July 24, 2026
|
5 min read

Published: June 9, 2026

Blazingly fast way to build, track and deploy your models!
Picking a model is the easy part. Picking the tools is the next easy part. The hard part — the part that decides whether your agent is reliable or a liability — is everything around the model: the loop that plans, acts, and observes; the sandbox that runs its code; the gates that stop it before a destructive action; the trace that explains what it did. That runtime layer is the agent harness, and it's the real build-versus-buy decision in agentic AI. This post is what a harness is, what makes one production-ready, and why a managed harness keeps credentials out of agent definitions.
Sofia, a platform engineer, inherited three teams' worth of agents and a request to make them production-ready. Each team had built its own runtime around the model. One hand-rolled an orchestration loop in Python; another wrapped a framework; the third called the model directly in a cron job. Provider API keys were pasted into agent configs and committed to repos. Approvals for sensitive actions ranged from a Slack message to nothing at all. Two of the three had no usable trace of what an agent actually did on a given run. Sofia's job wasn't to give these agents better models or more tools — they had those. It was to give them the thing none of them had built well: a common, governed runtime. She was missing a harness.
This is where most teams arrive after the first agent demo works. The demo proves the model and the tools; production demands the runtime around them — and that runtime is large, security-sensitive, and almost entirely undifferentiated from one agent to the next. Building it three different ways, as Sofia's teams did, is how you end up with three different sets of problems. This post is about the layer that solves all three at once.
An agent harness is the runtime layer around an LLM that turns it from a text generator into a reliable, long-running agent. Instead of a single model call, the harness manages the full execution loop: it plans, calls a tool, observes the result, and decides whether to continue or stop — repeating until the goal is met or a limit is hit. Around that loop sits everything the loop needs to be safe and useful: tool routing and execution for APIs, MCP tools, and code; memory and context controls for long tasks; security boundaries like sandboxing, credentials, and permissions; human-in-the-loop gates for sensitive actions; and tracing, logs, metrics, and cost visibility.
The word "harness" is well chosen: it's the rigging that lets you put a powerful, somewhat unpredictable thing to work without it running away. None of these pieces is the model, and none is the tool — they're the scaffolding that makes the model-plus-tools combination dependable. That scaffolding is what Sofia's teams each rebuilt, badly, in isolation.
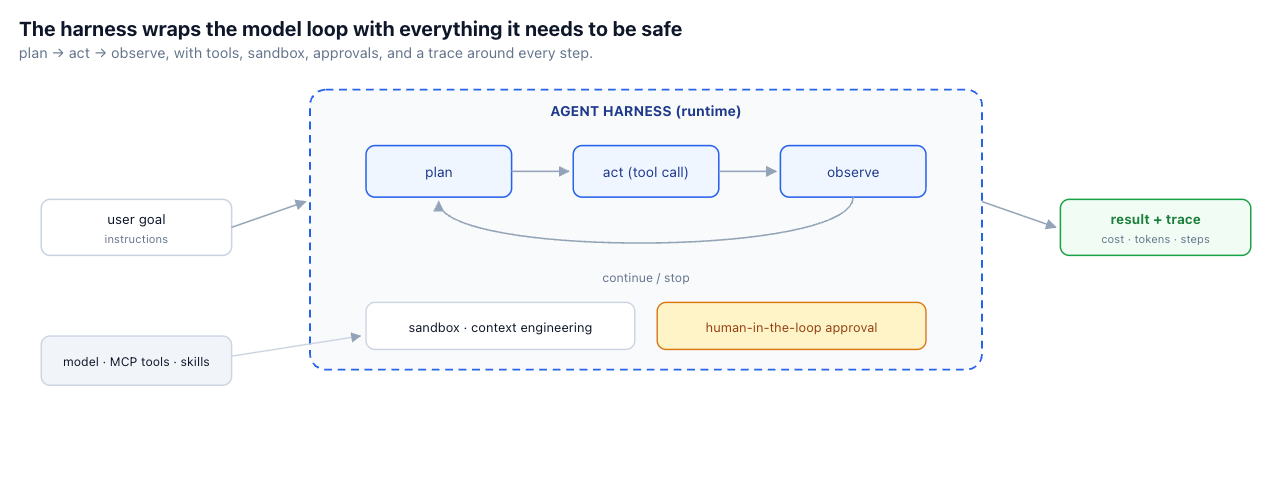
Here's the uncomfortable arithmetic of agentic AI: the model is a few lines of API call, the tools are a registry away, and the harness is the rest of the system. The orchestration loop with its stopping conditions, the sandbox with its lifecycle, the credential handling, the approval gates, the per-step tracing and cost accounting — that's where the engineering months go, and almost none of it is specific to your use case. It's undifferentiated heavy lifting, rebuilt every time a team starts an agent from scratch.
That's the trap Sofia's three teams fell into independently. Each spent real effort on runtime plumbing instead of on the agent's actual job, and each produced a different, partial version with its own gaps — the committed API key, the missing approval gate, the absent trace. Buying the harness (or adopting a managed one) is the decision to stop rebuilding the plumbing and standardize it once, so teams spend their effort on instructions, tools, and skills — the parts that are actually theirs.
TrueFoundry's Agent Harness is a managed harness built on top of the AI Gateway and MCP Gateway. The builder's mental model is deliberately small: you choose a model, connect MCP servers, add skills, and write instructions. TrueFoundry provides the rest as managed capabilities — orchestration, sandbox lifecycle, tool execution, approval flows, governance, and observability — while teams still own the agent's instructions, tools, policies, and deployment posture. There's a no-code builder in the console for non-developers and a Python SDK and REST API for the same agent definition, so the path from "pick a model" to "working agent" is short, and the same definition can be driven from code.
An agent defined declaratively — model, tools, skills, instructions (illustrative)
name: refund-assistant
model: claude-sonnet-4-6 # a name, not a key — credentials live in the gateway
mcp_servers:
- zendesk # governed tools, referenced by name
- payments
skills:
- refund-policy@v4 # versioned SKILL.md from the Skills Registry
instructions: |
Resolve refund requests within policy. Confirm any refund over $100 with the user.Notice what's not in that definition: any secret. The model is a name, the MCP servers are names, the skill is a versioned reference. That absence is the whole point of the next section, and it's the difference between an agent definition you can safely commit to a repo and one you can't.
The single most consequential design choice in a harness is where credentials live. The tempting answer — paste the provider key and the tool tokens into the agent definition — is exactly what put Sofia's keys in a repo. It doesn't scale (every agent and every user re-registers secrets), it doesn't rotate cleanly (a key change touches every definition), and it doesn't stay secure (secrets spread to wherever definitions are stored).
TrueFoundry's harness takes the other path: no API keys or credentials are ever pasted into agent definitions. Provider credentials live in the AI Gateway, and agents reference model names while RBAC, budgets, and guardrails are enforced at the gateway. MCP authentication — OAuth tokens, API keys — lives in the MCP Gateway, which handles credential injection, token refresh, and per-user delegation, so users authenticate inline and the agent calls tools by name. Skills are published in the Skills Registry with versioning and RBAC, so agents pick from a governed catalog. Platform teams configure access once; agent builders never handle secrets.
A loop alone isn't production-ready; the capabilities around it are what separate a demo from a system. TrueFoundry's harness combines several, each addressing a failure mode this series has covered.
A sandbox gives the agent a secure environment to run code, handle files, and execute long-running tasks without that code touching the host or sensitive systems directly. Context engineering helps keep the model's window lean — through subagents that isolate subtasks, a code mode that lets the agent manipulate data programmatically instead of stuffing it into the prompt, large-result offloading so a giant tool result doesn't blow the context, and compaction for long runs (the agent-loop counterpart to the gateway-side session management in our context engineering post). Human-in-the-loop gates pause sensitive tool calls and require explicit approval before they execute. Ask-user lets the agent request clarification or offer choices mid-run instead of guessing. And generative UI lets the agent stream structured blocks — cards, tables, charts — that the client renders, rather than returning a wall of text.
Each of these maps to a specific failure the harness is there to prevent — which is the clearest way to see why they're not optional polish:
Running the agent and streaming its progress over the API (illustrative)
session = harness.sessions.create(agent="refund-assistant",
input="Refund order #8842, $240")
for event in session.stream(): # SSE stream of run events
if event.type == "tool_call":
log(event.tool, event.args) # each step is traced
elif event.type == "approval_required": # HITL gate fired
decision = ask_human(event) # pause for explicit approval
session.respond(event.id, decision)
elif event.type == "final":
return event.outputThe approval gate deserves a closer look, because it's where governance meets the agent's freedom to act. Rather than every agent builder remembering to mark each sensitive tool, the harness lets a tool be flagged as destructive once, centrally, so the approval requirement is enforced for every agent that uses it — governance that doesn't depend on each builder getting it right.
Destructive tools gated once, centrally — enforced for every agent (illustrative)
# Set at the MCP Gateway, not in each agent definition:
tools:
payments.issue_refund:
destructive: true # every agent calling this must get approval
approval: require_user # harness pauses the run and waits
payments.read_balance:
destructive: false # read-only — runs without a gateThis inverts the usual failure mode, where a sensitive action runs unconfirmed because someone forgot to configure a gate on it. Flagging at the gateway makes the safe default org-wide rather than per-agent, which is exactly the kind of control that survives contact with many teams shipping many agents.
Flagging a tool is only the start; the policy behind the gate is what makes the approval meaningful. A production approval policy should be versioned and scoped, answering: which tools require approval, who may approve, whether approval is per-call or per-session, what arguments are shown to the approver, and how long an approval stays valid. A refund approval that doesn't show the amount and the recipient isn't a meaningful approval — it's a rubber stamp. Centralizing the flag is what makes those questions answerable in one place rather than re-litigated in every agent.
Two of Sofia's three teams couldn't reconstruct what an agent did on a given run, which is the observability gap this whole series keeps returning to — now at the agent level. A harness has to emit an end-to-end trace per run: every LLM call, tool call, sandbox execution, and subagent, with cost, tokens, and latency attributed per step. Without that, a misbehaving agent is a black box, and the only signal you get is the bill or the complaint.
What the trace carries matters as much as that it exists. A useful per-step record ties together the run and step identity, the model and tool involved, the approval decision, the sandbox session, and the cost, tokens, and latency of the step — enough to reconstruct, attribute, and cost any run after the fact:
An illustrative per-step trace record (shape is gateway-specific)
{
"agent.run_id": "run_abc123",
"agent.name": "refund-assistant",
"agent.step.type": "tool_call",
"agent.step.name": "payments.issue_refund",
"model": "claude-sonnet-4-6",
"mcp.server": "payments",
"approval.required": true,
"approval.status": "approved",
"sandbox.session_id": "sbx_7f1c",
"tokens.input": 1842,
"tokens.output": 391,
"latency_ms": 2200,
"cost_usd": 0.0142
}
A run is then just the ordered set of these records under one run_id — which is what turns "the agent did something expensive" into "step 4 called issue_refund after an approved gate, costing this much."
Because TrueFoundry's harness runs on the same gateway plane as model and MCP traffic, it inherits the AI Gateway's analytics, request logs, OpenTelemetry export, and Prometheus and Grafana integration — one pane of glass across model, MCP, and agent traffic rather than three disconnected dashboards
TrueFoundry isn't the only managed harness, and the alternatives are good. Anthropic's Claude Managed Agents and LangChain's LangSmith Managed Deep Agents are both strong hosted runtimes, and for many teams they're an excellent fit. The useful way to compare them isn't a scoreboard; it's a difference in design philosophy, and which philosophy fits depends on your situation.
As documented at the time of writing, many managed-cloud runtimes lean pro-code and API-first: you define agents, sessions, and environments through an SDK or REST API, register credentials per agent or workspace (vault IDs, header arrays), set tool-approval policies per agent, and run in the provider's managed cloud. That's a clean, tightly integrated model — especially if you're already standardized on one model provider or one orchestration framework and your team is comfortable defining agents in code. TrueFoundry's philosophy is different: a no-code builder first (with the same definition available via SDK and REST), credentials centralized in the gateway control plane rather than registered per agent, destructive-tool approval flagged once org-wide, model access governed with RBAC and budgets across any provider, and deployment available as SaaS, self-hosted, or on-prem. The trade is integration-simplicity-within-one-ecosystem versus centralized-governance-across-many.
The harness is the capstone of the control-plane story this series has been telling. The AI Gateway governs model traffic; the MCP Gateway governs tool traffic; the Agent Gateway governs agent-to-agent traffic; the Skills Registry governs reusable, versioned skills; and the harness is the runtime that ties them together into a managed agent, running in the same plane so orchestration, governance, and observability stay in one system rather than scattered across layers.
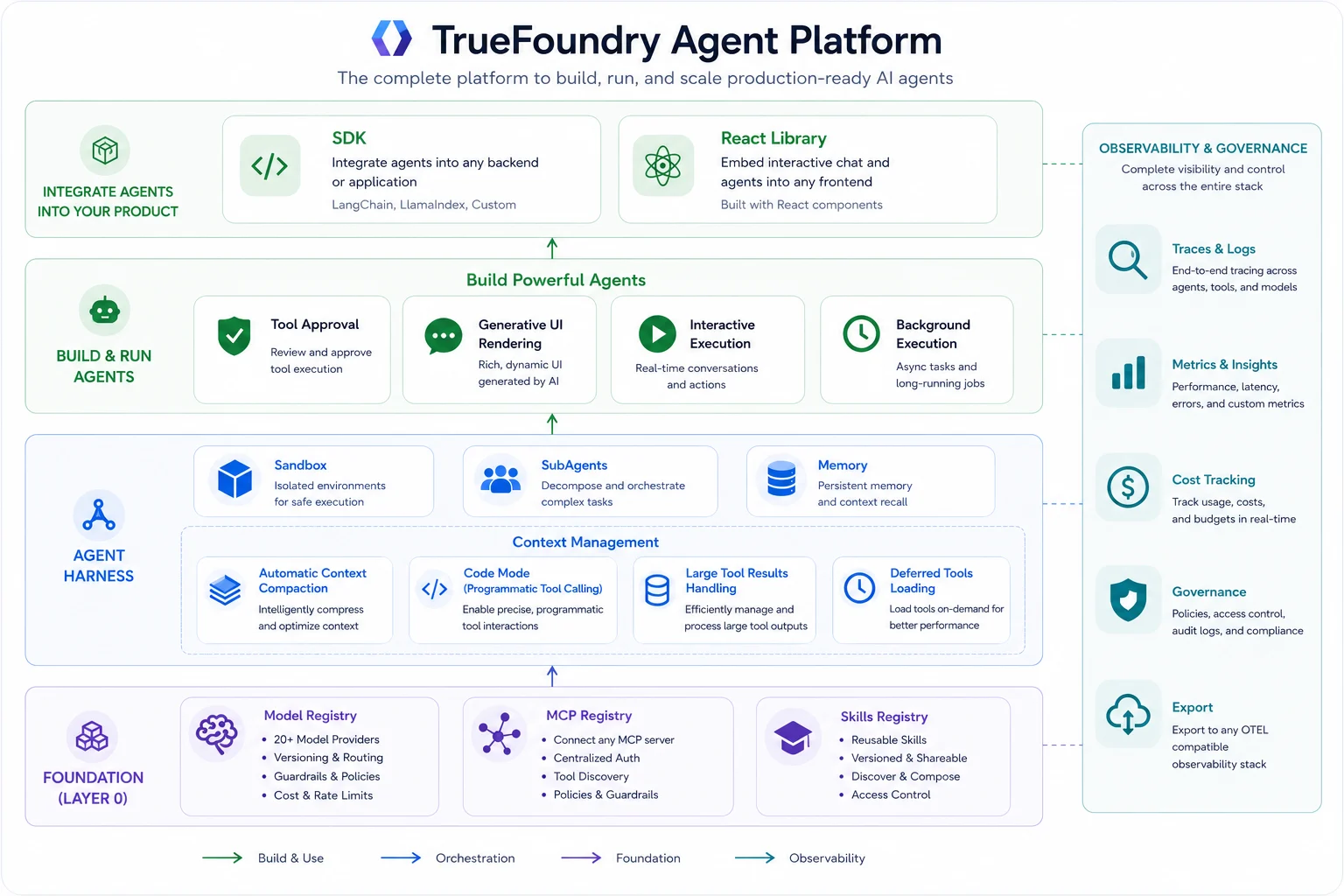
That co-location is the reason the harness can keep credentials out of definitions, gate destructive tools once, and trace a run end-to-end: it's not bolting governance onto an agent runtime after the fact, it's running the agent runtime inside the governance plane that was already there. For Sofia, that's the difference between standardizing three teams onto one governed runtime and continuing to babysit three bespoke ones.
Isn't the harness just an agent framework like LangChain or CrewAI?
Related but not the same. A framework is a library you use to build an agent's logic; a harness is the managed runtime that runs it — orchestration loop, sandbox, credential injection, approvals, and tracing as operated capabilities. TrueFoundry's harness adds the managed runtime and governance layer around models, MCP tools, skills, sandboxing, approvals, and traces. You can think of the framework as how you write the agent's logic, and the harness as where a governed agent safely runs.
Why does "no keys in agent definitions" matter so much?
Because a credential pasted into a definition spreads to wherever that definition is stored or copied, can't be rotated without finding every copy, and is the most common way secrets leak. Referencing models, tools, and skills by name — with credentials held and injected by the gateway — makes rotation a single central action and keeps secrets out of repos. It's governance enforced by architecture rather than by remembering a policy.
Do I have to use the no-code builder?
No. TrueFoundry's harness exposes the same agent definition through a no-code builder, a Python SDK, and a REST API, so non-developers can ship from the console while engineers drive the identical definition from code and integrate runs into applications. The builder lowers the floor; the SDK and API keep the ceiling high.
How is the harness's context engineering different from the gateway session post?
Our earlier context-engineering post was about managing the conversation and session state flowing through the gateway. The harness's context engineering operates inside the agent loop — subagents to isolate subtasks, a code mode to manipulate data programmatically, large-result offloading, and compaction — to keep a long-running agent's window lean automatically. Same goal of controlling context; different layer, with agent-loop-specific tools.
Can I run a managed harness on-prem?
With TrueFoundry, yes — it deploys as SaaS, self-hosted, or on-prem in your own cloud and region, which is often the deciding factor for regulated or air-gapped environments. That portability is one of the architectural distinctions from managed-cloud-only runtimes; confirm current options against each vendor's documentation, since deployment models change.
Sofia's problem was never the model or the tools. It was that the runtime around them — the harness — had been rebuilt three times, three different ways, with three different gaps. A managed harness collapses that into one governed runtime: define the agent declaratively, keep secrets in the control plane, gate the dangerous actions, and trace every step. Make the harness a platform capability, and shipping a governed agent becomes a repeatable platform workflow instead of a per-team runtime rebuild.
Sofia is illustrative. TrueFoundry Agent Harness capabilities are summarized from public product documentation as of mid-2026 and will evolve; some capabilities may be in active development. Comparisons to Claude Managed Agents and LangSmith Managed Deep Agents describe design philosophies as documented at the time of writing — these are strong, fast-moving products whose specifics (models, regions, credential and approval mechanisms, SDK availability, deployment options) change frequently, so verify against each vendor's current documentation. Code and configuration samples are illustrative of the documented patterns, not copied from a reference implementation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox