Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
Da Unternehmen immer mehr LLM-gestützte Anwendungen teamübergreifend einführen, wird eine neue Infrastrukturebene immer wichtiger: die KI-Gateway. Ein KI-Gateway befindet sich zwischen Ihren Anwendungen und den zugrunde liegenden KI-Diensten oder -Modellen und fungiert als zentrale Steuerungsebene für den KI-Verkehr. Es bietet einheitlichen Zugriff auf Dutzende oder Hunderte von Modellen und setzt gleichzeitig Unternehmensrichtlinien in Bezug auf Sicherheit, Kosten und Beobachtbarkeit durch. Dies wird mit zunehmender Nutzung immer wichtiger: Bis 2026 werden voraussichtlich über 80% der Unternehmen generative KI einsetzen, und Gartner prognostiziert, dass bis 2028 70% der Entwicklungsteams, die Apps mit mehreren Modellen entwickeln, auf KI-Gateways angewiesen sein werden, um die Zuverlässigkeit zu verbessern und die Kosten zu kontrollieren. Ohne ein Gateway muss jeder KI-Kundenanruf einzeln verwaltet werden — was zu unkontrollierten Token-Ausgaben, fragmentierter Protokollierung und Sicherheitslücken führt. In dieser Umgebung wird ein gut durchdachtes KI-Gateway zum neue Steuerungsebene für Unternehmens-KI, die Konsistenz, Governance und Effizienz bietet, die herkömmlichen API-Gateways nicht bieten.
Was ist ein KI-Gateway und warum ist es wichtig
Ein KI-Gateway ist eine spezialisierte Middleware-Schicht, die den Verkehr zwischen Anwendungen und KI-Modellen verwaltet. Im Gegensatz zu herkömmlichen API-Gateways wurde sie speziell für KI-Workloads entwickelt. Es behandelt KI-spezifische Bedenken wie Ratenbegrenzung auf Token-Ebene, Streaming-Antworten und schnelle Sicherheitsüberprüfungen, die normale HTTP-Gateways nicht berücksichtigen. In der Praxis sendet eine Anwendung jede KI-Anfrage zuerst an das Gateway: Das Gateway authentifiziert dann die Anfrage, wendet alle Inhaltsfilter oder Leitplanken an, leitet sie an das entsprechende Modell weiter und gibt die Antwort schließlich (möglicherweise mit eigener Nachbearbeitung) an die App zurück. Diese zentrale Ebene ermöglicht Funktionen wie die Modellorchestrierung (Ausgleich oder Failover zwischen verschiedenen KI-Anbietern) und eine einheitliche Abrechnung.
Gartner hat vier identifiziert grundlegende Aufgaben die ein KI-Gateway in modernen Unternehmen leisten muss: Routing, Sicherheit/Leitplanken, Kostenkontrolle, und Beobachtbarkeit.
Routenplanung: Es leitet Anfragen auf der Grundlage von Richtlinien an das am besten geeignete Modell oder den am besten geeigneten Anbieter weiter (z. B. Auswahl zwischen schnelleren, aber teureren Modellen oder günstigeren Modellen).
Sicherheit: Es erzwingt Authentifizierung, Schlüsselverwaltung und Inhaltsfilterung von einem einzigen Kontrollpunkt aus. Dazu gehört auch die Vermeidung von Problemen wie der schnellen Eingabe oder dem Verlust vertraulicher Daten durch zentrale Schutzmaßnahmen für Ein- und Ausgänge.
Kostenkontrolle: Es verfolgt die Token-Nutzung pro Anfrage und setzt Budgets oder Kontingente durch, um Kostenüberschreitungen zu verhindern. So kann es beispielsweise doppelte Anfragen zwischenspeichern, um Tokens zu speichern und Anfragen umzuleiten, falls ein Modell das Budget überschreitet.
Beobachtbarkeit: Es protokolliert jeden KI-Aufruf und stellt Metriken/Traces zur Verfügung, sodass Teams Leistung und Nutzungstrends überwachen und Anomalien in allen Modellen und Anwendungen erkennen können.
Durch die Integration dieser Funktionen verwandelt ein KI-Gateway den KI-Verkehr in einen programmierbare Richtlinienebene — so wie es Kubernetes für Container getan hat. Dies löst wichtige Probleme beim Übergang von KI-Experimenten zur Produktion: Ohne ein Gateway ist es leicht, den Überblick über die Token-Ausgaben zu verlieren, inkonsistente Sicherheitskontrollen anzuwenden und fragmentierte Leistungsdaten zu haben. Ein Gateway stellt sicher, dass jeden Die KI-Anfrage ist geregelt und messbar. In einem Analystenleitfaden heißt es: „Ohne diese Ebene haben Unternehmen Schwierigkeiten, die Kosten zu kontrollieren, die Sicherheit aufrechtzuerhalten und die Leistung in großem Maßstab zu überwachen“. Kurz gesagt, ein KI-Gateway macht die KI-Nutzung unternehmenstauglich, indem es die Steuerungen und Telemetrie hinzufügt, die große Teams benötigen.
Wann benötigt eine Organisation ein KI-Gateway?
Nicht jedes kleine KI-Projekt benötigt ein vollständiges Gateway, aber sobald mehrere Teams, Modelle oder Nutzungsmuster auftauchen, wird ein Gateway wertvoll. Sie benötigen wahrscheinlich ein KI-Gateway, wenn:
Sie verwenden mehrere KI-Anbieter oder -Modelle. Wenn Ihre Anwendungen mehr als eine LLM-API aufrufen (z. B. indem Sie OpenAI, Azure oder benutzerdefinierte Modelle kombinieren), können Sie über ein Gateway über eine einzige, konsistente Schnittstelle darauf zugreifen. Dies verhindert, dass jedes Team die Zugriffslogik neu erfindet, und gewährleistet einheitliche Sicherheitsrichtlinien.
Die Nutzung erfolgt skalierend oder teamübergreifend. Wenn Dutzende von Entwicklern abteilungsübergreifend LLMs integrieren, riskieren Sie eine „Schatten-KI“ — eine unkontrollierte Nutzung auf verschiedenen Konten. Ein KI-Gateway vereinheitlicht diesen Traffic und gibt Aufschluss darüber, wer welches Modell aufruft. Gartner prognostiziert, dass die Nutzung von Gateways mit der Verbreitung von Multimodell-Anwendungen erheblich zunehmen wird.
Kosten und Budgets sind wichtig. Jede KI-Anfrage verbraucht Tokens, die Geld kosten. Eine einzelne Eingabeaufforderung kann Tausende von Token verwenden. Wenn die Nutzung steigt, wird es leicht, das Budget zu sprengen, ohne dass es jemand bemerkt. Ein KI-Gateway verfolgt die Token-Nutzung pro Anfrage und kann die Budgets pro Team oder Projekt durchsetzen, um unkontrollierbare Kosten zu vermeiden. Wenn sich Ihr Finanz- oder Plattformteam über unvorhersehbare KI-Ausgaben beschwert, ist es Zeit für ein Gateway.
Sicherheit und Compliance sind erforderlich. Für regulierte Branchen (Finanzen, Gesundheitswesen usw.) benötigen Sie eine zentrale Prüfung der KI-Interaktionen, strenge Zugriffskontrollen und Sicherheitsprüfungen für Inhalte. Ein KI-Gateway bietet genau das: Es kann beispielsweise personenbezogene Daten in Ausgängen blockieren oder die Desinfektion von Eingaben erzwingen. Wenn Sie HIPAA/SOC2-Konformität benötigen oder eine Integration mit SIEM-Systemen durchführen müssen, ist ein Gateway mit Sicherheit auf Unternehmensebene unerlässlich.
Sie haben Multi-Tenant- oder Agenten-Workloads. Wenn mehrere Geschäftsbereiche oder Kunden dieselbe KI-Infrastruktur verwenden, benötigen Sie eine Workload-Isolierung. Echte Unterstützung für mehrere Mandanten (separate Arbeitsbereiche, RBAC, API-Schlüssel) wird mit einem Gateway geliefert. Wenn Sie KI-Agenten einsetzen (die Protokolle wie das MCP/Model Context Protocol verwenden), kann ein für Agenten entwickeltes Gateway diese Tool-/Modell-Aufrufe ebenfalls zentral verwalten.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Wichtige Funktionen, auf die Sie bei einem KI-Gateway achten sollten
Konzentrieren Sie sich beim Vergleich von AI-Gateway-Lösungen auf Funktionen, die Folgendes sicherstellen Skalierbarkeit, Sicherheit, Beobachtbarkeit, und Wirtschaftlichkeit. Zu den wichtigen Funktionen gehören:
Vereinheitlichte API für mehrere Modelle: Das Gateway sollte eine einzelner, OpenAI-kompatibler Endpunkt zum Aufrufen von Modellen, auch wenn sie von verschiedenen Anbietern stammen. Das bedeutet, dass es Ihre Anfragen an Anbieter wie OpenAI, Azure OpenAI, Amazon Bedrock, Gemini, Groq oder sogar selbst gehostete Modelle mithilfe einer Standardschnittstelle für v1/Chat/Completions übersetzen kann. Eine breite Modellabdeckung ist von entscheidender Bedeutung: Stellen Sie sicher, dass führende Modelle sofort unterstützt werden, und eine einfache Möglichkeit, neue oder benutzerdefinierte Modelle zu integrieren. Idealerweise sollten Sie in der Lage sein, Modelle über Header oder Konfigurationsänderungen zu wechseln, ohne Ihren Anwendungscode zu berühren. Diese einheitliche Oberfläche vereinfacht die Entwicklung und ermöglicht es Ihnen, nahtlos mit verschiedenen Modellen zu experimentieren.
Hohe Leistung und Skalierbarkeit: Da das Gateway jeden KI-Produktionsaufruf weiterleitet, muss es schnell und skalierbar sein. Achten Sie auf einen minimalen Latenz-Overhead (optimalerweise nur ein paar Millisekunden pro Anfrage). Das Gateway sollte hohe RPS (Anfragen pro Sekunde) auch bei bescheidenen Ressourcen unterstützen. Beispielsweise kann ein gut durchdachtes Gateway Hunderte von RPS pro CPU-Kern verarbeiten. Autoscaling und die Bereitstellung in mehreren Regionen sind ebenfalls von entscheidender Bedeutung. Das Gateway sollte in der Lage sein, bei Bedarf zusätzliche Pods oder Instances hochzufahren und zonen-/regionsübergreifend zu arbeiten, um die Latenz für globale Teams zu reduzieren. Architektonisch gesehen implementieren viele Gateways speicherinterne Ratenbegrenzungs- und Lastausgleichsprüfungen (keine externen Aufrufe im Anforderungspfad), um Latenzen unter 50 ms zu erreichen. Bestätigen Sie die Benchmark-Angaben des Anbieters (z. B. X RPS pro Pod) und testen Sie unter der erwarteten Last.
Routing, Lastenausgleich und Zuverlässigkeit: Das Gateway muss den Verkehr intelligent verteilen. Zu den wichtigsten Funktionen gehören ein gewichteter oder latenzbasierter Lastausgleich zwischen Modellreplikaten und -anbietern, automatische Wiederholungsversuche und Modell-Fallbacks bei Fehlern sowie semantisch bewusstes Zwischenspeichern von Eingabeaufforderungen. Stark LLM-Lastenausgleich Funktionen stellen sicher, dass der Datenverkehr intelligent auf die Anbieter verteilt wird, um die Leistung aufrechtzuerhalten, Latenzspitzen zu reduzieren und die Produktionszuverlässigkeit zu verbessern. Sie sollten in der Lage sein, Ratenlimits pro Benutzer oder Team festzulegen, um Missbrauch zu verhindern, und pro Projekt Kontingente oder Budgets (auf Token- oder Dollarbasis) festlegen. Die Unterstützung erweiterter Routing-Richtlinien (z. B. das Senden von Datenverkehr mit hoher Priorität an Premium-Modelle oder das Routing auf der Grundlage von Anforderungs-Timeouts) ist von Vorteil. Stellen Sie insgesamt sicher, dass das Gateway als robuster Proxy dienen kann, damit Ihre Anwendung nicht durch einen Downstream-API-Ausfall oder -Spike abstürzt.
Robuste Beobachtbarkeit: Jede Anfrage über das Gateway sollte detaillierte Protokolle und Metriken generieren. Zu den wichtigsten Beobachtbarkeitsfunktionen gehören die Anforderungsverfolgung mit umfangreichen Metadaten (Eingabeaufforderungstext, verwendetes Modell, Eingabe-/Ausgabetokens, Benutzeridentität, Latenz usw.) sowie Echtzeit- oder historische Dashboards, die Nutzungs- und Leistungstrends anzeigen. Das Gateway sollte Integrations-Hooks für Ihren Monitoring-Stack bereitstellen — zum Beispiel OpenTelemetry-Kompatibilität und den einfachen Export von Logs/Metriken nach Grafana, Prometheus, Datadog usw. Wichtige Fragen: Können Sie Logs/Metriken nach Benutzer, Team oder Modell filtern? Können Sie Fehler (4xx/5xx) oder Fallback-Ereignisse detailliert aufschlüsseln? Mit echten Unternehmenslösungen können Sie Kosten- und Nutzungsdaten nach Bedarf aufteilen (pro Modell, pro Abteilung usw.), sodass Sie Budgets genau zuweisen können. In der Evaluierungs-Checkliste wird vorgeschlagen, dies zu überprüfen Kostenmetriken und Leistungskennzahlen (wie Time-to-First-Token) sind auf granularen Ebenen verfügbar.
Sicherheit, Leitplanken und Zugriffssteuerung: Sicherheit muss eingebaut sein. Achten Sie auf die integrierte Unterstützung für Eingabeaufforderungs- und Inhaltsfilterung (Schlüsselwortlisten, Regex-Regeln, kontextsensitive Richtlinien), um unsichere oder unerwünschte Ausgaben zu verhindern. Das Gateway sollte in der Lage sein, externe Inhaltsfilter oder TriSM-Tools (z. B. AWS Content Moderation, KI-Guardrail-Anbieter) zu integrieren. Alle API-Anfragen sollten mit vollständigen Audit-Trails protokolliert werden, und Sie sollten in der Lage sein, fein abgestufte Berechtigungen zuzuweisen, z. B. einzuschränken, welche Teams oder Benutzer welche Modelle aufrufen können. Role-Based Access Control (RBAC) ist ein Muss — stellen Sie sicher, dass das Gateway die Integration mit Ihrem SSO/IdP (SAML, OIDC usw.) unterstützt und dass Rollen und Richtlinien damit synchronisiert werden können. Prüfen Sie, ob die SaaS- oder On-Premise-Lösung des Anbieters die Verschlüsselung von Daten im Ruhe/bei der Übertragung und Compliance-Zertifizierungen (wie SOC2, GDPR, HIPAA, falls Sie diese benötigen) vorhanden sind.
Kostenmanagement: Zusätzlich zum Raw-Token-Tracking sind erweiterte Kostenkontrollen von entscheidender Bedeutung. Das Gateway sollte Preistabellen für große Anbieter führen (oder benutzerdefinierte Preise zulassen), damit es die Dollarkosten jeder Anfrage berechnen kann. Es sollte die Ausgabenpolitik durchsetzen und beispielsweise Warnmeldungen senden oder Anfragen blockieren, wenn ein Team 80% seines Budgets erreicht. Bei einigen Gateways können Sie benutzerdefinierte Tarife für Unternehmenstarife oder selbst gehostete Modelle voreinstellen und diese zur Berechnung der Kosten verwenden. Das semantische Zwischenspeichern von Antworten (z. B. durch Einbettungen) kann die Nutzung ebenfalls drastisch reduzieren. Daher ist dies ein nettes Extra, um Kosten zu sparen. Achten Sie letztlich auf die Fähigkeit zum Generieren Kostenberichte nach Benutzer oder Projekt und um die Token-Ausgaben in Echtzeit zu sehen.
Erfahrung und Integrationen für Entwickler: Ein gutes Gateway fühlt sich für Entwickler nahtlos an. Es sollte mit gängigen KI-Frameworks und -Agenten kompatibel sein — zum Beispiel LangChain, LlamaIndex oder beliebte No-Code-Tools (n8n, Flowise) über seine API unterstützen. Prüfen Sie, ob es ein einheitliches Prompt-Playground oder ein Versionierungstool zur zentralen Verwaltung von Prompts bietet. Multimodaler Support (Bearbeitung von Text, Bildern, Audio und Einbettungen) über dieselbe Oberfläche ist nützlich, wenn Ihre Anwendungsfälle mehr als nur Chat beinhalten. Schließlich sollte das Gateway eine klare REST-API oder SDKs für die Verwaltung bereitstellen: z. B. das Erstellen von API-Schlüsseln, das Konfigurieren von Modellen, das Festlegen von Budgets usw. Das TrueFoundry-Gateway bietet beispielsweise eine schnelle Spielwiese, eine API-Schlüsselverwaltung und funktioniert sofort mit allen wichtigen LLM-Frameworks.
Flexibilität bei der Bereitstellung: Abhängig von Ihrer Sicherheitslage benötigen Sie das Gateway möglicherweise als SaaS- oder selbst gehostete Lösung. Prüfen Sie, ob das Gateway in Ihrer Cloud oder vor Ort ausgeführt werden kann (TrueFoundry unterstützt beides) und welche Infrastruktur es benötigt (Kubernetes usw.). Überlegen Sie, wie die Konfiguration verwaltet wird — achten Sie auf Terraform/Helm-Unterstützung und GitOps-Integration, wenn Sie diese Methoden anwenden. Achten Sie auch auf Edge-Bereitstellungsfunktionen oder regionale Bereitstellungsfunktionen, um die Latenz für globale Teams zu minimieren. Das SaaS von TrueFoundry ist beispielsweise global verteilt und das lokale Gateway kann in jeder Cloud-Region platziert werden, sodass die Antwortzeiten in der Praxis unter ~5 ms liegen.
Zusammenfassend sollte Ihre Bewertung Folgendes umfassen Routing/Orchestrierung, Performance, Beobachtbarkeit, Sicherheit, Kostenkontrolle, und Einsatz. Verwenden Sie als praktischen Schritt eine strukturierte Checkliste, um jedes Gateway anhand dieser Dimensionen zu bewerten.
Der Ansatz von TrueFoundry für das Design von KI-Gateways
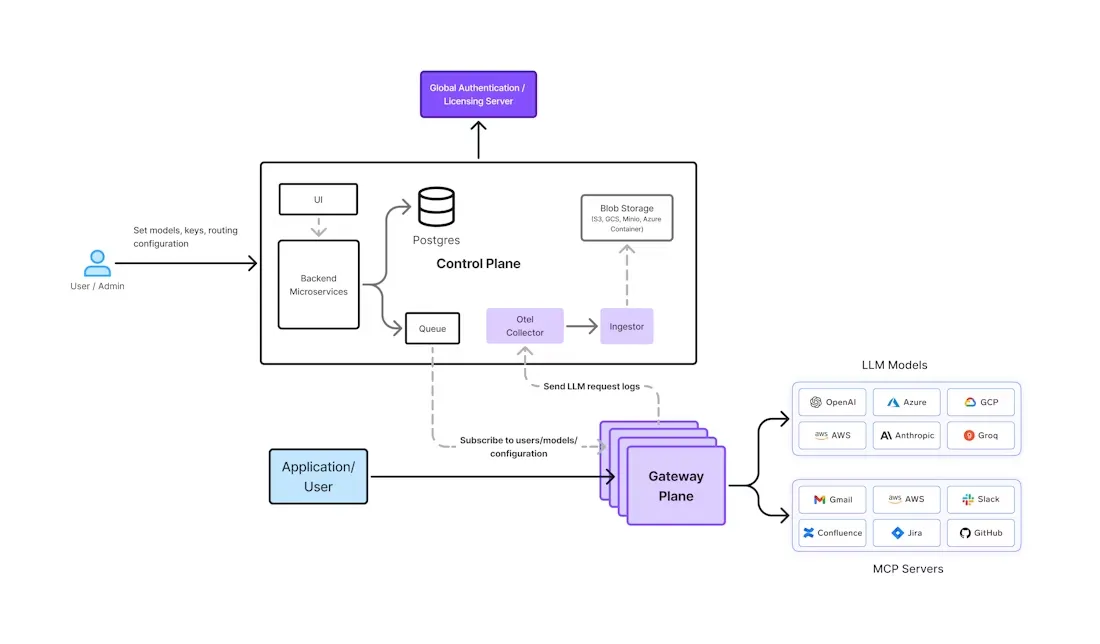
Das eigene KI-Gateway von TrueFoundry wurde von Grund auf unter Berücksichtigung dieser Unternehmensanforderungen entwickelt. Es bietet eine einheitliche Schnittstelle zu über 1000 LLMs (OpenAI, Anthropic, Gemini, Bedrock, Open-Source-Modelle und mehr), wobei Sicherheit, Beobachtbarkeit und Governance in den Mittelpunkt gestellt werden. Die Architektur trennt Funktionen der Steuerungsebene (UI, Policy-Datenbank usw.) von statusfreien Gateway-Pods, die den Inferenzverkehr verarbeiten (siehe Abbildung unten).
Abbildung 1: Architektur des AI Gateways von TrueFoundry. Eine zentrale Steuerungsebene (links) überträgt die Konfiguration an global verteilte Gateway-Pods (rechts). Alle Richtlinienprüfungen (Authentifizierung, Ratenbegrenzungen, Routing) finden auf jedem Pod im Speicher statt.
True Foundry's Gateway-Pods abonnieren einen NATS-Nachrichtenstrom von der Steuerungsebene. Richtlinienänderungen (wie neue Benutzerberechtigungen, Modellkonfigurationen oder Balancing-Regeln) werden in NATS veröffentlicht und sind sofort für jeden Pod verfügbar. Wenn eine Anfrage bei einem Gateway-Pod eingeht, Alle wichtigen Prüfungen finden im Speicher statt, ohne zusätzliche Netzwerk-Hops — dazu gehören JWT-Authentifizierung, RBAC-Prüfungen, Durchsetzung von Ratenlimits und Entscheidungen zum Modelload-Balancing. Infolgedessen zeigen die Tests von TrueFoundry einen Latenz-Overhead in der Größenordnung von nur wenigen Millisekunden pro Anfrage. Selbst bei vollständiger Ablaufverfolgung (Protokollierung jeder Eingabeaufforderung und Token-Anzahl) verarbeitet moderne Hardware Hunderte von Anfragen pro Sekunde pro Pod, und das System skaliert linear, indem es weitere Pods hinzufügt.
Hinter den Kulissen werden genehmigte Anfragen an den ausgewählten KI-Anbieter oder Modellendpunkt weitergeleitet. Wenn eine Antwort erfolgreich ist, wird sie sofort an den Client zurückgesendet. Gleichzeitig werden die Metadaten der Anfrage und Antwort (verwendete Token, Latenz, Benutzer, Modell) asynchron in der Nachrichtenwarteschlange veröffentlicht. Ein Backend-Analysedienst nimmt diese Ereignisse in ClickHouse auf (über Blob-Speicher), um Nutzungs- und Kostenmetriken zu berechnen. Diese asynchrone Pipeline bedeutet, dass Protokollierung und Analysen niemals den Live-Datenverkehrspfad blockieren. Dashboard- und API-Clients können dann die aggregierten Telemetriedaten (über OpenTelemetrie-Standards) abfragen, um die Nutzung nach Modell, Team oder Zeitraum zu verfolgen.
Die Sicherheit wird durchgehend durchgesetzt. Das Gateway von TrueFoundry verwendet feinkörnigeRBAC sodass Teams nur die Modelle sehen und aufrufen, die sie verwenden dürfen. Alle API-Schlüssel und -Token können zentral und detailliert verwaltet werden Audit-Logs Erfassen Sie jede Aktion (Zeitstempel, Benutzer-IDs, verwendetes Modell usw.). Benutzerdefinierter Inhalt Leitplanken kann im Portal definiert werden (z. B. Schlüsselwortfilter oder kontextsensitive Regeln), und das Gateway blockiert oder kennzeichnet alle Antworten, die gegen die Richtlinien verstoßen. TrueFoundry lässt sich auch in Unternehmensidentitätsanbieter integrieren, sodass Sie Rollen von Ihrem IdP synchronisieren können (SSO über SAML/OIDC) und diese automatisch auf Gateway-Berechtigungen anwenden können.
Zu den weiteren Funktionen gehören multimodale Unterstützung (dieselbe API verarbeitet Text, Bilder, Audio und Einbettungen nahtlos) und ein integriertes System zur Verwaltung von Eingabeaufforderungen. Das Gateway bietet eine Prompter Spielplatzzum zentralen Versionieren und Testen von Prompts, was besonders für Teams nützlich ist, die an Produktionsprompts iterieren. Es bietet auch globale Budget- und Ratenlimits: Sie können beispielsweise ein monatliches Dollarkontingent pro Team festlegen oder Token-basierte Budgets pro Projekt durchsetzen. In der Praxis erhalten Unternehmen, die das TrueFoundry-Gateway verwenden, sofort Einblick in die Token-Ausgaben (sogar nach Anbieter und Modell aufgeschlüsselt) und können Benutzer automatisch anhalten oder Benutzer benachrichtigen, wenn Budgets überschritten werden.
Flexibilität bei der Bereitstellung ist ein Markenzeichen des Designs von TrueFoundry. Das AI Gateway kann als verwaltetes SaaS (mit Knoten in mehreren Cloud-Regionen für niedrige Latenz und hohe Verfügbarkeit) ausgeführt oder in Ihrer eigenen Cloud-/On-Premises-Umgebung installiert werden. In beiden Fällen sind die Auswirkungen auf die Leistung minimal. In einer kürzlich erschienenen häufig gestellten Frage wird darauf hingewiesen, dass das SaaS von TrueFoundry weniger als ~5 ms an Overhead pro Anfrage verursacht. Da es in jedem Kubernetes-Cluster (oder sogar am Edge) bereitgestellt werden kann, können Sie Gateway-Pods in der Nähe Ihrer Anwendungen oder Datenquellen platzieren, um die Round-Trip-Zeit weiter zu reduzieren. TrueFoundry unterstützt auch den sicheren Betrieb vor Ort: Die einzigen Daten, die an den Cloud-Lizenzserver gesendet werden, sind anonymisierte Nutzungskennzahlen, und die vollständige Bereitstellung auf der Steuerungsebene kann bei Bedarf hinter Ihrer Firewall erfolgen.
Wählen Sie das richtige Gateway für Ihren Anwendungsfall
Kein einziges KI-Gateway ist für jedes Szenario perfekt, also richten Sie Ihre Auswahl nach Ihren Prioritäten aus:
Kostensensible Anwendungsfälle: Wenn eine strenge Budgetkontrolle entscheidend ist, priorisieren Sie Gateways mit integrierte Ausgabenpolitik. Stellen Sie sicher, dass es benutzerdefinierte Preise anwenden kann (z. B. unter Berücksichtigung Ihrer Unternehmensrabatte) und Warnmeldungen bei Budgetschwellen auslösen kann. Mit TrueFoundry können Sie beispielsweise Tarife für öffentliche Anbieter vorab herunterladen und benutzerdefinierte Tarife für Ihre Verträge oder selbst gehosteten Modelle definieren, wobei automatische Benachrichtigungen angezeigt werden, sobald sich die Schwellenwerte nähern.
Hohe Sicherheits-/Compliance-Anforderungen: Achten Sie in regulierten Branchen auf Funktionen wie vollständige Überprüfbarkeit (manipulationssichere Protokolle), granulares RBAC und Verschlüsselungsschlüsselverwaltung. Das Gateway von TrueFoundry unterstützt sofort SOC2- und HIPAA-Workflows (über lokale Optionen und sichere Schlüsselspeicherung) und kann in SIEM-Tools integriert werden. Funktionen wie PII-Erkennung und Datenredigierung können entscheidend sein, wenn Sie mit sensiblen Daten umgehen.
Extrem hoher Durchsatz/niedrige Latenz: Für Echtzeitanwendungen (z. B. Kunden-Chatbots oder Handelssysteme) ist die Leistung des Gateways von größter Bedeutung. Prüfen Sie die Benchmarks des Anbieters oder führen Sie ein Pilotprojekt durch: Die Architektur von TrueFoundry kann bei minimaler zusätzlicher Latenz mehr als 250 RPS pro Pod bereitstellen und mit mehr Replikaten problemlos auf viele Tausend skalieren. Wenn Sie eine extrem niedrige Latenz benötigen, ist es wichtig, Gateway-Pods in derselben Region (oder sogar in Edge-Zonen) wie Ihre Benutzer bereitzustellen — die multiregionale SaaS- oder On-Prem-Option von TrueFoundry ermöglicht dies.
Multi-Cloud- oder Hybridumgebungen: Wenn Sie mehrere Cloud-Anbieter verwenden oder strenge Datenresidenzanforderungen haben, wählen Sie ein Gateway, das über diese Anbieter laufen kann. TrueFoundry unterstützt die Bereitstellung in jeder Cloud- oder lokalen Infrastruktur und kann Richtlinien global synchronisieren. Das bedeutet, dass eine Steuerungsebene Gateways verwalten kann, die in verschiedenen Regionen oder Clouds eingesetzt werden.
Multimodale oder agentische Anwendungen: Wenn Ihr Anwendungsfall Agenten (Tools, Aktionen) über die MCP/A2A-Protokolle umfasst oder wenn Sie nahtlose Unterstützung für Bild und Audio benötigen, stellen Sie sicher, dass das Gateway über diese Funktionen verfügt. TrueFoundry erweitert sein Gateway aktiv, um MCP-Server zu virtualisieren und KI-Tools unter einer API zu vereinheitlichen. Bereits heute bietet das Unternehmen „virtuelle MCP-Server“ an, auf denen Sie Tools und Modelle mehrerer Agenten in einer Oberfläche kombinieren können (demnächst in GA verfügbar). Für multimodale Anwendungen unterstützt TrueFoundry Text-, Bild-, Audio- und Einbettungsmodelle einheitlich.
Entwickler und Ökosystem passen zusammen: Überlegen Sie, was Ihre Entwicklungsteams verwenden. Wenn sie sich auf LangChain- oder LLM-Frameworks verlassen, wählen Sie ein Gateway, von dem bekannt ist, dass es sofort mit ihnen zusammenarbeitet. Die einfache Einführung (API-Dokumente, Client-SDKs) ist für die Akzeptanz von Bedeutung. TrueFoundry bietet offene APIs und Clientbibliotheken in mehreren Sprachen. Aufgrund seiner einheitlichen API funktioniert vorhandener OpenAI-basierter Code oft unverändert. Prüfen Sie auch, ob das Gateway in die von Ihnen verwendeten CI/CD- oder Infrastrukturtools integriert ist (z. B. die Terraform-Unterstützung in TrueFoundry).
Ordnen Sie diese Anforderungen in jedem Fall Ihrer Evaluierungscheckliste zu. Gewichten Sie die Kriterien auf der Grundlage dessen, was für Ihr Projekt am wichtigsten ist (Sicherheit, Kosten, Funktionen). Der Evaluierungsrahmen von TrueFoundry kann individuell angepasst werden (er ist als öffentliche CSV-Datei verfügbar), sodass Sie Anbieter Seite an Seite anhand der Funktionen bewerten können, die Sie benötigen. Ziel ist es, das Gateway auszuwählen, das nicht nur die heutigen Anforderungen erfüllt, sondern auch mit Ihren KI-Initiativen wachsen kann.
Fazit
Mit der zunehmenden Verbreitung von KI wird ein speziell entwickeltes Gateway schnell zu einer unverzichtbaren Steuerungsebene. Es bringt Ordnung in eine ansonsten chaotische Mischung aus APIs, Kosten und Sicherheitsrisiken. Durch die zentrale Verwaltung von Routing, Beobachtbarkeit, Budgetierung und Compliance macht ein KI-Gateway die KI-Infrastruktur zu einer zuverlässigen, kontrollierten Plattform. Das KI-Gateway von TrueFoundry basiert auf diesen Prinzipien und bietet eine einheitliche Schnittstelle für Hunderte von Modellen mit Sicherheit, Überwachung und Richtlinienkontrollen auf Unternehmensebene.
Verwenden Sie bei der Auswahl eines Gateways einen strukturierten Ansatz: Machen Sie sich ein Bild von Ihren Workloads, lesen Sie die Evaluierungs-Checkliste und vergleichen Sie, wie die einzelnen Optionen in Bezug auf Routing-Flexibilität, Leistung, Beobachtbarkeit, Kostenkontrolle und Governance-Funktionen abschneiden. Auf diese Weise können Sie die Lösung auswählen, die als „KI-Kontrollebene“ für die LLM- und agentenbasierten Anwendungen Ihres Unternehmens dient. Ein robustes Gateway schützt nicht nur Budgets und Daten, sondern beschleunigt auch die Entwicklung, indem es eine konsistente, skalierbare Grundlage für alle KI-Services bietet. Letztlich ebnet die Investition in das richtige KI-Gateway den Weg, um Ihre KI-Anwendungsfälle sicher vom Experiment zur Realität auf Unternehmensebene zu machen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last


































.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




