

June 25, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 25, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
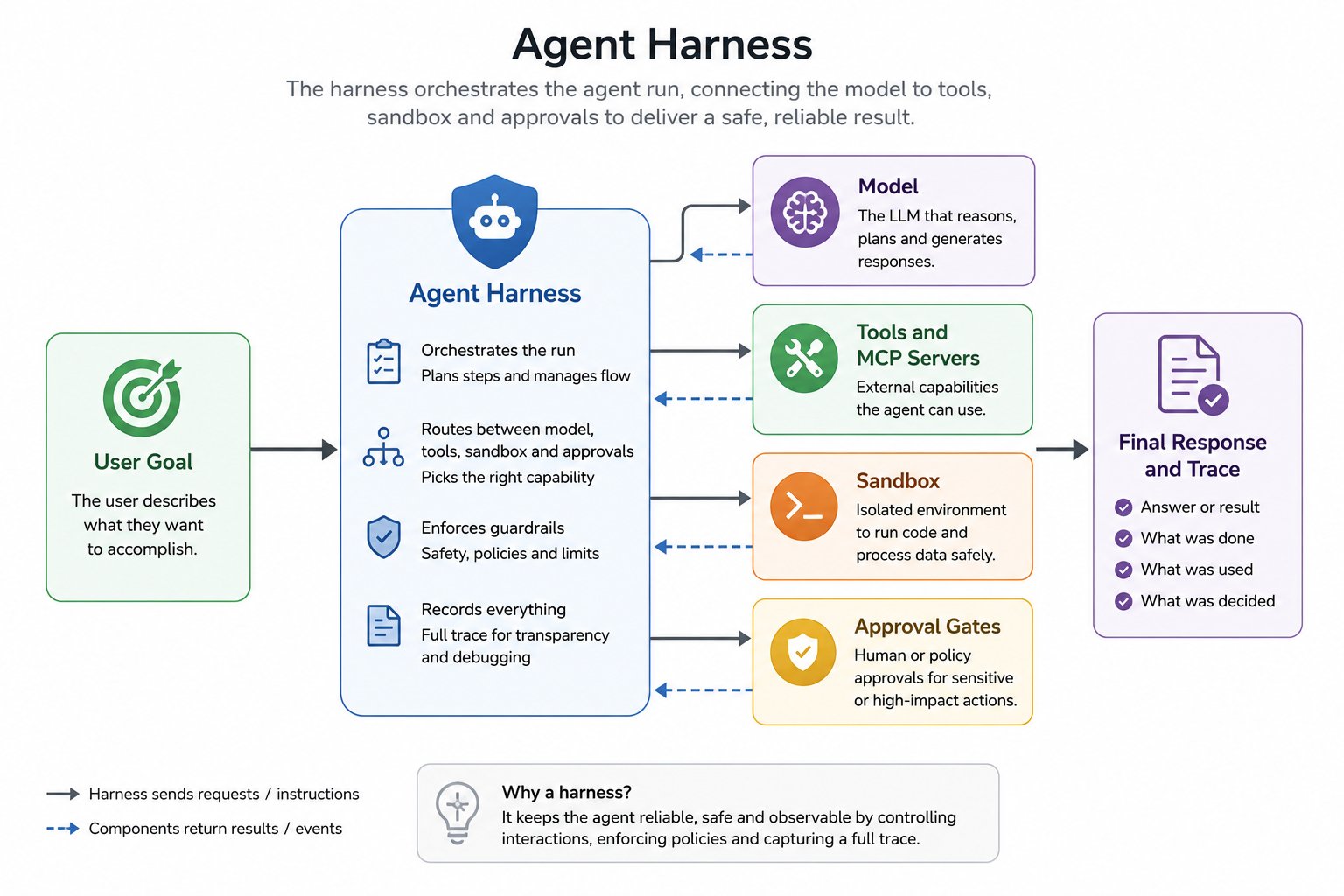
The agent field has a vocabulary problem. After a season in which "harness," "scaffold," "skill," and "agent" meant something different in every conversation, Hugging Face published a widely shared glossary that gives the field a useful working vocabulary. It's worth reading. But a glossary answers "what does this word mean?" — and the next question, the one platform teams actually live with, is "where does this thing live in my stack?" This post takes that working vocabulary and maps every term to the piece of production infrastructure that implements it. The words come from an emerging community vocabulary; the wiring is what production teams have to make concrete.
Elif, a platform engineering lead, watched a steering meeting eat forty minutes on a question that shouldn't have needed five: "how many agents do we have?" Engineering counted harness deployments and said nine. The data team counted prompts-with-tools and said thirty-something. A vendor slide counted every workflow with an LLM call and said two hundred. Nobody was wrong by their own definition; nobody shared a definition. The same meeting tripped over whether a "skill" was a tool, whether the new "sub-agent" was an agent for inventory purposes, and what exactly the team was buying when a product said "harness included." Elif's conclusion wasn't that her colleagues were sloppy. It was that the field's words had moved faster than its shared understanding — and that until the words were pinned to things in the stack, every architecture conversation would secretly be a vocabulary fight.
The community has been working to clarify these definitions — most visibly in Hugging Face's agent glossary, which grew out of exactly this confusion at ICLR 2026 and which we'll lean on (and credit) throughout. What this post adds is the second column Elif needed: for each term, the production component that implements it, and the governance that attaches to it once it's real infrastructure rather than a diagram label. This is not a replacement for the Hugging Face glossary; it's the infrastructure column next to it. We'll walk the stack from the inside out — model, scaffold, harness, agent — then the working vocabulary around it: context engineering, the tool/skill/sub-agent spectrum, policy, and the training terms that turn out to matter in production too. Four deep dives follow this post; this is the map.
Start where the glossary starts. The model is the LLM itself: text in, text out, no memory between calls, no loop, no ability to actually execute anything. It can express the intent to call a tool — emit a structured request — but something outside it has to run that tool and feed the result back. Calling the model "the agent" is the original category error: the model is the reasoning engine, and on its own it answers one prompt and stops.
In production terms, the model is also the most interchangeable part — which is precisely why it should sit behind an abstraction. On TrueFoundry, models are addressed by name through the AI Gateway's single OpenAI-compatible API: commercial frontier models, self-hosted open-weight models, and fine-tuned checkpoints behind a common gateway interface, with RBAC, budgets, observability, and guardrails applied centrally where traffic flows through the gateway. The architectural consequence of "the model is just one component" is that swapping it should be a configuration change — the subject of our unified-API post — and everything else in this glossary is what stays put when you swap it.
Here's the distinction the glossary exists to make, and the one that causes the most confusion in practice. The scaffold is the behavior-defining layer the model works from: the system prompt, the tool descriptions, the output formats it's asked to follow, the rules for what gets carried across steps. It shapes how the model sees its world. The harness is the execution layer that makes the agent run: the loop that calls the model, parses its tool requests, actually executes them, feeds results back, handles errors, and decides when to stop. Scaffold is instructions; harness is machinery. Products like Claude Code often use "harness" loosely for everything that isn't the model, which is fine as shorthand — the distinction earns its keep when you have to reason about the layers separately, and in production you constantly do: a prompt edit is a scaffold change you can ship in minutes; a change to stop conditions or error handling is a harness change with blast radius.
On TrueFoundry the two layers have two different homes, which is itself clarifying. Scaffold artifacts — instructions, prompt versions, tool descriptions, skills — are managed content: versioned, reviewable, RBAC-controlled. The harness is the managed runtime: TrueFoundry's Agent Harness runs the plan→act→observe loop, executes tools through governed gateways, manages the sandbox, enforces approval gates, and records the steps of governed Agent Harness runs. You author the scaffold; the platform operates the harness. The deep dive that follows this post is entirely about that split and the discipline the community now calls harness engineering.
With those two layers named, the agent stops being mystical: an agent is a model plus everything around it that lets it act rather than just respond — the framing the community compresses to agent = model + harness. The lineage is reinforcement learning, where an agent is simply the thing that takes observations and returns actions in a loop; the LLM version keeps that loop and fills the "decide" step with a model. Two practical consequences fall out of the equation, and both are worth internalizing.
First, what users experience as an “agent product” is often the harness and scaffold around the model. When two products built on the same underlying model feel completely different, the difference is the harness and scaffold — their loop design, their context management, their tool sets. The model, the harness, and the product are three different things, and evaluating "an agent" without saying which harness it ran in is close to meaningless. Second, inventory becomes possible. Elif's "how many agents do we have?" has an answer once an agent is a concrete, registered thing: a definition (model + scaffold + tool grants) plus a runtime. For agents run through TrueFoundry’s Agent Harness, the agent becomes a registered definition referencing a model, MCP servers, and skills by name, with credentials kept in the gateway plane rather than embedded in the definition — which makes the governed portion of the agent estate countable and auditable instead of a vocabulary debate.
An agent definition, annotated with the glossary (illustrative)
agent:
name: ticket-triage
model: ticket-triage-default # MODEL — by name, resolved at the AI Gateway
instructions: ./instructions.md # SCAFFOLD — versioned content the model works from
mcp_servers: [jira, slack] # TOOL USE — governed at the MCP Gateway
skills: [triage-runbook@v3] # SKILL — versioned procedure from the registry
subagents: [log-analyzer] # SUB-AGENT — its own context, identity, trace
# The HARNESS is what runs this: the loop, sandbox, approvals, traces.
# The POLICY is the behavior of all of the above, together. No provider or tool credentials in the agent definition.
together. No provider or tool credentials in the agent definition.
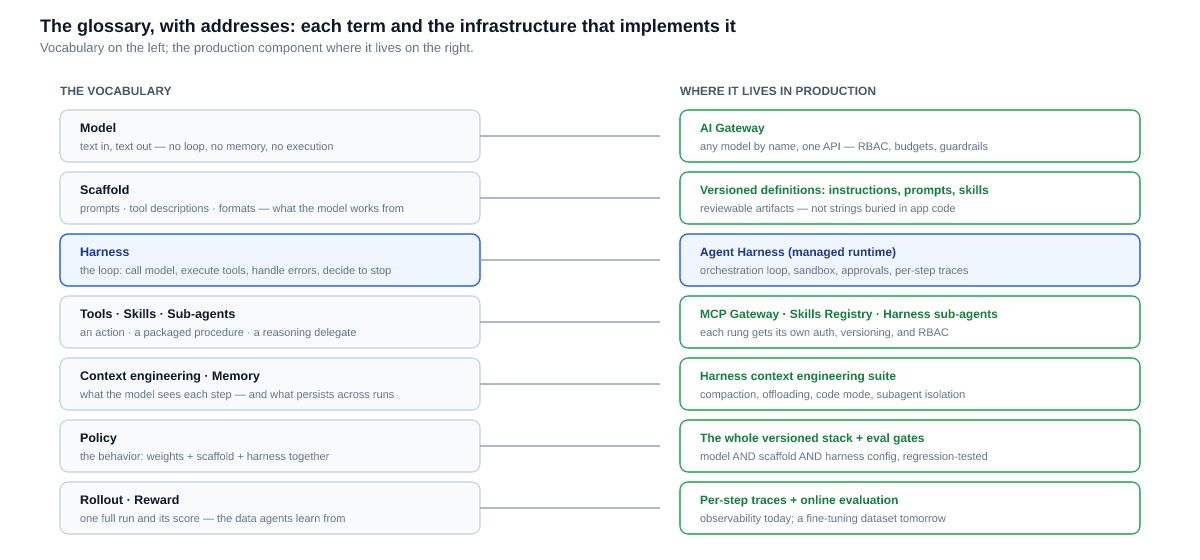
Step back from the runtime and the whole vocabulary lines up the same way: each term on the left is a concept, and each has a concrete production home on the right.
Context engineering is the discipline of deciding what the model sees on every step: which instructions, which tool descriptions, which slice of history, which retrieved facts. It's not a one-time prompt decision, because in an agent the context is alive — every turn's output shapes the next turn's input, and a harness that doesn't actively manage that accumulation watches its agent degrade as the window fills. The glossary splits the memory side cleanly: short-term memory is what stays in the window during a run; long-term memory persists across sessions externally and gets retrieved back in when relevant.
In production this is a harness responsibility, not a prompt-author responsibility — no human can hand-curate a 40-step run's context. TrueFoundry's Agent Harness ships a context-engineering suite that does the curation automatically: compaction summarizes a long transcript and continues; large-result offloading keeps a huge tool response out of the window and loads it on demand; code mode lets the agent process bulky data with code instead of reading it into context; sub-agents (next section) isolate subtasks in fresh windows. We cover the failure mode this prevents — the community calls it context rot — in its own post; here the mapping is the point: "context engineering" names work that, in a managed runtime, the harness does for you.
The glossary's most practically useful clarification is the line between three things that all look like "the agent doing something." A tool is an action: a single function call — run this command, query this API — executed by the harness and fed back. A skill is packaged knowledge: a reusable, structured procedure for a multi-step goal ("investigate the bug, form a hypothesis, write the fix"), loaded into context on demand rather than executed as one call. A sub-agent is a reasoning delegate: an agent invoked by another agent, with its own model, scaffold, and context, that works the subtask independently and returns a result. The line shifts across frameworks — the glossary says so honestly — but the spectrum itself is stable: action, procedure, delegate.
The reason the distinction matters in production is that each rung needs different governance. A tool needs authentication and authorization per call — which is what the MCP Gateway provides: registry, central auth, per-tool RBAC, pre/post-call guardrails. A skill needs versioning and provenance — who wrote this procedure, which version is an agent running — which is what TrueFoundry's Skills Registry provides: versioned SKILL.md artifacts with RBAC, mounted on demand. A sub-agent needs identity and bounded context — its own trace, its own permissions, isolation from the parent's window — which the Agent Harness provides natively. Flatten the spectrum into "tools" and you'll govern a reasoning delegate like a function call; the deep dive on this spectrum takes each rung apart.
Policy is the glossary's quietest term and, for operating teams, maybe its most important. Borrowed from RL, a policy is the behavior itself — for any situation, what the system will do. The crucial sentence is that in LLM agents, only part of the policy is in the model weights: the rest is determined by the scaffold and the harness. The same checkpoint behind a different system prompt, different tool descriptions, or a different loop is, behaviorally, a different policy. A policy is not an agent — the policy is the behavior; the agent is the deployed system whose behavior it is.
Take that seriously and a common operational habit collapses: tracking "which model version is in prod" as if it answered "what will the system do." It answers a third of the question. The production translation of "policy" is that the entire behavior-determining stack — model name, prompts, tool set and descriptions, skills, harness configuration — is one versioned thing, changed deliberately and regression-tested together, because a one-line prompt edit is a policy change exactly as a model swap is. That's the argument of the fourth post in this series; the infrastructure that makes it tractable is definitions-as-artifacts (the Agent Harness's declarative agent definition), prompt versioning, and the online evaluation loop that catches a behavior shift whichever layer caused it.
The glossary's last section covers RL training vocabulary — environment, trainer, rollout, reward — and it's tempting for a production team to skip it. Don't, because two of the terms describe things you already have. A rollout is one full agent run, end to end: what the agent saw, what it did, what came back, step by step. Production teams call that a trace. A reward is the score that says whether a run was good — verifiable (tests pass, answer matches) or learned (preferences, LLM-as-judge). Production teams call that an eval signal. The training pipeline and the production loop are the same shape; one updates weights and the other updates dashboards.
The consequence is worth sitting with: if your harness records complete, per-step traces and your evaluation layer scores them, you are already collecting the raw material for rollout/reward datasets — traces plus quality signals that can be curated for fine-tuning or RL-style improvement. Teams that self-host open-weight models (our self-hosting post) can close that loop deliberately: traces from the Agent Harness, scores from the eval layer, fine-tuning on TrueFoundry, the improved checkpoint deployed behind the same gateway name. The final post in this series is that loop in full. The vocabulary lesson is simpler: "rollout" and "reward" aren't someone else's training jargon — they're your observability, seen from the future.
Elif's forty-minute meeting wasn't wasted by ignorance; it was wasted by ambiguity, and ambiguity in vocabulary becomes ambiguity in systems. When "agent" has no fixed referent, the agent inventory can't exist. When "harness" might mean a product, a loop, or everything-but-the-model, a buy-versus-build conversation about harnesses is three conversations wearing one trench coat. When "skill" and "tool" blur, the governance model blurs with them — and unguarded capability is exactly how the sprawl and shadow-agent problems start. Pinning the words is the cheap first step toward pinning the architecture.
The mapping this post adds is the second step: every term should have an address. On TrueFoundry, it does — models behind the AI Gateway, tools behind the MCP Gateway, skills in the Skills Registry, the loop and sub-agents in the Agent Harness, context engineering as harness machinery, policy as the versioned whole, rollouts as traces feeding evaluation. None of that requires TrueFoundry specifically; it requires some concrete answer to "where does this word live, and who governs it there." The four posts that follow take the richest terms one at a time: harness versus scaffold, the tool/skill/sub-agent spectrum, policy as the thing you actually version, and the rollout-to-reward loop in production.
Is "agent = model + harness" the official definition? There's no official body, and the glossary itself is careful to say many terms lack universally accepted definitions — different frameworks genuinely use the same words differently. It's better read as a useful working model, and a usable one: it cleanly separates the reasoning engine from the machinery that makes it act, which is the separation production architecture needs. Treat it as a working model, credit the source, and expect refinement.
Where does the scaffold end and the harness begin? The cleanest line: scaffold is what the model works from (prompts, tool descriptions, formats — content), harness is what makes the agent run (the loop, execution, error handling, stopping — machinery). Products often say "harness" for both, which is fine until you need to change one without the other. In practice the line is also an ownership line: authors own scaffold; the platform owns the harness.
Is a sub-agent just a tool from the caller's perspective? Mechanically it's often invoked like one, which is why the terms blur. The difference is what's on the other side: a tool executes a function; a sub-agent reasons — it has its own model, scaffold, context, and possibly its own tools. That difference is invisible to the calling code and enormous to governance: a sub-agent needs identity, permissions, and tracing of its own, not just an entry in the parent's tool list.
Do production teams really need the RL terms? Two of them, yes. In production terms, a rollout looks like a trace and a reward looks like an eval score — vocabulary for things you already produce. Knowing the training framing matters the day you want your agents to improve from their own history: complete traces plus quality scores are the raw material, and teams that captured them well have a dataset where others have logs.
Does standardizing vocabulary actually change anything technical? Indirectly but materially. Shared terms make the inventory countable ("agent" = registered definition + runtime), make procurement comparable (every "harness included" claim decomposes into loop, sandbox, approvals, traces), and make governance assignable (each term's address has an owner). Elif's meeting problem was a systems problem that looked like a semantics problem — they usually are.
A glossary is a map legend; this post tried to draw the map. The community's vocabulary — model, scaffold, harness, agent, skill, sub-agent, policy, rollout, reward — turns out to describe a production architecture remarkably well, term by term, as long as every term gets an address. Give it one, and the words stop being the argument and start being the design.
Elif is an illustrative composite, not a specific person, organization, or incident. Definitions in this post are paraphrased from, and credited to, Hugging Face's agent glossary (May 2026) plus the broader community discussion it cites; the glossary itself notes that many terms lack universally accepted definitions and usage varies across frameworks. TrueFoundry capabilities referenced reflect public product documentation at the time of writing; verify specifics against current docs.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.webp)
.webp)





.webp)
.webp)
.webp)