Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Benchmarking des TrueFoundry LLM Gateways: Es ist unglaublich schnell ⚡
TrueFoundry LLM Gateway bietet eine einheitliche OpenAI-kompatible Schnittstelle zu verschiedenen LLM-Anbietern wie Anthropic, OpenAI, Bedrock, Gemini und vielen anderen
TrueFoundry LLM Gateway lässt sich problemlos auf 350 RPS auf einem einzigen Replikat einer CPU-Einheit skalieren und nutzt dabei 270 MB Arbeitsspeicher. Wir haben einen Vergleich mit einem anderen Gateway-Produkt, LitelLM, mit einem ähnlichen Setup durchgeführt, und LiteLLM konnte nicht über 50 RPS skaliert werden
TrueFoundry LLM Gateway fügt nur eine zusätzliche Latenz von 3 bis 5 ms hinzu, während LiteLLM zwischen 15 und 30 ms pro Anfrage hinzufügt.
Warum benötigt Ihre Organisation ein LLM Gateway?
Ein LLM Gateway bietet eine einheitliche Oberfläche zur Verwaltung der LLM-Nutzung Ihres Unternehmens:
Vereinheitlichte API: Greifen Sie über einen einzigen auf mehrere LLM-Anbieter zu OpenAI-kompatibel Schnittstelle, keine Codeänderungen erforderlich
API-Schlüsselsicherheit: Sichere, zentrale Verwaltung von Anmeldeinformationen
Führung und Kontrolle: Legen Sie Grenzwerte, Zugriffskontrollen und Inhaltsfilterung fest
Ratenbegrenzung: Vermeiden Sie Missbrauch und sorgen Sie für eine faire Nutzung
Beobachtbarkeit: Verfolgen Sie Nutzung, Kosten, Latenz und Leistung
Kostenmanagement: Überwachen Sie die Ausgaben und richten Sie Budgetwarnungen ein
Prüfprotokolle: Alle LLM-Interaktionen zur Einhaltung der Vorschriften protokollieren
Wie schnell ist TrueFoundry LLM Gateway?
Test-Setup laden
Für unser Lasttest-Experiment haben wir ein bereitgestelltes eingerichtet gefälschter OpenAI-Endpunktdienst mit TrueFoundry. Der Dienst würde das OpenAI-Anfrage- und Antwortformat simulieren, ohne tatsächlich Token zu erzeugen.
Wir haben auch das TrueFoundry LLM Gateway und den LiteLM Proxy Server bereitgestellt, die beide auf einem einzigen Replikat mit einer CPU-Einheit und 1 GB Speicher laufen.
Wir haben unseren gefälschten OpenAI-Anbieter sowohl zu TrueFoundry- als auch zu LitelLM-Gateways hinzugefügt. Während des Lasttests haben wir auf drei verschiedene Arten Anfragen an den gefälschten OpenAI-Server gestellt:
Setup 1: Direkt ohne Verwendung eines Proxys oder Gateways
Setup 2: Über das TrueFoundry LLM Gateway, das auf einer CPU-Einheit und 1 GB Arbeitsspeicher bereitgestellt wird
Setup 3: Über den LitelM Proxy Server, der auf einer CPU-Einheit und 1 GB Arbeitsspeicher bereitgestellt wird
RPS
10 RPS
50 RPS
200 RPS
300 RPS
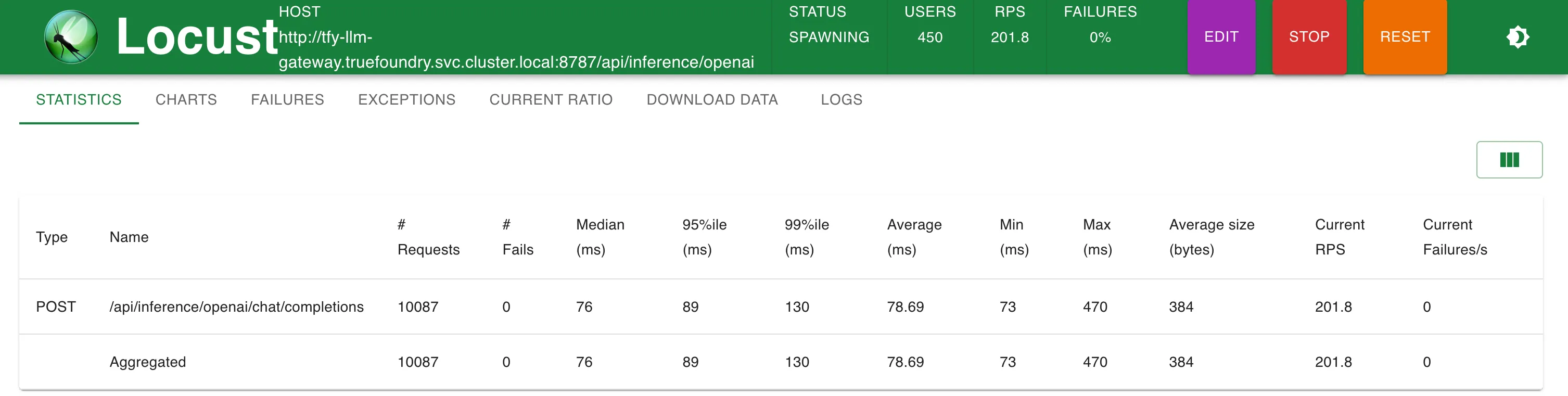
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
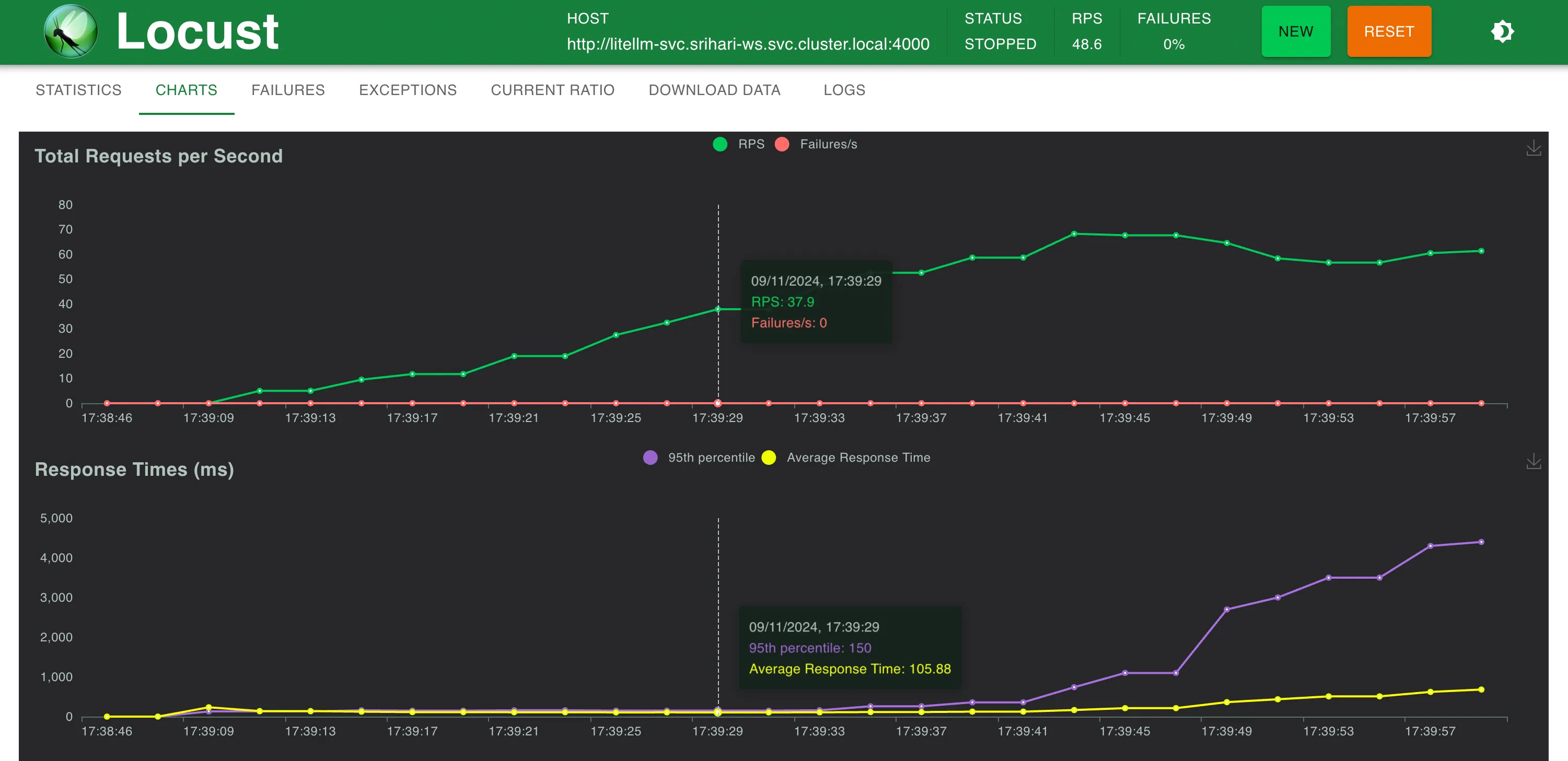
Could not scale to 200 RPS
Could not scale to 300 RPS
Beobachtungen
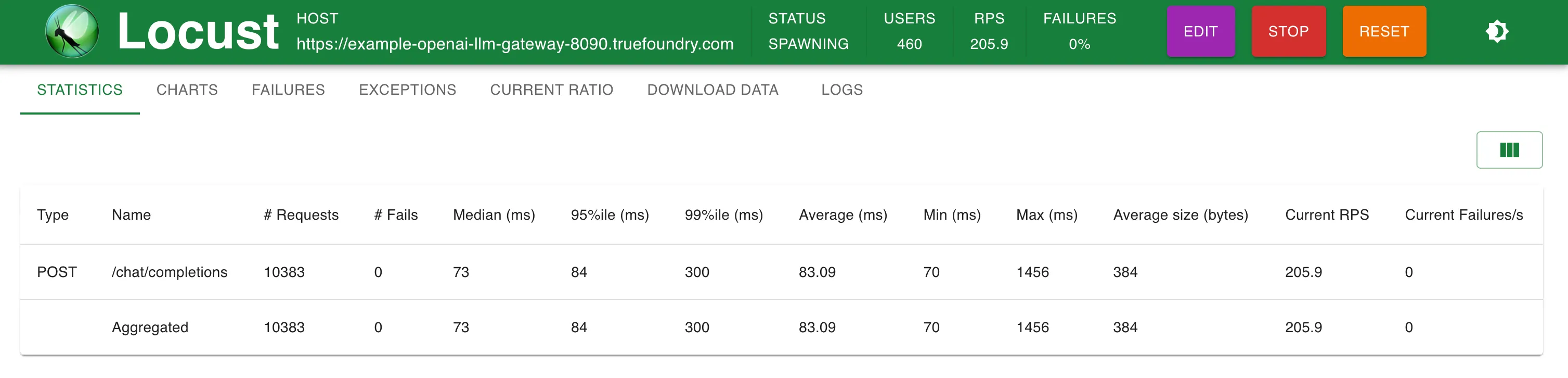
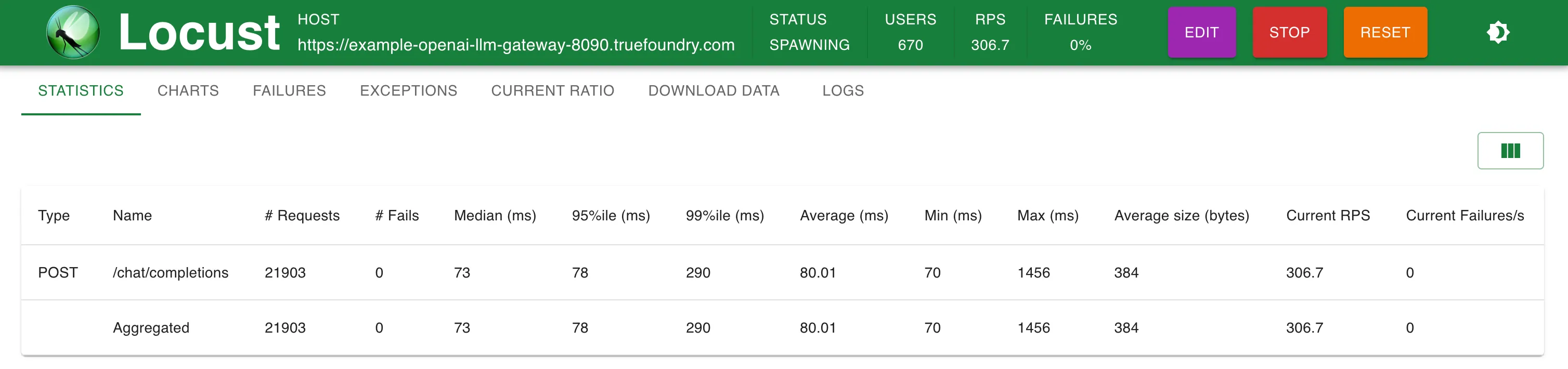
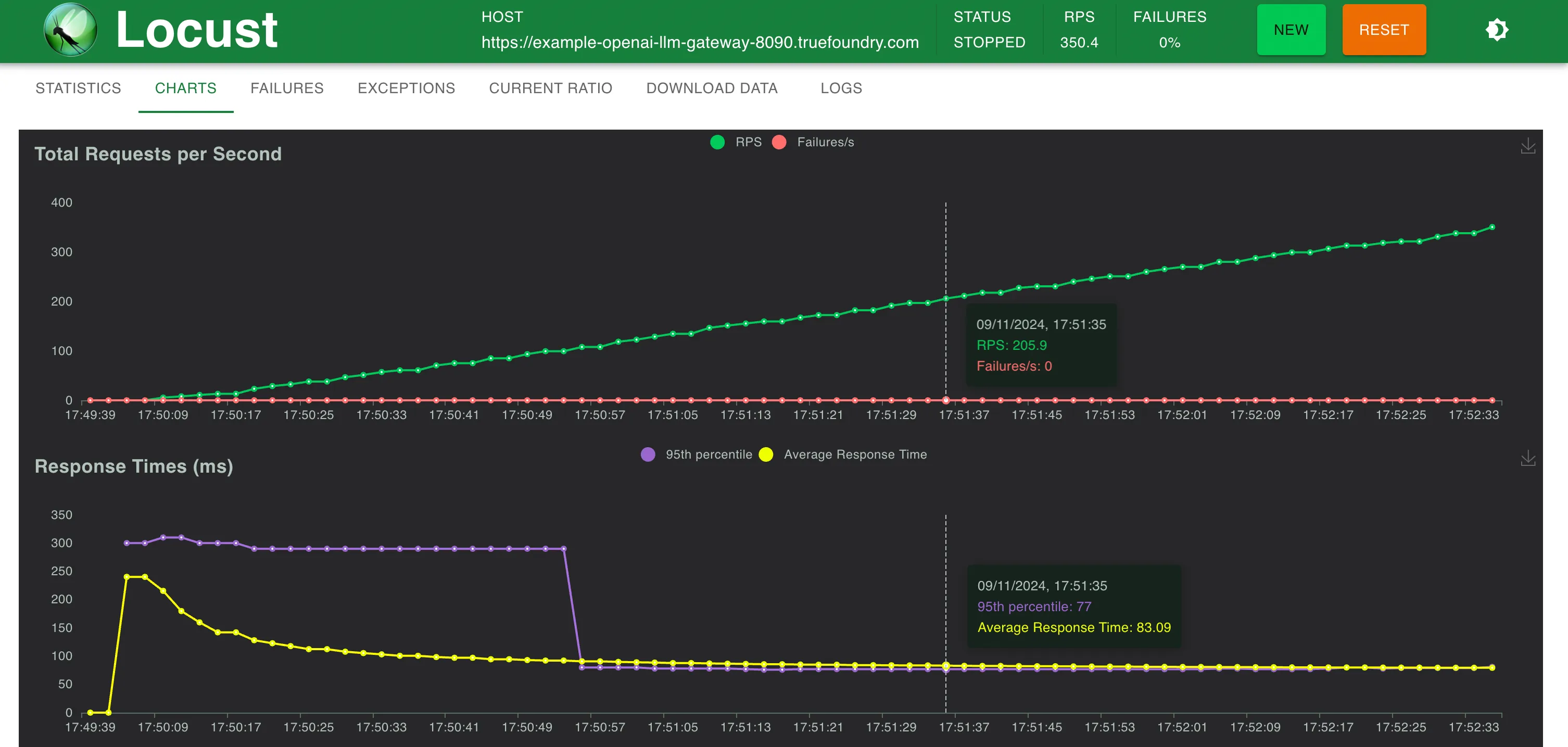
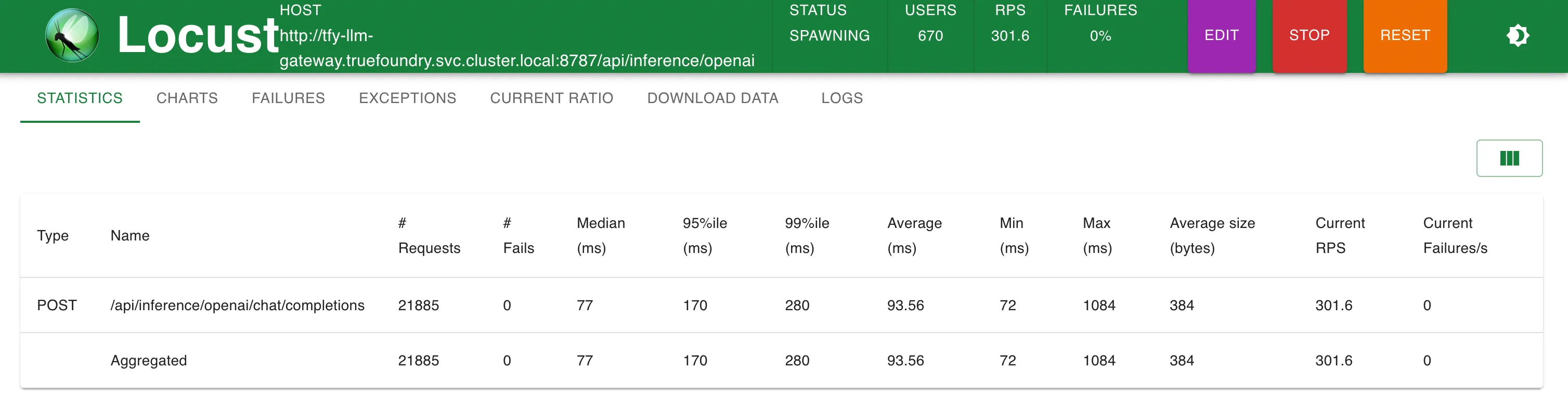
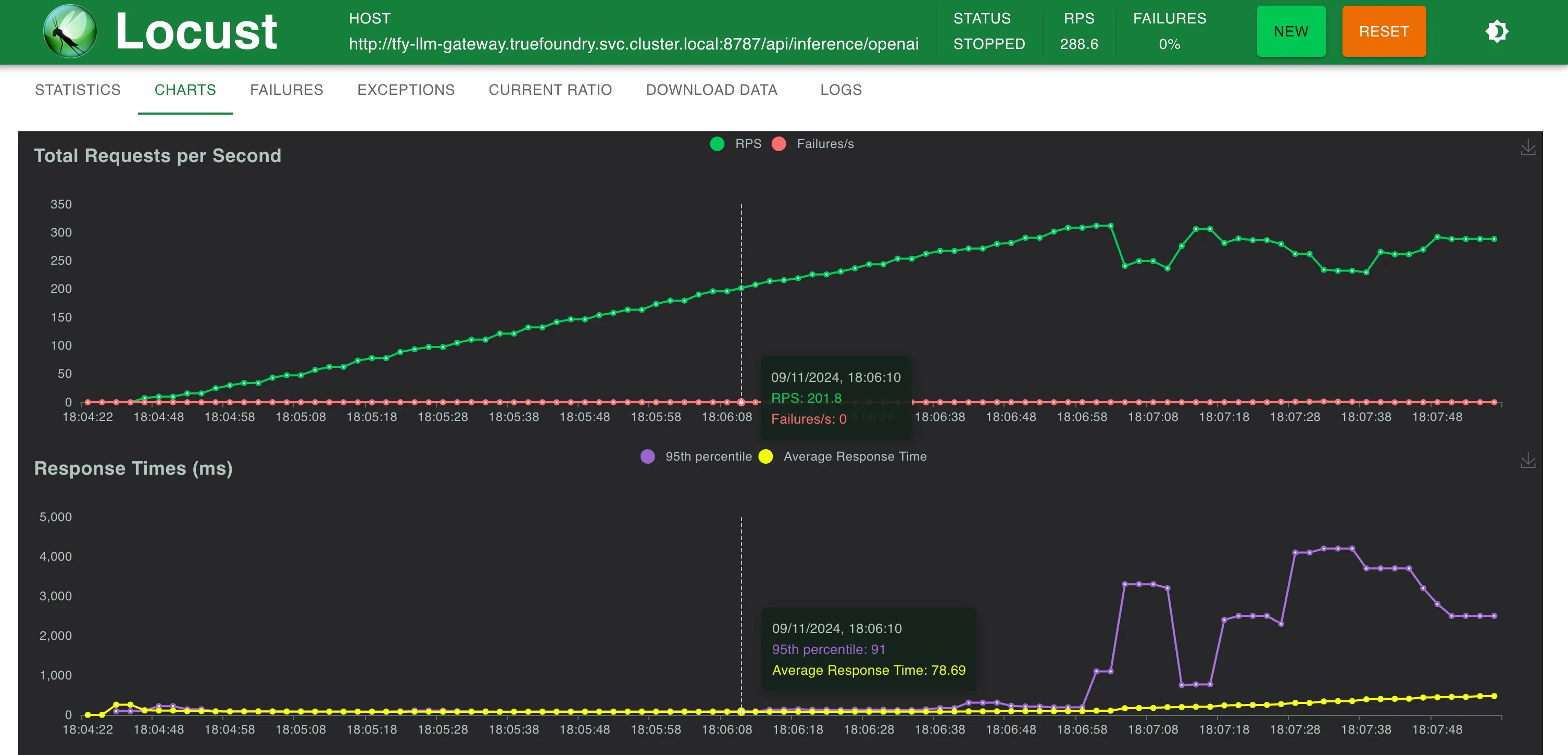
TrueFoundry Gateway fügt nur zusätzliche 3 ms Latenz hinzu, bis zu 250 RPS und 4 ms bei RPS > 300
TrueFoundry LLM Gateway konnte ohne Leistungseinbußen skalieren, bis etwa 350 RPS (1 vCPU, 1 GB-Maschine), bevor die CPU-Auslastung 100% erreichte und die Latenzen begannen beeinträchtigt zu werden. Mit mehr CPU oder mehr Replikaten kann das LLM Gateway auf Zehntausende von Anfragen pro Sekunde skaliert werden.
LiteLLM auf demselben Computer konnte nicht über 40-50 RPS skalieren, bevor das CPU-Limit erreicht wurde
Mehr Metriken
Setup 1: Direkter OpenAI-Endpunktaufruf
Statistiken bei 200 RPS
Statistiken bei 300 RPS
Reaktionszeit im Vergleich zu RPS
Einrichtung 2: TrueFoundry LLM Gateway
Statistiken bei 200 RPS
Statistiken bei 300 RPS
Reaktionszeit im Vergleich zu RPS
Einrichtung 3: LiteLLM
Statistiken @ ~58 RPS
Reaktionszeiten im Vergleich zu RPS
Geschwindigkeitsfunktionen von LLM Gateway
Nahezu kein Overhead: Nur 3—5 ms Latenz hinzugefügt
Optimiertes Backend: Mit dem performanten Node.js Framework gebaut
Zwischenspeichern von Konfigurationen: Die Konfiguration wird zum schnellen Nachschlagen im Speicher gespeichert
Bereit für Edge: Stellen Sie es in der Nähe Ihrer Apps bereit
hohe Kapazität: EIN t2.2x groß Der AWS-Instance-Computer (43$ pro Monat vor Ort) kann problemlos auf bis zu ~3000 RPS skaliert werden.
Edge-Bereitstellung von TrueFoundry LLM Gateway
Unterstützte Anbieter
Im Folgenden finden Sie eine umfassende Liste beliebter LLM-Anbieter, die von TrueFoundry LLM Gateway unterstützt werden:
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last




































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




