

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
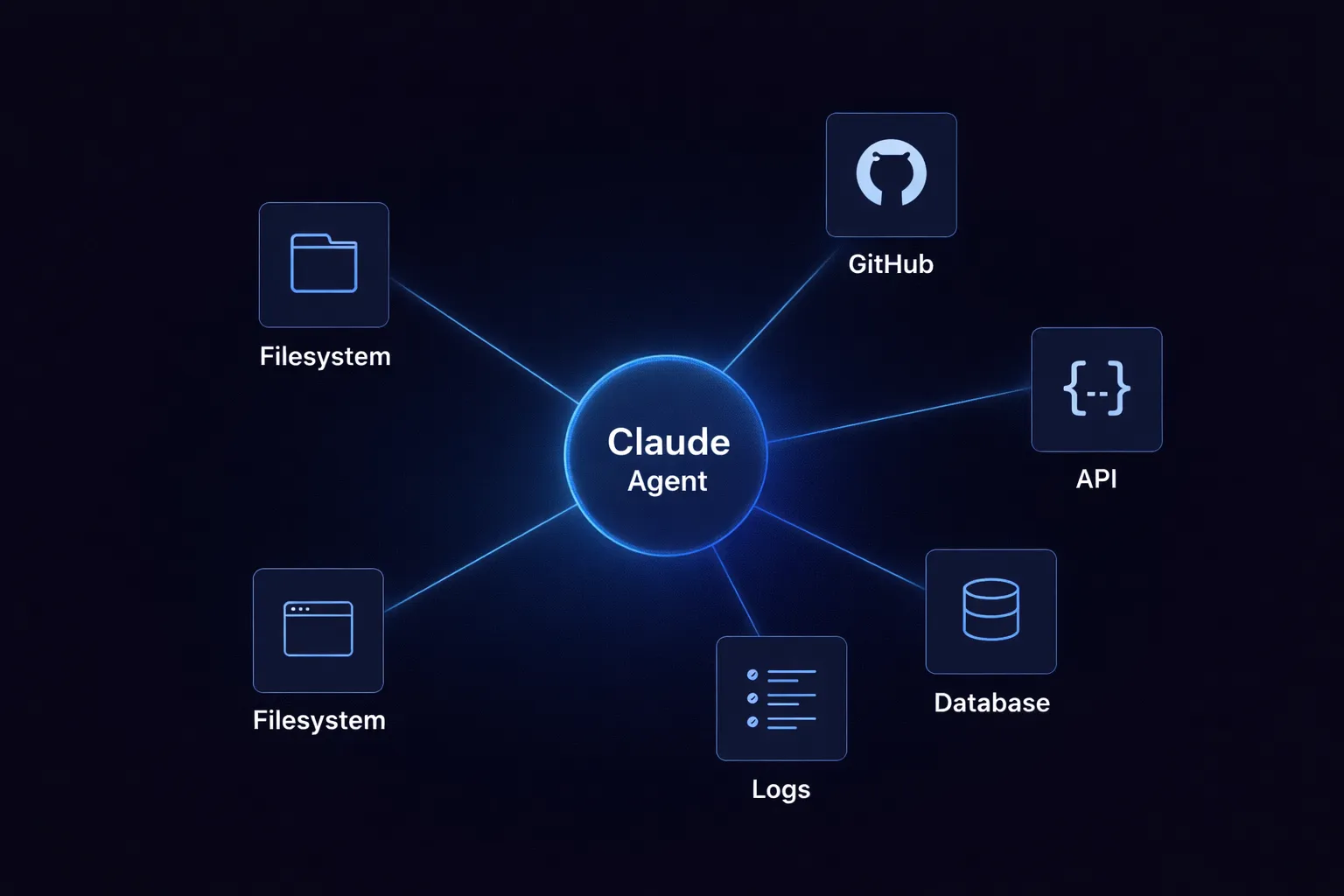
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Un agent de codage qui n'a pas accès à des outils externes ne peut pas faire grand-chose. Il peut expliquer le code, suggérer des modifications ou écrire un correctif. Mais si vous voulez qu'il vérifie un référentiel, appelle une API ou lise un fichier journal, il doit aller au-delà de sa fenêtre contextuelle. C'est là que la plupart des configurations commencent à échouer.
J'ai vu des équipes créer ces liens en partant de zéro. Il peut y avoir un script Python à un endroit, un wrapper personnalisé à un autre. Une intégration utilise JSON sur HTTP, une autre exécute des commandes via une CLI et une autre dépend d'un ancien adaptateur issu d'un hackathon. Cette configuration fonctionne avec quelques outils, mais à mesure que vous en ajoutez d'autres, les choses se compliquent. Les autorisations deviennent incohérentes et le débogage devient plus difficile.
Claude Code est en train de passer du statut d'assistant à celui d'agent connecté. Il devient beaucoup plus utile lorsqu'il peut accéder à des fichiers, à des outils de développement et à des systèmes externes. Mais s'il n'existe pas de méthode standard pour tout connecter, vous vous retrouvez avec des intégrations fragiles qui peuvent être interrompues de manière inattendue.
C'est ce à quoi répond MCP.
Le protocole Model Context fournit un moyen standard de mettre des outils à la disposition des modèles. Plutôt que de connecter chaque outil à chaque agent, vous utilisez un protocole de découverte partagé. Cela ne résout pas tous les problèmes, mais cela déplace la question de « comment connecter ceci » à « comment gérer ce qui est connecté ».
Le MCP est un protocole, pas un produit. C'est important car cela façonne la façon dont Claude Code travaille dans les coulisses.
Le protocole Model Context spécifie comment les outils se décrivent à un modèle et comment le modèle les appelle. Il normalise l'échange : découverte, schéma, demande et réponse. Il n'implémente pas l'outil lui-même. Il ne gère pas le contrôle d'accès. Il fournit simplement le contrat.
Lorsque nous mentionnons les intégrations MCP dans Claude Code, nous faisons référence à des outils que Claude peut découvrir et utiliser via le protocole. Le modèle n'est pas lié à chaque point de terminaison. Au lieu de cela, il voit une interface structurée, comprend les paramètres et utilise l'outil dans le cadre de son flux de travail.
Par exemple, supposons que vous souhaitiez que Claude crée un problème GitHub lorsqu'il détecte un bogue lors de la révision du code. Sans MCP, vous devrez écrire du code personnalisé pour gérer la sortie de Claude, vous connecter à GitHub et effectuer l'appel d'API. Avec MCP, il vous suffit d'enregistrer une intégration GitHub qui fournit à l'outil create_issue des paramètres tels que le référentiel, le titre, le corps et les étiquettes. Claude peut alors trouver et utiliser directement cet outil.
Les intégrations MCP ne se contentent pas de connecter Claude aux outils, elles définissent la manière dont Claude reconnaît ces outils et interagit avec eux dès le départ.
En cours d'exécution, Claude ne connaît que les outils mis à disposition par le biais de MCP. La façon dont il interagit avec eux suit une séquence définie.
Cette étape se produit avant que Claude interagisse avec quoi que ce soit. Un outil est enregistré auprès d'un serveur MCP, y compris son nom, sa description et son schéma d'entrée. Le schéma aide le modèle à comprendre l'outil. Si l'enregistrement n'est pas clair, Claude peut choisir le mauvais outil.
Un lecteur de fichiers peut exposer un paramètre de chemin. Une intégration GitHub peut exposer le référentiel, la branche et l'identifiant de problème. Un outil de journalisation peut prendre service_name, time_range et severity_filter.
Découverte d'outils
Lorsque Claude se connecte, il envoie une demande d'outils/de liste :
{
"method": "tools/list"
}
Le serveur renvoie les outils disponibles et leurs schémas. Cette liste devient l'ensemble des actions possibles de Claude. Claude ne devine pas, il lit une interface clairement définie.
Invocation
Lorsque Claude a besoin d'un outil, il envoie une requête call_tool avec des arguments. Supposons que Claude découvre un problème de sécurité lors de l'examen. Il peut invoquer l'intégration GitHub comme ceci :
{
"method": "call_tool",
"params": {
"name": "github_create_issue",
"arguments": {
"repository": "acme/payment-service",
"title": "SQL injection vulnerability in user input handler",
"body": "Found unsanitized user input in src/handlers/payment.py line 142...",
"labels": ["security", "high-priority"]
}
}
}
Si les arguments sont erronés ou si les définitions des outils ne sont pas claires, les choses peuvent échouer à ce stade.
Gestion des réponses
L'outil s'exécute indépendamment du modèle et renvoie un résultat. Claude lit ce résultat et passe à autre chose. Parfois, le résultat est clair, mais d'autres fois, il est compliqué ou incomplet. Quoi qu'il en soit, cela affecte ce qui se passe ensuite.
Ce cycle d'enregistrement, de découverte, d'invocation et de réponse est la façon dont MCP fonctionne dans Claude Code.
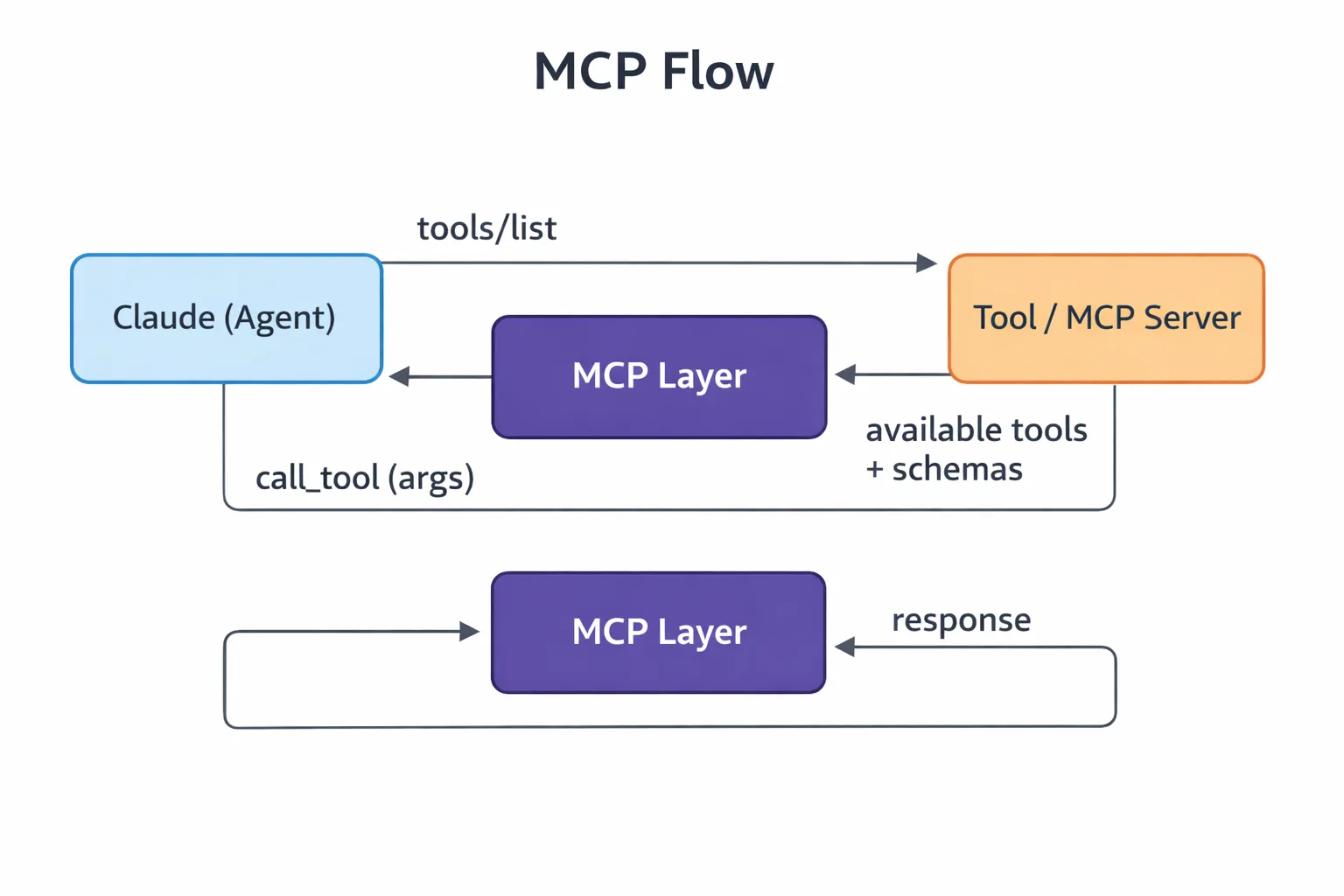
Les intégrations MCP utilisent toutes le même protocole, mais elles ne fonctionnent pas toutes de la même manière. Des différences apparaissent dans la façon dont ils gèrent l'état, dans quelle mesure leurs réponses sont prévisibles et dans quelle mesure Claude doit gérer le contexte.
Intégrations de systèmes de fichiers
Ce sont les types les plus simples. Claude lit et écrit des fichiers en cycles rapides. C'est rapide et généralement prévisible, mais aussi fragile. Si un chemin de fichier est manquant ou si une écriture est incomplète, le flux de travail peut être interrompu sans erreur claire. J'ai vu des agents se bloquer parce qu'une lecture de fichier renvoyait une valeur vide au lieu d'une erreur. Intégrations de référentiels
Il s'agit notamment de GitHub, GitLab et d'autres outils similaires. Claude peut lire les pull requests, vérifier les commits, créer des problèmes et envoyer des modifications. C'est puissant mais cela peut être risqué. Si les autorisations ne sont pas configurées correctement, un agent peut fusionner du code alors qu'il ne devrait pas le faire. Vous devez être prudent avec les autorisations, car lire des pull requests n'est pas la même chose qu'écrire dans des branches.
Intégrations d'API
Il s'agit de services externes accessibles via HTTP. Ils sont plus structurés mais moins indulgents. Vous devez gérer les appels réseau, l'authentification, les limites de débit et les délais d'attente. Des incohérences de schéma peuvent apparaître au milieu d'une course. J'ai débogué des cas où Claude n'arrêtait pas de réessayer un appel Jira qui échouait en raison d'une erreur de validation de champ masquée.
Journal et observabilité
Claude peut interroger des journaux, des traces ou des métriques. Il s'agit principalement d'opérations de lecture impliquant de grandes quantités de données. Le principal défi est de poser la bonne question. Un outil qui renvoie 10 000 lignes de journal n'est pas utile, mais un outil qui vous permet de filtrer par plage horaire, gravité et service est bien meilleur.
Intégrations de bases de données
Elles sont imposantes et comportent plus de risques. Claude crée des requêtes sur la base de schémas qu'il ne comprend peut-être pas complètement. Ici, la précision est plus importante que la vitesse. La plupart des équipes les configurent en lecture seule.
Ils utilisent tous le même protocole, mais leur comportement dans la pratique peut varier considérablement.
Le système fonctionne bien car chaque couche reste séparée. Si vous les combinez, cela devient rapidement plus difficile à comprendre et à gérer.
La couche d'agent est Claude lui-même. Il détermine ce que vous voulez, décide des informations dont il a besoin et décide si un outil doit être utilisé. Claude ne gère rien directement, il planifie, choisit et délègue les tâches.
La couche MCP fait office de limite de protocole et normalise la façon dont les outils sont décrits et appelés. Pour Claude, chaque outil, qu'il s'agisse d'un lecteur de fichiers, d'une base de données ou d'une API externe, apparaît comme une interface structurée, car MCP les rend tous identiques.
La couche d'outils est l'endroit où les choses se passent réellement. Les commandes sont exécutées, les fichiers sont modifiés et des appels d'API sont effectués. C'est là que les véritables effets se produisent.
Claude réfléchit sans interagir directement avec le système. Les outils gèrent l'exécution sans prendre de décisions. MCP transforme les intentions de Claude en actions concrètes.
Cette configuration explique certains choix de conception. Pourquoi Claude n'appelle-t-il pas directement l'API GitHub ? Il ne devrait pas avoir besoin de savoir qu'il s'agit de GitHub. Au lieu de cela, il voit simplement un outil appelé create_issue avec un schéma. L'authentification, les limites de débit et la gestion des erreurs sont toutes effectuées dans la couche d'outils, derrière le protocole.
MCP rend la connectivité plus propre. Cela ne le rend pas prêt pour la production à lui seul.
Pas de gouvernance centralisée
MCP met des outils à disposition, mais ne contrôle pas qui peut voir quoi au sein des différentes équipes ou environnements. Au fur et à mesure que vous ajoutez d'autres intégrations, cela devient un défi. Un agent peut voir trop d'outils, alors qu'un autre n'en voit pas assez. Il n'y a pas de lieu central pour maintenir la cohérence.
Par exemple, si vous avez trois déploiements Claude, un pour la révision du code, un pour la réponse aux incidents et un pour la documentation, chacun nécessite un accès à un outil différent. L'agent de révision de code ne doit pas voir les outils de base de données de production, et la réponse aux incidents ne doit pas être écrite dans le référentiel principal. Avec le MCP natif, vous devez configurer chaque déploiement séparément en espérant que rien ne se désynchronise.
Lacunes de sécurité
L'accès à l'outil est basé sur les informations d'identification utilisées. De nombreuses configurations MCP utilisent des autorisations de niveau de service trop étendues. Si vous les renforcez, les flux de travail peuvent être interrompus. Si vous les laissez ouverts, vous augmentez le risque. Le protocole ne résout pas ce problème.
Aucune observabilité
Claude utilise des outils et passe à autre chose, laissant invisible ce qui s'est passé entre les deux. Quel outil a été sélectionné, pourquoi, avec quels arguments et la réponse sont inconnus. Sans traces, le débogage devient une conjecture. J'ai passé des heures à essayer de comprendre pourquoi un agent avait choisi un outil en particulier, pour me rendre compte qu'il n'y avait aucune trace de cette décision.
Problèmes de dimensionnement
Un petit nombre d'intégrations est gérable, mais en avoir des dizaines devient compliqué. Les noms varient, les schémas diffèrent et les équipes définissent les outils à leur manière. Claude doit travailler avec cette configuration incohérente, ce qui nuit à la fiabilité. Par exemple, si github_create_issue et gh_new_issue sont tous deux enregistrés, Claude doit deviner lequel utiliser.
Il n'y a pas de limite claire à ce qu'un agent doit voir. Les listes d'outils s'allongent au fil du temps. Certains outils deviennent obsolètes, tandis que d'autres sont trop puissants. Une liste encombrée nuit aux performances et au contrôle.
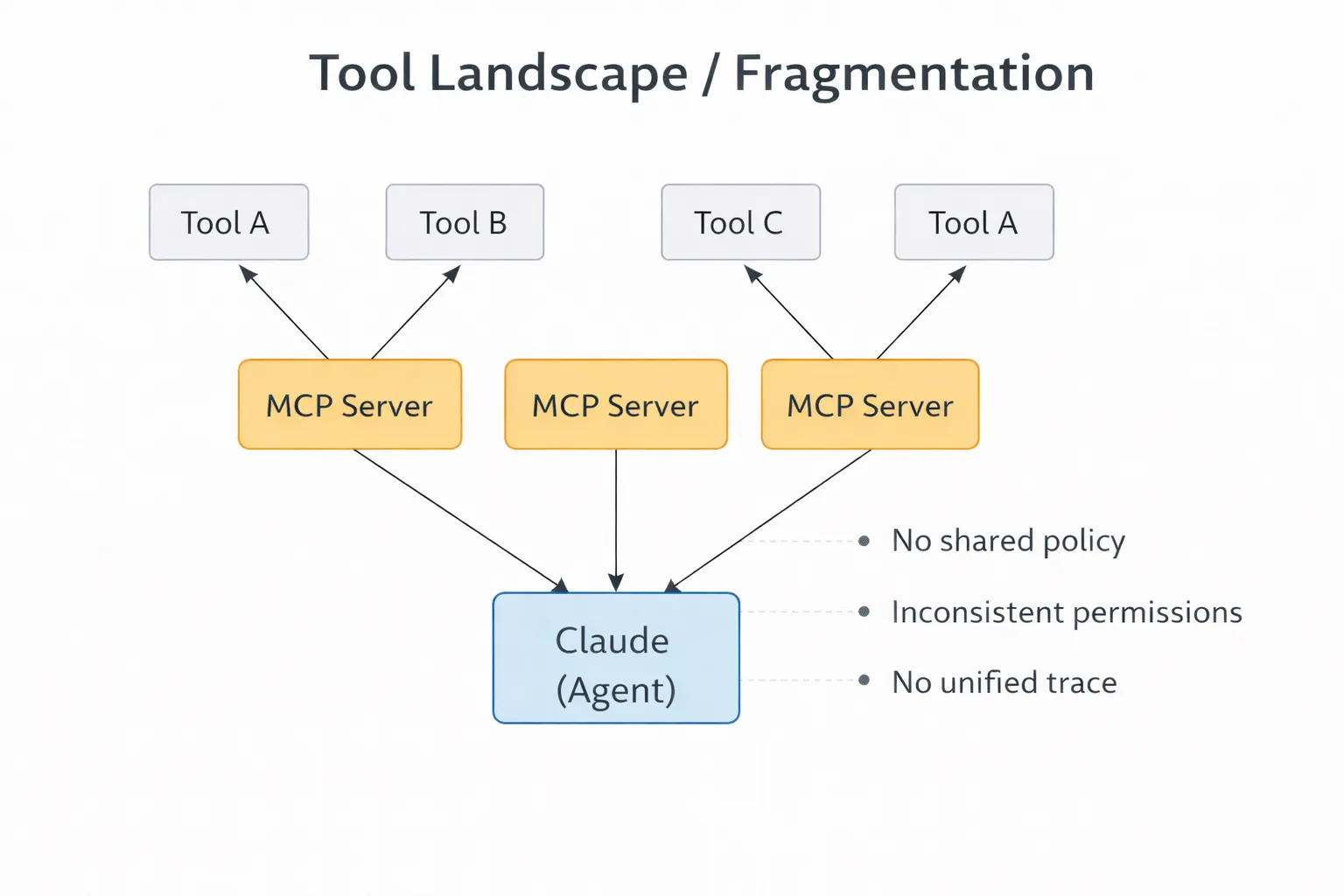
MCP gère les connexions, mais ne gère pas le contrôle.
Au fur et à mesure que les équipes passent de quelques intégrations à une production complète, leurs besoins évoluent. Les outils doivent être gérés, pas simplement trouvés. Quel agent peut utiliser quel outil ? Dans quelles conditions ? Avec quelles limites ? Native MCP ne répond pas clairement à ces questions.
C'est là que les passerelles deviennent utiles. Ils ne constituent pas simplement des frais généraux supplémentaires, ils aident à gérer une complexité croissante.
Une passerelle se trouve entre les serveurs Claude et MCP. Elle limite la visibilité de l'outil en fonction de l'identité de l'agent. Il applique l'authentification avant que les requêtes n'atteignent les outils en aval. Il applique des limites de débit, enregistre les appels et rejette les violations des politiques.
L'audit fonctionne de la même manière. Lorsque les agents interagissent avec les systèmes de production, par exemple en créant des problèmes, en interrogeant des bases de données ou en lisant des journaux, les équipes doivent savoir ce qui a été fait, par qui et pourquoi. Sans cela, le débogage et la conformité sont réactifs, vous ne découvrez les problèmes qu'une fois qu'ils se sont produits.
Une simple intégration devient quelque chose de plus : une couche de contrôle entre les agents et les outils qui façonne le fonctionnement de l'accès dans des situations réelles.
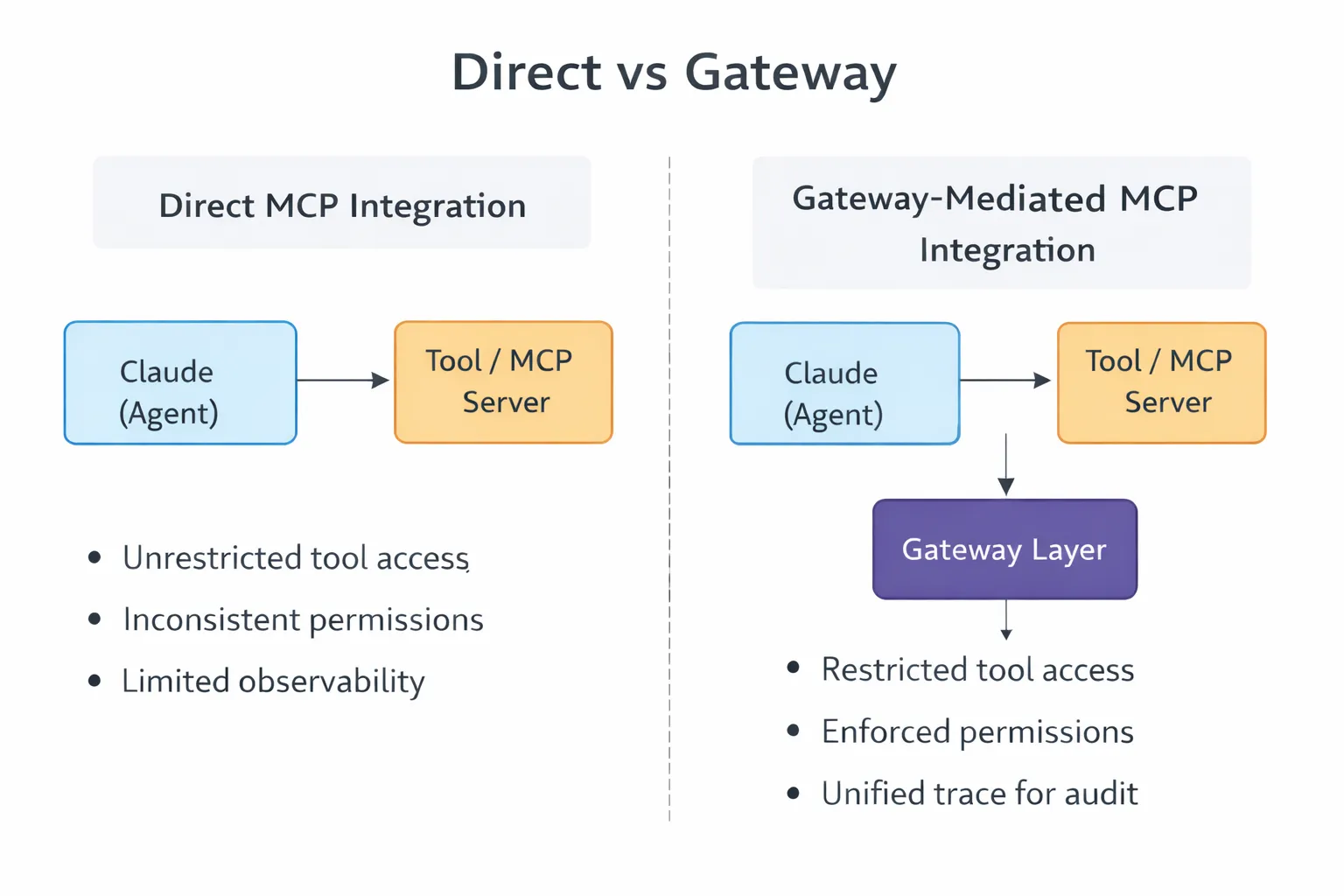
Les intégrations MCP fonctionnent mieux lorsque vous les considérez comme des interfaces et non comme des raccourcis.
L'accès à l'outil Scope est restreint.
L'accès doit correspondre à la tâche. Si une intégration doit uniquement lire les métadonnées du référentiel, elle ne doit pas disposer d'informations d'identification permettant de supprimer des branches. Cela semble évident, mais il est souvent ignoré car des autorisations plus étendues sont plus rapides à configurer. Au début, c'est plus rapide, mais vous pourriez passer des semaines à corriger des problèmes après qu'un agent ait supprimé quelque chose qu'il ne devrait pas.
Limiter la visibilité des outils par agent
Le modèle ne doit voir que ce dont il a besoin. Si un agent se contente de lire des fichiers et de rechercher des problèmes, il n'a pas besoin d'accéder aux contrôles de déploiement ni d'écrire dans la base de données. Moins d'options signifie moins d'erreurs.
Concevez des définitions d'outils claires.
Des noms explicites. Des responsabilités restreintes. Schémas prévisibles. Si un seul outil fait cinq choses, Claude en déduit trop. Les bonnes intégrations sont ennuyeuses. Chaque outil fait une chose proprement.
Par exemple, au lieu d'avoir un outil d'opérations GitHub avec de nombreux paramètres, divisez-le en GitHub_Read_PR, GitHub_Create_issue et GitHub_Add_Comment. Cela rend l'objectif de chaque outil clair et limité.
Empêcher l'étalement
Le fait d'avoir trop d'outils similaires rend plus difficile le choix du bon et ralentit le débogage. Il vaut mieux avoir un ensemble d'outils plus petit et bien organisé qu'un ensemble d'outils volumineux et désordonné. Vérifiez régulièrement les enregistrements d'outils, supprimez les outils inutilisés et combinez les outils qui se chevauchent.
Ils permettent de résoudre des problèmes connexes à différents niveaux.
Les API constituent l'interface de base de la plupart des systèmes, et les kits de développement logiciel facilitent leur utilisation. MCP vient compléter les deux, transformant l'accès aux outils en un format cohérent que les agents peuvent utiliser.
MCP ne remplace ni les API ni les SDK. Votre intégration GitHub utilise toujours l'API GitHub. MCP ne fait que normaliser la façon dont Claude trouve et utilise cette intégration.
Le MCP met de l'ordre dans ce qui était autrefois un processus compliqué. Il normalise la manière dont les modèles exposent, découvrent et utilisent les outils. Cela facilite la création d'agents connectés.
Mais ce n'est encore qu'un point de départ. Il ne répond pas aux questions concernant le contrôle, la visibilité ou les politiques. Il ne décide pas quel agent accède à quel outil ni comment les interactions sont auditées. C'est là que l'architecture de votre système doit évoluer. Vous passez des intégrations simples à l'ajout d'une couche gérée devant celles-ci. MCP rend les connexions possibles, mais ce que vous construisez autour de lui déterminera si ces connexions restent gérables.
Que se passe-t-il en cas d'échec d'un appel à l'outil MCP ?
Claude obtient la réponse d'erreur et décide de la marche à suivre. Il peut réessayer, essayer un autre outil ou signaler l'échec. Le problème est que la gestion des erreurs varie selon les intégrations. Certains renvoient des codes structurés. D'autres renvoient des messages vagues. En l'absence de schémas d'erreur cohérents, la restauration devient imprévisible.
Puis-je restreindre les outils qu'un déploiement de Claude voit ?
Pas par le biais de MCP lui-même. Le protocole gère la découverte et l'invocation. Le contrôle d'accès est externe. Vous configurez chaque serveur MCP séparément ou vous ajoutez une passerelle qui filtre la visibilité en fonction de l'identité de l'agent.
Comment les intégrations MCP gèrent-elles l'authentification ?
Au niveau de la couche d'outils, pas de la couche de protocole. Chaque serveur MCP gère les informations d'identification pour les services qu'il encapsule. Claude ne voit pas ces informations d'identification. Cela n'appelle que des outils. Vous sécurisez chaque intégration séparément.
Quel est le coût des performances de MCP ?
Minimale dans la plupart des cas. MCP ajoute une surcharge de protocole pour la découverte et l'invocation, mais l'exécution réelle passe toujours par tout ce que l'outil utilise, généralement des appels d'API directs ou des commandes locales. Les frais sont liés à la standardisation, et non au chemin d'exécution.
Comment corriger une mauvaise sélection d'outils ?
Difficile sans observabilité. Enregistrez chaque réponse à un outil/à une liste et chaque requête call_tool, puis reconstituez manuellement les décisions. Une couche passerelle automatise cette journalisation et simplifie le débogage.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


