

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
AWS Bedrock actúa como una capa gestionada para acceder a los modelos básicos dentro de los límites de las VPC de AWS. Para los equipos de ingeniería, elimina la sobrecarga operativa que supone el aprovisionamiento de instancias de GPU o la administración de clústeres de Kubernetes con fines de inferencia. El servicio ofrece acceso inmediato a modelos como Claude 3.5 Sonnet, Llama 3 y Amazon Titan a través de una API unificada.
Sin embargo, Precios de AWS Bedrock no es una tarifa plana. Funciona como un menú complejo en el que el coste final depende de las variaciones del modelo, la distribución de los tokens, las capacidades de tráfico regional y la sobrecarga operativa de servicios de soporte como CloudWatch y OpenSearch. Este informe analiza la economía unitaria de AWS Bedrock, identifica los puntos en los que los costos aumentan a gran escala y analiza las ventajas arquitectónicas entre la inferencia gestionada y las alternativas autohospedadas que utilizan plataformas como TrueFoundry.
Antes de examinar los costos detallados, es importante comprender el modelo general de precios de AWS Bedrock. AWS Bedrock sigue una política pura enfoque de precios basado en el uso sin tarifas iniciales de plataforma ni de suscripción.
No pagas para activar el servicio. En su lugar, se te factura principalmente por la inferencia del modelo, medida a través de tokens o resultados generados. Sin embargo, el precio por unidad varía considerablemente según el proveedor del modelo base; un modelo antrópico cuesta mucho más que un modelo Meta o Mistral, incluso si el recuento de fichas es idéntico.
Los precios de AWS Bedrock se basan en la forma en que los modelos consumen los recursos durante la inferencia. Si bien la mayoría de los modelos de texto facturan por token, los modelos multimodales son diferentes.
Debes distinguir entre Tokens de entrada y Tokens de salida. Los tokens de entrada consisten en la carga útil inmediata, que incluye las instrucciones del sistema, las consultas de los usuarios y, lo que es más importante, el contexto recuperado de las canalizaciones de RAG. Los tokens de salida son la respuesta generada.
La realidad operativa dicta que los tokens de salida son significativamente más caros porque el costo computacional de generación (predicción del próximo token) es mayor que el del procesamiento del contexto de entrada. Por ejemplo, con Claude Sonnet 4.5 en us-east-1, tú pagas 3,00 USD por millón de fichas de entrada pero 15,00$ por millón de fichas de salida—un multiplicador de 5 veces. En los modelos multimodales, como Amazon Titan Image Generator, la facturación pasa a ser por imagen, calculada en función de la resolución y el recuento de pasos.
Figura 1: El efecto multiplicador de costos
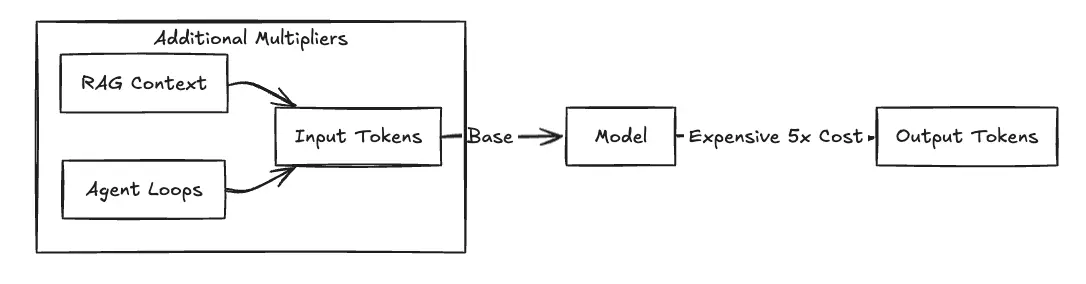
Los precios de AWS Bedrock no se limitan a «pagar por token». Los equipos deben elegir entre dos modelos de precios que cambian la flexibilidad por una capacidad garantizada.
Figura 2: Descomposición de la factura total
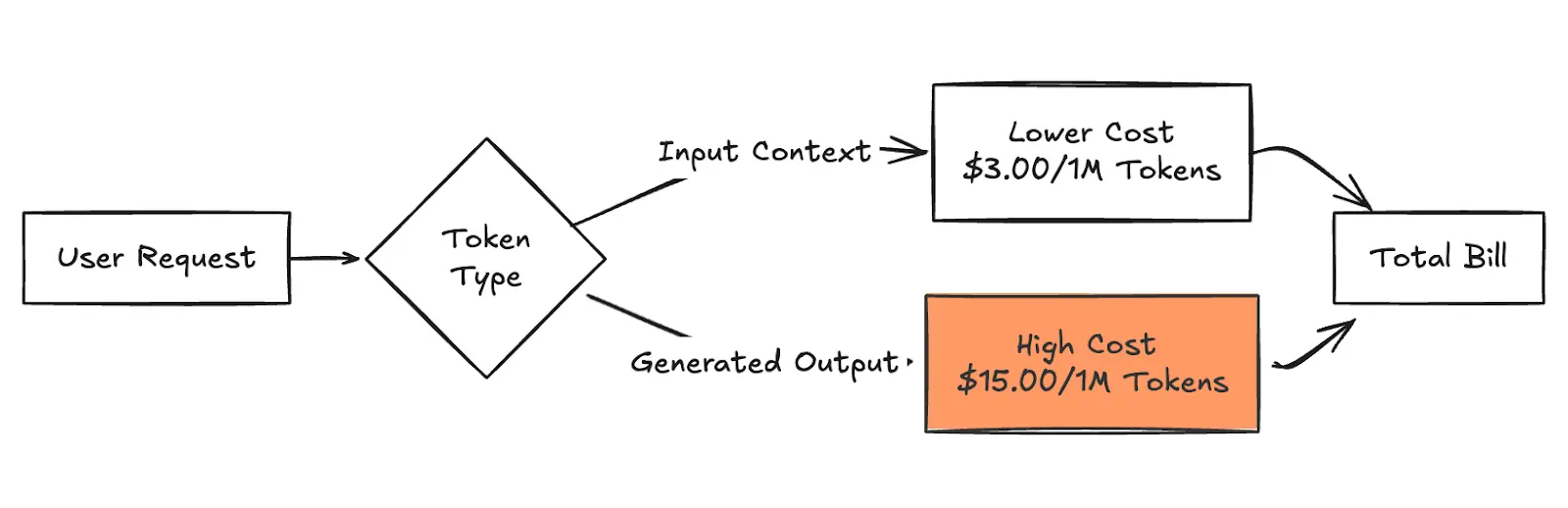
Los precios reflejan las tarifas de AWS Bedrock On-Demand para Soneto antropico de Claude 3.5 en el Estados Unidos Oriente-1 región a partir de enero de 2026. Los precios pueden variar según la región o la versión del modelo.
Los precios bajo demanda son la opción predeterminada para la mayoría de los usuarios de AWS Bedrock. Ofrece flexibilidad, pero conlleva riesgos operativos. Se le cobrará estrictamente por cada 1000 fichas procesadas, lo que resulta perfecto para patrones de tráfico variables o para experimentos iniciales en los que los patrones de uso son «a rabiar». Sin embargo, la desventaja es la fiabilidad. AWS impone límites de limitación, lo que significa que durante los picos de demanda, es posible que sus solicitudes sufran limitaciones.
Los precios de Provisioned Throughput están diseñados para los equipos que necesitan garantizar la disponibilidad del modelo a escala. Introduce la previsibilidad, pero requiere un compromiso financiero. En lugar de pagar por token, compras una unidad modelo dedicada para reservar la capacidad de inferencia y garantizar un nivel de precios de rendimiento específico.
El problema es que se te cobra una tarifa fija por hora, independientemente de si no envías ninguna solicitud o si llegas al máximo de la unidad. Este modelo funciona como una instancia reservada; por lo general, requiere un compromiso de 1 a 6 meses, lo que reduce la posibilidad de cambiar de modelo rápidamente si se lanza uno mejor la semana que viene.
A diferencia de OpenAI, donde se paga a un solo proveedor, Bedrock es un mercado. Las estrategias de precios varían según el proveedor.
Los modelos Amazon Titan son modelos básicos nativos de AWS diseñados para cargas de trabajo de IA de uso general. Como son modelos propios, suelen tener un precio inferior al de las alternativas de terceros. Esto los hace idóneos para aplicaciones de producción en las que los costes son sensibles, como la generación integrada o la clasificación simple, en los que el objetivo es un rendimiento «suficientemente bueno» a un precio bajo.
AWS Bedrock también proporciona acceso a modelos de proveedores externos como Anthropic, Cohere y AI21 Labs. Los precios aquí son generalmente más altos debido a las capacidades avanzadas y a las licencias externas involucradas. Tenga en cuenta que los modelos de alta capacidad de razonamiento, como el Claude 4.5 Sonnet, en los que los tokens de salida son significativamente más caros. En este caso, los costes pueden aumentar rápidamente en el caso de las aplicaciones con uso intensivo de chats, en las que el modelo «reflexiona» o genera respuestas largas y detalladas.
El diseño de su aplicación afecta a su factura tanto como el precio del modelo.
El precio base del token es a menudo solo la punta del iceberg. Las aplicaciones de IA del mundo real utilizan «bases de conocimiento» y «agentes», que tienen sus propios medidores independientes.
Figura 3: La pila de costos adicionales
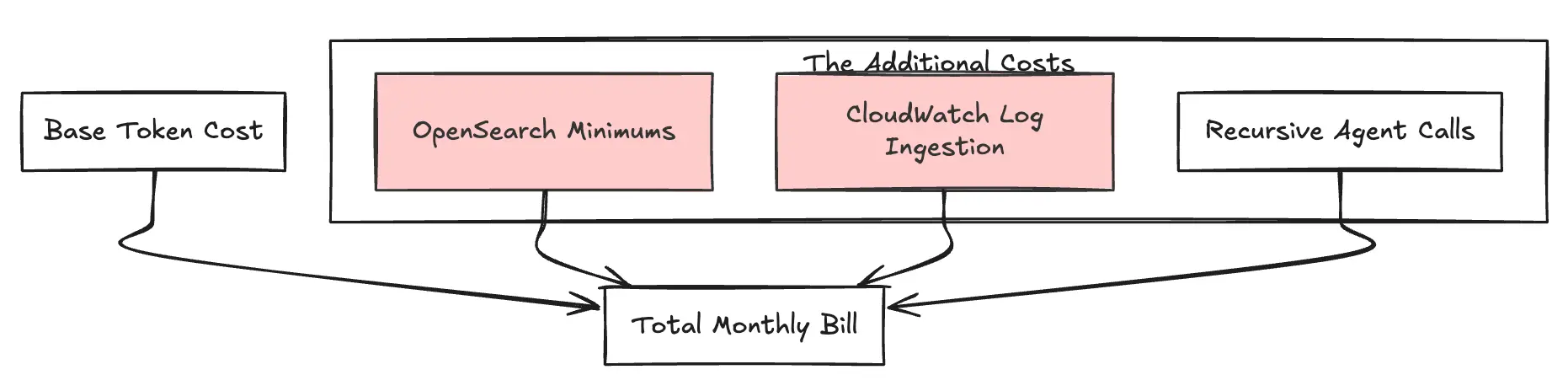
Las bases de conocimiento de Bedrock resumen la cartera de RAG, pero aprovisionan la infraestructura en segundo plano. Por lo general, esto hace que surja un OpenSearch sin servidor tienda de vectores. Los equipos de ingeniería suelen pasar por alto el coste mínimo: OpenSearch Serverless requiere un mínimo de 2 OCU (OpenSearch Compute Units) para garantizar la redundancia en la producción. En ~0,24 USD por OCU/hora (en us-east-1), esto resulta en un costo de referencia de aproximadamente 350 USD al mes (para una configuración redundante estándar) para que el índice exista, incluso sin tráfico de consultas.
Los «agentes» realizan varios pasos para responder a la consulta de un usuario (Pensar → Buscar → Resumir). El impacto es que una sola pregunta de usuario puede generar 10 veces más fichas lo que esperabas debido a este bucle interno y a este rastro de razonamiento. Pagas por la entrada y la salida de cada pensamiento intermedio, lo que crea un efecto multiplicador en tu factura.
La auditabilidad es obligatoria para la IA empresarial, pero la integración de Bedrock con CloudWatch Logs es exhaustiva. Registra todas las cargas útiles de avisos y respuestas. La ingestión de CloudWatch en regiones como US-east-1 cuesta 0,50 USD por GB, y el almacenamiento añade otro 0,03 USD por GB. Las aplicaciones de generación de textos de gran volumen pueden generar fácilmente cientos de gigabytes de datos de registro, lo que aumenta considerablemente la factura mensual de forma silenciosa.
Muchos equipos subestiman los precios de AWS Bedrock durante los primeros experimentos porque las variables son difíciles de aislar. El uso de los tokens varía mucho en función del comportamiento de los usuarios; un usuario puede hacer una pregunta sencilla mientras que otro pega un PDF de 50 páginas para resumirlo. Además, a los desarrolladores les encanta experimentar y, al cambiar de Claude Haiku a Claude Sonnet, cambias tu nivel de precios al instante, a menudo sin que Finanzas se dé cuenta hasta final de mes. Por último, los presupuestos de AWS se basan en las cuentas, por lo que resulta muy difícil saber cuánto gastó el bot de marketing en comparación con el de ingeniería. sin estrategias de etiquetado complejas.
A pesar de su complejidad, los precios de AWS Bedrock funcionan bien en ciertos escenarios. Si ya está estandarizado en AWS, el impuesto de «integración nativa» vale la pena por los beneficios de seguridad y cumplimiento, como IAM y PrivateLink. Para las aplicaciones con picos de tráfico que se utilizan con poca frecuencia o de forma imprevisible, el modelo bajo demanda es perfecto, ya que no se paga nada cuando la aplicación está inactiva. Permite que los proyectos en fase inicial se lancen rápidamente sin tener que gestionar las GPU o los clústeres de Kubernetes, lo que permite validar la adecuación del producto al mercado antes de optimizar los costes.
A medida que las cargas de trabajo de IA maduran, los equipos suelen encontrar limitaciones estructurales. En el caso de grandes volúmenes (millones de solicitudes), el margen de beneficio por token resulta más caro en comparación con el hecho de ser propietario del procesamiento. El perfeccionamiento de Bedrock a menudo requiere una compra Rendimiento aprovisionado, lo que aumenta drásticamente la barrera de entrada en comparación con el ajuste fino del Llama 3 en tu propia GPU. Además, los entornos en los que hay varios equipos no aplican con precisión el presupuesto por parte de las aplicaciones, lo que lleva a que se recurra al uso del término «tragedia de los bienes comunes», en el que un equipo agota el presupuesto compartido.
TrueFoundry ofrece un patrón arquitectónico alternativo para los equipos que están llegando al límite de la economía unitaria de Bedrock. En lugar de alquilar la API modelo con un marcado, TrueFoundry organiza la implementación de modelos de código abierto (Llama 3, Mistral, Qwen) directamente en sus propios clústeres de AWS EC2 o EKS.
Esto desbloquea la capacidad de utilizar Instancias puntuales de AWS. Al ejecutar la capacidad de inferencia in situ (computación de AWS de repuesto disponible con grandes descuentos), puede reducir los costos brutos de inferencia de la siguiente manera 60-70% en comparación con las tarifas de On-Demand Bedrock. TrueFoundry gestiona el riesgo operativo de las interrupciones puntuales automatizando el recurso a las instancias bajo demanda si se recupera la capacidad puntual, lo que garantiza la fiabilidad sin tener que recurrir al rendimiento aprovisionado durante 6 meses.
Esta es una comparación fáctica que se centra en la economía de los modelos de servicio.
A medida que crece la adopción de la IA, la claridad de los precios se vuelve fundamental para una escalabilidad sostenible. Los precios de AWS Bedrock no deberían tener que elegir entre la innovación y la quiebra.
TrueFoundry le permite controlar su gasto en IA, ya que ofrece una visibilidad granular de cada modelo y la flexibilidad necesaria para ejecutar cargas de trabajo en la infraestructura más rentable disponible, ya sea la API de Bedrock o una instancia puntual en su VPC.
Reserva una demostración gratuita ahora para obtener más información sobre cómo TrueFoundry puede ayudar a sus operaciones.
Los precios de AWS Bedrock varían según el modelo básico y el uso de los tokens. Si bien se puede acceder a la inferencia de modelos de bajo volumen, la inferencia de modelos a gran escala resulta costosa debido a los márgenes de beneficio de los servicios gestionados. TrueFoundry permite una mejor optimización de los costos al ejecutar modelos en instancias puntuales de AWS, lo que reduce significativamente el costo mensual total en comparación con las tarifas de Bedrock.
Sí, el costo de AWS Bedrock sigue un modelo de precios de pago por uso. Se le facturará por cada número de tokens procesados, tanto los de entrada como los de salida. En el caso de las aplicaciones de IA generativa intensivas, estas tarifas se acumulan rápidamente. TrueFoundry ofrece un enfoque más económico al utilizar velocidades de procesamiento sin procesar en su propia infraestructura.
Los precios de Amazon Bedrock no incluyen un modo gratuito permanente. Si bien una nueva cuenta de AWS puede ofrecer créditos generales, Bedrock cobra inmediatamente por la inferencia del modelo. TrueFoundry ayuda a minimizar los costos básicos al permitirle usar instancias puntuales más baratas para sus casos de uso específicos y trabajos por lotes.
No existe una capa gratuita dedicada para AWS Bedrock. Los usuarios pagan por todo el uso de la generación de texto e imágenes. Para evitar los impredecibles costes de AWS Bedrock, los equipos optan por TrueFoundry, que aprovecha el escalado automático y la inferencia por lotes para gestionar los gastos de IA generativa de forma más eficaz que el servicio gestionado.
TrueFoundry es un equivalente superior a este servicio totalmente gestionado. Le permite implementar cualquier modelo personalizado (como Mistral AI) o un modelo de Amazon Titan en su propia nube. A diferencia de Bedrock, simplifica la administración de costos mediante el uso de instancias puntuales y la automatización de datos, lo que evita la dependencia de un proveedor para la importación de modelos personalizados.
No existe una versión gratuita de Amazon Bedrock; hay que pagar para acceder a todos los modelos básicos. Para obtener un mejor valor a largo plazo, TrueFoundry le permite ejecutar modelos de código abierto con almacenamiento en caché y destilación de modelos rápidos en su propio hardware, lo que reduce drásticamente la barrera de entrada para la adopción de la IA generativa.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


