

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 8, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les outils de codage assistés par l'IA tels qu'OpenCode modifient fondamentalement la façon dont les développeurs interagissent avec le code. Au lieu de fonctionner sur des extraits isolés, ces systèmes raisonnent en fonction des fichiers, des dépendances et du contexte historique. Il en résulte une augmentation significative de la productivité, mais également un nouveau défi en termes de coûts et d'évolutivité que de nombreuses équipes sous-estiment : utilisation des jetons.
Contrairement aux outils de développement traditionnels dont les coûts de licence sont prévisibles, l'utilisation d'OpenCode est régie par une tarification basée sur des jetons. Chaque interaction, génération de code, refactoring, débogage ou révision consomme des jetons. À mesure que les équipes adaptent l'utilisation aux développeurs, aux référentiels et aux agents automatisés, la consommation de jetons devient le principal facteur de coût.
Ce qui rend cela particulièrement délicat, c'est que l'utilisation des jetons est souvent non intuitif. De petits changements dans la taille du contexte, la structure rapide ou le comportement des agents peuvent entraîner de fortes fluctuations de la consommation de jetons. Sans modèle mental clair de la façon dont les jetons sont utilisés, les équipes ont du mal à prévoir les coûts, à optimiser les flux de travail ou à appliquer des garde-fous.
Ce blog explique comment fonctionne l'utilisation des jetons dans OpenCode au niveau technique, pourquoi les charges de travail liées au code sont particulièrement gourmandes en jetons et ce que les équipes de la plateforme doivent comprendre avant d'étendre l'utilisation en production.
À la base, l'utilisation des jetons OpenCode suit les mêmes mécanismes que la plupart des systèmes alimentés par LLM : les jetons sont consommés à la fois pour les entrées et les sorties. Cependant, la nature des charges de travail de codage ajoute une complexité supplémentaire.
L'utilisation des jetons OpenCode peut être largement divisée en deux catégories :
Dans OpenCode, les jetons d'invite incluent généralement :
Les jetons d'achèvement incluent :
Du point de vue des coûts, les jetons rapides sont souvent le facteur dominant dans l'utilisation d'OpenCode, en particulier à mesure que les référentiels et la taille des contextes augmentent.
Les tâches liées au code se comportent très différemment des requêtes en langage naturel. Plusieurs facteurs contribuent à l'augmentation de la consommation de jetons :
Contrairement aux cas d'utilisation basés sur le chat, OpenCode envoie souvent :
Même une « petite » base de code peut rapidement se traduire en dizaines ou centaines de milliers de jetons lorsque plusieurs fichiers sont inclus.
Le code source est dense. La syntaxe, l'indentation, les symboles et la mise en forme comptent tous pour les jetons. Quelques milliers de lignes de code peuvent consommer bien plus de jetons qu'une quantité équivalente de texte brut.
Les flux de travail OpenCode impliquent fréquemment :
Chaque étape peut renvoyer du contexte ou des sorties intermédiaires, multipliant ainsi l'utilisation des jetons sur une seule tâche.
Lorsqu'OpenCode est utilisé par le biais d'agents ou d'une automatisation (par exemple, lors de la refactorisation de plusieurs fichiers ou de l'exécution dans des pipelines CI), l'utilisation des jetons augmente rapidement :
Cela rend l'utilisation pilotée par les agents puissante mais également coûteuse si elle n'est pas limitée.
L'un des plus grands défis liés à l'utilisation des jetons OpenCode est que les développeurs voient rarement le contexte complet envoyé au modèle. Éditeurs et outils de manière abstraite :
Par conséquent, deux tâches apparemment similaires peuvent avoir des empreintes symboliques très différentes. Sans suivi explicite au niveau de la demande, les équipes découvrent souvent les problèmes de coûts uniquement après les pics d'utilisation.
C'est pourquoi comprendre la mécanique des jetons ne suffit pas à lui seul. Les équipes ont besoin visibilité de la consommation réelle de jetons par tâche, par développeur et par flux de travail pour prendre des décisions d'optimisation éclairées.

La plupart des pics d'utilisation des jetons OpenCode ne sont pas causés par une seule erreur évidente. Ils découlent de la manière dont OpenCode est utilisé dans les flux de travail d'ingénierie du monde réel, en particulier lorsque les outils et les agents sont profondément intégrés dans les pipelines de développement et d'automatisation.
Vous trouverez ci-dessous les scénarios les plus courants qui augmentent de manière disproportionnée la consommation de jetons.
L'un des principaux contributeurs à l'utilisation élevée des jetons est inclusion contextuelle trop large. De nombreux flux de travail OpenCode incluent des répertoires entiers ou de grands sous-ensembles d'un référentiel pour « garantir leur sécurité », même lorsque seule une petite partie du code est pertinente.
Les exemples incluent :
Étant donné que les jetons rapides évoluent de manière linéaire en fonction de la taille du contexte, ce modèle à lui seul peut rapidement multiplier les coûts.
OpenCode fonctionne souvent de manière itérative : générer du code, réviser, ajuster, régénérer. Dans de nombreuses configurations, chaque itération renvoie le contexte complet, y compris les fichiers et les sorties précédentes.
Cela conduit à :
Sans mise en cache ni réutilisation intelligente du contexte, l'itération devient l'un des modèles les plus coûteux.
Lorsqu'OpenCode est utilisé via des agents ou des flux de travail automatisés, l'utilisation des jetons peut augmenter rapidement si l'exécution n'est pas explicitement limitée.
Les causes courantes incluent :
Comme ces processus s'exécutent souvent en arrière-plan, les équipes peuvent ne pas remarquer une utilisation excessive avant une hausse des coûts.
Les tâches de refactorisation et de révision sont généralement plus gourmandes en jetons que la génération de code, car elles nécessitent :
Lorsque ces tâches sont appliquées à de grandes bases de code ou à plusieurs pull requests, l'utilisation des jetons augmente considérablement.
L'utilisation d'OpenCode intégrée dans les pipelines CI ou les flux de travail d'automatisation introduit un profil de risque différent. Ces systèmes :
Même une utilisation modeste de jetons par exécution peut devenir coûteuse si elle est multipliée sur de nombreux builds ou déploiements.
Enfin, l'un des facteurs les plus négligés de l'utilisation élevée de jetons est l'absence de visibilité. Quand les équipes ne peuvent pas voir :
L'optimisation devient une conjecture. Les équipes réagissent souvent en limitant l'utilisation à l'échelle mondiale, plutôt que de s'occuper des flux de travail spécifiques qui génèrent des coûts.
Une fois que les équipes ont compris d'où vient l'utilisation des jetons, l'étape suivante est l'optimisation. Il est important de noter que l'optimisation ne consiste pas à limiter arbitrairement l'utilisation, mais à utilisation intentionnelle de jetons afin que les gains de productivité ne se transforment pas en coûts incontrôlés.
Vous trouverez ci-dessous les meilleures pratiques pratiques qui réduisent régulièrement l'utilisation des jetons OpenCode sans dégrader la qualité de sortie.
Le levier d'optimisation le plus efficace est contrôler le contexte envoyé au modèle. Plus de contexte n'est pas toujours préférable, surtout lorsque cela n'est pas pertinent.
Les techniques pratiques incluent :
Une bonne règle de base : si un fichier n'est pas obligatoire raison du changement, cela ne devrait pas faire partie de l'invite.
Au lieu d'envoyer de grandes quantités de code à l'avance, les équipes devraient s'orienter vers récupération à la demande.
Exemples :
Cette approche réduit la taille du prompt tout en améliorant souvent la qualité du raisonnement, car le modèle reçoit des informations plus ciblées.
Les invites génériques ont tendance à encourager un raisonnement plus large et des résultats plus importants, ce qui augmente à la fois le nombre de points d'invite et de complétion.
De meilleurs modèles :
Les instructions à portée de tâche réduisent non seulement l'utilisation des jetons, mais améliorent également le déterminisme.
Les flux de travail basés sur des agents amplifient l'utilisation des jetons s'ils ne sont pas cochés. Chaque agent doit opérer dans des limites clairement définies.
Les principaux garde-corps sont les suivants :
Sans ces limites, les agents peuvent retraiter involontairement des contextes volumineux à plusieurs reprises, ce qui augmente leur utilisation.
De nombreux flux de travail OpenCode répètent des tâches similaires d'une itération à l'autre ou d'un utilisateur à l'autre. La mise en cache peut réduire de manière significative la consommation de jetons redondants.
Scénarios applicables :
Même une mise en cache partielle au niveau du flux de travail peut permettre de réaliser des économies significatives.
Alors que les jetons rapides dominent souvent, les jetons de complétion sont également importants, en particulier dans les flux de travail de refactorisation ou riches en explications.
Les techniques incluent :
Des contraintes de sortie claires réduisent la verbosité inutile.
Enfin, l'optimisation ne doit pas être réactive. Les équipes doivent instrumenter l'utilisation des jetons dès le premier jour.
Cela signifie au minimum le suivi :
Sans ces données, les équipes ne peuvent pas faire la distinction entre utilisation productive et gaspillage.
La plupart des équipes n'ont pas de difficultés à utiliser les jetons OpenCode dès le premier jour. Les problèmes apparaissent progressivement à mesure que l'utilisation se répand entre les développeurs, les référentiels et les flux de travail automatisés. Ce qui n'est au départ qu'un outil de productivité individuel devient rapidement une infrastructure partagée et l'utilisation des jetons évolue d'une manière difficile à prévoir ou à gérer.
À grande échelle, OpenCode n'est plus utilisé par un seul développeur dans un éditeur. Il est utilisé par :
Chacun de ces consommateurs génère une utilisation de jetons de manière indépendante. Sans une vue centralisée, il devient difficile de répondre à des questions de base telles que qui utilise des jetons, dans quel but, et à quel prix.
Les premiers efforts d'optimisation sont souvent mis en œuvre au niveau de l'application ou de l'outil, des limites d'invite personnalisées, du découpage du contexte ou de la logique de nouvelle tentative. Bien que ceux-ci soient utiles au niveau local, ils ne s'étendent pas à :
Par conséquent, les politiques deviennent fragmentées et incohérentes. Une équipe optimise de manière agressive tandis qu'une autre augmente les coûts sans le savoir.
L'automatisation change les règles du jeu. Un flux de travail qui consomme un petit nombre de jetons par exécution peut devenir coûteux lorsque :
Comme ces tâches sont exécutées sans visibilité humaine directe, les inefficacités s'aggravent rapidement. Les pics d'utilisation des jetons proviennent souvent de l'automatisation plutôt que de l'utilisation interactive.
Sans attribution précise, les équipes ne voient que des chiffres d'utilisation agrégés. Cela rend l'optimisation réactive et directe.
Les modes de défaillance courants incluent :
Un contrôle efficace nécessite de savoir quels flux de travail génèrent de la valeur et lesquels génèrent des déchets quelque chose que les statistiques agrégées ne peuvent pas révéler.
Dans de nombreuses organisations, l'adoption d'outils d'IA dépasse celle de la gouvernance. L'utilisation d'OpenCode se propage plus rapidement que :
Au moment où l'utilisation des jetons devient une préoccupation, l'outillage est déjà profondément intégré aux flux de travail, ce qui rend les contrôles rétroactifs difficiles et perturbateurs.
Le problème principal n'est pas une mauvaise utilisation, c'est utilisation décentralisée sans contrôle centralisé. À mesure qu'OpenCode devient une infrastructure partagée, l'utilisation des jetons doit être gérée de la même manière que les équipes gèrent les ressources de calcul, de stockage ou de CI.
Cela nécessite :
Sans ce changement, l'utilisation des jetons reste imprévisible et les efforts d'optimisation restent réactifs.
Une fois que l'utilisation d'OpenCode atteint l'échelle de production, le suivi ad hoc et les optimisations manuelles cessent de fonctionner. À ce stade, l'utilisation des jetons doit être traitée comme n'importe quelle autre ressource d'infrastructure partagée : mesuré en continu, géré de manière centralisée et lié à la propriété.
De nombreuses équipes commencent par suivre l'utilisation des jetons dans des outils ou des flux de travail individuels. Bien que cela fournisse des informations locales, cela se décompose rapidement lorsque :
Chaque intégration rend compte de l'utilisation différemment, et aucune n'offre une vue d'ensemble. Par conséquent, les équipes de la plateforme ne disposent pas d'une source fiable unique pour la consommation de jetons.
À grande échelle, la surveillance doit se faire au niveau de demande, et pas seulement au niveau de l'outil. Capture efficace des configurations :
Cela permet aux équipes de répondre à des questions telles que :
Sans cette granularité, les efforts d'optimisation restent grossiers et souvent mal orientés.
La gouvernance commence par l'attribution. L'utilisation des jetons doit être mappée aux propriétaires qui peuvent agir en conséquence.
Les modèles d'attribution courants incluent :
Une fois que la propriété est claire, les discussions sur les coûts passent d'une budgétisation abstraite à des décisions concrètes concernant les flux de travail offrant une valeur suffisante.
Le suivi à lui seul ne permet pas d'éviter les dépassements de coûts. Les systèmes de production nécessitent mécanismes d'exécution qui fonctionnent en temps réel.
Les garde-corps typiques incluent :
Ces contrôles doivent être appliqués de manière centralisée afin que tous les flux de travail alimentés par OpenCode en héritent automatiquement.
Le fil conducteur de toutes les structures de gouvernance efficaces est centralisation. Les politiques, les limites et la visibilité relatives à l'utilisation des jetons doivent exister à un point de contrôle partagé plutôt que d'être réimplémentées entre les outils.
C'est là que les plateformes orientées vers l'infrastructure telles que True Foundry s'adapte naturellement. En centralisant le trafic d'IA, l'observabilité et l'application des politiques, les équipes de la plateforme peuvent gérer l'utilisation des jetons OpenCode de manière cohérente entre les développeurs, les agents et les systèmes automatisés, sans ralentir les équipes individuelles.
Du point de vue de la plate-forme, le principal défi lié à l'utilisation des jetons OpenCode est le manque de compréhension comment les jetons sont consommés, mais où le contrôle et la visibilité devraient résider.
TrueFoundry aborde ce problème en traitant l'utilisation de l'IA et du LLM, y compris les outils destinés aux développeurs tels qu'OpenCode, comme une infrastructure partagée qui doit être observable, gérable et soucieuse des coûts par défaut. Au cœur de cette approche se trouve le Passerelle IA, qui fait office de plan de contrôle pour tout le trafic LLM au sein de l'organisation.
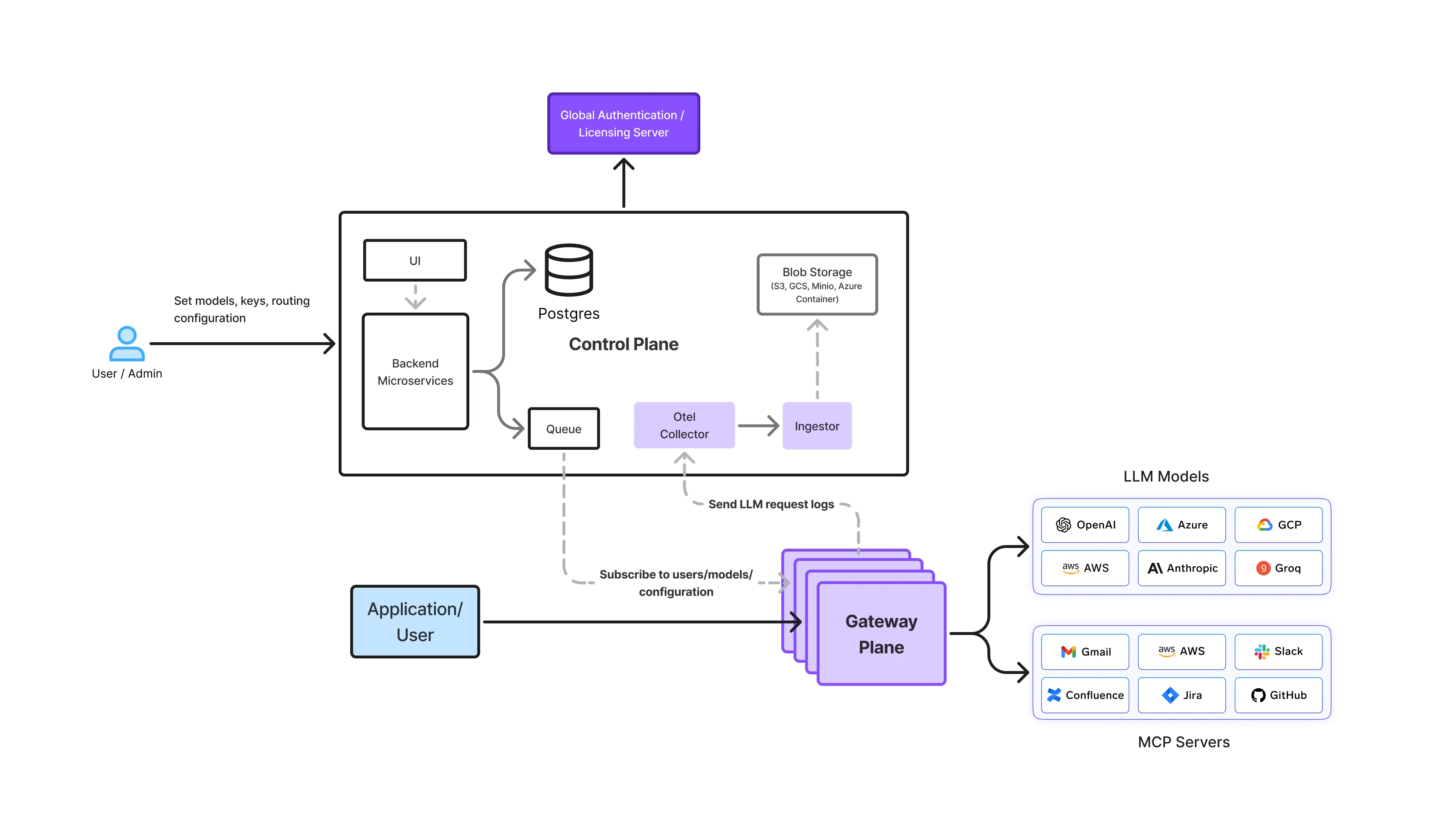
Dans une configuration TrueFoundry, OpenCode n'interagit pas directement avec les fournisseurs LLM sous-jacents. Au lieu de cela, toutes les demandes passent par l'AI Gateway, qui fournit une interface unique et cohérente pour l'inférence.
Sur le plan architectural, cela permet de :
En supprimant l'accès direct aux modèles depuis les outils individuels, les équipes de la plateforme bénéficient d'une visibilité complète sur la manière dont OpenCode est réellement utilisé par les développeurs, les agents et l'automatisation.
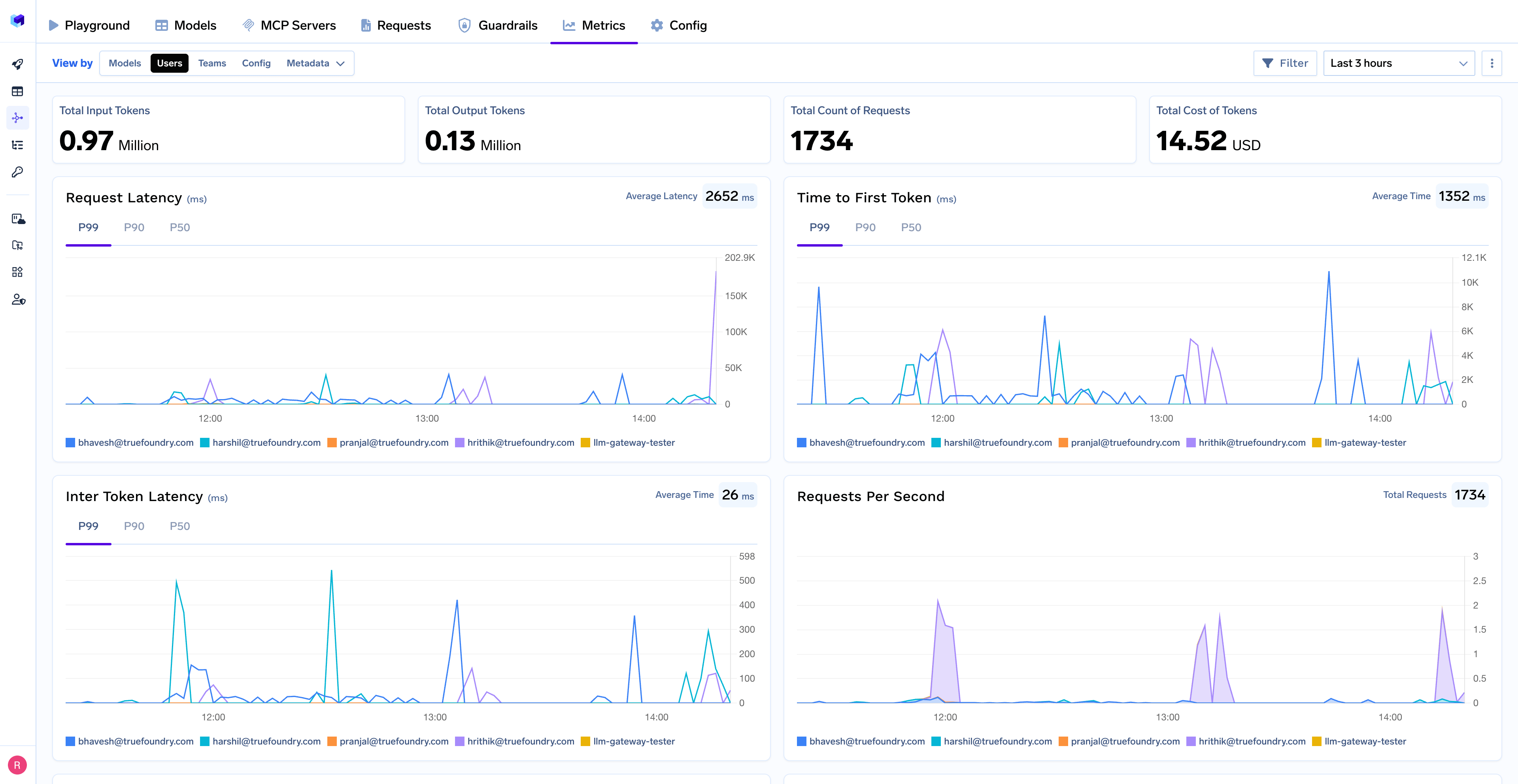
La passerelle IA de TrueFoundry capture utilisation des jetons au niveau de la demande, y compris :
Il est essentiel que cette télémétrie ne soit pas bloquée dans un système contrôlé par le fournisseur. Les journaux et les métriques sont conservés dans le cloud et le stockage du client, ce qui permet aux équipes de :
Cela permet d'éviter le problème de « boîte noire » courant avec les outils d'IA et permet une optimisation à long terme.
Étant donné que tout le trafic OpenCode passe par la passerelle, des contrôles des coûts peuvent être appliqués de manière cohérente et en temps réel.
Les équipes de la plateforme peuvent :
Ces politiques sont appliquées une fois sur la passerelle et s'appliquent automatiquement à chaque flux de travail basé sur OpenCode sans nécessiter de modifications des éditeurs, des plugins ou des outils internes.
L'architecture de TrueFoundry est conçue pour les environnements dans lesquels l'utilisation d'OpenCode s'étend au-delà de l'IDE. Les pipelines CI, les tâches en arrière-plan et les agents génèrent souvent la consommation de jetons la plus importante et la moins visible.
En acheminant ces charges de travail via la même passerelle IA, les équipes peuvent :
Cela permet d'étendre l'utilisation d'OpenCode à l'échelle de l'organisation sans perdre en prévisibilité ni en contrôle.
L'utilisation des jetons OpenCode est la véritable contrainte d'échelle pour le codage assisté par l'IA. À mesure que l'utilisation se propage entre les développeurs, les référentiels, l'automatisation et les agents, la consommation de jetons devient difficile à prévoir et à contrôler sans visibilité et gouvernance centralisées.
La gestion de cela au niveau de l'outil ou de l'application n'est pas évolutive. L'utilisation des jetons nécessite une observabilité au niveau de la demande, une attribution claire et une application en temps réel, en traitant le codage assisté par l'IA comme une infrastructure partagée et non comme une fonctionnalité isolée.
Des plateformes comme True Foundry reflètent cette approche en centralisant le trafic OpenCode via une passerelle IA, permettant aux équipes de surveiller, de gouverner et d'optimiser l'utilisation des jetons de manière cohérente. Pour les responsables des plateformes et de l'ingénierie, le point à retenir est simple : si OpenCode est au cœur de la conception des logiciels, l'utilisation des jetons doit être gérée avec la même rigueur que toute autre ressource d'infrastructure critique.
La vérification précise de l'utilisation des jetons OpenCode nécessite un suivi et une instrumentation explicites au niveau de la demande. Étant donné que les outils résument souvent le contexte complet envoyé au modèle, il est essentiel de disposer d'une visibilité sur la consommation réelle de jetons par tâche, développeur et flux de travail pour prévoir les coûts et optimiser efficacement votre utilisation.
L'utilisation des jetons Opencode est le modèle de tarification basé sur les jetons pour les outils de codage assistés par l'IA tels qu'OpenCode. Chaque interaction, qu'il s'agisse des invites de saisie et du contexte du code, du code généré et des explications, consomme des jetons. La gestion de cette utilisation de jetons OpenCode est cruciale car elle devient le principal facteur de coûts pour les équipes de développement aux États-Unis.
Pour réduire l'utilisation des jetons OpenCode, limitez l'injection de contexte aux seuls fichiers essentiels, en évitant d'inclure de nombreux référentiels. Empêchez la réhydratation répétée du contexte en réutilisant intelligemment les résultats au fil des itérations. Décomposez les tâches complexes en étapes plus petites et utilisez des instructions précises. Le suivi de la consommation de jetons pour chaque tâche fournit des informations essentielles pour optimiser les coûts et l'efficacité.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


