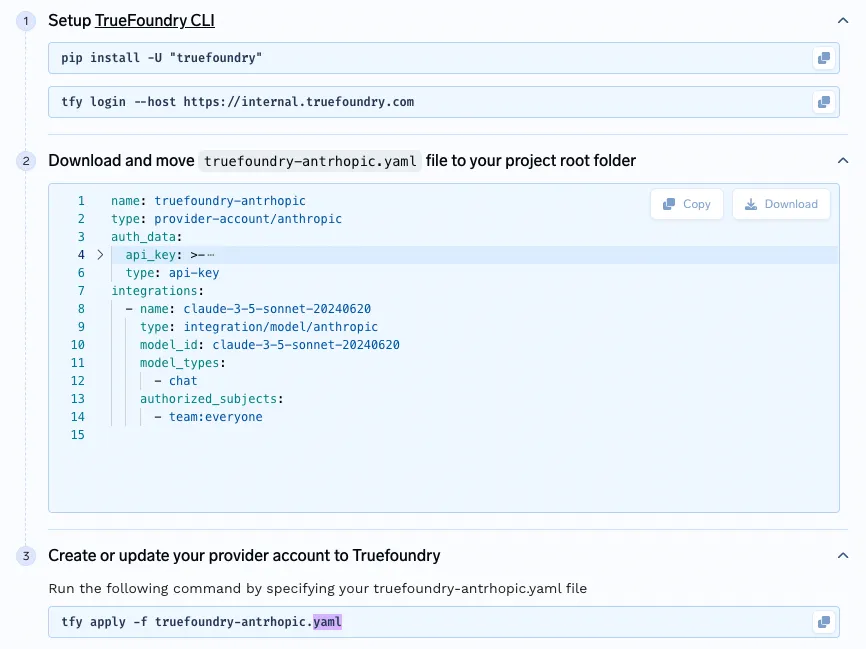
La passerelle de TrueFoundry permet aux administrateurs de gérer un accès précis à tous les modèles intégrés, qu'ils soient auto-hébergés ou tiers, via une interface d'administration unifiée. Les configurations de contrôle d'accès sont suivies dans des fichiers YAML versionnés, ce qui garantit l'auditabilité et la conformité.
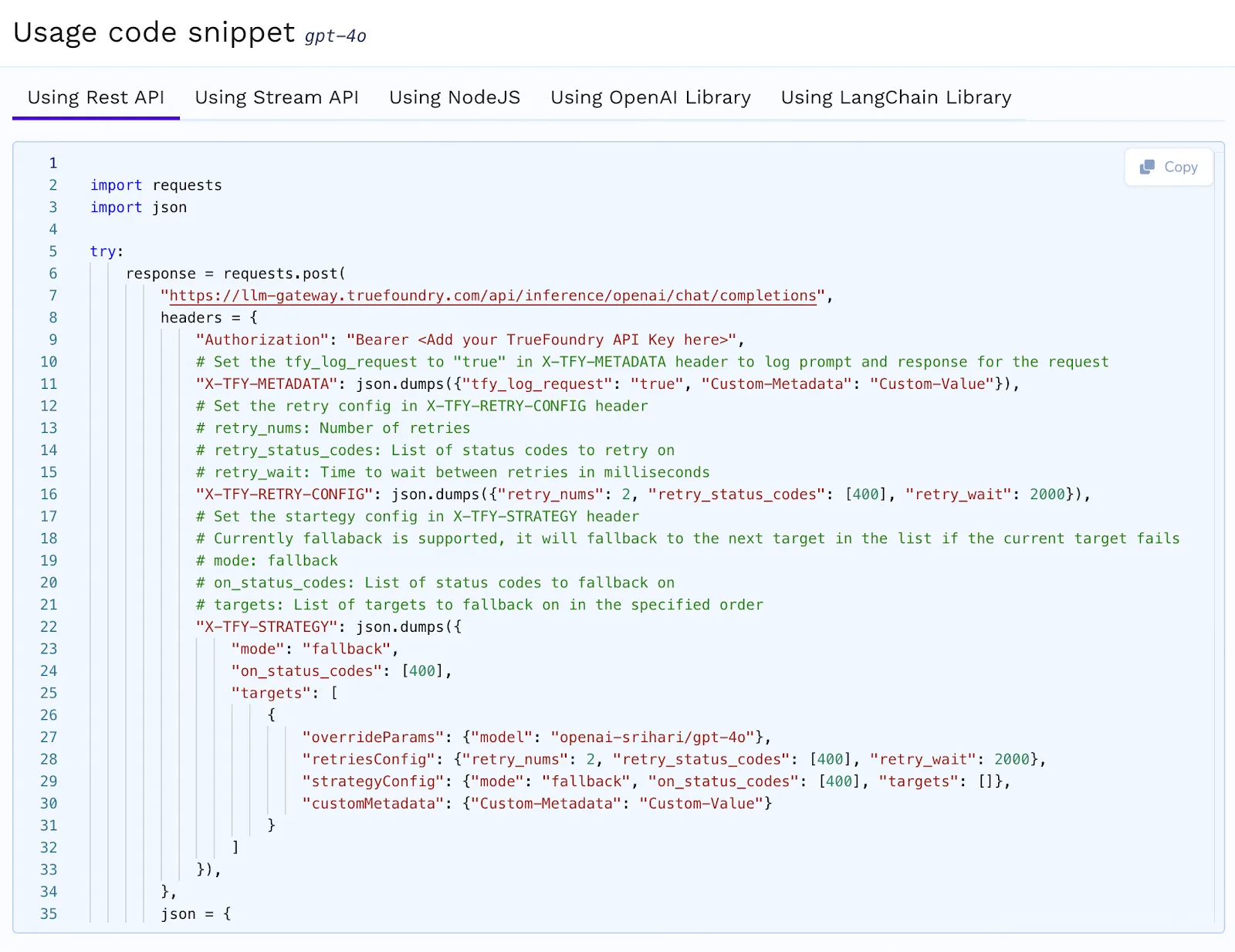
L'AI Gateway devrait offrir une interface standardisée pour interagir avec plusieurs modèles. TrueFoundry suit le format de demande-réponse OpenAI, ce qui le rend compatible avec les SDK LangChain et OpenAI. Les développeurs peuvent passer d'un modèle à l'autre sans modifier leur code. TrueFoundry fournit également des extraits de code générés automatiquement pour différents fournisseurs et langages de programmation, simplifiant ainsi l'intégration.
TrueFoundry prend en charge trois voies principales pour l'accès aux modèles : des fournisseurs tiers (tels que OpenAI, Cohere, AWS Bedrock et Anthropic), des modèles open source auto-hébergés (déployés via HuggingFace ou une infrastructure personnalisée) et des modèles hébergés par TrueFoundry partagés entre les clients. Cette flexibilité permet aux équipes de mélanger et assortir les modèles en fonction des cas d'utilisation, du budget ou des exigences de latence.
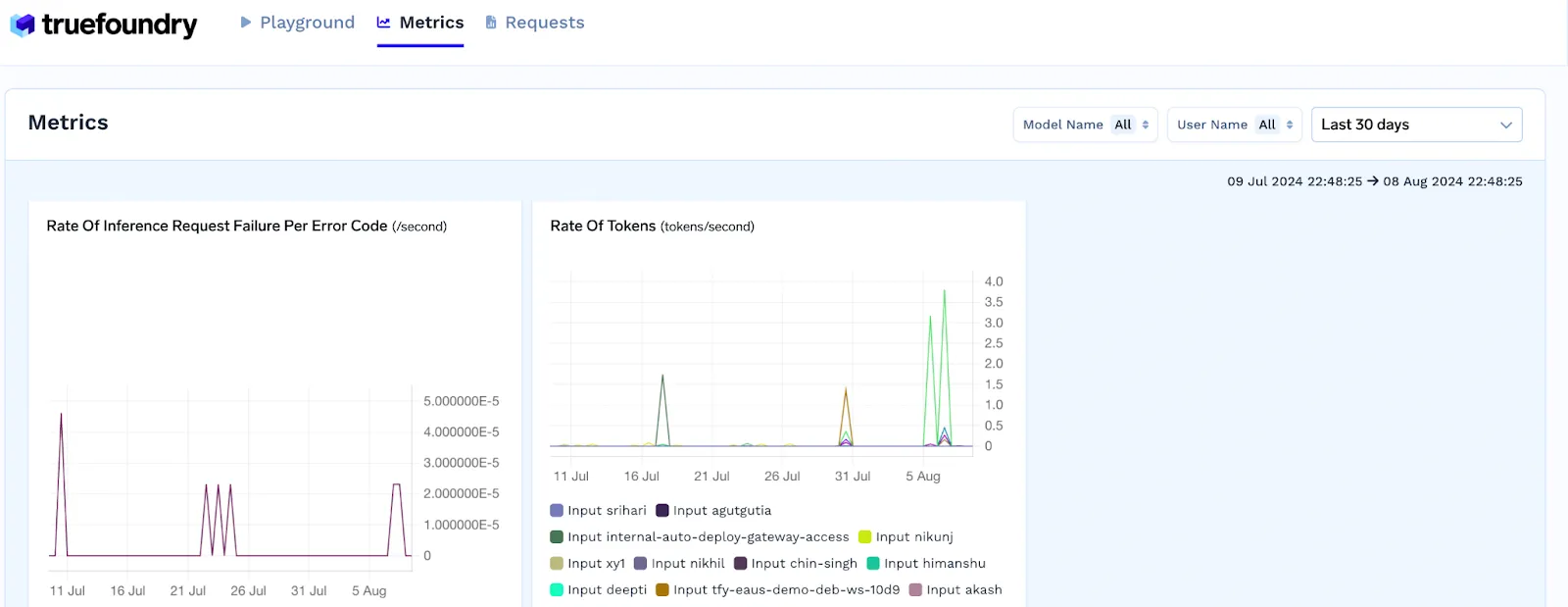
Pour garantir la fiabilité, la passerelle doit surveiller la latence, les taux d'erreur, le débit et les échecs d'inférence. TrueFoundry capture des indicateurs clés tels que la latence des demandes, le taux de jetons et le taux d'échecs d'inférence, ce qui permet d'identifier facilement les goulots d'étranglement en matière de performances grâce à des tableaux de bord en temps réel.
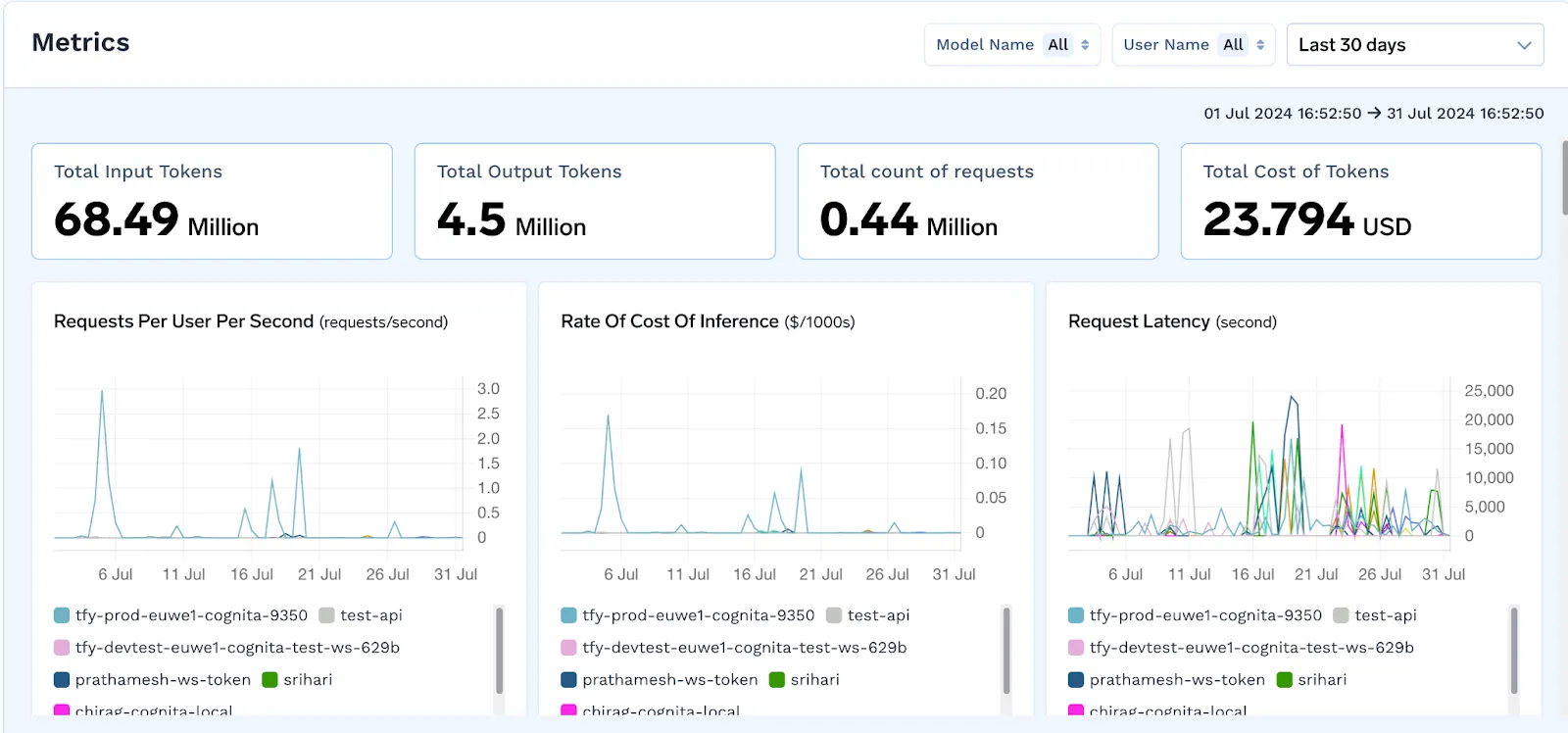
Comprendre comment, quand et par qui les modèles sont utilisés est essentiel pour la gouvernance. TrueFoundry enregistre l'activité détaillée des demandes et des réponses, la consommation de jetons et le coût par modèle. Ces informations aident les équipes à gérer les charges de travail et à optimiser les modèles d'utilisation.
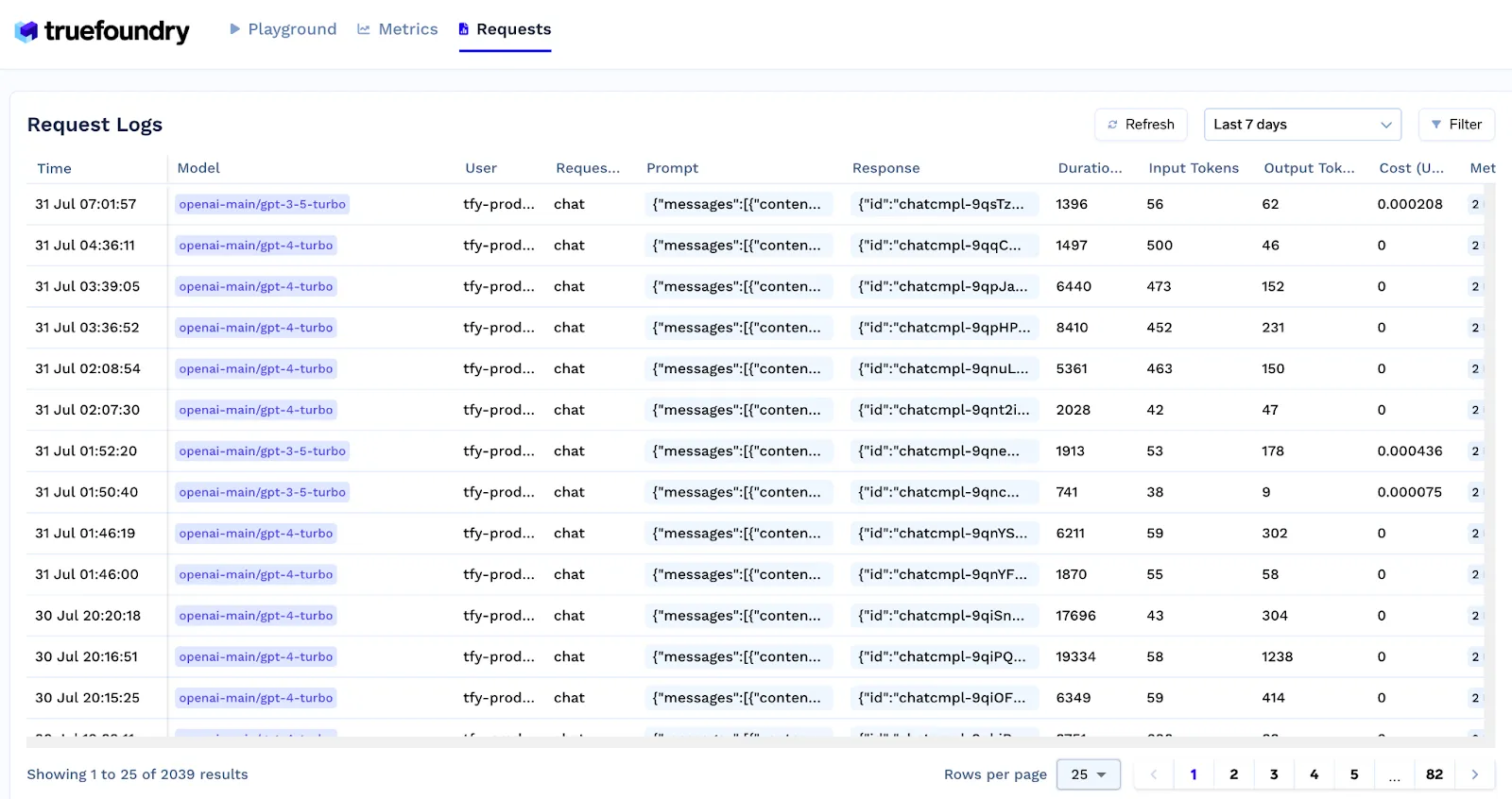
La passerelle doit enregistrer les coûts de toutes les interactions avec les modèles, qu'ils soient hébergés en interne ou via des API commerciales. TrueFoundry fournit une visibilité complète des coûts d'utilisation des modèles pour les utilisateurs, les équipes et les projets. Les tableaux de bord intégrés permettent aux entreprises de suivre les dépenses, de configurer des alertes et d'appliquer des limites tarifaires ou budgétaires pour contrôler les excédents.
Les fonctionnalités avancées d'une passerelle IA déterminent son efficacité dans des environnements de production réels. Passerelle IA de TrueFoundry propose un ensemble complet de fonctionnalités qui optimisent les performances, améliorent la fiabilité et s'intègrent parfaitement à des systèmes plus étendus, le rendant ainsi prêt à être utilisé par les entreprises dès le premier jour.
La mise en cache permet de réduire la latence et de réduire les coûts en évitant les appels de modèles redondants. TrueFoundry prend en charge à la fois la mise en cache des correspondances exactes (pour des instructions identiques) et mise en cache sémantique (pour les requêtes ayant une signification similaire), ce qui améliore la rapidité sans compromettre la pertinence. Vous pouvez configurer les politiques d'expiration du cache et invalider manuellement les entrées obsolètes si nécessaire. Cela garantit que la passerelle fournit des réponses rapides, précises et à jour.
Pour les applications critiques pour la production, la passerelle achemine automatiquement le trafic vers d'autres modèles en cas de défaillance du modèle principal, garantissant ainsi un service ininterrompu. Les nouvelles tentatives automatiques permettent de remédier à des erreurs passagères sans intervention de l'utilisateur. La limitation de débit intégrée permet d'appliquer les quotas et d'éviter les surutilisations, tandis que l'équilibrage de charge répartit le trafic entre plusieurs modèles ou fournisseurs afin de maintenir un débit optimal et de minimiser la latence.
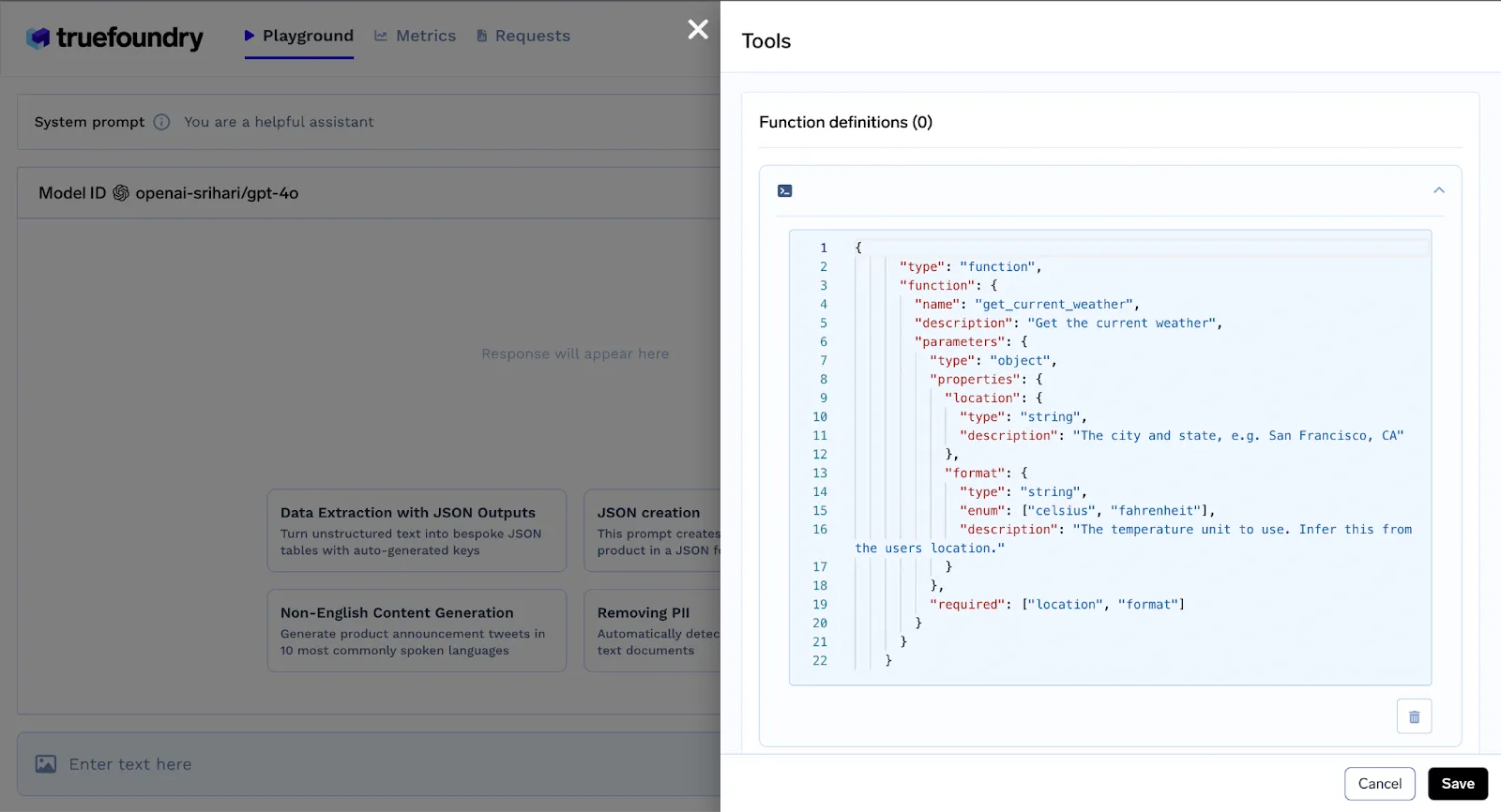
La passerelle de TrueFoundry prend en charge les appels d'outils en simulant les interactions avec des API externes. Bien que la fonction réelle ne soit pas exécutée par la passerelle, le modèle peut renvoyer des sorties structurées représentant l'appel d'outil prévu. C'est idéal pour créer des flux de travail dans lesquels les LLM doivent décider quand et comment invoquer des outils, ce qui permet aux développeurs de concevoir et de tester ces comportements en toute sécurité.
Les applications modernes impliquent souvent bien plus que du texte. La passerelle prend en charge les entrées multimodales telles que du texte et des images au sein d'une même demande, ce qui permet de débloquer des cas d'utilisation tels que les questions-réponses de documents, la recherche visuelle ou le support client enrichi de captures d'écran ou de photos de produits. L'AI Gateway convient donc à la fois aux applications de NLP traditionnelles et d'IA de nouvelle génération qui nécessitent un contexte provenant de plusieurs formats de données.
TrueFoundry permet une intégration approfondie avec votre stack existant. Vous pouvez intégrer des outils d'observabilité tels que Prometheus et Grafana pour une surveillance en temps réel, implémenter des couches de sécurité à l'aide de Guardrails AI ou NeMo Guardrails, et évaluer la qualité du modèle en continu à l'aide d'Arize ou MLflow. Cet écosystème connecté garantit que votre système d'IA est non seulement performant, mais également sûr, transparent et en constante amélioration.
Une passerelle IA offre des avantages opérationnels, financiers et techniques importants aux organisations qui intègrent des modèles de langage de grande taille (LLM) dans leurs produits et leurs flux de travail. Il agit comme un plan de contrôle de la consommation d'IA, fournissant une interface cohérente, renforçant la sécurité et optimisant les performances à grande échelle.
Accès et gouvernance centralisés
Lorsque plusieurs équipes ou applications doivent interagir avec différents fournisseurs de LLM, la gestion des clés, des jetons et des droits d'accès individuels devient complexe. Une passerelle IA centralise le contrôle d'accès, en permettant des autorisations basées sur les rôles, la journalisation des audits et une gestion sécurisée des clés.
Exemple : Une entreprise internationale déployant des fonctionnalités d'IA au sein de ses équipes marketing, produit et support utilise une passerelle IA pour attribuer des clés d'API délimitées et restreindre l'accès de chaque équipe à des modèles spécifiques, réduisant ainsi le risque d'utilisation abusive accidentelle ou de fuite de données.
Transparence des coûts et contrôle budgétaire
Les LLM peuvent représenter un coût opérationnel important, en particulier en raison de leur utilisation croissante au sein des équipes. Les passerelles AI fournissent un suivi précis des coûts par utilisateur, par équipe ou par projet. Cette visibilité aide les organisations à gérer leurs budgets, à identifier les inefficacités et à introduire des modèles de rétrofacturation, le cas échéant.
Exemple : Une entreprise SaaS proposant des fonctionnalités basées sur l'IA à ses clients surveille l'utilisation via la passerelle et utilise les données pour mettre en œuvre une tarification échelonnée en fonction de la consommation réelle de jetons.
Commutation et abstraction de modèles fluides
La couche API unifiée permet aux organisations d'échanger des LLM ou des fournisseurs sans modifier le code de l'application. Cela permet de tester plus facilement de nouveaux modèles, de négocier de meilleurs prix ou de passer des déploiements commerciaux aux déploiements open source.
Exemple : Une start-up utilisant initialement un LLM commercial passe à un modèle open source affiné pour la confidentialité des données et la réduction des coûts, sans modifier sa base de code, grâce à l'abstraction de la passerelle.
Fiabilité et résilience améliorées
Les passerelles proposent des solutions de secours intégrées, des nouvelles tentatives automatiques, une mise en cache et un équilibrage de charge pour garantir un service ininterrompu et des performances constantes, même en cas de charge ou de panne du fournisseur.
Exemple : Un système de chatbot à fort trafic gère les pics de trafic soudains en acheminant dynamiquement les demandes entre plusieurs fournisseurs tout en revenant aux réponses mises en cache si nécessaire.
Conformité et observabilité
Pour les secteurs réglementés, la capacité de suivre et d'auditer l'utilisation des modèles est essentielle. Les passerelles IA s'intègrent aux outils de surveillance, de journalisation et de sécurité pour répondre aux normes de conformité et aux politiques de gouvernance internes.
Exemple : Une entreprise de santé enregistre chaque demande et réponse via la passerelle, ce qui permet une traçabilité complète à des fins d'audit tout en maintenant les limites d'accès aux données.
Si des termes tels que Passerelle API et passerelle IA vous pouvez facilement tout mélanger, vous n'êtes pas seul. De nombreuses équipes rencontrent d'abord des passerelles lors de la mise à l'échelle de leurs API. Dans ce contexte, voici en quoi les passerelles IA diffèrent et pourquoi elles existent en premier lieu.
Les passerelles d'IA sont spécialement conçues pour répondre à la complexité des grands modèles de langage (LLM). Ils vont au-delà de la simple gestion du trafic pour gérer « l'intelligence » des données.
Voici une comparaison claire entre les passerelles API traditionnelles et les passerelles IA spécialisées.
En résumé, une passerelle traditionnelle gère la façon dont les données circulent. Une passerelle IA gère le coût des données et leur comportement. Pour une pile d'IA moderne, la passerelle est votre principal moyen de défense contre la spirale des coûts et les risques de sécurité.
Au fur et à mesure que les organisations utilisent de plus en plus de grands modèles linguistiques, le besoin d'une interface sécurisée, fiable et efficace devient essentiel. Une passerelle IA fait office de couche fondamentale, éliminant la complexité liée à la gestion de plusieurs fournisseurs, à l'application des contrôles d'accès, au suivi des coûts et à la garantie de performances à grande échelle. Il permet aux équipes d'expérimenter, de déployer et de surveiller des applications basées sur LLM en toute confiance et contrôle.
Qu'il s'agisse de créer des copilotes internes, des interfaces de discussion orientées client ou des flux de travail d'IA multimodaux, une passerelle IA permet de standardiser l'infrastructure tout en restant suffisamment flexible pour prendre en charge l'évolution des écosystèmes de modèles. Des fonctionnalités telles que la mise en cache, le routage, l'attribution des coûts et l'appel d'outils augmentent encore sa valeur pour les déploiements de niveau entreprise.
Dans un paysage de l'IA en évolution rapide, l'adoption d'une passerelle d'IA n'est pas seulement une question de commodité ; c'est un investissement stratégique dans la maturité opérationnelle, l'observabilité et l'évolutivité à long terme.
Êtes-vous prêt à découvrir ces fonctionnalités en action ? Réservez une démo avec TrueFoundry dès aujourd'hui pour découvrir comment nous pouvons centraliser et sécuriser l'infrastructure d'IA de votre entreprise.
Une passerelle IA agit comme un plan de contrôle centralisé qui unifie plusieurs fournisseurs LLM au sein d'une seule API. Il gère les tâches les plus lourdes que constituent le routage des demandes, l'authentification et la surveillance des performances sur différents terminaux. En gérant les nouvelles tentatives automatisées et en définissant des limites de taux spécifiques à l'équipe, il garantit la stabilité et la rentabilité de votre infrastructure d'IA.
La meilleure passerelle d'IA doit offrir une fiabilité de niveau production et une flexibilité pour les fournisseurs. TrueFoundry est l'un des principaux concurrents car il fournit des fonctionnalités d'entreprise uniques, telles que la mise en cache sémantique pour une latence plus faible et des solutions de repli automatisées pour éviter les pannes. Cela permet aux équipes de basculer facilement entre les modèles commerciaux et les modèles auto-hébergés sans avoir à réécrire le code de l'application.
Alors qu'un pare-feu basé sur l'IA se concentre spécifiquement sur les menaces de sécurité telles que l'injection rapide, une passerelle IA gère l' « intelligence » plus large du flux de données. La passerelle gère des tâches opérationnelles telles que l'équilibrage de charge basé sur des jetons, la mise en cache sémantique et le basculement des modèles. Considérez la passerelle comme la couche de gestion complète et le pare-feu comme un agent de sécurité spécifique.
TrueFoundry permet aux entreprises de faire évoluer l'IA en fournissant une visibilité granulaire sur l'utilisation des jetons et les coûts dans tous les services. Il simplifie la gouvernance grâce à un contrôle d'accès basé sur les rôles et à une gestion rapide versionnée, garantissant la conformité et la reproductibilité. Cette approche centralisée permet aux entreprises de passer de prototypes expérimentaux à des environnements de production sécurisés et performants de manière efficace.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


