

July 15, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 1, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Anthropic's September 2025 essay on context engineering reframed the discipline: from picking the right words for a single prompt to deciding what information should be in the context window at each step of an agent's work. This post is about the infrastructure that executes those decisions at the gateway layer. Session tracking, conversation compaction, and prefix caching are the gateway-level primitives that let context engineering actually run in production — not the strategy (that belongs to the agent), but the substrate that makes the strategy enforceable across thousands of long-running runs.
Friday afternoon at Northwind. Maya, staff engineer on the platform team, opens the Slack thread titled "#agent-help: code-review is failing on big PRs." She traces the failure to PR #4127 — a 600-line refactor. The agent ran 23 tool calls: read four files, ran the test suite twice, queried the linter, fetched coverage. On turn 24 the model returned a response that repeated the same paragraph three times and ended mid-sentence.
The gateway's session view shows the smoking gun. By the time it failed, the request payload had grown past 185K tokens against a 200K-context model — the two test-suite runs alone had added tens of thousands of tokens each. The agent never noticed it was running out of room; it kept appending tool results to the conversation array until the model's attention budget collapsed.
The fix is usually not a smarter base model. It is infrastructure that prevents the agent from running its context budget into the ground — turning "we accidentally filled the context window" into "the gateway compacted around the 150K threshold, and the agent kept going." This post is how that infrastructure works.
In many 2023-era applications, prompt engineering meant choosing the right phrasing, examples, and ordering to get a single response right. Context engineering, as Anthropic articulated in their September 2025 essay, is the successor — it asks what configuration of context is most likely to produce the model's desired behavior across an agent's entire run, not just one call.
The shift matters because long-running agents accumulate state. Every tool result, prior model response, and user follow-up either lives in the context window or doesn't. Model behavior degrades — context rot, in Anthropic's framing — well before the nominal context limit is reached, with the exact degradation curve varying by model, task, and where the relevant information sits in the window. So the agent has decisions to make: what to keep, what to summarize, what to discard, what to pay full price for, what to cache. Those decisions belong to the agent. The mechanics that execute them belong to the gateway — the layer that, in TrueFoundry's AI Gateway, already sits on every call: tagging a request with a conversation ID, computing what fraction of context is system prompt vs. growing history, calling the compaction endpoint at a threshold, hitting the prefix cache instead of paying for the same 12K-token system prompt on every call. The agent decides the context configuration it wants; the gateway implements that configuration efficiently. The rest of this post is the mechanics.
A single agent run is many provider calls. A code-review agent processing one PR might make 10–30 of them — one to plan, several to read files, several to run tests, one to draft the review, one to revise after a tool error. Without session metadata, the trace store sees 30 disconnected requests; with it, the trace store sees a 30-turn conversation that can be replayed end-to-end.
The convention is a header set by the agent at the outer call. In TrueFoundry's AI Gateway this is the X-TFY-CONVERSATION-ID header — the X-TFY- prefix is TrueFoundry's namespace, paired with the X-TFY-METADATA header from the cost-attribution post. Treat the specific name as an illustrative gateway convention rather than an industry standard; the equivalent header could be named anything, and what matters is that the value propagates through the span tree:
HTTP — application tags every turn of a multi-turn agent with a conversation ID
POST /v1/responses HTTP/1.1
Host: gateway.northwind.internal
Authorization: Bearer ...
Content-Type: application/json
X-TFY-CONVERSATION-ID: conv-pr-4127-review-2026-05-22-14-03
X-TFY-METADATA: {"team": "platform-eng", "app": "code-review-agent",
"feature": "pr-review", "env": "production",
"pr_id": "northwind/cargo-copilot#4127"}
{"model": "claude-sonnet-4-6", "input": [...], "tools": [...]}What the gateway records per session: the ordered sequence of provider calls in the conversation with their trace IDs; cumulative input, output, cache-read and cache-write tokens both per turn and across the conversation; the metadata fields from each call (carrying forward the cost-attribution schema from the previous post); and references to trace IDs rather than the full text — the rendered context window stays with the provider, the session record is small.
This matters for debugging. A 20-turn agent that fails at turn 15 is not debuggable as 20 isolated requests. It needs to be debuggable as a sequence — turn 14 produced a tool result that triggered turn 15's bad behavior; turn 13's input was already 95% of context limit. The session view collapses 20 traces into one queryable timeline with cumulative token counts, latency profile, and cache hit rates per turn.
A coding agent's context window grows in a predictable pattern. For the simplified model below, assume a 12K-token system prompt (tool definitions, style guide, examples) at turn 0, and that each subsequent turn appends roughly 6K rendered tokens — a tool result plus the assistant's response and per-turn overhead. That gives a linear climb of about 6K per turn (real runs are burstier; see the note after the table):
What happens as the window fills is not failure exactly — it is degradation. Model accuracy on retrieval and instruction-following tends to slip well before the nominal limit, and worse, the model gives no signal that it has degraded — confident, well-formatted output that happens to be wrong. By the time the window is full, the model is more likely to hallucinate, repeat itself, miss instructions, or return malformed tool calls. The degradation is a gradient, not a cliff, and where it starts varies by model, task, and where the relevant tokens sit — but the operational implication is the same: infrastructure has to act before behavior collapses, not after. (The table above is an illustrative linear model; real coding-agent runs are typically burstier — a single grep across a large codebase or a verbose test run can add 20K tokens in one turn.)
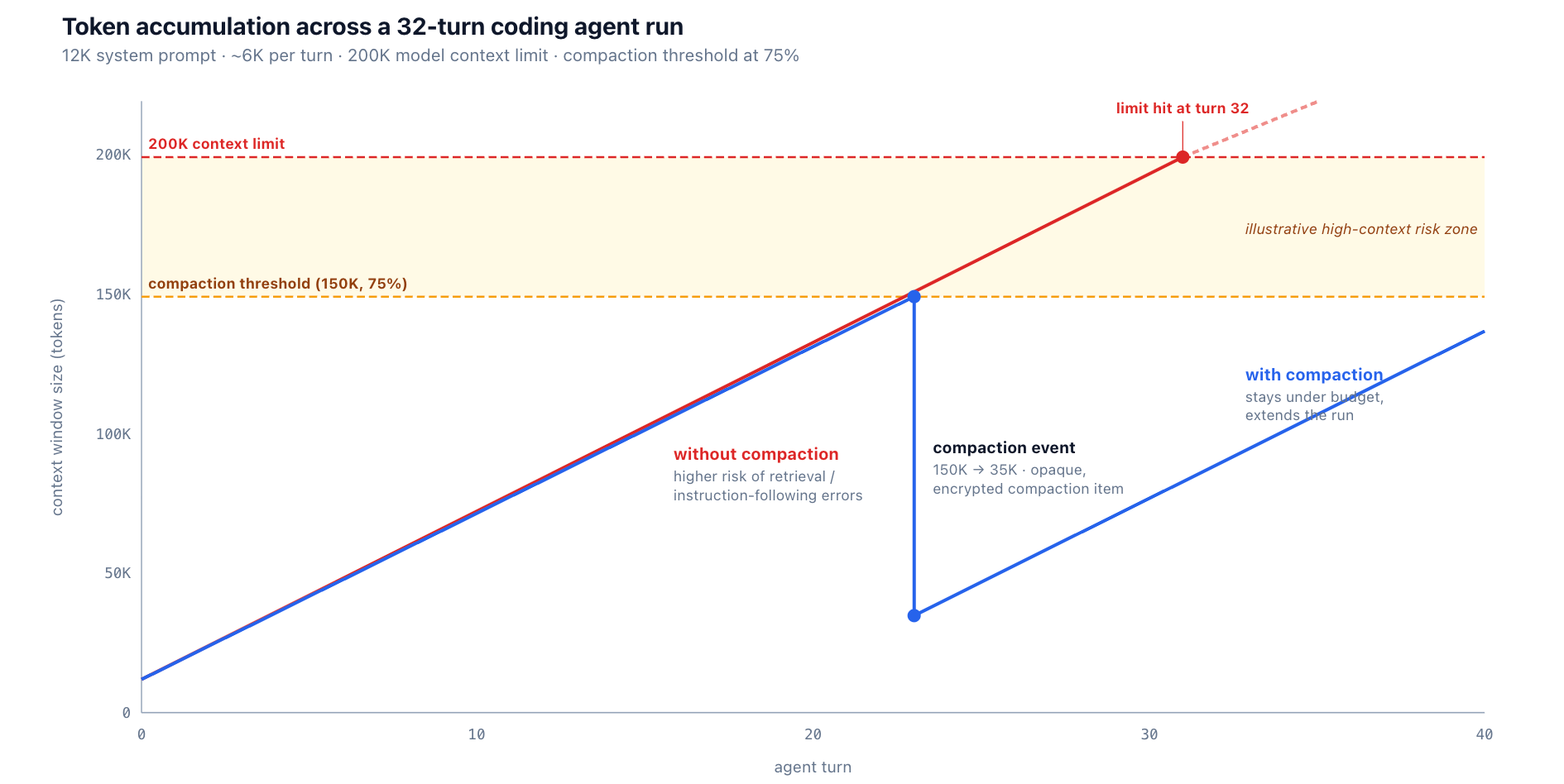
The agent could choose to never grow that big — purge old tool results, write summaries to disk, run sub-agents for each tool call with a fresh context. Those are real strategies and they belong to the agent. The gateway's role is to make the alternative — compaction — easy enough to apply consistently: route it, observe it, attribute its token and latency effects, and enforce policy around when it triggers. In TrueFoundry's AI Gateway, the per-turn token counts that make this table real come from the same session rollup that surfaced the failure in the opening — the accumulation is something you can watch climb, not something you discover after the model breaks.
The OpenAI Responses API supports compaction as a first-class primitive, in two modes.
Standalone (explicit). The application detects context growth, calls POST /v1/responses/compact with the full conversation as input, and receives a new compacted context window. The next /responses call uses that returned window in place of the prior conversation history — passed through as-is, since it carries forward the state the model needs (and may retain some earlier items alongside the compaction item).
Python — explicit compaction when the application decides
from openai import OpenAI
client = OpenAI()
# Up to this point the agent has been appending tool results to `conv`.
# `conv` is now a long list of items totaling ~150K rendered tokens.
compacted = client.responses.compact(
model="gpt-5.5",
input=conv, # the full pre-compaction conversation
)
# The returned window is the canonical next context. Pass it as-is — it
# generally holds more than just the compaction item (it can retain earlier
# items too), and the docs say not to prune it.
next_input = [
*compacted.output,
{"type": "message", "role": "user", "content": new_user_msg},
]
response = client.responses.create(
model="gpt-5.5",
input=next_input,
tools=tools,
store=False, # ZDR-friendly — set on create, not on compact
)Server-side (automatic). The application includes context_management with a compact_threshold in the original /responses request. When the rendered token count crosses the threshold mid-stream, the server compacts in-band, emits an encrypted compaction item in the response stream, and continues inference without a separate round-trip.
Python — automatic server-side compaction via context_management
response = client.responses.create(
model="gpt-5.5",
input=conversation,
tools=tools,
store=False,
context_management=[
{"type": "compaction", "compact_threshold": 150_000}
],
)
# Append all output items as usual. If the server compacted mid-stream, the
# compaction item is included among them.
conversation.extend(response.output)
# Latency tip: after appending, you may drop items before the most recent
# compaction item to keep the next request smaller. (Skip this if you chain
# with previous_response_id — let the server prune.)
last_compaction = None
for i, item in enumerate(conversation):
if getattr(item, "type", None) == "compaction":
last_compaction = i
if last_compaction is not None:
conversation = conversation[last_compaction:]
conversation.append(
{"type": "message", "role": "user", "content": new_user_msg}
)The compaction item itself is opaque to the client. You cannot read it back, edit it, or inspect its contents. It carries forward the state and reasoning the model needs to continue and is significantly smaller than the original conversation. It is ZDR-compatible when store=false is set on the original request.
Two chaining patterns once compaction has happened. Stateless input-array chaining: append output items (including the compaction item) to the next input array, dropping items before the most recent compaction item to keep requests small. previous_response_id chaining: pass only the new user message in the next request and let the server resolve prior state. The first gives the application explicit control over the wire payload; the second offloads it. For ZDR-sensitive workloads, stateless with store=false is the standard pattern. Either way, compaction stays a provider feature; TrueFoundry's gateway routes the call and records it on the session timeline, so the token drop is an observable step you can attribute to the compaction call rather than an unexplained dip in the conversation array.
For most production agents the dominant cost is not the growing conversation — it is the system prompt that ships unchanged on every call. A 12K-token system prompt at Claude Sonnet 4.6 pricing ($3 per million input tokens) costs $0.036 per call without caching. At 1,000 calls per hour, that is $36/hour just for the unchanging instructions. Across one production agent over a year, the system-prompt portion alone runs to roughly $315,000.
Provider-side prefix caching is the fix. Anthropic exposes it via cache_control breakpoints on the prompt; OpenAI applies it automatically on prefix matches of 1,024 tokens or longer. Because the match is on the exact prefix, the practical rule is the same on both providers: put the stable content (system prompt, tool definitions) first and the variable content (the user's turn) last, so the cacheable head stays byte-identical across calls. The Anthropic economics are explicit: cache reads bill at 10% of the input rate ($0.30 per million for Sonnet 4.6); the first call that creates the cache pays a 25% premium for the 5-minute TTL, or 100% for the 1-hour TTL.
JSON — Anthropic cache_control breakpoint on the system prompt
{
"model": "claude-sonnet-4-6",
"system": [
{
"type": "text",
"text": "<12,000 tokens of tool definitions, style guide, examples>",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{"role": "user", "content": "Review PR #4127"}
]
}The economics on a 12K system prompt × 1,000 calls/hour with an 85% warm-hit rate (cache miss on the cold path, cache read on the warm path):
$36/hour to $9.81/hour is the kind of delta that makes prompt-prefix caching the first optimization most teams reach for on long-running agent workloads. The mechanic follows prompt caching's core economic principle: stable context should be reused rather than reprocessed on every request — the gateway makes it operationally trivial to enforce. The cache-read and cache-write tokens land in the same per-call usage that TrueFoundry's gateway already attributes for cost, so the discount above is something you can confirm against your own traffic in the cost-attribution view from the previous post, not just a back-of-envelope estimate.
Compaction adds latency; cache reads do not. The asymmetry shapes the production heuristics.
A standalone call to /v1/responses/compact is a synchronous round-trip — it has to read the entire input, run a provider-side compaction operation with its own latency and cost characteristics, and return the compacted window. For a 150K-token input, that can add noticeable latency; measure it on your own traces before choosing thresholds. The agent stalls during that time.
Server-side compaction is better but not free. The compaction pass happens in-stream during the next /responses call, so TTFT for that call includes both the compaction overhead and the normal inference time. If compaction triggers at every threshold crossing on a busy agent, user-visible TTFT becomes bimodal: most turns are fast, a few are noticeably slow. Because TrueFoundry's gateway records each call's latency on the session trace, that bimodal pattern is visible directly in the request-traces view — the slow turns are the ones carrying the compaction overhead, which is what lets you tune the threshold against real numbers instead of guessing.
Two heuristics that matter in production:
Compact proactively, not reactively. If compaction triggers only at the actual context limit, the agent has already spent its last several turns in the elevated-risk zone where quality tends to slip. Set the threshold well below the limit — typically 75% — so the agent spends less time there. For a 200K-context model, that is a 150K threshold.
Don't compact short conversations. For a 5-turn task that tops out at 30K tokens, compaction overhead exceeds the benefit — the round-trip cost is real even if the inference is small. A reasonable floor: never compact below ~75K tokens or before turn 10, whichever comes first. Below that, even the worst-case full-context pass is cheaper than a compaction round-trip.
A practical default for a production agent platform: compact_threshold at 75% of model context limit, with a minimum-size guard at ~75K tokens, applied via server-side compaction with stateless chaining.
Compaction is also only one tool among several, and not always the right one. The choice depends on the shape of the task:
These compose rather than compete — a production agent often caches its system prompt, retrieves from a corpus, writes notes to disk, and compacts the residual conversation. The gateway's role is the same across all of them: make each one observable and attributable, not to pick one for the agent.
The connection between the context engineering principles and the concrete gateway primitives is direct:
The gateway does not make context engineering decisions. It makes them implementable, debuggable, and uniform across the providers the agent talks to — which is what an AI gateway like TrueFoundry's is for: one place where session grouping, token-budget visibility, and cost attribution apply identically whether the agent is talking to OpenAI or Anthropic.
Do we need to use the Responses API to get compaction?
For the API-native server-side version, yes. Chat Completions has no first-class compaction primitive — applications have to roll their own (typically: summarize the prior conversation with a separate model call and pass the summary forward). The Responses API ships compaction as an explicit operation with the opaque compaction-item semantics that make it ZDR-safe.
How does compaction interact with prompt caching?
If the static system/developer/tool prefix stays byte-identical and sits before the compacted history, compaction should not disturb cache hits on that prefix — cache hits require an exact prefix match, so the unchanged head of the prompt still matches. What changes is the cacheability of the conversation-history portion: subsequent requests have to warm a new cache entry against the post-compaction prefix. This is one practical reason to compact infrequently rather than every few turns — each compaction event invalidates the conversation-portion cache, even though the larger system-prompt portion is untouched.
Can the gateway compact across multiple providers?
No. Compaction is provider-side and the compaction item is opaque and provider-specific — you cannot compact with OpenAI and resume with Anthropic. The gateway can route compaction calls and surface the resulting items in its session view, but continuation has to stay with the same provider.
What if the agent uses sub-agents instead of compaction?
Sub-agents are a valid alternative — fresh context per sub-task means each one never grows beyond its own subproblem, and the orchestrator synthesizes outputs at the end. Sub-agents work when subproblems are clearly decomposable; compaction works when the agent needs continuity across many turns of one connected task. The two are not exclusive.
How do session token counts square with the OTel spans we already capture?
One trace per provider call, one session per conversation. The session is a roll-up over the conversation's traces; it surfaces cumulative token counts, latency profile, and cache hit rates across all turns.
Where does TrueFoundry fit?
The pattern in this post is gateway-agnostic: a gateway is the natural place to expose session grouping, per-turn token-budget visibility, cache-hit attribution, and the routing of provider compaction calls, because it already sits on every request. The TrueFoundry AI Gateway provides the session and observability layer those build on — centralized tracing, metadata tagging, and the per-trace cost attribution and budget enforcement covered in earlier posts, rolled up to the conversation level. Compaction and caching themselves are the provider's features; the gateway's contribution is to route them, attribute their token and cost effects, and make a long agent run queryable as one timeline. (The specific header name X-TFY-CONVERSATION-ID is used here as an illustrative convention; treat the exact primitives as ones a gateway can expose rather than a fixed contract.) The agent platform decides the context strategy; the gateway gives it the visibility and the controls.
If you operate a long-running agent in production today, the highest-leverage move is enabling prefix caching on the system prompt. For OpenAI that is automatic and requires no code changes; for Anthropic, add cache_control breakpoints around the stable prefix and validate the write/read economics on your workload, since cache writes carry their own pricing tier. In both cases it typically pays back the platform investment within weeks. Compaction is the second move, once the agent regularly exceeds 60–70% of the model's context limit. Session tracking is the move that makes both of the above debuggable.
Northwind, Maya, and PR #4127 are illustrative. The compaction and prompt-caching examples reflect the documented OpenAI Responses API and Anthropic API behavior as of May 2026. Token accumulation, thresholds, latency, and cache-hit rates are representative workload assumptions, not measurements — measure them against your own agent traces before setting production policy. Provider pricing and context limits cited are per the providers' public rate cards and model pages at that date.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
.webp)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)








