Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
AI Gateway: Das zentrale Kontrollfeld der heutigen generativen KI-Infrastruktur
In unserem jüngsten Webinar zu AI Gateway haben wir zunächst überprüft, wo sich das Publikum derzeit auf seiner Reise zur generativen KI (GenAI) befindet.
Interessanterweise gaben über 50% an, dass GenAI bereits in der Produktion läuft, und weitere 15% skalieren es über mehrere Teams hinweg — deutliche Anzeichen für eine starke Akzeptanz in Unternehmen und eine zunehmende Reife bei der Bereitstellung von GenAI-Anwendungen.
Die Entwicklung des LLM-Gateways als zentrale Steuerungsebene
Wir haben uns darauf konzentriert, wie sich das KI-Gateway in den letzten 6 bis 9 Monaten weiterentwickelt hat — von einer grundlegenden Modell-Routing-Ebene zu einer wichtigen zentralen Steuerungsebene innerhalb des modernen generativen KI-Stacks.
Anfänglich wurden LLMs hauptsächlich verwendet, um Single-Turn-Antworten auf Prompts zu generieren, die größtenteils als fortgeschrittene Prädiktoren für das nächste Wort angesehen wurden.
Aktueller Status der Agenten: Im Jahr 2025 sind LLM-gestützte Agenten autonom und zielorientiert geworden und in der Lage, hinter den Kulissen mehrere Tools und Systeme aufzurufen. Ein Agent zum Zurücksetzen von Passwörtern kann beispielsweise einen Benutzer authentifizieren, APIs aufrufen, um Passwörter zurückzusetzen, und Bestätigungs-E-Mails versenden — und das alles ohne menschliches Eingreifen.
Organisatorische Komplexität: Unternehmen verwenden oft Dutzende solcher komplexer Agenten, die sich über mehrere Teams erstrecken und verschiedene Modelle verschiedener Anbieter, Frameworks und Infrastrukturen (einschließlich Hyperscaler und Hybrid Clouds) verwenden.
Herausforderungen ohne Zentralisierung: Diese Dezentralisierung führt zu erheblichen Governance-Problemen, einschließlich Inkonsistenzen bei den Modell-APIs, Bereitstellbarkeit, Überprüfbarkeit, Kostenmanagement und Failover-Strategien.
Das LLM-Gateway ist als zentrales Gateway unverzichtbar geworden, das diese unterschiedlichen Ressourcen und betrieblichen Anforderungen konsolidiert und Governance, Beobachtbarkeit, Kostenkontrolle und Zuverlässigkeit in großem Maßstab ermöglicht.
Herausforderungen für Unternehmen, die mehrere LLM-Anbieter nutzen
Inkonsistente API-Formate: Trotz allgemeiner Behauptungen zur OpenAI-API-Kompatibilität unterscheiden sich die Anbieter in der Parametersyntax (z. B. maximale Tokens, Temperaturbereiche, Stoppsequenzen), was die Umschaltbarkeit und Interoperabilität erschwert.
Häufige Ausfälle: Modellanbieter sind selbst Startups, bei denen häufige Ausfallzeiten zu Anwendungsausfällen führen. Daher müssen Anwendungen modellunabhängig sein und einen ordnungsgemäßen Failover durchführen können.
Hohe Latenzvarianz: Die Latenz zwischen den Anbietern schwankt stark, was die Anwendungsleistung unvorhersehbar macht. Die Latenz wirkt sich genauso stark auf das Benutzererlebnis aus wie eine vollständige Ausfallzeit.
Komplexe Ratenbegrenzungen: Mehrere Tariflimits pro Anbieter erfordern Drosselung und Kostenkontrolle in allen Geschäftsbereichen und Kostenstellen. Eine zentrale Durchsetzung ist schwierig, aber unerlässlich.
Anforderungen an eine hybride Infrastruktur: Viele Unternehmen müssen Ratenbegrenzungen und wichtige Rotationen zwischen Cloud-Anbietern und der lokalen GPU-Infrastruktur verwalten.
Kostspielige Wiederholungsabfragen: Generative KI-Anwendungen erhalten oft viele identische oder semantisch ähnliche Anfragen (z. B. Grußnachrichten), wodurch die Kosten generativer KI unnötig, es sei denn, gemildert durch semantisches Caching.
Leitplanken und Einhaltung: Unternehmen benötigen eine zeitnahe Eingabefilterung (z. B. keine Weitergabe von personenbezogenen Daten) und eine Output-Validierung (Filterung obszöner Ausdrücke) für mehrere Teams und Modelle, was eine zentrale Durchsetzung erfordert.
Führungs- und Prüfungsanforderungen: Anfragen können mehrere Anbieter und Datenquellen innerhalb einer einzigen Benutzeroberflächenaktion umfassen. Daher benötigen Unternehmen zentrale Beobachtbarkeit, Auditprotokollierung, Erklärbarkeit und Rückverfolgbarkeit, um Compliance-Anforderungen zu erfüllen.
Diese Herausforderungen rechtfertigen die Rolle des LLM-Gateways als zentrale Steuerungsebene in generativen KI-Ökosystemen von Unternehmen.
Kernfunktionen und Vorteile eines KI-Gateways
Ein KI-Gateway spielt eine Schlüsselrolle bei der Bewältigung dieser Herausforderungen, da es eine Reihe von technischen Funktionen bietet, mit denen der Modellzugriff, die Steuerung und die Zuverlässigkeit optimiert werden können.
Wichtige Gateway-Funktionen:
Vereinheitlichte API-Ebene: Bietet eine einzige, konsistente API-Schnittstelle, die anbieterspezifische Details und Authentifizierungsmechanismen abstrahiert. Dies gewährleistet:
Keine Bindung an einen Anbieter.
Reibungsloser Anbieterwechsel ohne Codeänderungen.
Vereinfachte SDK-Nutzung für Entwickler.
Zentralisiertes Schlüsselmanagement: Verwaltet verschiedene Authentifizierungsmethoden (AWS-IAM-Rollen, OpenAI-API-Schlüssel, GCP-Identitäten) über ein einheitliches System. Zu den Vorteilen gehören:
Ausgabe von API-Schlüsseln auf Benutzerebene zur Rückverfolgbarkeit.
Dienstkonten oder virtuelle Schlüssel für Anwendungen.
Einfache Schlüsselrotation und Verwaltung.
Vermeidet die pauschale gemeinsame Nutzung von API-Schlüsseln und ermöglicht feinere Berechtigungskontrollen.
Wiederholungen und Rückrufe: Behandelt Provider-Ausfälle zuverlässig mit automatisierten Failover-Richtlinien. Das konfigurierbare Fallback von einem Modell zum anderen gewährleistet einen unterbrechungsfreien Betrieb, ohne den Anwendungscode zu beeinträchtigen.
Ratenbegrenzung und Kostenkontrolle: Ermöglicht die präzise Durchsetzung von API-Nutzungsrichtlinien pro Benutzer, pro Anwendung oder pro Geschäftseinheit. Zu den Beispielen gehören:
Tägliche Anruflimits für Entwickler.
Premium-Benutzerstufen mit differenzierten Kontingenten.
Schutz vor außer Kontrolle geratenen Agenten, die Endlosschleifen aufrufen, und verhindert so unerwartete Abrechnungsspitzen.
Lastenausgleich: Automatisiert das Routing von Anfragen an das schnellste oder zuverlässigste Modell in Echtzeit und führt latenzbasierte Lastverteilung und Integritätsprüfungen durch.
Canary-Rollouts für neue Modelle: Erleichtert die schrittweise, kontrollierte Einführung neuer Modellversionen und ermöglicht so Tests und Leistungsvergleiche vor der vollständigen Migration.
Verschiedene Arten von Load Balancing
Zentrale Leitplanken : Implementiert unternehmensweite Prompt- und Response-Filter wie:
Entfernung personenbezogener Daten vor dem externen Senden von Daten.
Erkennung und Entfernung von Obszönitäten oder schädlichen Inhalten in Antworten.
Fähigkeit, Eingabeaufforderungen zentral zu blockieren oder zu mutieren.
Transparente Integration, sodass Anwendungsentwickler diese Regeln nicht einzeln verwalten müssen.
Semantisches Caching: Verwaltet einen Cache mit semantisch ähnlichen Prompt-Response-Paaren, um Modellaufrufe zu reduzieren, Latenz und Kosten für sich wiederholende Abfragen zu reduzieren.
Die wichtigsten Vorteile
Starke zentrale Steuerung für Unternehmen.
Sofortige Möglichkeit, Modelle und Anbieter ohne Ausfallzeiten zu wechseln.
Überprüfbarer und beobachtbarer Zugriff auf alle Modellinteraktionen mit granularen Metriken.
Reduzierter technischer Aufwand bei der Verwaltung der Komplexität mehrerer Modelle.
Verbesserte Benutzererfahrung mit Failover- und Latenzoptimierungen.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Zukunftsvision: Integration mit MCP-Servern mit AI Gateway
In Zukunft wird das LLM-Gateway über Modelle hinausgehen, um ganze Tools und Agenten über MCP- und A2A-Protokolle zu verwalten -
Was ist ein MCP-Server?
Ein MCP-Server stellt Produkt-APIs (z. B. Slack-Kanäle, Nachrichten, Benutzer) in einer Form zur Verfügung, die LLM-basierte Agenten entdecken und nutzen können.
Beispiel: Ein Slack MCP-Server stellt APIs zum Lesen von Kanälen, Nachrichten und Senden von Nachrichten zur Verfügung, die alle für einen LLM-Agenten verständlich sind.
Agenteninteraktion mit MCP-Servern:
Agenten fragen den MCP-Server ab, um verfügbare Tools zu identifizieren.
Basierend auf einer Anfrage in natürlicher Sprache plant und ruft der Agent eigenständig die richtige Reihenfolge der Tools auf (z. B. Nachrichten abrufen, Zusammenfassen, Erstellen von Jira-Aufgaben).
Gateway-Integration mit MCP:
Das Gateway dient als einheitlicher Zugangspunkt sowohl für LLM-Modelle als auch für MCP-Server innerhalb einer Organisation.
Nutzer werden in der Lage sein, Befehle in natürlicher Sprache (z. B. „Erstelle Aufgaben in Jira auf der Grundlage meiner Slack-Nachrichten“) über integrierte Tools hinweg ohne Programmierkenntnisse auszugeben.
Die Authentifizierung wird nahtlos verwaltet und über bestehende Identitätsanbieter wie Okta oder Azure AD zusammengeführt.
Diese Integration ermöglicht es Benutzern ohne technische Kenntnisse, Geschäftsprozesse einfach zu automatisieren.
Einheitlicher Zugangspunkt für LLM-Modelle und MCP-Server innerhalb einer Organisation
Zentralisierte Prüfung und Steuerung aller Agentenaktivitäten und Tool-Aufrufe.
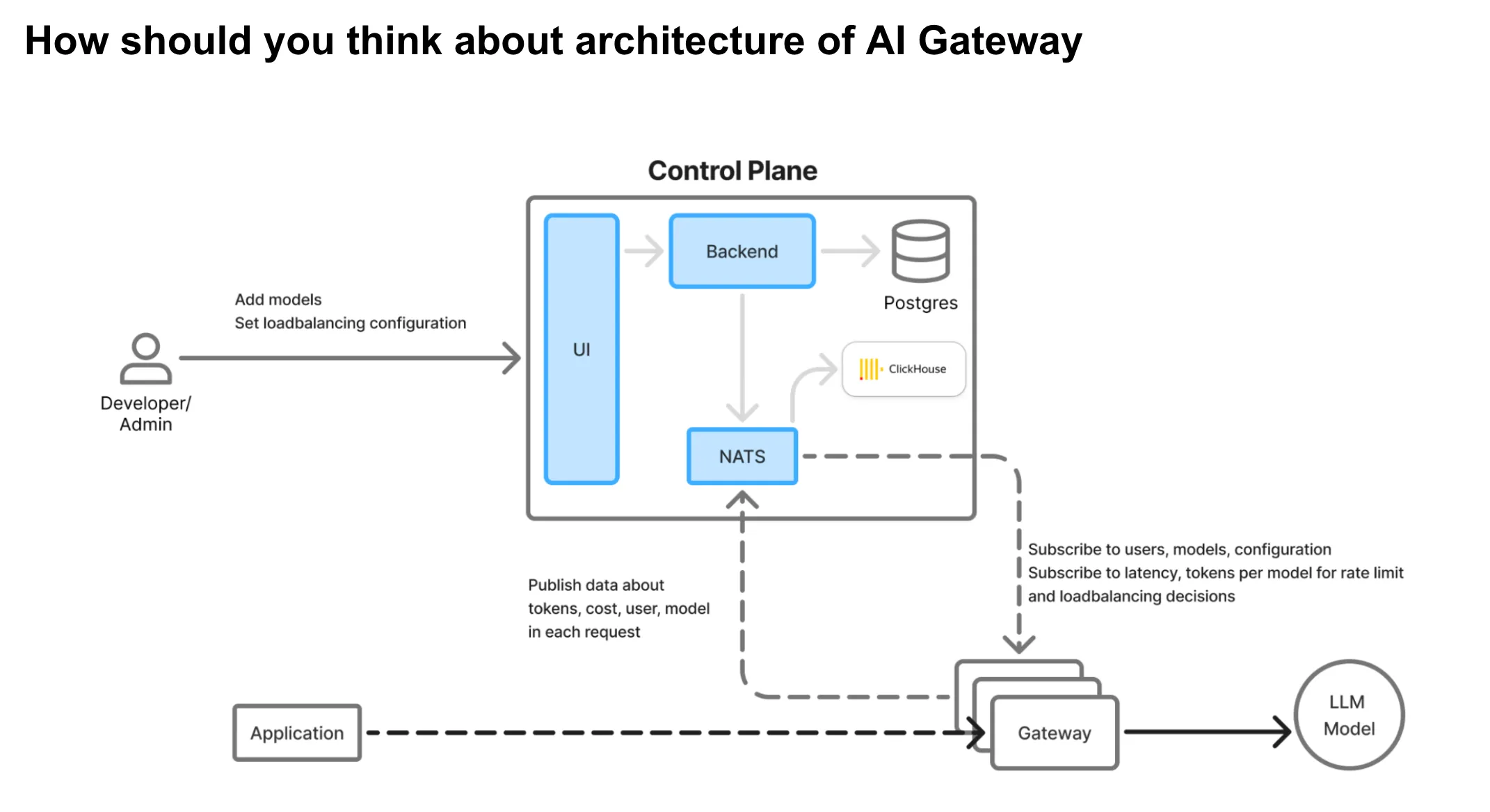
AI-Gateway-Architektur
Das AI Gateway fungiert als kritische Proxyschicht zwischen Anwendungen und Anbietern von Sprachmodellen (LLM). Weil das Gateway lügt im kritischen Pfad des Produktionsverkehrs, es muss unter Berücksichtigung der folgenden Kernprinzipien konzipiert werden:
Wichtige architektonische Prioritäten:
Hohe Verfügbarkeit: Das Gateway darf nicht zu einer einzigen Ausfallstelle werden. Selbst angesichts von Abhängigkeitsproblemen (wie Datenbank- oder Warteschlangenausfällen) sollte es den Datenverkehr weiterhin problemlos abwickeln.
Niedrige Latenz: Da es bei jeder Inferenzanforderung enthalten ist, muss das Gateway Folgendes hinzufügen minimaler Aufwand um eine schnelle Benutzererfahrung zu gewährleisten.
Hoher Durchsatz und Skalierbarkeit: Das System sollte linear mit der Auslastung skalieren und in der Lage sein, Tausende von gleichzeitigen Anfragen mit effizienter Ressourcennutzung zu verarbeiten.
Keine externen Abhängigkeiten im Hot Path: Alle netzwerkgebundenen oder festplattengebundenen Operationen sollten auf asynchrone Systeme ausgelagert werden, um Leistungsengpässe zu vermeiden.
In-Memory-Entscheidungsfindung: Kritische Prüfungen wie Ratenbegrenzung, Lastenausgleich, Authentifizierung, und Autorisierung sollten alle im Speicher ausgeführt werden, um maximale Geschwindigkeit und Zuverlässigkeit zu gewährleisten.
Trennung von Steuerungsebene und Proxyebene: Konfigurationsänderungen und Systemmanagement sollten vom Live-Verkehrsrouting entkoppelt werden, um globale Bereitstellungen mit regionaler Fehlerisolierung zu ermöglichen.
Das AI Gateway von TrueFoundry verkörpert alle oben genannten Designprinzipien und wurde speziell für niedrige Latenz, hohe Zuverlässigkeit und nahtlose Skalierbarkeit entwickelt.
Die KI-Gateway-Architektur von TrueFoundry
Basiert auf Hono Framework: Das Gateway nutzt Hono, ein minimalistisches, ultraschnelles Framework, das für Edge-Umgebungen optimiert ist. Dies gewährleistet einen minimalen Laufzeitaufwand und eine extrem schnelle Anforderungsbearbeitung.
Keine externen Aufrufe auf dem Anforderungspfad: Sobald eine Anfrage das Gateway erreicht, löst sie keine externen Aufrufe aus (es sei denn, das semantische Caching ist aktiviert). Die gesamte Betriebslogik wird intern verarbeitet, wodurch das Risiko reduziert und die Zuverlässigkeit erhöht wird.
In-Memory-Durchsetzung: Alle Entscheidungen über Authentifizierung, Autorisierung, Ratenbegrenzung und Lastverteilung werden mithilfe von In-Memory-Konfigurationen getroffen, wodurch Reaktionszeiten von unter einer Millisekunde gewährleistet werden.
Asynchrone Protokollierung: Protokolle und Anforderungsmetriken werden asynchron in eine Nachrichtenwarteschlange übertragen, um sicherzustellen, dass die Datenbeobachtbarkeit den Anforderungspfad nicht blockiert oder verlangsamt.
Ausfallsicheres Verhalten: Selbst wenn die externe Protokollierungswarteschlange ausgefallen ist, schlägt das Gateway keine Anfragen fehl. Dies garantiert Verfügbarkeit und Widerstandsfähigkeit bei teilweisen Systemausfällen.
Horizontal skalierbar: Das Gateway ist CPU-gebunden und zustandslos, was eine einfache Skalierung ermöglicht. Es arbeitet effizient bei hoher Parallelität und geringem Speicherverbrauch.
Das KI-Gateway von True Foundry
Unterstützung mehrerer Anbieter: Einfaches Hinzufügen und Verwalten von Modellen aus AWS, GCP, OpenAI, Anthropic, DeepInfra und benutzerdefinierten/selbst gehosteten Optionen.
Unified Playground: Testen und führen Sie Aufforderungen für jedes Modell über eine einzige Oberfläche aus. API-Schlüssel und Modellnamen sind konfigurierbar, ohne dass Codeänderungen erforderlich sind.
Prompt Management mit Guardrails: Zeigt in Echtzeit die Schwärzung sensibler Daten während der sofortigen Übermittlung an und ist in den zentralen Guardrails-Server integriert.
Detaillierte Metriken und Beobachtbarkeit:
Live-Tracking, wer welches Model anruft.
Detaillierte Latenzstatistiken, einschließlich „Zeit bis zum ersten Token“ und „Latenz zwischen den Token“ (entscheidend für die LLM-Leistungsüberwachung).
Statistiken zu Ratenbegrenzung, Fallback und Guardrail-Trigger.
Auditprotokolle aller Anfrage-Antwort-Paare, die zur Einhaltung der Vorschriften exportiert werden können.
Konfigurierbare Admin-Einstellungen: Definieren Sie Ratenlimits pro Entwickler oder Team, legen Sie Fallback-Richtlinien und latenzbasiertes Routing fest und verwalten Sie die Leitplanken zentral.
Roadmap zur MCP Server-Integration: Vorschau auf kommende Funktionen, die alle internen MCP-Server für Tools wie Gmail, Slack, Confluence, Jira, GitHub und benutzerdefinierte APIs unterstützen.
Live-Fragen und Antworten: Umgang mit Skalierbarkeit, Integration und technischen Fragen
Die Sitzung endet mit Publikumsfragen zu folgenden Themen:
Gateway-Skalierbarkeit: Konzipiert für horizontale Skalierbarkeit; Leistungsbenchmarks zeigen, dass eine CPU 350 Anfragen pro Sekunde (RPS) verarbeiten kann, weshalb für höhere Raten Scale-Out-Bereitstellungen erforderlich sind.
Latenz und Stabilität: Das Gateway bietet Rückruf- und Wiederholungsmechanismen für eine höhere Zuverlässigkeit und wechselt automatisch zwischen den Modellen, wenn Anbieter mit Ausfällen konfrontiert werden.
Größenbeschränkungen für Modelleingaben: Modelle können extrem große Eingaben (z. B. 500 MB) nicht verarbeiten; es wird empfohlen, RAG-Systeme (Retrieval-Augmented Generation) zu verwenden.
Framework-Integrationen: Kompatibel mit wichtigen Frameworks zur Agentenerstellung wie LangChain und LangGraph unter Verwendung von Standard-OpenAI-kompatiblen APIs, ohne dass spezielle SDKs erforderlich sind.
Unterstützung für Programmiersprachen: Gateway basiert auf leistungsstarken, schlanken Frameworks (Hono, ähnlich denen, die in Cloudflare-Workern verwendet werden) und ist sprachunabhängig für API-Clients (Python, JavaScript, Go usw.).
Schnelle Anpassung an neue Modell-APIs: Kontinuierliche Updates zur Unterstützung herstellerspezifischer Parameter und multimodaler Eingaben mit strenger Dokumentation.
Governance- und Audit-Tools: Möglichkeit, detaillierte Latenz-, Nutzungs- und Kostendaten für Audits zu exportieren, die auf die Anforderungen der Unternehmensführung abgestimmt sind.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last




































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




