




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
%20(10).webp)
Blazingly fast way to build, track and deploy your models!

Neste exemplo, treinamos um modelo que pode classificar uma flor do gênero íris em uma de três espécies com base em medições de tamanho de sua pétala e sépala.
Você também pode seguir este exemplo em um notebook do Google Colaboratory.
O Dataset Iris contém três espécies diferentes:
Precisamos construir um classificador que possa identificar a espécie da flor dados os seguintes parâmetros:
TrueFoundry fornece duas bibliotecas para simplificar seus fluxos de trabalho de ML:
mlfoundry biblioteca é usada para rastrear experimentos de treinamento de ML.
Por que você precisa de rastreamento de experimentos? Se você está treinando múltiplos modelos de ML para resolver um problema, provavelmente treinará múltiplos modelos com múltiplos frameworks, hiperparâmetros e múltiplos conjuntos de dados. Rastrear seu experimento usando uma biblioteca como mlfoundry pode ajudar você a organizar seus experimentos de ML.
Você pode usar o MLFoundry para registrar hiperparâmetros, métricas, conjuntos de dados e modelos. Você pode então comparar diferentes experimentos no painel do TrueFoundry e escolher um modelo para implantar em produção ou decidir retreinar o modelo.
Usaremos 5 APIs diferentes do MLFoundry neste exemplo. Elas são:
Utilizando a servicefoundry biblioteca, você pode empacotar, conteinerizar e implantar um modelo em um cluster Kubernetes facilmente.
Abra um notebook IPython - você pode usar o Jupyter rodando localmente em sua máquina ou um notebook Google Colab que roda na nuvem.
Instale as bibliotecas necessárias.
Faça login no TrueFoundry. Crie e copie uma chave de API da página de configurações. Use esta chave de API para inicializar o cliente MLFoundry e criar uma execução (run). Uma execução (run) é uma entidade que representa um único experimento.
Busque o conjunto de dados Iris usando o sklearn.datasets módulo. Em seguida, dividimos em conjuntos de dados de teste e treinamento.
Vamos dar uma olhada nos nomes dos alvos. Usaremos isso para mapear a saída inteira do modelo para os nomes reais das espécies
Inicialize um modelo. Em seguida, use o MLFoundry para registrar os parâmetros do modelo e crie algumas tags para esta execução de experimento atual.
Em seguida, treinamos o modelo em nosso conjunto de dados de treinamento. Uma vez concluído o treinamento, calculamos as várias métricas e as registramos no MLFoundry usando log_metrics.
Se estivermos satisfeitos com as pontuações de precisão e outras métricas, podemos optar por implantar o modelo atual. Para isso, precisamos salvar o modelo e copiar o ID da execução atual.
Você pode ver todas as suas execuções e comparar métricas através do painel de acompanhamento de experimentos do TrueFoundry.

Para implantar o modelo usando o ServiceFoundry, precisamos criar um arquivo Python contendo a função que queremos expor como um endpoint.
Dentro desse arquivo Python, buscaremos o modelo que acabamos de treinar e salvar usando o ID da execução, utilizando mlfoundry. Observe que a chave de API exigida por mlfoundry estará disponível como a variável de ambiente TFY_API_KEY.
No seu notebook IPython, crie um bloco com o seguinte conteúdo e execute-o para criar um arquivo Python chamado predict.py. Usamos o comando mágico do Jupyter %%writefile para criar o arquivo no ambiente do notebook.
Dentro da função de espécies, carregamos as características em um pandas DataFrame e faça a previsão usando o modelo. Traduzimos da classe inteira para os nomes das espécies usando os target_names que imprimimos durante o treinamento.
Isso é praticamente todo o trabalho que você precisará fazer. Agora, vamos implantar este modelo como um serviço de API. Primeiro, instale e importe servicefoundry no seu notebook. Faça login em servicefoundry.
Acesse o painel do TrueFoundry e crie um espaço de trabalho para implantar o serviço. Espaços de trabalho são uma forma de agrupar projetos relacionados dentro do TrueFoundry. Assim que o espaço de trabalho for criado, copie o FQN para que possamos informar servicefoundry onde implantar o modelo.

servicefoundry permite que você reúna todas as dependências do arquivo que você acabou de criar usando a gather_requirements função.
Agora crie um sfy.Service objeto, forneça o FQN do workspace e implante-o chamando .deploy()
Você pode acompanhar o progresso desta implantação no dashboard. Assim que a implantação for concluída, você poderá acessar o serviço implantado a partir daí e testá-lo.
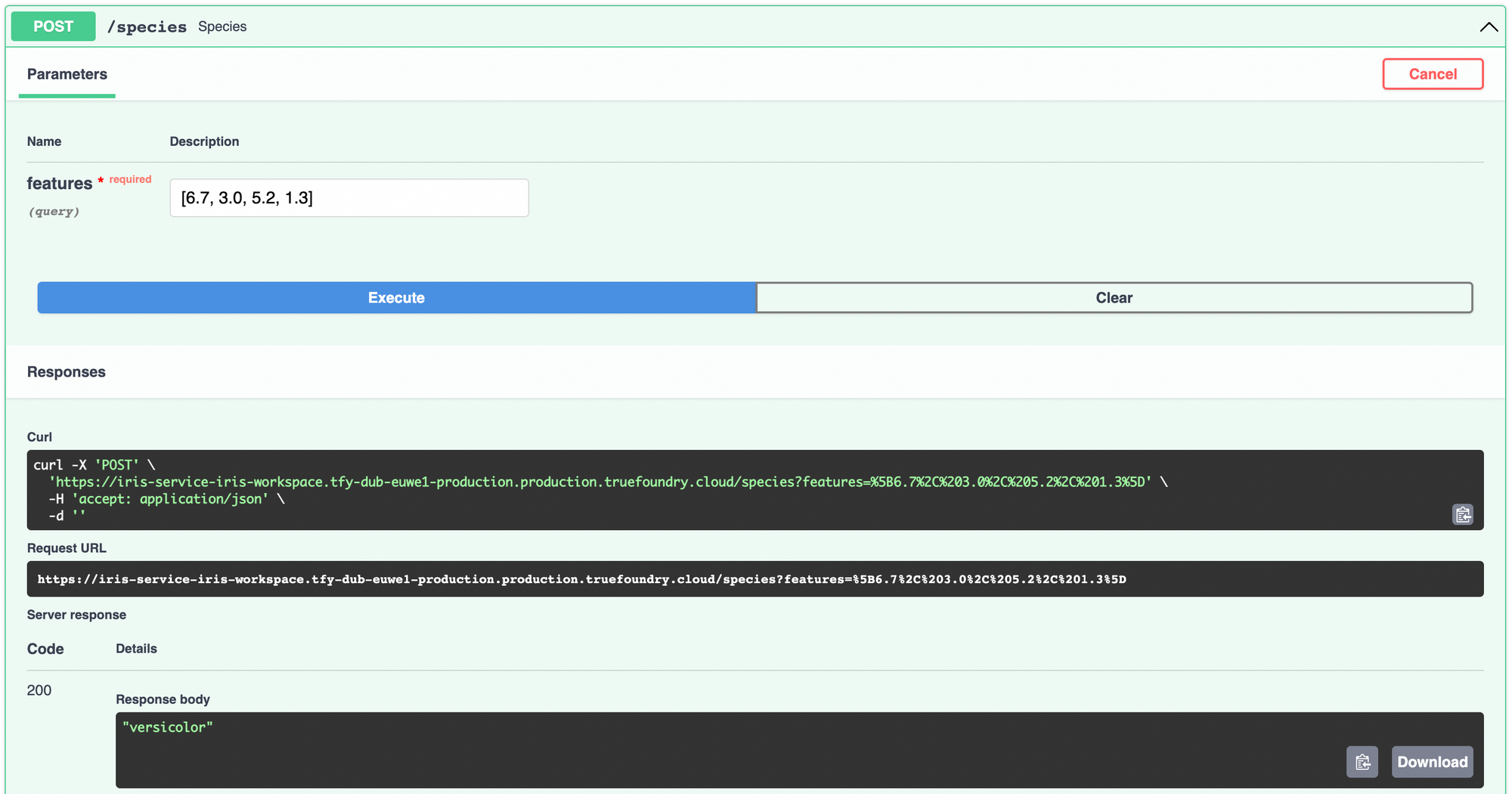
O dashboard do TrueFoundry também inclui links para métricas e logs que vêm prontos para uso com as implantações do TrueFoundry, na forma de dashboards do Grafana. Você pode ler mais sobre eles aqui.

Você também pode implantar aplicativos de UI interativos e aplicativos Gradio facilmente a partir de um notebook IPython usando servicefoundry. Leia este guia para ver como.
Estamos trabalhando para tornar a integração entre o rastreamento de experimentos e a implantação ainda mais estreita e a experiência, mais agradável. Você pode ler sobre outras coisas que você pode fazer com o TrueFoundry em nossa documentaçãoSe você está treinando modelos de machine learning para resolver um problema, o TrueFoundry ajuda você a rastrear diferentes experimentos e torna fácil e intuitivo implantar modelos com as melhores práticas, disponibilizando-os para uso público em questão de minutos.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




