

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
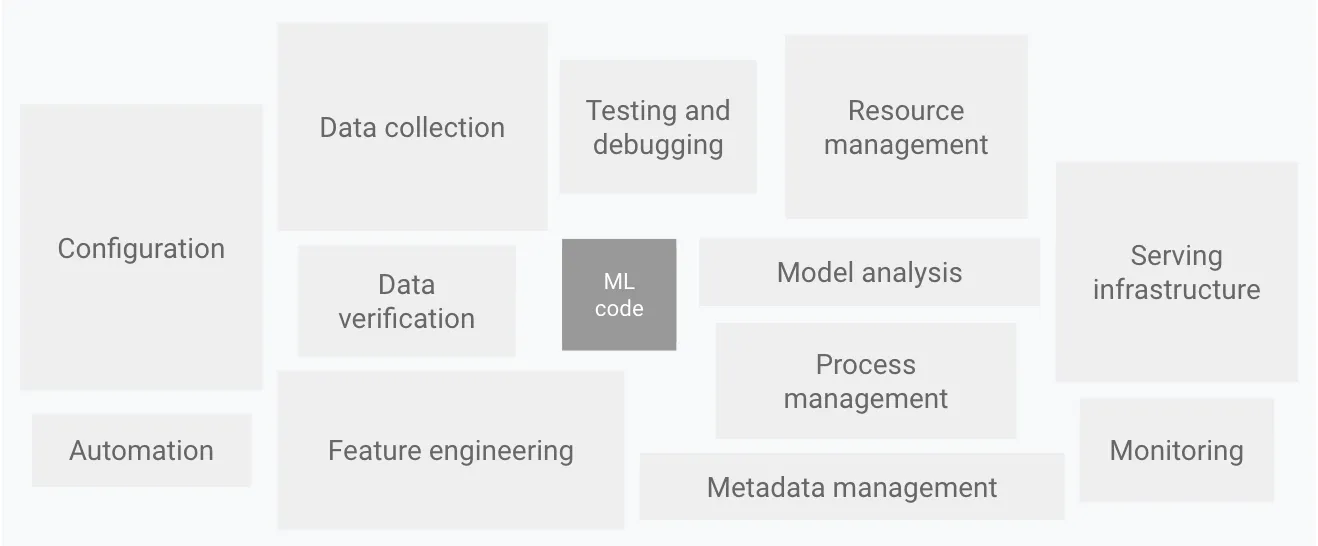
Das Truefoundry-Team hat im letzten Monat sehr hart daran gearbeitet, unserer ML Deployment-Plattform Funktionen hinzuzufügen. Unser Ziel ist es, eine Bereitstellungsplattform zu entwickeln, die es absolut einfach macht, ML-Modelle und -Dienste bereitzustellen und gleichzeitig die besten technischen und Sicherheitsprinzipien durchzusetzen. Um eine großartige ML-Plattform aufzubauen, benötigen wir eine solide Engineering-Plattform. Aus diesem Grund lag der Schwerpunkt zunächst hauptsächlich auf der Bereitstellung einer soliden Plattform für die Codebereitstellung.
Von allen oben beschriebenen Teilen der Ml-Plattform konzentrieren wir uns auf die Serverinfrastruktur, die Überwachung und die gesamte Automatisierung, die damit verbunden ist.
Es wurde viel Arbeit in den Aufbau unserer Bereitstellungsplattform auf Kubernetes gesteckt. Das Ziel dabei war es, die Bereitstellung in weniger als 5 Minuten absolut einfach zu machen, wobei die Plattform sich darum kümmert, das Image aus dem Quellcode zu erstellen, es in einer Docker-Registry zu speichern und dann die Anwendung schließlich auf Kubernetes bereitzustellen. Einige der Updates aus unserem letzten Monat beinhalten Folgendes:
Modelle für maschinelles Lernen können je nach Instanztyp eine sehr unterschiedliche Inferenzlatenz oder Leistung aufweisen. Als wir beispielsweise die Inferenzlatenz eines Modells mit umarmtem Gesicht auf Intel- und AMD-Prozessoren testeten, stellten wir fest, dass Intel-Prozessoren etwa 30% schneller sind. Aus diesem Grund haben wir jetzt eine Option, mit der Benutzer bei der Bereitstellung ihrer Workloads den Instance-Typ wählen können. Wenn der Instanztyp nicht ausgewählt ist, kann der Workload auf jedem verfügbaren Instanztyp bereitgestellt werden.

Wir hatten zuvor einen Grafana-Link zum Anzeigen von Protokollen und Metriken. Grafana war zwar hochgradig anpassbar, aber Berechtigungen und Zugriffskontrolle waren auf Grafana nicht wirklich möglich. Außerdem stellte sich heraus, dass es für Benutzer, die nicht an Grafana gewöhnt waren, etwas langsam und schwer zu verstehen war. Aus diesem Grund haben wir unsere eigene Benutzeroberfläche für die Anzeige von Protokollen und Metriken implementiert, was in den meisten Fällen ausreichen sollte. Wir bieten weiterhin die Grafana-Integration in der Public Cloud für fortgeschrittenere Benutzer an.

Wir können jetzt Benutzer als Editor, Viewer oder Admin zu geheimen Gruppen hinzufügen.

Wir können jetzt von jedem Github- oder Bitbucket-Repositorys aus direkt auf Truefoundry bereitstellen. Benutzer können mithilfe des OAuth Flow eine Integration in ihre eigenen privaten Repositorys vornehmen und die entsprechenden Parameter für die Bereitstellung der Anwendung auswählen.
Im nächsten Monat arbeiten wir an einigen aufregenden Funktionen wie:
Bleiben Sie dran und teilen Sie uns Ihr Feedback mit!
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




