

July 31, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 4, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
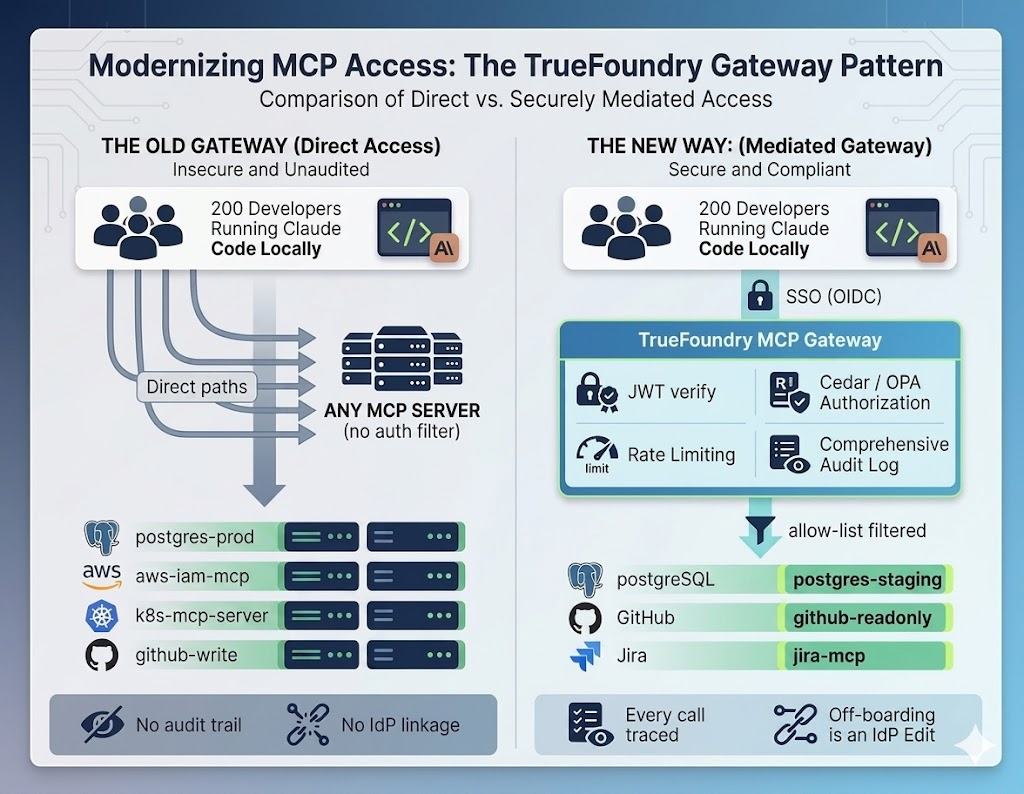
Claude Code is a productivity multiplier and a governance gap in the same install. With 200 developers and no central control point, any of them can reach any backend their agent decides to use. The gateway is where that gap closes.
Claude Code is a substantial productivity gain. It reads codebases, runs tests, queries databases, and resolves multi-step engineering tasks autonomously. The capability is exactly what makes the security model uncomfortable. The agent is not a remote service that occasionally takes a turn; it is an autonomous loop that runs on a developer's laptop with whatever credentials are reachable from that laptop.
Natively, Claude Code has no concept of enterprise governance. Hand it an MCP server configuration and it assumes total authority over every tool that server exposes. Stand up a postgres-mcp-server so agents can query staging data, and there is no built-in mechanism to prevent an overconfident agent — or a compromised developer endpoint — from issuing DROP TABLE if the underlying credentials allow it. Local config files asking developers to behave responsibly are not the answer; they are the absence of one.
The right way to think about this: the human supervising the loop used to be the rate limiter, the policy engine, and the audit log all at once. The agent removes the human from the per-action path. Whatever guardrails that humans provided implicitly now have to be reconstructed explicitly — and the only place to put them is upstream of the agent, on the network, where one team can own them.
The threat model is over-broad reachability combined with agentic unpredictability. Three failure modes show up in production within the first month of any non-trivial Claude Code rollout.
Goal-directed over-reach. A developer connects Claude Code to the internal network to debug “the bug in the user authentication flow.” The agent, reasoning through the problem, decides it needs to see real user data to reproduce the bug. It picks up a kubernetes-mcp-server, port-forwards into a production database, extracts PII, and pastes a summary into the local terminal — or sends it to the provider as part of the next prompt. This is not malicious behavior. It is an agent fulfilling its objective using the most permissive tool available.
Accidental destruction. The agent attempts to fix a Terraform module by applying it. It attempts to clean a misconfigured branch by deleting it. It runs a database migration to verify the new schema works. Each individual step looks locally rational; the global outcome is a production incident.
SSRF through the agent. The agent picks up a network tool to verify an integration. The agent reads a poisoned tool description that suggests a particular host is canonical. The agent fetches that host, which happens to be inside the cloud metadata service. Credentials leak. The user is unaware any of this happened — the agent simply reported success on its task.
Without a centralized control point, every one of these is possible by default. With one, every one of them is a configuration decision.
The mitigation is to deploy a gateway between Claude Code and internal MCP servers, and run default-deny tool scoping based on identity. Policy is expressed declaratively, not buried in code, and reviewed in pull requests like any other piece of infrastructure:
Cedar · TrueFoundry policy
// Frontend engineers can read staging databases.
// Nobody is granted production write access by default.
permit(
principal == Role::"frontend-developer",
action == Action::"mcp:invoke-tool",
resource == McpServer::"staging-database"
) when {
context.tool_name == "read_only_query" &&
context.environment == "staging"
};
Cedar (or OPA, or whichever policy engine your platform standardizes on) lets the org state plainly: frontend engineers reach frontend MCP tools, no agent has write access to production databases unless a time-bound break-glass procedure is invoked. The gateway inspects the JWT of the developer running Claude Code, cross-references the request against the policy, and blocks unauthorized calls at the network layer — long before the agent's reasoning reaches the database. Both Cedar Guardrails and OPA Guardrails ship in TrueFoundry as built-in MCP guardrails, with default-deny semantics enforced at the Pre Tool hook.
Table 1 — Cedar vs OPA. Both ship as built-in TrueFoundry guardrails with default-deny semantics. Cedar is the easier on-ramp; OPA is the more flexible long-term tool. Pick whichever your platform team will be willing to own.
The semantic that matters is when this check runs. TrueFoundry's MCP guardrails expose two hooks per tool call: Pre Tool runs synchronously before the tool executes, and Post Tool runs after it returns. Cedar/OPA decisions sit at the Pre Tool hook, which means a denied call never reaches the database, the cloud API, or the internal service. The agent's reasoning continues; the dangerous action does not.
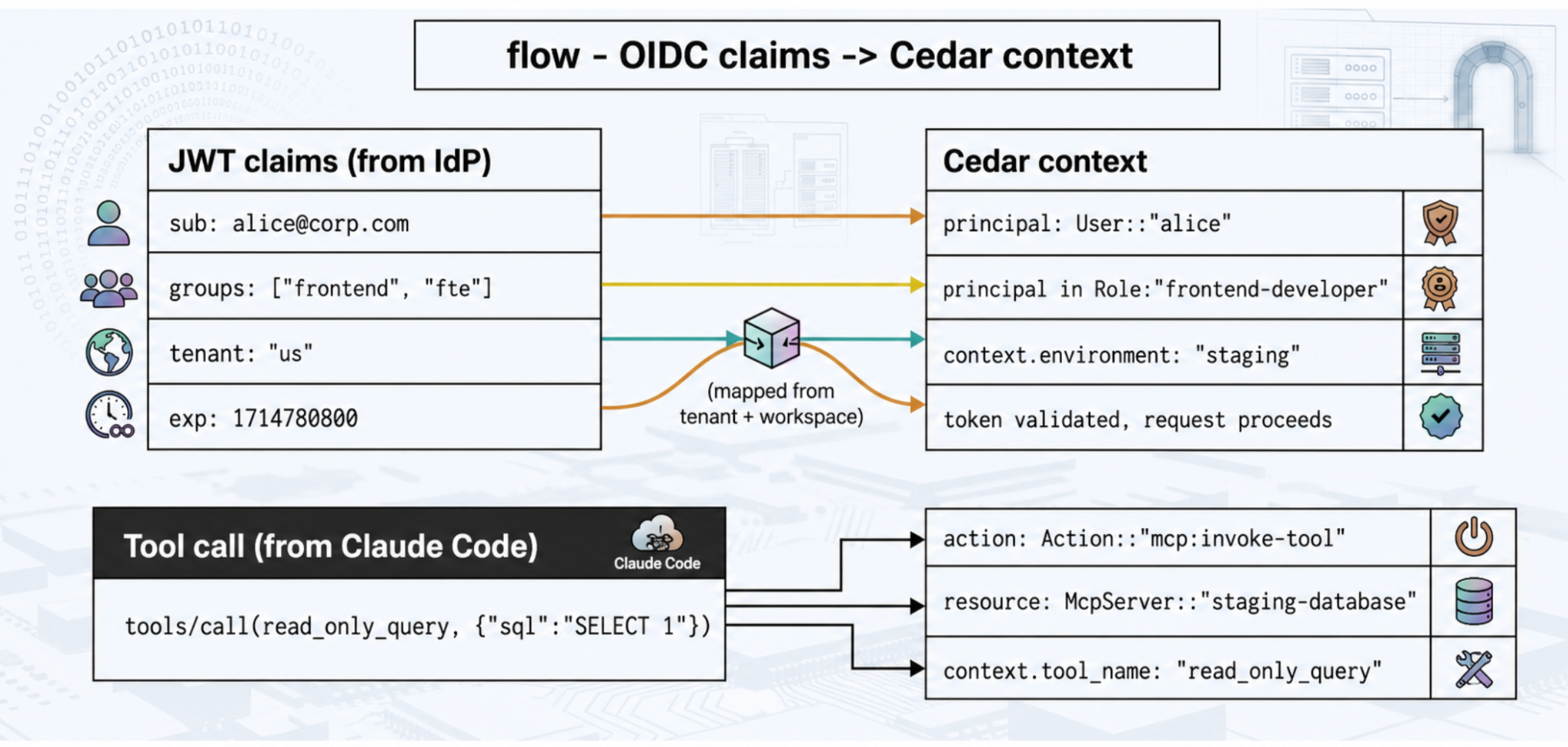
The bridge between identity and policy is straightforward. The developer authenticates against the corporate IdP (Okta, Azure AD), receives a JWT signed by the IdP, and presents it to the gateway on every request. The gateway verifies the signature against the IdP's cached public keys (no per-request callback to the IdP — the keys are downloaded once on startup and cached in process memory). The verified claims are then mapped into a Cedar context that the policy engine evaluates:
flow · OIDC claims → Cedar context
Agentic loops run away. A vague prompt can cause an agent to invoke a search tool hundreds of times in a tight loop, hammering internal APIs and burning tokens at a rate the human in front of the keyboard would never produce. Gateway rate limiting is essential — and it has to be applied at the right granularity.
Specifically, rate limits belong at the tool-call layer, not the prompt layer. A developer might send five prompts an hour. The agent might execute five thousand tool calls in service of those prompts. Limit by tool call. The TrueFoundry gateway uses a sliding-window token-bucket algorithm under the hood — a 60-second sliding window built from twelve 5-second buckets, all maintained in process memory on every gateway pod. Limits sync across replicas through NATS, and the algorithm holds steady up to the gateway's documented ~250 RPS per single-CPU pod.
The configuration model uses static rule IDs combined with rate_limit_applies_per to scope limits to entities. Rate limits are expressed in YAML, version-controlled, and reviewable like any other piece of policy:
YAML · per-developer + per-project limits
name: claude-code-rate-limits
type: gateway-rate-limiting-config
rules:
# Each developer gets their own per-day token budget.
- id: "user-daily-tokens"
when: {}
limit_to: 1_000_000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# Each user-model pair gets its own minute-window cap.
- id: "user-model-minute"
when: {}
limit_to: 200
unit: requests_per_minute
rate_limit_applies_per: ["user", "model"]
# Each project (via X-TFY-METADATA) gets its own hourly cap.
- id: "project-hourly-tokens"
when: {}
limit_to: 50_000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]
Three things are worth calling out about this configuration. First, rules are evaluated top-to-bottom and the first matching rule wins — ordering encodes priority. Second, rate_limit_applies_per replaces the older dynamic rule-ID format ({user}-daily-limit and so on); migration is mechanical but breaking, and worth doing once. Third, you can combine up to two entities per rule, so per-user-per-model and per-project-per-environment limits are both expressible without rule explosion.
When the bucket is exhausted, the gateway returns HTTP 429. Claude Code reads that as a standard backoff signal and naturally pauses the loop, instead of crashing the downstream database. The agent retries when the bucket refills, which is exactly the behavior you want.
When something goes wrong — a cost spike, a security incident, a regulator's question — platform teams need a forensic record. The gateway provides one, external to the developer's machine and impossible for the user to modify. This is the part of the architecture that turns “we think it was Bob's agent” into “it was Bob's agent at 14:32:05 UTC, here is the trace.”
A TrueFoundry log entry contains everything an analyst needs to reconstruct cause and effect:
Table 2 — Log fields for a forensic record. The trace ID is the field auditors actually care about — it is what allows an analyst to walk from “developer asked X” through “model decided Y” through “tool executed Z” in a single query.
Logs flow from the gateway into ClickHouse (with object-storage backing) and from there into whatever SIEM the org standardizes on. The gateway never writes synchronously to the log path — it publishes to NATS, and the log subsystem is async by design. If the log queue is down, the gateway does not fail the request. Reliability of the request path beats observability of the request path; observability is reconciled when the queue comes back.
Static rules cannot anticipate every threat, and human review of every line of audit log is not a scaling strategy. The audit stream is also a behavioral baseline. A developer who normally uses git-mcp and jira-mcp who suddenly starts hitting aws-iam-mcp fifty times a second is a signal — possibly a compromised laptop, possibly a misconfigured agent, definitely worth a look.
Platform teams configure circuit breakers on these patterns. Above a configurable z-score threshold, the gateway quarantines the developer's agentic access and pages the on-call security responder. The developer keeps working in their IDE; their agent loop sits idle until reviewed. Anomaly detection is downstream of the audit log, not the request path, so the latency cost in steady state is zero — anomaly evaluation runs on the aggregated metrics stream that the gateway already publishes.
The behaviors worth alerting on, ranked by how often they actually fire in real deployments, are: sudden spikes in invocation rate (loop-stuck agent), tool calls with parameter shapes the developer has never produced (compromised credentials), multi-second gaps followed by bursts (bot-like access patterns), and access to tools outside the developer's normal workgraph (lateral movement). The features driving the z-score are simple — invocations-per-minute, distinct-tools-per-hour, payload-size-distribution — and the math is plain rolling-window mean-and-stddev. Sophistication here mostly hurts; what matters is that the alert fires reliably and is easy to silence when it's a false positive.
The structural elegance of this architecture is that everything ties back to the corporate identity provider — Okta, Azure AD, whatever the org runs. Authentication is OAuth/SAML/OIDC; the gateway caches the IdP's public keys in process memory and verifies every incoming JWT locally without an external call. Authorization is policy evaluation against the OIDC claims, also in memory. There is no per-request callback to the IdP; the gateway is fast because all of these checks happen in the pod's RAM, not over the network.
When a developer changes teams, their group memberships change in the IdP. Because the gateway evaluates policies dynamically against fresh OIDC claims, the developer's Claude Code loses access to sensitive MCP servers immediately, with zero local config edits. Off-boarding becomes a single IdP change. Role changes, team transfers, and contractor terminations propagate the same way. The gateway is the seam where corporate identity meets the agent loop, and that seam is where governance becomes operationally tractable instead of permanently aspirational.
Claude Code is going to ship in your enterprise — if not this quarter, next. The question is whether it ships through a seam your platform team controls, or through a thousand individual config files your platform team does not. There is only one of those answers that survives an audit.
Standing access to production is the wrong default; time-bound elevation is the right one. The pattern that works in production: a separate Cedar/OPA rule that grants a senior engineer a 30-minute elevated role when they file a justified request through an approval workflow (a Slack bot, a PagerDuty incident, a JIRA ticket). The elevation is itself logged through the gateway, the role expires automatically, and the audit log captures both the request and the actions taken under it. The gateway has no special break-glass code — it is the same JWT-claim-to-Cedar-context flow, just with a different role and an expiration time the IdP enforces.
The gateway returns a structured 403 with the rule ID that denied the call. That rule ID is the address of a conversation: it points to the Cedar/OPA file in the platform repo, which is reviewable in a normal pull request. If the policy is wrong, the fix is a PR. If the policy is right, the developer has the receipt they need to ask for an exception through a separate channel. There is no developer-side override switch by design — that switch is exactly what the gateway is supposed to remove.
Claude Code's local permission prompts are useful as user experience but are not a security boundary — they live on the developer's machine and can be disabled or auto-accepted. The gateway sits below those prompts and gates the actual tool invocation. The two layers compose: prompts give the developer a sanity check; the gateway gives the org a policy. Treat the prompts as defense-in-depth, not the load-bearing layer.
Policies should mirror the IdP group structure rather than enumerate every (user, tool) pair. Group developers into roles in the IdP — frontend-developer, backend-developer, sre, contractor — and write policies against those roles. New hires inherit access on day one through their group membership; off-boarding is one IdP edit. The number of policy rules should grow with the number of MCP-server / tool categories, not with the number of developers.
It is in the request path, so engineering it for high availability is not optional. The gateway plane is stateless, runs as multiple replicas, and continues serving on last-known config if the control plane is briefly unreachable. New configuration is reconciled through NATS and re-published in full every 10 minutes as a safety net. In production deployments, run at least three gateway replicas across availability zones and put them behind a normal HTTP load balancer; the failure mode you have to engineer against is “one pod restarts during a control-plane outage,” not “all pods restart simultaneously,” which is rare enough to be acceptable.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet

.webp)
.webp)




.webp)


.webp)
.png)
.webp)
.webp)
.webp)




