













June 24, 2026
|
5 min read

Published: June 24, 2026

Blazingly fast way to build, track and deploy your models!
There's a moment in most enterprise AI programs when a workload appears that can't send its data to a third-party API — a regulated dataset, a sovereignty requirement, a cost curve that's gotten frightening at scale. The answer is an open-weight model you run yourself. The reason teams dread it isn't the model; it's that self-hosting usually means a second, different stack — a non-OpenAI API, a serving layer, GPU operations — bolted onto a platform built around commercial APIs. This post is how a gateway collapses that, making a self-hosted Llama or Mistral a drop-in alongside the commercial models you already call.
Ravi, an ML platform engineer, got the request he'd been expecting: a new workload would process records that, by policy, could not leave the company's cloud. No commercial API was an option. An open-weight model running in their own VPC was the obvious answer — and Ravi's heart sank a little, because the application that needed it was written against the OpenAI API, the team had no serving stack, and he could already picture the parallel universe of a second SDK, a second set of dashboards, and a GPU autoscaling problem nobody had solved. The model was the easy decision. The stack around it was the dread.
What changed Ravi's week was realizing the self-hosted model didn't have to be a different stack at all. If it sat behind the same gateway as the commercial models, speaking the same OpenAI-compatible API, then to the application it was just another model name — and to the platform it was one more endpoint governed by the same rules. The sovereignty requirement got met without forking the architecture. This post is how that works, and where the genuine engineering still lives.
Self-hosting an open-weight model is rarely about quality — frontier APIs are excellent and improving. It's about four other things. Sovereignty: some data legally or contractually cannot leave your environment, which a model running in your VPC or on-prem satisfies by construction. Cost at scale: past a certain steady volume, amortized GPUs can undercut per-token pricing, especially for high-throughput, predictable workloads. Control: you choose the model version, can fine-tune on proprietary data, and aren't subject to a provider deprecating or changing a model under you. Availability: your inference path is no longer directly tied to a model API provider's uptime — though it now depends on your own infrastructure and deployment supply chain.
The honest counterweight is that you now own inference operations: GPU capacity, the serving stack, scaling, and reliability — work that a commercial API hides entirely. Self-hosting is worth it when one of those four drivers is real and the operational cost is contained. Most enterprises end up hybrid: commercial APIs for general traffic, self-hosted models for the sovereign or high-volume slices. The goal isn't to replace one with the other; it's to run both without running two of everything.
Customization deserves to be pulled out of that list, because it's often the driver that tips a team toward open weights specifically. A commercial API gives you a model someone else trained for everyone; an open-weight model you can adapt to your domain, your formats, your tone, and your edge cases by fine-tuning on data you can't or won't send anywhere. For narrow, repetitive tasks a smaller fine-tuned open model can match or beat a much larger general one at a fraction of the serving cost — which folds the customization driver back into the cost one. The catch is that fine-tuning is its own pipeline: data preparation, training runs, evaluation, versioning, and then serving the result like any other model. TrueFoundry supports both no-code and full-code fine-tuning alongside its serving stack, so a tuned model lands behind the same gateway endpoint as everything else rather than becoming a separate artifact you have to operationalize by hand. The point isn't that fine-tuning is always worth it — it frequently isn't, and a good base model with strong prompting often wins — but when it is, owning the weights is what makes it possible at all.
One caveat belongs in this decision, not after it: open-weight does not mean obligation-free. Before you self-host or fine-tune, verify the model's license, acceptable-use policy, redistribution terms, attribution requirements, and any restrictions on regulated or commercial use — some popular open-weight models carry usage thresholds or field-of-use limits that matter at enterprise scale. Treat the license review as part of the deployment checklist, not a footnote discovered after the model is already in production.
Ravi's dread was well founded, because the naive way to self-host produces exactly that second stack. The open-weight model exposes its own API shape, so the application needs a code path for it. It needs a serving engine, which is its own operational surface. It needs GPU autoscaling, which behaves nothing like scaling a stateless web service. And it needs its own observability, because the commercial-API dashboards don't see it. Multiply that by a few models and you have a parallel platform whose only job is to be different from the one you already run.
The insight that defuses this is that almost none of that difference needs to reach the application or the platform's control surface. The serving engine and GPU scaling are real and unavoidable — they're the genuine work of self-hosting. But the API shape, the routing, the governance, and the observability can be made identical to the commercial path by putting the same gateway in front. The rest of this post separates the difference that's essential (serving, GPUs) from the difference that's accidental (everything the gateway can absorb).
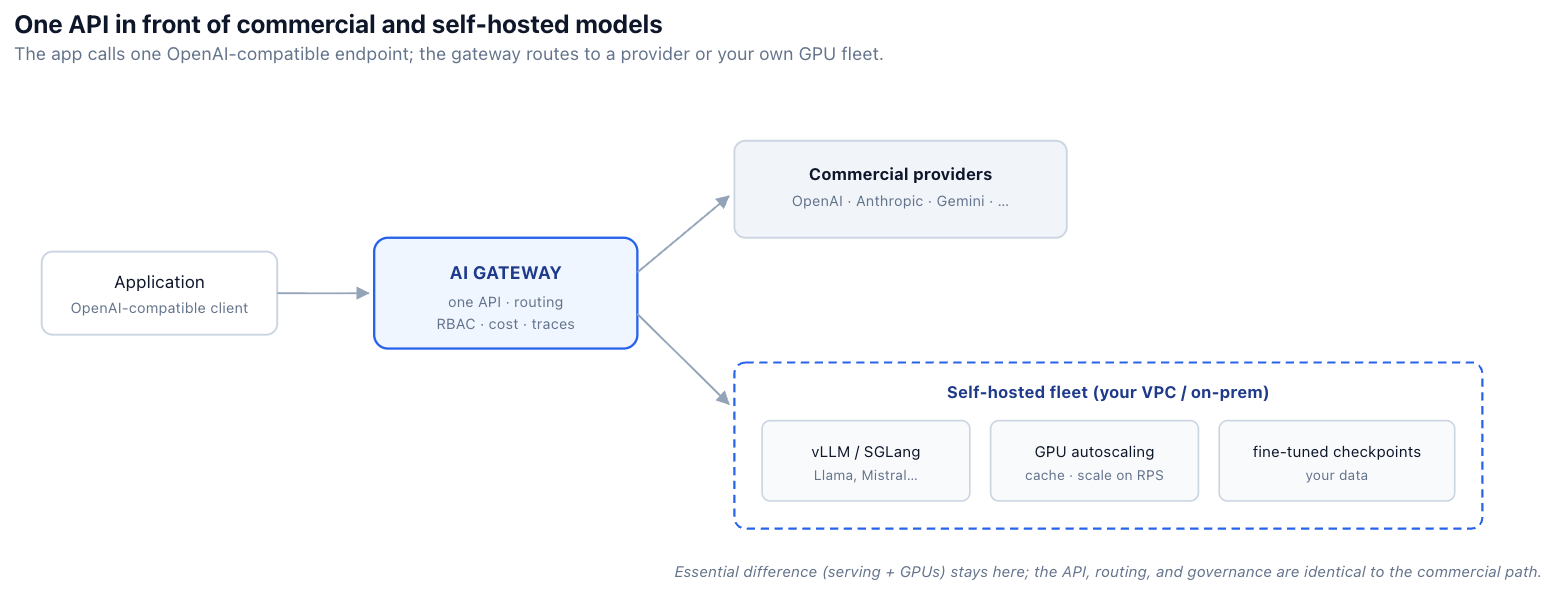
The move that makes self-hosting painless is exposing the self-hosted model through the same OpenAI-compatible API the application already speaks. When a self-hosted Llama answers the same request shape as a commercial model, switching between them is a configuration change, not a code change — and routing, fallback, RBAC, budgets, and tracing all apply uniformly because, from the gateway's perspective, it's just another model behind the same interface.
Same client, same call — only the model name changes (illustrative)
# Commercial model:
client.chat.completions.create(model="commercial-chat-model", messages=msgs)
# Self-hosted open-weight model — same API, same code, different name:
client.chat.completions.create(model="llama-3-70b-internal", messages=msgs)
# The gateway resolves the name to a commercial provider or your GPU fleet,
# and applies the same routing, RBAC, budgets, and tracing either way.This is the same unification our routing post covers, applied to the self-hosted case: the application is decoupled from where a model physically runs. Ravi's regulated workload points at a self-hosted model name; everything else in his platform keeps working unchanged. TrueFoundry's AI Gateway is built to be exactly this central interface for both self-hosted and third-party models.
Here's the difference that's genuinely yours to own. An open-weight model doesn't serve itself; it runs inside an inference engine, and the engine you pick materially affects throughput, latency, and memory efficiency. vLLM popularized continuous batching and paged attention for high throughput; SGLang is strong on structured and high-concurrency workloads; TGI is a mature, widely deployed server; and TRT-LLM (Triton) squeezes hardware-specific performance on NVIDIA GPUs. None is universally best.
The discipline that matters is benchmarking: run your actual model, at your actual sequence lengths and concurrency, on candidate engines and GPUs, and choose on the numbers rather than the reputation. TrueFoundry’s LLM deployment docs list vLLM, SGLang, and TRT-LLM as supported model servers (TGI and Triton appear among the gateway’s self-hosted backends), and the platform aims to pick a sensible GPU configuration for a given model automatically — which turns “which engine and how many GPUs” from a research project into a choice you validate against your own benchmarks. The engine is essential complexity; the goal is to make selecting and operating it routine.
Autoscaling a self-hosted LLM is not like autoscaling a web service, for one stubborn reason: the weights are huge — anywhere from a few gigabytes to well over a hundred. A naive autoscaler that downloads a 100 GB model every time it adds a replica will spend minutes and serious network cost before the new pod serves a single token, which makes scaling up during a traffic spike almost useless. Cold start is the defining operational problem of self-hosted inference.
The fixes are unglamorous and decisive. Model caching downloads the weights once and mounts them to every pod, so a new replica starts from a local copy instead of a fresh download. Image streaming pulls the serving image far faster than a cold pull. Shared model volumes keep the weights out of each image entirely. Together these can move a cold start from “download everything from scratch” toward a scale-up path fast enough that RPS-based autoscaling tracks demand — though the actual startup time still depends on model size, storage class, registry location, node warmth, and GPU scheduling. TrueFoundry’s docs describe model caching (weights downloaded once and mounted to every pod), image streaming for markedly faster vLLM and SGLang image pulls, and shared volumes for precisely this reason; it's the difference between autoscaling that works and autoscaling that's theoretical.
Self-hosting also moves supply-chain responsibility closer to you. The weights, the serving image, and their dependencies are now artifacts you own and ship. Pin model and image versions rather than tracking a moving tag, verify checksums or signatures where the source provides them, control who can publish model checkpoints and serving images to your registry, scan those images like any other production container, and keep a rollback path for both the engine and the weights. The gateway governs who may call the model; this is the discipline that governs what you're actually running behind it.
A self-hosted model as a governed deployment (illustrative config)
name: llama-3-70b-internal
model: meta-llama/Llama-3-70B # from Hugging Face / private registry
server: vllm # or sglang / tgi / trt-llm — benchmark first
gpu: { type: H100, count: 2 }
cache: shared_volume # download once, mount to all pods
autoscaling:
metric: rps # scale on requests/sec
min_replicas: 1
max_replicas: 8
scale_to_zero_after: 30m # idle policy — release GPUs when unused
Self-hosting unlocks an optimization that commercial APIs largely hide from you: control over how requests map to GPUs. When a model processes a sequence, it builds a key-value cache of its attention computations. If the next request shares a prefix — the same system prompt, the same conversation so far — routing it to the same GPU instance lets the engine reuse that cached computation instead of recomputing it, which cuts latency meaningfully on prefix-heavy traffic.
Capturing that benefit requires prefix-aware sticky routing: the gateway routes requests with a shared prefix to the same instance rather than spreading them round-robin. TrueFoundry’s docs describe exactly this — sticky routing that sends requests with the same prefix to the same GPU machine to leverage KV-cache optimization — the self-hosted, GPU-level cousin of the gateway-level semantic caching in our caching post. One reuses computation inside the serving engine; the other reuses whole responses at the gateway. On conversational or shared-system-prompt workloads, the two compound.
Once self-hosted and commercial models live behind one API, the routing and reliability machinery from earlier in the series applies to the whole fleet at once. You can route a sovereign workload to the self-hosted model by policy, send general traffic to a commercial API, and — crucially — fall back across the boundary: if the self-hosted fleet is saturated during a spike, burst to a commercial model rather than queueing, and if a provider has an outage, fail over to the self-hosted model.
Routing that treats self-hosted and commercial as one fleet (illustrative)
routes:
- match: { tag: "regulated" } # sovereignty: must stay in-VPC
target: llama-3-70b-internal
fallback: [] # no commercial fallback for this class
- match: { tag: "general" }
target: llama-3-70b-internal # prefer self-hosted for cost
fallback: [commercial-chat-model] # burst to commercial under load/outageThis is the routing and failover from Blogs 11 and 12, now spanning the commercial/self-hosted seam — with one important constraint made explicit in policy: a regulated route must not fall back to a commercial provider, because availability never overrides sovereignty. Encoding that as a rule, rather than trusting everyone to remember it, is the kind of guardrail the gateway exists to enforce.
The throughline is that self-hosting splits cleanly into two kinds of work. The essential kind — the serving engine and the GPUs — is real, and the next post in this pair is about its economics. The accidental kind — a different API, separate routing, separate governance, separate observability — is what the gateway absorbs by being the single seam between your applications and every model, wherever it runs.
Put the gateway there and a self-hosted model stops being a parallel platform and becomes one more governed endpoint: same OpenAI-compatible API, same routing and fallback rules, same RBAC and budgets, same traces. TrueFoundry is built around exactly this division — high-performance serving on vLLM, SGLang, TGI, and TRT-LLM with the GPU and caching machinery to make it operable, fronted by an AI Gateway that makes the result indistinguishable from a commercial model to everything upstream. For Ravi, that's the difference between meeting a sovereignty requirement and rebuilding his platform to do it.
Is self-hosting cheaper than a commercial API?
Sometimes, past a threshold. For steady, high-volume, predictable traffic, amortized GPUs (especially with fractional sharing and spot capacity) can undercut per-token pricing; for spiky or low-volume traffic, a commercial API is usually cheaper because you're not paying for idle GPUs. The honest answer is to model your own volume — which is the subject of the GPU-economics post that pairs with this one. Cost is one of four reasons to self-host, not the only one.
Do I have to rewrite my application to use a self-hosted model?
Not if the model is fronted by an OpenAI-compatible gateway. The application keeps calling the same API and only the model name changes; the gateway resolves that name to your GPU fleet and applies the same routing, RBAC, and tracing as for commercial models. The whole point is that the application doesn't know or care where the model runs.
Which serving engine should I use?
Benchmark to decide — there's no universal winner. The documented backends — vLLM, SGLang, TRT-LLM, plus KServe and Triton — differ in throughput, latency, memory efficiency, and feature support, and the right choice depends on your model, sequence lengths, and concurrency. Run your real workload on candidates and choose on the measured numbers. A platform that supports all of them lets you switch without re-architecting.
What's the hardest operational part?
Cold starts. LLM weights are large, so an autoscaler that re-downloads the model per replica is too slow to track demand. Model caching, image streaming, and shared volumes are what make scaling practical — they turn a multi-minute cold start into something fast enough that RPS-based autoscaling and scale-to-zero idle policies actually work.
Can I mix self-hosted and commercial models?
That's the common end state, and it's the strength of fronting both with one gateway. Route sovereign or high-volume traffic to self-hosted models, general traffic to commercial APIs, and fail over across the boundary under load or outage — with the explicit exception that regulated routes must not fall back to a commercial provider. One fleet, one set of rules, two kinds of backend.
Ravi's sovereignty problem never required a second platform; it required one model to run somewhere specific and everything else to stay the same. That's what a gateway buys you: the freedom to put a model wherever sovereignty, cost, control, or availability demands, while the application and the platform see one consistent surface. Own the serving and the GPUs — they're the real work — and let the gateway absorb the rest.
Ravi is illustrative. TrueFoundry serving and gateway capabilities — supported inference engines, model caching, image streaming, prefix-aware sticky routing, and autoscaling — are summarized from public product documentation as of mid-2026 and will evolve; verify specifics against current docs. Cost comparisons between self-hosted and commercial models depend entirely on your own volume and hardware and should be modeled directly. Code and configuration samples are illustrative of the documented patterns, not copied from a reference implementation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)

.webp)







.webp)
.webp)
.webp)
.webp)
.webp)
