




August 27, 2025
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Na edição anterior, abordamos o fluxo de trabalho de um cientista de dados e onde exatamente o Kubernetes pode se mostrar uma base útil sobre a qual construir uma plataforma para isso.
Nesta edição, vamos analisar um exemplo simples para obter experiência prática para tal.
Antes de começar, precisamos de um ambiente de testes para realizar a demonstração. Configuraremos um cluster Kubernetes na máquina local para isso. Embora um cluster deva conter múltiplos nós para tolerância a falhas e alta disponibilidade, simularemos esse comportamento usando uma ferramenta incrível kind (kubernetes-in-docker).
Ao final desta seção, teremos múltiplos contêineres em execução, com cada contêiner atuando como um nó de cluster separado.
Siga as instruções fornecidas aqui
Teste a instalação executando
$ kind --version
kind version 0.14.0
Agora iniciamos um cluster local usando kind. Criaremos um plano de controle e dois nós de trabalho. É possível ter vários de ambos.
<aside> 💡 Kubernetes pode ter múltiplos nós de plano de controle e de trabalho. Todos os componentes centralizados de gerenciamento do cluster residem nos nós do plano de controle, enquanto as cargas de trabalho do usuário são executadas nos nós de trabalho. Leia mais aqui
</aside>
Primeiro, crie uma kind configuração em um arquivo chamado kind-config.yaml. Você pode encontrá-lo aqui. Isto definirá a estrutura do nosso cluster -
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- função: nó de trabalho
- função: nó de trabalho
Aqui, definimos três nós, sendo um com a função de plano de controle e os outros dois como nós de trabalho.
Inicie um cluster usando esta configuração. Isso pode levar algum tempo. Certifique-se de que o daemon do Docker esteja ativo em seu sistema antes de executar isto -
$ kind create cluster --config kind-config.yaml
...
Obrigado por usar o kind! 😊
kubectl para garantir que nosso cluster esteja ativo -$ kubectl cluster-info
O plano de controle do Kubernetes está em execução em <https://127.0.0.1:63122>
O CoreDNS está em execução em <https://127.0.0.1:63122/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy>
...
Isso nos diz que o cluster está realmente ativo. Também podemos ver os contêineres individuais atuando como nós executando docker ps.
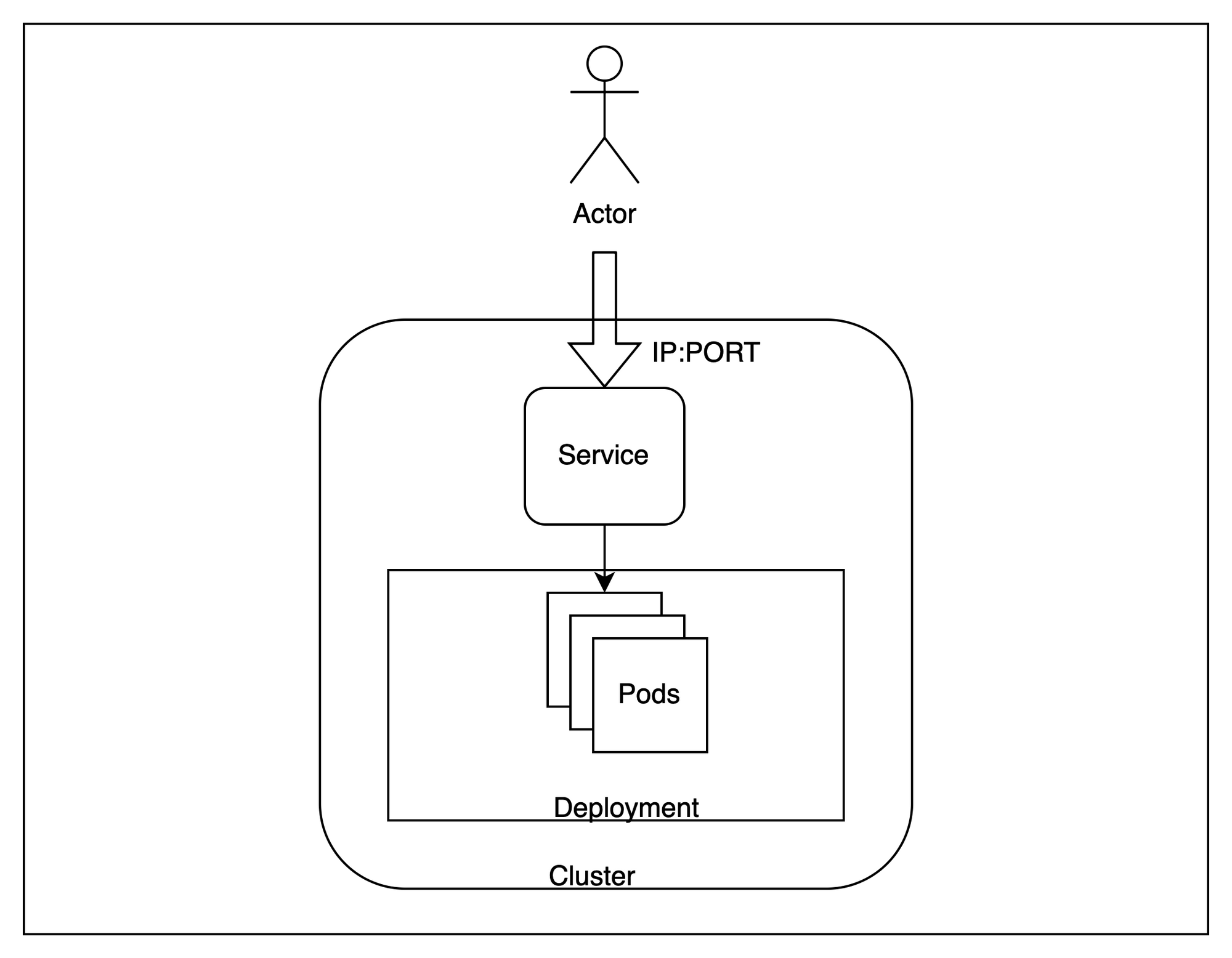
Com nosso cluster ativo, vamos analisar uma arquitetura geral do que estamos prestes a provisionar.
Em termos gerais, hospedaremos múltiplas réplicas da nossa aplicação dentro do cluster e tentaremos acessá-las de fora, com as requisições sendo balanceadas entre as diferentes instâncias.
Para conseguir isso, há algumas terminologias específicas do Kubernetes que precisamos conhecer -
Pod - Pods são as menores unidades de computação implantáveis que você pode criar e gerenciar no Kubernetes. No nosso caso, uma instância da aplicação estará rodando dentro de um pod independente. Estes são recursos efêmeros e o plano de controle pode movê-los entre os nós, se necessário.Deployment - Um deployment é útil quando queremos ter mais de uma réplica para uma aplicação. O Kubernetes tenta sempre manter o número de réplicas igual ao que é fornecido em um deployment. Criaremos três réplicas idênticas para nossa aplicação.Service - Um service é útil para balancear a carga entre um conjunto de pods rodando no cluster. Como os pods são essencialmente efêmeros e podem ser substituídos a qualquer momento, o service fornece uma interface estável para acessar os pods que estão por trás dele. Usaremos um service para testar nossa aplicação.Esses três recursos nos permitirão hospedar um endpoint escalável para servir nossa aplicação.
Com o cluster em funcionamento, podemos agora implantar uma aplicação e testá-la. Criaremos uma aplicação usando o popular conjunto de dados do classificador iris.
O repositório está disponível em https://github.com/shubham-rai-tf/iris-classifier-kubernetes. Ele já contém o código para construir e servir previsões no /iris/classify_iris endpoint usando fastapi.
Precisamos empacotar este código em uma imagem docker para prepará-lo para kubernetes. Um Dockerfile é fornecido no repositório para fazer isso - aqui.
Este Dockerfile especifica a imagem que precisaremos para criar um contêiner que hospeda os endpoints de previsão em um uvicorn servidor na porta 5000. Mais detalhes sobre a sintaxe estão disponíveis aqui.
Execute este comando para construir uma imagem local -
$ docker build . -t iris-classifier:poc
...
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
iris-classifier poc 549913d5b1f9 12 seconds ago 737MB
Podemos ver que a imagem foi criada com sucesso com o nome iris-classifier e a tag poc. Agora vamos carregar esta imagem no cluster para usá-la dentro do cluster
<aside> 💡 Este passo é necessário apenas porque não temos um registro de imagens para puxar a imagem recém-construída. Em produção, a imagem deve ser hospedada em um registro privado como Dockerhub ou AWS ECR e então puxada diretamente para o cluster
</aside>
Execute este comando para carregar a imagem construída localmente no cluster -
$ kind load docker-image iris-classifier:poc
Image: "iris-classifier:poc" com ID "sha256:549913d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" ainda não presente no nó "kind-worker2", carregando...
Image: "iris-classifier:poc" com ID "sha256:549913d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" ainda não presente no nó "kind-control-plane", carregando...
...
Você pode verificar se as imagens foram carregadas listando as imagens dentro de qualquer um dos três contêineres -
$ docker exec -it kind-worker crictl images
IMAGE TAG IMAGE ID SIZE
docker.io/library/iris-classifier poc 549913d5b1f94 753MB
Kubernetes é essencialmente um sistema declarativo. Isso significa que descrevemos os contornos do que queremos fazer e os componentes do plano de controle impulsionam constantemente o sistema para alcançar esse estado.
Para implementar a arquitetura que discutimos anteriormente, descreveremos nossa intenção na forma de um yaml arquivo que atua como um registro de intenção. Na terminologia do Kubernetes, estes são chamados de manifestos.
Todos os manifestos do Kubernetes têm os seguintes campos -
apiVersion - Múltiplos recursos são agrupados nas mesmas versões de API. Isso fornece uma maneira padronizada de descontinuar ou promover um recurso entre as versões do Kubernetes.kind - Identifica o tipo exato de objeto a ser criadometadata - Contém campos que atuam como metadados para o objeto criado. Os campos apiVersion, kind e metadata.name juntos identificam um recurso único dentro de um namespacespec - Este campo contém a especificação para o objeto a ser criado. Cada 'kind' define sua própria estrutura para este campo com sua própria implementação.Usaremos os manifestos presentes no repositório em arquivos dentro do manifests diretório aqui.
Ele define dois recursos do Kubernetes, Deployment e Service em deployment.yaml e service.yaml respectivamente. Vamos analisar ambas as seções.
apiVersion: apps/v1
kind: Deployment
spec:
# número de réplicas
replicas: 3
template:
spec:
containers:
# nome da imagem
- image: iris-classifier:poc
name: iris-classifier
O manifesto de implantação em deployment.yaml define principalmente a especificação do pod que queremos implantar, incluindo o nome da imagem e o número de réplicas. Uma vez aplicado, o Kubernetes tomará medidas constantes para manter o número de réplicas conforme especificado aqui.
apiVersion: v1
kind: Service
spec:
# Tipo do serviço
type: ClusterIP
ports:
# Porta onde o serviço será acessível
- port: 8080
# Porta no contêiner para onde o tráfego será encaminhado
targetPort: 5000
protocolo: TCP
seletor:
app: iris-classifier
O manifesto do serviço em service.yaml define como balancear a carga entre as réplicas criadas pelo deployment. Aqui definimos como a porta do serviço deve ser mapeada para a porta dos contêineres. Como nossa aplicação roda na porta 5000, o targetPort é definido como 5000. O serviço é exposto na porta 8080. O tráfego TCP enviado para 8080 será balanceado entre a porta 5000 nos contêineres.
Execute o seguinte comando para aplicar os manifestos ao Kubernetes -
$ kubectl apply -f manifests/
deployment.apps/iris-classifier criado
service/iris-classifier criado
Ambos os recursos foram criados com sucesso no cluster. Podemos verificar executando os seguintes comandos -
$ kubectl get service iris-classifier
NOME TIPO CLUSTER-IP EXTERNAL-IP PORTA(S) IDADE
iris-classifier ClusterIP 10.96.107.238 <none> 8080/TCP 37m
$ kubectl get deployment iris-classifier
NOME PRONTO ATUALIZADO DISPONÍVEL IDADE
iris-classifier 3/3 3 3 38m
$ kubectl get pods
NOME PRONTO STATUS REINÍCIOS IDADE
iris-classifier-5d97498ff9-77wqw 1/1 Em execução 0 39m
iris-classifier-5d97498ff9-8twjm 1/1 Em execução 0 39m
iris-classifier-5d97498ff9-znrz8 1/1 Em execução 0 39m
Como podemos ver, o serviço está exposto na porta 8080 e três pods foram criados conforme especificamos.
Altere deployment.yaml para ter 2 réplicas em vez de 3 e reaplique. O Kubernetes excluirá uma das réplicas para corresponder à especificação.
Agora que os recursos foram criados no cluster, podemos verificar nossa implantação chamando o modelo usando o endpoint do serviço. Como estamos usando uma configuração local, teremos que fazer o port-forward do serviço para uma porta na máquina local.
<aside> 💡 Em uma configuração de provedor de nuvem, este serviço será vinculado a um balanceador de carga externo que pode ser acessado pela internet, se necessário.
</aside>
Execute o seguinte comando para realizar o port forwarding para o serviço -
$ kubectl port-forward services/iris-classifier 8080
Encaminhando de 127.0.0.1:8080 -> 5000
Encaminhando de [::1]:8080 -> 5000
Podemos verificar chamando o /healthcheck endpoint no modelo -
$ curl '<http://localhost:8080/healthcheck>'
"Classificador Iris está pronto!"
Para realizar uma previsão de teste, enviaremos uma entrada de exemplo para obter uma previsão -
$ curl '<http://localhost:8080/iris/classify_iris>' -X POST \\
-H 'Content-Type: application/json' \\
-d '{"sepal_length": 2, "sepal_width": 4, "petal_length": 2, "petal_width": 4}'
{"class":"setosa","probability":0.99}
Obtemos uma previsão da classe setosa com 99% de probabilidade. Ao executar várias dessas previsões, podemos verificar que as requisições estão de fato sendo roteadas para diferentes pods de forma round robin.
Vamos remover todos os recursos do Kubernetes que instalamos primeiro -
$ kubectl delete -f manifests/
Isso limpará todos os recursos do Kubernetes que criamos nas seções anteriores. Agora podemos desativar o cluster também -
$ kind delete cluster
Excluindo cluster "kind" ...
Nesta edição, abordamos como hospedar um modelo como um serviço chamável no Kubernetes. Embora este tenha sido um exemplo simples, onde construímos uma imagem Docker localmente e a executamos em um cluster na mesma máquina, uma configuração de produção típica funciona com princípios semelhantes. Muito pode ser alcançado apenas com esses dois recursos.
Nas próximas edições, exploraremos outras funcionalidades mais avançadas, como multi-tenancy e controle de acesso, que se tornam essenciais à medida que avançamos para as operações do dia 2.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.





.webp)




.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




