




March 25, 2025
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Numa era em que os LLMs impulsionam aplicações críticas, a visibilidade do seu funcionamento interno é inegociável. A observabilidade de LLM é a prática de capturar e analisar dados ao nível da inferência, incluindo uso de tokens, desempenho de prompts, taxas de erro, latência e métricas de custo, e correlacioná-los com as interações do utilizador. Isso vai além do monitoramento tradicional de modelos, que monitoriza principalmente métricas de infraestrutura como uso de CPU e tempos de resposta. O AI Gateway da TrueFoundry incorpora uma camada de observabilidade abrangente com versionamento de prompts, registo estruturado, dashboards de análise em tempo real e alertas de anomalias para revelar insights acionáveis, otimizar o desempenho e controlar os custos em cada etapa do seu pipeline de LLM.
A observabilidade de LLM é a prática de ponta a ponta de instrumentar, coletar e analisar cada evento de inferência num pipeline de modelo de linguagem. Ela combina duas camadas principais:
Análise Interativa
Um dashboard centralizado exibe métricas em tempo real sobre o uso de tokens, volume de requisições e custo. É possível visualizar tokens de entrada e saída cumulativos, requisições totais e custos de tokens juntamente com percentis de latência (P50, P90, P99) para cada modelo. Gráficos revelam requisições por segundo, taxas de erro, consumo ao nível do utilizador e detalhamento de custos específicos do modelo. Filtros permitem isolar chamadas afetadas por limitação de taxa, fallbacks ou balanceamento de carga e inspecionar quais regras foram aplicadas.
Contexto Orientado por Metadados
Cada requisição pode conter tags personalizadas como ambiente (dev, staging, prod), nome da funcionalidade, ID do utilizador, equipa ou qualquer contexto de negócio através de um cabeçalho X-TFY-METADATA. Os metadados permitem:
Exportação de Logs
Para análise aprofundada ou arquivamento, a TrueFoundry suporta exportações JSON estruturadas de logs e traces sob demanda, permitindo a investigação offline de padrões de desempenho, custo e uso
Juntas, estas capacidades dão às equipas total visibilidade sobre o comportamento do modelo, os fatores de custo e os problemas potenciais, garantindo implementações de LLM fiáveis e otimizadas.
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
A observabilidade de modelo tradicional foca-se principalmente na saúde da infraestrutura e em métricas básicas de requisição. Monitoriza indicadores ao nível do sistema, como utilização de CPU e GPU, consumo de memória, I/O de disco, throughput de rede, latência geral de requisição e taxas de erro. Estas métricas indicam se a sua plataforma de serviço de modelos está operacional e onde podem ocorrer gargalos de computação ou rede. Alertas são acionados em violações de limiares, como alta carga de CPU ou taxas de erro 5xx elevadas, permitindo que as equipas de operações provisionem recursos ou investiguem interrupções de serviço.
A observabilidade de LLM, em contraste, aprofunda-se na semântica e na economia de cada inferência. Grandes modelos de linguagem lidam com entradas de comprimento variável e geram conteúdo token a token, portanto, compreender o seu comportamento requer instrumentação sensível ao conteúdo:
Métricas de Token versus Throughput Fixo
Modelos tradicionais contam requisições por segundo; LLMs rastreiam tokens de entrada e saída. A observabilidade captura volumes cumulativos de tokens, custos de tokens e uso de tokens por modelo. Isso permite atribuir gastos a utilizadores ou funcionalidades específicas e detetar prompts descontrolados antes que os custos aumentem.
Registro de Prompt-Resposta versus Previsões de Caixa Preta
Os logs de observabilidade de ML padrão registram apenas metadados de solicitação, como o endpoint acessado e o código de status. A observabilidade de LLM registra pares completos de prompt-resposta juntamente com metadados contextuais como ambiente, recurso e ID de usuário. Isso possibilita rastrear alucinações ou regressões de qualidade até modelos de prompt específicos ou grupos de usuários.
Percentis de Latência versus Médias
Configurações tradicionais frequentemente relatam a latência média. Os painéis de LLM exibem os percentis de latência P50, P90 e P99 por modelo, já que a geração token a token pode introduzir atrasos de cauda longa que as métricas médias obscurecem.
Efeitos Impulsionados pela Configuração
Com LLMs, controles como limitação de taxa, balanceamento de carga e regras de fallback afetam o comportamento. A observabilidade sinaliza as solicitações impactadas por essas regras – por exemplo, chamadas que foram limitadas por taxa, redirecionadas ou que recorreram a outro provedor – permitindo que as equipes ajustem as políticas.
Análise em Tempo Real versus Logs Pós-Mortem
Enquanto a observabilidade tradicional depende da análise periódica de logs, plataformas de observabilidade de LLM como o AI Gateway da TrueFoundry fornecem painéis interativos para filtragem em tempo real e exploração de tendências, permitindo que você segmente métricas por tags de metadados em tempo real.
Em resumo, a observabilidade tradicional responde à pergunta: “A infraestrutura de serviço está saudável?” A observabilidade de LLM explica: “Como, quando e por que cada token é gerado, e o que isso significa para custo, desempenho e qualidade da saída?”
Implementar uma observabilidade robusta para LLMs é essencial para manter o desempenho, controlar custos e garantir saídas de alta qualidade. Esses pilares essenciais trabalham juntos para dar às equipes visibilidade completa sobre cada evento de inferência. Ao compreendê-los e aplicá-los, você pode monitorar, diagnosticar e otimizar suas implantações de LLM de forma eficaz.
1. Análise Interativa
Um painel unificado oferece insights em tempo real sobre todos os aspectos da sua carga de trabalho de LLM. Você pode rastrear volumes de tokens de entrada e saída cumulativos e por modelo, contagens totais de solicitações e custos baseados em tokens. Percentis de latência detalhados, P50, P90 e P99, revelam características de desempenho. Gráficos de solicitações por segundo e taxas de erro ajudam a identificar anomalias. Filtros permitem que você aprofunde a análise em chamadas afetadas por limites de taxa, regras de balanceamento de carga ou fallbacks para uma solução de problemas direcionada.
2. Contexto Orientado por Metadados
Ao anexar metadados personalizados a cada solicitação, como ambiente (desenvolvimento, staging, produção), nome do recurso, ID do usuário ou equipe, você ganha a capacidade de segmentar e analisar suas métricas. Os metadados impulsionam o monitoramento granular de uso entre grupos, direcionam controles condicionais para limitação de taxa e seleção de modelo, e permitem a filtragem precisa de logs para auditorias e conformidade. Você passa os metadados por meio de um único cabeçalho X-TFY-METADATA em SDKs OpenAI ou LangChain, solicitações REST ou chamadas cURL.
3. Registro Abrangente
Cada inferência é registrada em um formato estruturado que inclui pares completos de prompt-resposta, contagens de tokens, detalhes de latência, códigos de erro e metadados anexados. Esse nível de detalhe permite que você conduza análises de causa raiz em alucinações, regressões de qualidade ou anomalias de desempenho. Você pode comparar versões de prompt, monitorar como as alterações de modelo afetam a qualidade da saída e rastrear problemas até grupos de usuários ou recursos específicos.
4. Exportação e Auditoria de Logs
Para análises offline mais aprofundadas ou arquivamento, a TrueFoundry oferece suporte a exportações JSON estruturadas de logs e rastreamentos. Os administradores simplesmente solicitam as exportações via suporte com um período de tempo especificado. Os dados exportados permitem análises personalizadas, relatórios de conformidade ou armazenamento de longo prazo.
Juntos, esses pilares oferecem total transparência sobre os impulsionadores de custo, perfis de desempenho e qualidade da saída, garantindo que suas implantações de LLM permaneçam confiáveis, eficientes e econômicas.
Aqui estão as 4 melhores ferramentas de observabilidade de LLM, com uma breve visão geral de cada uma:
O AI Gateway da TrueFoundry oferece uma solução unificada e de nível empresarial para observabilidade e governança de LLMs, com os seguintes recursos:
Métricas em Tempo Real
.webp)
Painéis interativos que mostram contagens cumulativas e por modelo de tokens de entrada/saída, volume total de requisições, detalhamento de custos por modelo e usuário, e percentis detalhados de latência (P50, P90, P99). Mapas de calor de requisições por segundo, tendências de taxa de erro e alertas de anomalia configuráveis para identificar picos de falhas ou latência
Insights Orientados por Metadados
{
"tfy_log_request": "true", //Se deve adicionar um log/rastreamento para esta requisição ou não
"environment": "staging", // O ambiente - dev, staging ou prod?
"feature": "countdown-bot" //Qual recurso iniciou a requisição?
}
Marque as requisições com contexto de negócio (ambiente, recurso, usuário, equipe) através de um único cabeçalho X-TFY-METADATA. Filtre painéis e logs por metadados para comparar ambientes, isolar o uso de recursos e auditar a atividade de usuários ou equipes.
Controle de Políticas como Código
Defina regras de limitação de taxa baseadas em YAML (por exemplo, “1000 chamadas GPT-4/dia para dev”), pesos de balanceamento de carga entre provedores e cadeias de fallback quando ocorrem erros
Definições de política com controle de versão gerenciadas via fluxos de trabalho GitOps, permitindo revisões de pull request, validação de CI e reversões
Registro e Rastreamento Abrangentes

Armazene logs JSON estruturados de pares completos de prompt-resposta, detalhamentos em nível de token, latência, códigos de erro e IDs de política aplicadas. Correlacione em rastreamentos distribuídos para depurar fluxos de trabalho multi-etapas ou pipelines RAG.
Exportação e Conformidade:
Exportação sob demanda de logs e rastreamentos em JSON para análise offline, arquivamento de longo prazo ou auditorias regulatórias. RBAC integrado e trilhas de auditoria garantem que apenas usuários autorizados possam visualizar ou exportar dados sensíveis
Esses recursos tornam o TrueFoundry uma escolha de destaque para equipes que precisam de visibilidade de ponta a ponta, controle de custos granular, governança de política como código e auditabilidade robusta em suas implantações de LLM.
LangSmith é especializado em rastreamento profundo e depuração para aplicações baseadas em LangChain. Ele captura automaticamente cada etapa de suas cadeias, registrando entradas de prompt, saídas intermediárias e respostas finais. Os desenvolvedores obtêm um visualizador de rastreamento interativo para comparar modelos de prompt ao longo do tempo, identificar regressões de desempenho e aprofundar-se em chamadas de função. LangSmith também registra métricas de tempo de execução, como uso de tokens e latência por etapa da cadeia, e permite anexar metadados personalizados para rastreamento de recursos. Com gerenciamento de experimentos integrado, você pode marcar execuções, comparar a qualidade da saída entre as versões do modelo e reverter para configurações comprovadas. Seu foco na ergonomia do desenvolvedor e na transparência da cadeia o torna ideal para iteração rápida e depuração.
Helicone oferece uma plataforma de observabilidade centrada em API, adaptada para IA generativa. Ele registra cada chamada de API para OpenAI, Anthropic ou outros endpoints, capturando textos completos de prompts, respostas, uso de tokens e detalhes de tempo. O painel do Helicone destaca o custo por chamada, os modelos de prompt mais usados e as distribuições de erros, ajudando você a identificar padrões caros ou propensos a falhas. Visualizações de modelagem de tráfego integradas revelam como os limites de taxa e as cotas impactam o throughput, e você pode configurar alertas para picos de custo ou taxas de erro elevadas. Com suas integrações de SDK leves, o Helicone fornece insights rápidos sobre gastos e desempenho, tornando-o uma ótima escolha para equipes focadas no controle de custos de API e otimização de prompts.
Lunary foca na simplicidade e na experiência do desenvolvedor para a observabilidade de LLMs. Ele auto-instrumenta chamadas de SDK da OpenAI e Anthropic, registrando jornadas de prompt, métricas de token e tempos de resposta com configuração mínima. Seu painel apresenta modelos de prompt versionados e detecção de regressão para a qualidade da saída, alertando você quando as alterações introduzem resultados inesperados. Lunary também oferece uma API de anotações para marcar experimentos ou testes A/B, permitindo comparações claras entre as execuções. Embora leve, ele suporta controles condicionais para limitação de taxa e roteamento de fallback. A ênfase do Lunary na facilidade de configuração e nos recursos essenciais de observabilidade o torna ideal para pequenas equipes ou protótipos que precisam de feedback rápido sobre o comportamento do modelo sem integrações complexas.
Uso Variável de Tokens: LLMs geram saídas token por token, portanto, cada solicitação pode consumir contagens de tokens muito diferentes. Monitorar e atribuir custos torna-se complexo quando os volumes de tokens flutuam descontroladamente entre prompts e usuários. Sem um rastreamento granular de tokens, as equipes correm o risco de picos de faturamento inesperados ou prompts ineficientes não percebidos.
Alto Volume de Dados: Capturar pares completos de prompt-resposta, métricas de token, detalhes de latência e metadados para cada inferência pode gerar milhões de entradas de log diariamente. Armazenar, indexar e consultar esse volume de dados estruturados requer soluções de armazenamento escaláveis e motores de consulta otimizados para evitar gargalos de desempenho em seu pipeline de observabilidade.
Complexidade Contextual: O comportamento do LLM depende muito do fraseado do prompt, das configurações de temperatura e da versão do modelo. Correlacionar mudanças na qualidade da saída ou latência com edições específicas de prompt ou ajustes de configuração exige vinculação de rastreamento e versionamento robustos. As equipes devem implementar marcação de metadados consistente e controle de versão de prompt para desvendar a teia de fatores influenciadores.
Correlação Multi-Provedor: Muitas implantações usam vários provedores de LLM para balanceamento de carga ou otimização de custos. Agregar métricas de OpenAI, Azure, Anthropic e outros endpoints em uma visão unificada requer a normalização de APIs díspares, formatos de resposta e estruturas de custo. A falha em unificar esses fluxos leva a insights fragmentados e pontos cegos em comparações de desempenho entre provedores.
Alertas em Tempo Real vs. Ruído: Definir limites de alerta significativos para taxas de erro, picos de latência ou anomalias de custo é desafiador em um ambiente onde flutuações naturais são comuns. Alertas muito sensíveis levam à fadiga de alerta, enquanto limites definidos muito altos podem atrasar a detecção de problemas críticos. As equipes precisam de estratégias de alerta adaptativas que aprendam padrões de uso normais e ajustem os limites dinamicamente.
Conformidade e Privacidade: Armazenar logs de conversas completas pode entrar em conflito com regulamentações de privacidade de dados ou políticas de segurança internas. Equilibrar a necessidade de dados de observabilidade com os requisitos de minimização de dados, criptografia e controles de acesso exige uma definição cuidadosa de políticas e suporte de ferramentas para a redação ou anonimização seletiva de logs.
Abordar esses desafios exige uma estrutura de observabilidade robusta que escala com o uso, impõe práticas consistentes de metadados, normaliza dados de múltiplos provedores e oferece alertas inteligentes para destacar apenas os problemas mais críticos.
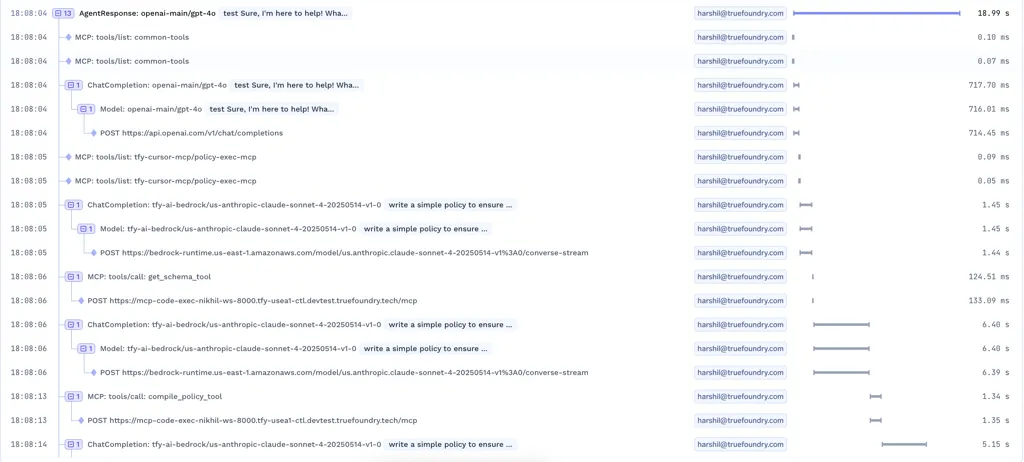
Em sistemas reais, uma requisição de LLM raramente é uma única chamada a um modelo. É uma cadeia de etapas.
A entrada do usuário se torna um prompt. Esse prompt busca contexto. O modelo responde. A resposta aciona uma ferramenta. O resultado da ferramenta é realimentado no modelo. Só então o usuário vê uma resposta. Cada etapa envolve repetidas inferências de LLM, razão pela qual o rastreamento deve capturar cada decisão intermediária em vez de apenas a saída final.
Um bom rastreamento torna isso visível.
As equipes precisam ver:
Sem isso, a depuração se transforma em adivinhação. Com isso, as equipes podem acompanhar exatamente o que aconteceu e onde as coisas deram errado.
Para muitas equipes, o custo é o primeiro sinal de alerta real. Os custos de LLM não crescem como os custos de infraestrutura. Eles crescem com tokens, verbosidade, novas tentativas e etapas intermediárias ocultas. Uma pequena mudança no prompt ou um agente com mau funcionamento pode silenciosamente gerar gastos duplicados.
É por isso que a visibilidade em nível de token é importante.
As equipes precisam entender:
Quando os dados de tokens estão vinculados a rastreamentos, o custo deixa de ser uma surpresa e passa a ser algo que você pode gerenciar.
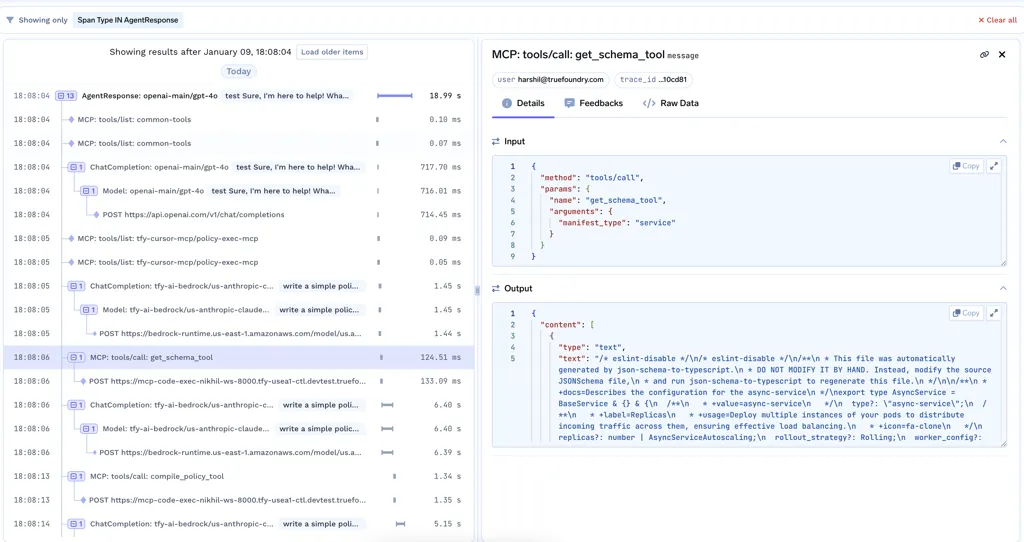
Assim que os LLMs começam a chamar ferramentas, as coisas se tornam mais poderosas – e mais frágeis. Agentes podem pesquisar bancos de dados, chamar APIs ou acionar fluxos de trabalho. Com o MCP, essas ferramentas são descobertas e invocadas dinamicamente, o que torna os sistemas mais flexíveis, mas também mais difíceis de compreender.
Em produção, as equipes precisam de respostas claras para perguntas básicas:
Sem observabilidade no nível da ferramenta de observabilidade de LLM, as equipes perdem a confiança rapidamente. Com ela, elas podem auditar o comportamento, depurar falhas e escalar com segurança sistemas baseados em agentes.
O objetivo não são dashboards melhores. É confiança. Na prática, é aqui que LLMOps se torna crítico, porque os dados de observabilidade devem alimentar continuamente as decisões de implantação, os controles de custo e a governança do modelo. Quando as equipes conseguem ver rastreamentos, uso de tokens e comportamento das ferramentas claramente, elas podem identificar problemas mais cedo, controlar custos e melhorar a qualidade com base em dados reais de produção.
Isso cria um ciclo: observe o que acontece em produção, aprenda com isso, melhore o sistema e repita. Plataformas como TrueFoundry’s AI Gateway ajuda as equipas a fazer isso, reunindo rastreamento, métricas e governança em um só lugar, para que os sistemas LLM possam ser tratados como a infraestrutura crítica que são.
A implementação da observabilidade de LLM transforma pipelines de inferência opacos em sistemas transparentes e gerenciáveis. Ao combinar análises interativas, contexto baseado em metadados, controles de política dinâmicos, registro abrangente e exportação de logs sem interrupções, as equipes obtêm os insights necessários para monitorar o desempenho, controlar custos e manter a qualidade da saída. Embora desafios como uso variável de tokens, volume de dados e correlação multiprovedor exijam arquiteturas escaláveis e práticas de metadados disciplinadas, uma solução unificada de observabilidade garante que você possa detectar anomalias precocemente, solucionar problemas de forma eficaz e iterar em prompts com confiança. No cenário atual impulsionado pela IA, a observabilidade robusta de LLM não é opcional, mas essencial para fornecer aplicações confiáveis e econômicas em escala.
Agende uma demonstração para ver como a TrueFoundry pode ajudar você a melhorar a observabilidade de LLM.
Observabilidade em IA refere-se à capacidade de compreender o estado interno de um sistema examinando sua telemetria e saídas. Ao analisar rastreamentos, métricas e logs, as equipes podem diagnosticar problemas de desempenho em tempo real. Isso garante que implantações complexas permaneçam transparentes, confiáveis e alinhadas de perto com os objetivos de negócios pretendidos.
Os cinco pilares da observabilidade de LLM incluem análises interativas, contexto baseado em metadados, registro abrangente, avaliações e exportação de logs. Esses elementos fornecem visibilidade sobre o consumo de tokens, custos e qualidade da resposta. Juntos, eles permitem que as equipes de engenharia monitorem, solucionem problemas e otimizem suas aplicações LLM de forma eficaz.
Plataformas populares para obter insights aprofundados do modelo incluem LangSmith, Helicone e Arize Phoenix. Para organizações que priorizam a soberania dos dados, a TrueFoundry oferece uma maneira poderosa de implementar a observabilidade de LLM dentro de sua própria infraestrutura. Essas ferramentas ajudam os desenvolvedores a depurar cadeias de raciocínio, rastrear custos e manter alta qualidade de saída das respostas.
O monitoramento tradicional rastreia métricas conhecidas, como latência ou taxas de erro, para manter a saúde da infraestrutura. A observabilidade de LLM usa rastreamento semântico para explicar por que problemas específicos ocorrem. Enquanto o monitoramento simplesmente sinaliza que um sistema falhou, a observabilidade fornece os dados aprofundados e o contexto necessários para encontrar e corrigir a causa raiz.
A TrueFoundry é única porque unifica o rastreamento em nível de aplicação com o monitoramento de infraestrutura dentro de sua própria VPC segura. Ela mantém uma latência inferior a 10ms enquanto lida com alto tráfego em vários provedores. Essa integração garante que os esforços de observabilidade de LLM permaneçam econômicos e seguros, ao mesmo tempo em que fornecem insights granulares sobre cada interação do modelo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.





.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




