Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Résoudre les goulots d'étranglement liés aux données SEO grâce à des agents autonomes et à TrueFoundry
Published: April 22, 2026
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Gère plus de 350 RPS sur un seul processeur virtuel, aucun réglage n'est nécessaire
Prêt pour la production avec un support complet pour les entreprises
C'est lundi matin. Votre responsable SEO consulte trois onglets de navigateur différents : Google Search Console (GSC), Looker Studio et une feuille de calcul qui se bloque si vous faites défiler la page trop rapidement. Ils exportent manuellement des milliers de lignes de données de requêtes, tentent de comparer VLOOKUP aux performances de la semaine dernière et appliquent des filtres subjectifs pour décider du contenu que l'équipe d'ingénierie devrait créer ensuite.
C'est le problème du « dernier kilomètre » de l'analyse des données. Nous disposons d'outils de collecte sophistiqués, mais la synthèse proprement dite, c'est-à-dire la couche décisionnelle, repose sur un ciment humain fragile.
Chez TrueFoundry, nous avons réalisé que notre flux de travail d'ingénierie de croissance était bloqué par cette agrégation manuelle. Nous n'étions pas limités par les données ; nous étions limités par le débit des analyses humaines. Pour résoudre ce problème, nous n'avons pas acheté d'autre outil de tableau de bord. Nous avons construit le Agent d'automatisation des mots clés, un système qui traite les métriques de référencement comme un flux d'ingénierie plutôt que comme un rapport statique, alimenté par la passerelle TrueFoundry AI et le protocole MCP (Model Context Protocol).
Le changement technique : de l'analyse statique aux pipelines adaptatifs
L'approche standard des opérations de référencement est Basé sur le sondage et manuel: les humains récupèrent périodiquement des données, appliquent des règles codées en dur (par exemple, « volume > 100 ») et devinent leur pertinence.
Nous sommes passés à Prouvé par les événements et probabiliste modèle :
Notation déterministe : Les mathématiques gèrent les métriques évidentes (deltas CTR, distance de classement).
Filtrage probabiliste : Les LLM apportent un contexte commercial (par exemple, en sachant que « AI Gateway » est pertinent pour nous, mais pas « Gateway Computer Drivers »).
Abstraction d'outils (MCP) : Les sources de données externes (Ahrefs, Google Trends) sont accessibles via des protocoles standardisés, et non via des wrappers d'API fragiles.
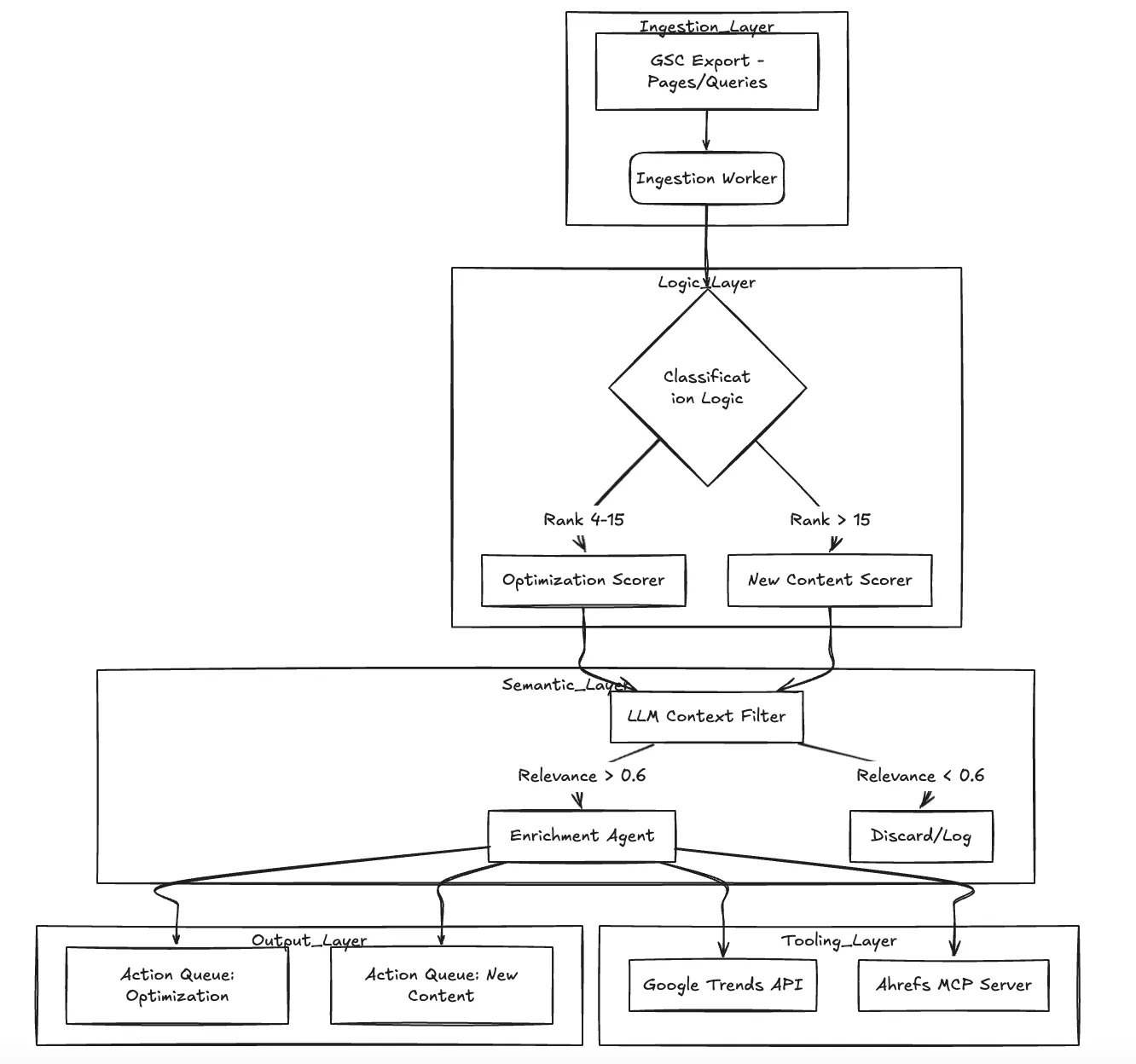
Architecture en profondeur
Le système fonctionne comme un graphe acyclique orienté (DAG) des étapes de traitement. Il ne se contente pas de « résumer » les données ; il les filtre et les enrichit activement.
Composantes principales :
Travailleur chargé de l'ingestion : Analyse les exportations CSV brutes depuis GSC (Pages et requêtes).
Contrôleur de notation : Applique la logique mathématique. Pour l'optimisation, nous utilisons une fonction de décroissance basée sur la distance : $Score = \ log (1 + impressions) \ times (1 - CTR) \ times (\ max (0, 20 - position)) $.
Agent de pertinence (LLM) : Agit en tant que gardien sémantique. Il évalue les mots clés par rapport au contexte du domaine de TrueFoundry (Kubernetes, LLM Ops, Developer Platforms) afin de filtrer le bruit.
Ouvrier chargé de l'enrichissement : Récupère les données de tendance et (dans la V2) les mesures de difficulté externes via MCP.
Infrastructure et TrueFoundry : Gateway et MCP
La mise en œuvre de cette architecture présente deux défis majeurs pour les systèmes distribués : Limitation de débit et Intégration d'outils.
Si vous parcourez simplement 5 000 mots clés et que vous cliquez sur une API LLM pour évaluer la pertinence, vous atteindrez immédiatement les limites de débit. Si vous codez en dur les appels d'API Ahrefs dans votre agent, vous créez un couplage étroit qui s'interrompt chaque fois qu'une version de l'API change.
Nous avons utilisé le Plateforme TrueFoundry pour résoudre les deux problèmes :
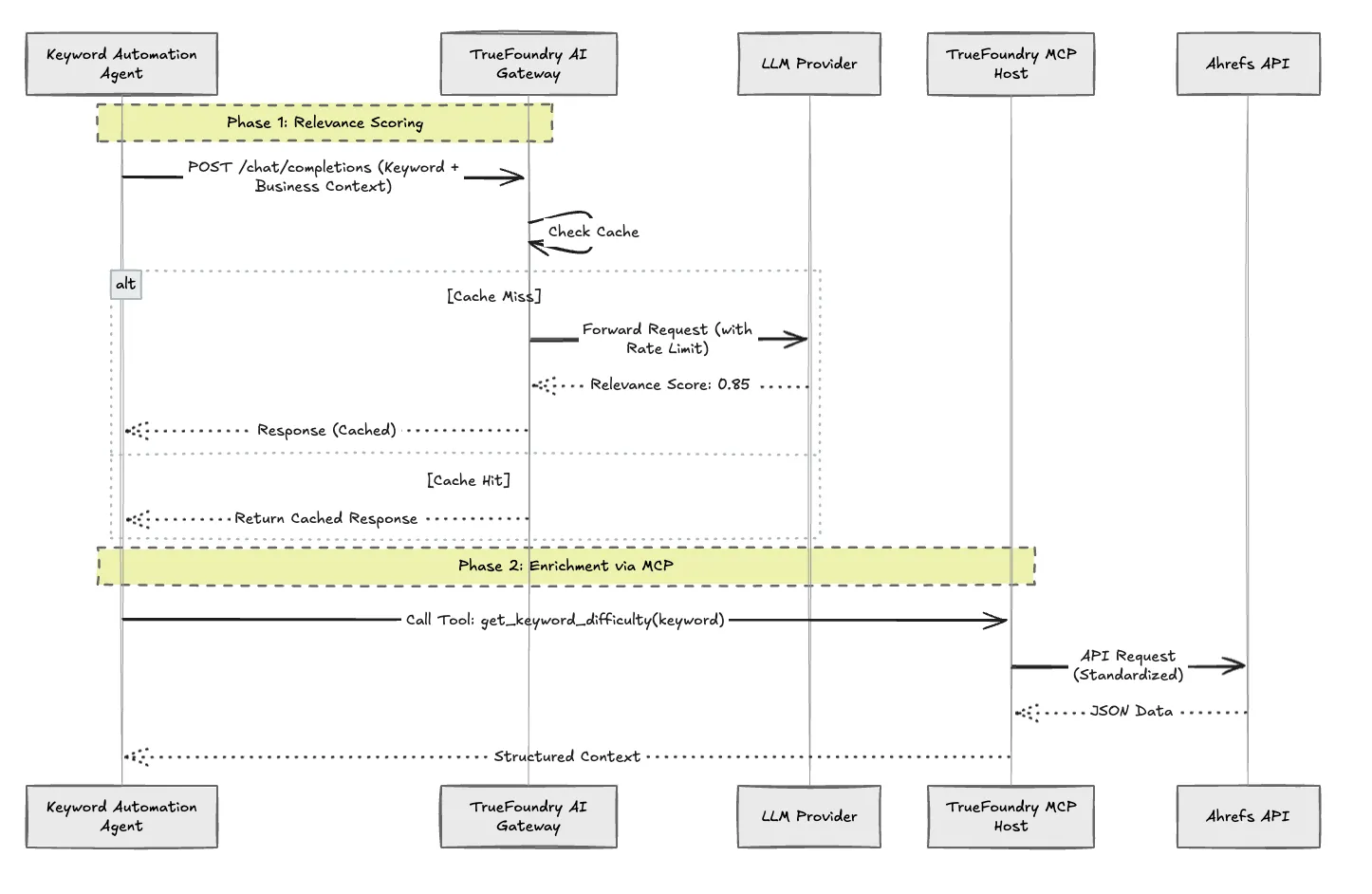
Passerelle TrueFoundry AI : Nous acheminons tous les appels LLM (pour la notation de pertinence et la génération de résumés) via le Gateway. Cela fournit :
Limitation de débit centralisée : Nous établissons un budget de demandes par minute au niveau de la passerelle, afin de protéger nos fournisseurs en aval.
Mise en cache : Si nous avons déjà noté le mot clé « LLM Observability » la semaine dernière, la passerelle affiche le verdict mis en cache, réduisant ainsi la latence et les coûts à zéro.
Modèle de routage : Nous pouvons échanger le modèle sous-jacent (par exemple, de GPT-4 à un modèle moins cher et plus rapide comme Gemini Flash) pour la tâche de classification sans modifier une ligne de code d'application.
Protocole de contexte modèle (MCP) : Au lieu d'écrire des fonctions personnalisées pour Ahrefs, nous déployons un Serveur Ahrefs MCP sur TrueFoundry. L'agent interroge simplement le serveur MCP pour connaître les indicateurs de l'explorateur de site ou la difficulté des mots clés. Le serveur MCP gère l'authentification et les spécificités de l'API. Cela permet de standardiser la façon dont nos agents communiquent avec les outils externes.
Extrait de code
Comparaison : Standard Scripting et TrueFoundry Accelerator
Le tableau suivant explique pourquoi nous avons abandonné les scripts Python locaux au profit d'une architecture gérée.
Dimension
Standard Python Script Approach
TrueFoundry Accelerator Approach
Resilience
Fragile. If the GSC API times out or the script hits an LLM rate limit, the entire process crashes. Requires manual restarts.
High. TrueFoundry Gateway handles retries and exponential backoff. Process isolation ensures one failed batch doesn't kill the pipeline.
Security
Low. API keys for OpenAI and Ahrefs are often stored in local .env files or hardcoded.
Enterprise. Keys are managed in TrueFoundry Secrets. Agents access tools via authenticated MCP endpoints, never touching raw credentials.
Scalability
Vertical. Limited by the local machine's memory when processing large CSVs combined with trend data.
Horizontal. Workers run as microservices on Kubernetes. We can parallelize the scoring of 10,000 keywords across multiple pods.
Maintenance
High. Every time Ahrefs changes an API endpoint, the main application code must be refactored.
Low. Tool logic is isolated in the MCP Server. The core agent logic remains untouched during external API updates.
Gestion des cas extrêmes et fiabilité
Dans un environnement de production, les données sont rarement propres. Nous avons mis en place des garde-corps spécifiques pour garantir la fiabilité :
La porte « Hallucination » : Les LLM peuvent être trop confiants. Nous avons implémenté une porte logique où si pertinence = faux ET confiance < 0,6, le mot clé est supprimé sous forme de bruit. Cependant, si la pertinence est vraie mais que la confiance est inférieure à 0,5, elle est signalée pour un examen humain plutôt que pour un traitement automatique.
Divergence de tendance : Un mode d'échec courant dans le référencement consiste à optimiser pour un mot clé mourant. Notre agent d'enrichissement consulte Google Trends. Si Impression_Trend est stable mais que Market_Trend est en hausse, cela signale une « opportunité manquée ». Si Impression_Trend est en hausse mais que Market_Trend est égal à zéro, cela signale une anomalie de bot probable ou un pic saisonnier, évitant ainsi tout gaspillage d'efforts.
Conclusion
En déplaçant le flux de travail SEO des feuilles de calcul manuelles vers un flux de travail agentique sur TrueFoundry, nous avons réduit le temps nécessaire pour obtenir des informations de plusieurs jours à quelques minutes. Plus important encore, nous avons découplé la logique de l'infrastructure. La passerelle TrueFoundry AI Gateway gère le « coût de la cognition » (appels LLM), tandis que MCP gère la « complexité de l'intégration » (outils externes).
Cette architecture prouve que les outils internes ne doivent pas nécessairement être des scripts hackés. Il peut s'agir de systèmes résilients et évolutifs qui génèrent une véritable valeur commerciale.
Déployez cet accélérateur à partir de la bibliothèque TrueFoundry dès aujourd'hui pour standardiser vos propres flux de travail d'enrichissement des données.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge





























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


