




August 27, 2025
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Diferentes cargas de trabalho exigem especificações de hardware variadas, como tipo de máquina, tamanho e geolocalização. Com o aumento de ML/LLMs, selecionar o hardware certo tornou-se crucial. Precisamos fazer escolhas com base em especificações de hardware como tipo de SO, arquitetura, processador, tipo de GPU e armazenamento. O Kubernetes auxilia na orquestração e distribuição de recursos entre cargas de trabalho semelhantes, mas o provisionamento dinâmico desses recursos sob demanda continua sendo um desafio.
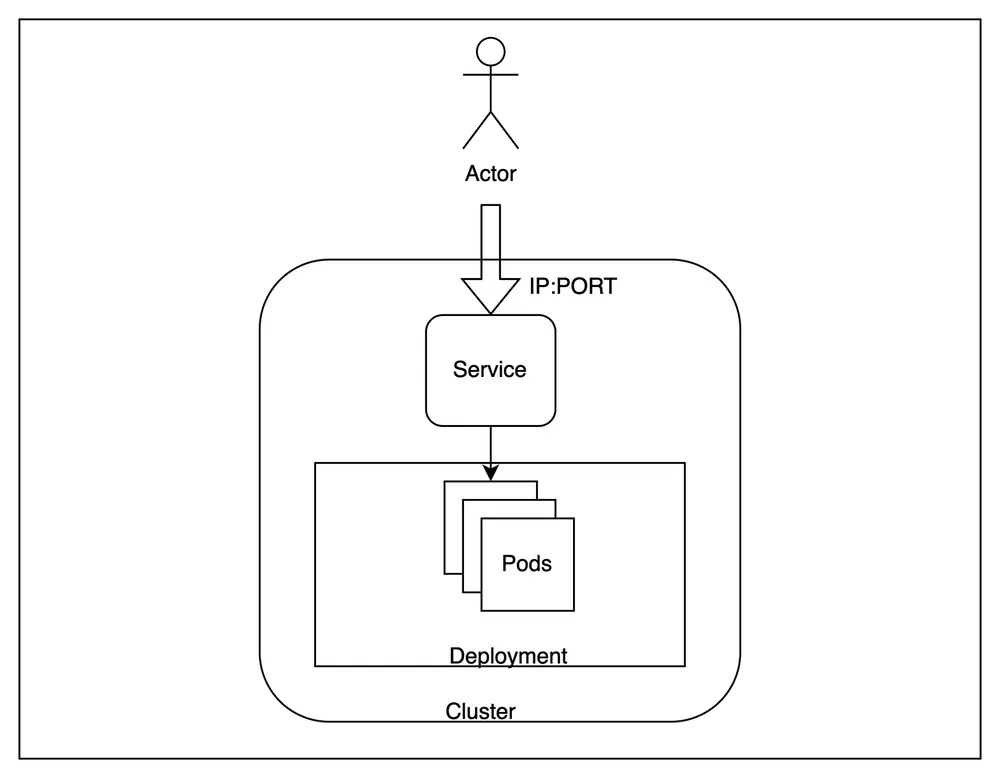
Um Kubernetes (K8s) é um agrupamento de nós que executam aplicativos conteinerizados de forma eficiente, automatizada, distribuída e escalável. Cada nó dentro de um cluster Kubernetes possui atributos específicos como tipo de máquina, tamanho e localização.
Este blog explora a necessidade de provisionadores automáticos de nós na nuvem para gerenciar automaticamente diversos requisitos de carga de trabalho dentro de clusters Kubernetes. Também fornecemos insights sobre as soluções oferecidas pelos principais provedores de nuvem, como AWS, GCP e Azure. Por fim, aprofundamos como a TrueFoundry aborda esses desafios como plataforma.
O provisionamento automático de nós automatiza o provisionamento do grupo de nós apropriado com base nas restrições de pods não agendados para otimizar os custos de infraestrutura. Os provisionadores automáticos de nós em um cluster Kubernetes são responsáveis pelas seguintes ações:
O Kubernetes tem nós como suas máquinas de trabalho com configurações de hardware específicas, como tipo de máquina, tamanho e tipo de capacidade, e os pools de nós referem-se a pools de tais máquinas de trabalho comuns. Na ausência de um provisionador automático de nós, a única maneira de alocar uma configuração de hardware específica para sua carga de trabalho era através da seleção de pool de nós. Isso exige que o usuário crie um pool de nós com a configuração necessária em sua nuvem e, em seguida, adicione a afinidade para o pool de nós específico na especificação do Pod.
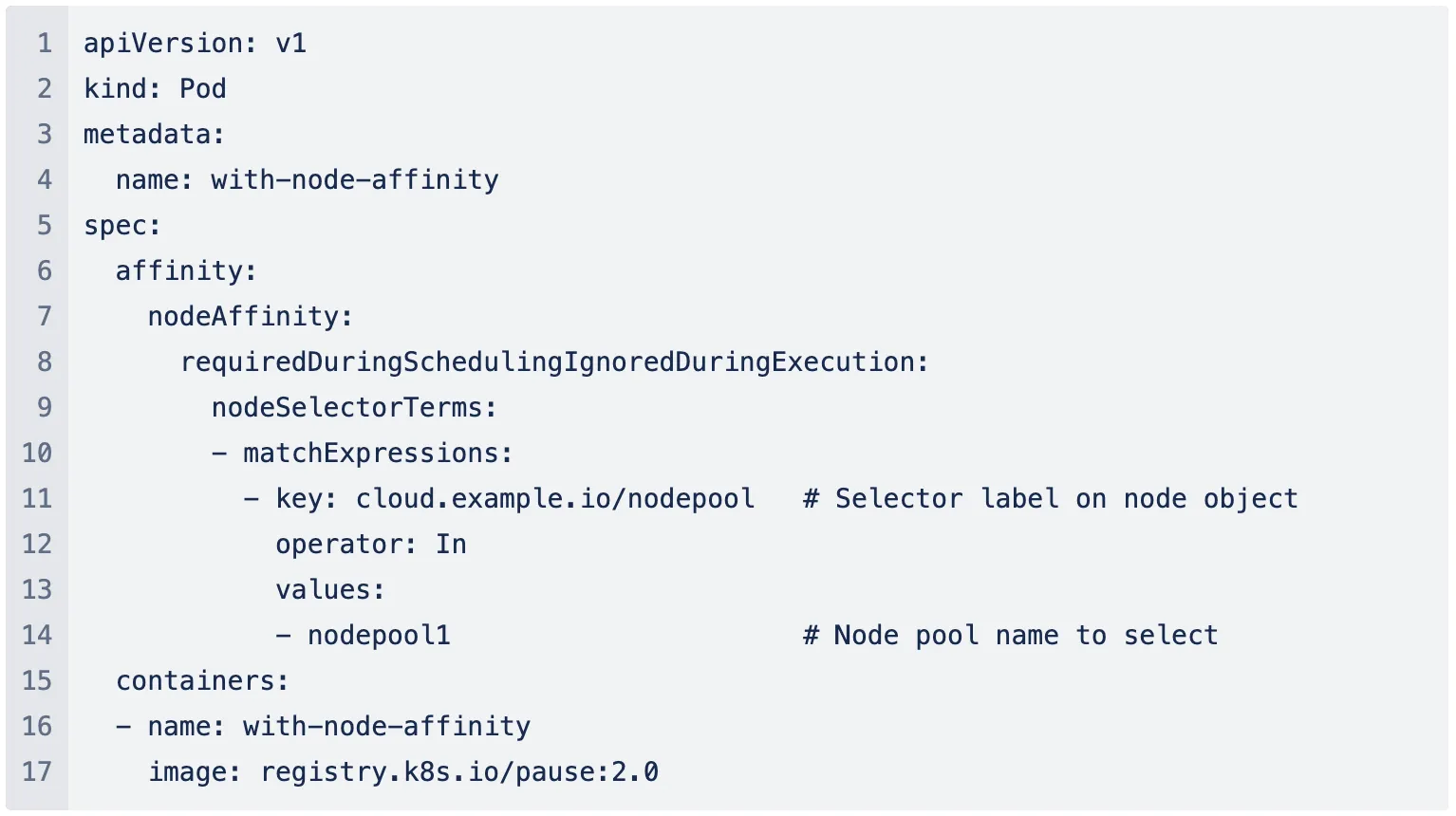
No geral, este mecanismo envolve os seguintes passos:
As combinações de requisitos de pools de nós podem ser numerosas, especialmente durante a fase de experimentação para cargas de trabalho de ML/LLM. A coordenação entre equipes separadas de DevOps e Plataforma pode consumir um tempo significativo durante o desenvolvimento. Portanto, um controlador que avalia dinamicamente os requisitos e provisiona automaticamente a infraestrutura torna-se crucial.
O auto-provisionamento de nós elimina a etapa manual de pré-criação de pools de nós, permitindo que os usuários adicionem requisitos de alto nível como restrições. Ele determina automaticamente o melhor tipo de máquina ou nó disponível para a carga de trabalho.

Algumas das restrições comumente usadas:
21000t4, a100sob demanda ou spotus-east-1alinux ou windowsarm64 ou amd64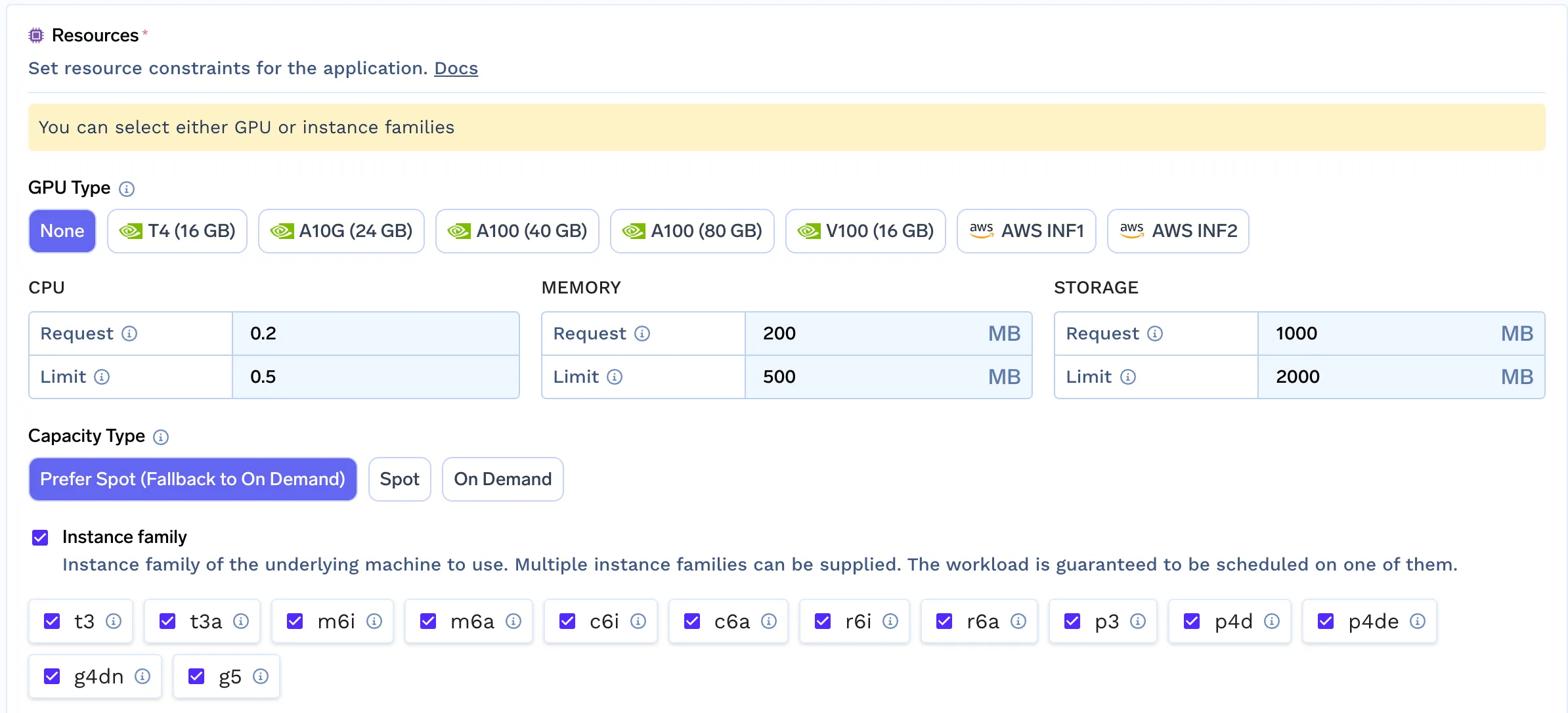
Cada provedor de nuvem oferece seus próprios mecanismos de auto-provisionamento. A AWS exige a instalação de ferramentas como o Karpenter, enquanto o GCP oferece uma solução integrada. A Azure introduziu recentemente seu projeto de auto-provisionador, atualmente em modo de pré-visualização.
Karpenter, um projeto de gerenciamento de ciclo de vida de nós de código aberto projetado para Kubernetes, que melhora significativamente a eficiência e a relação custo-benefício da execução de cargas de trabalho em clusters. Ao considerar restrições de agendamento, como solicitações de recursos, seletores de nós, afinidades, tolerâncias e restrições de distribuição de topologia, o Karpenter provisiona e desaloca nós de forma inteligente conforme necessário.
Provisionamento automático de nós, integrado ao autoscaler do cluster, dimensiona os pools de nós existentes com base nas especificações de Pods não agendáveis. O recurso de provisionamento automático do GCP garante a utilização ideal dos recursos, considerando CPU, memória, armazenamento efêmero, solicitações de GPU, afinidades de nós e seletores de rótulos.
O projeto de Provisionamento Automático de Nós (NAP), atualmente em modo de pré-visualização, aproveita o projeto de código aberto Karpenter para determinar a configuração ideal de VM para executar cargas de trabalho de forma eficiente e econômica. O NAP implanta e gerencia automaticamente o Karpenter em clusters AKS, proporcionando aos usuários uma experiência contínua.
💡
O Provisionamento Automático de Nós (NAP) para AKS está atualmente em PRÉ-VISUALIZAÇÃO. Estamos muito entusiasmados com este novo projeto e ansiosos para usá-lo para nossos clientes. Saiba mais
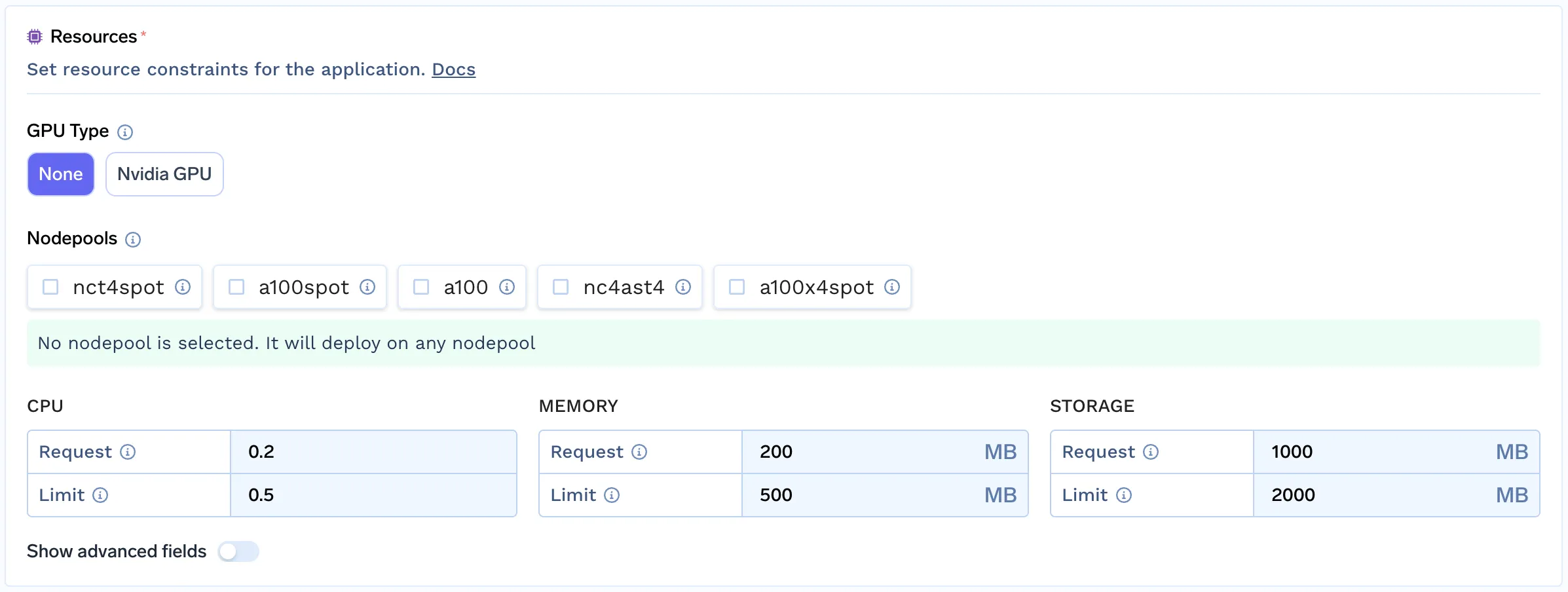
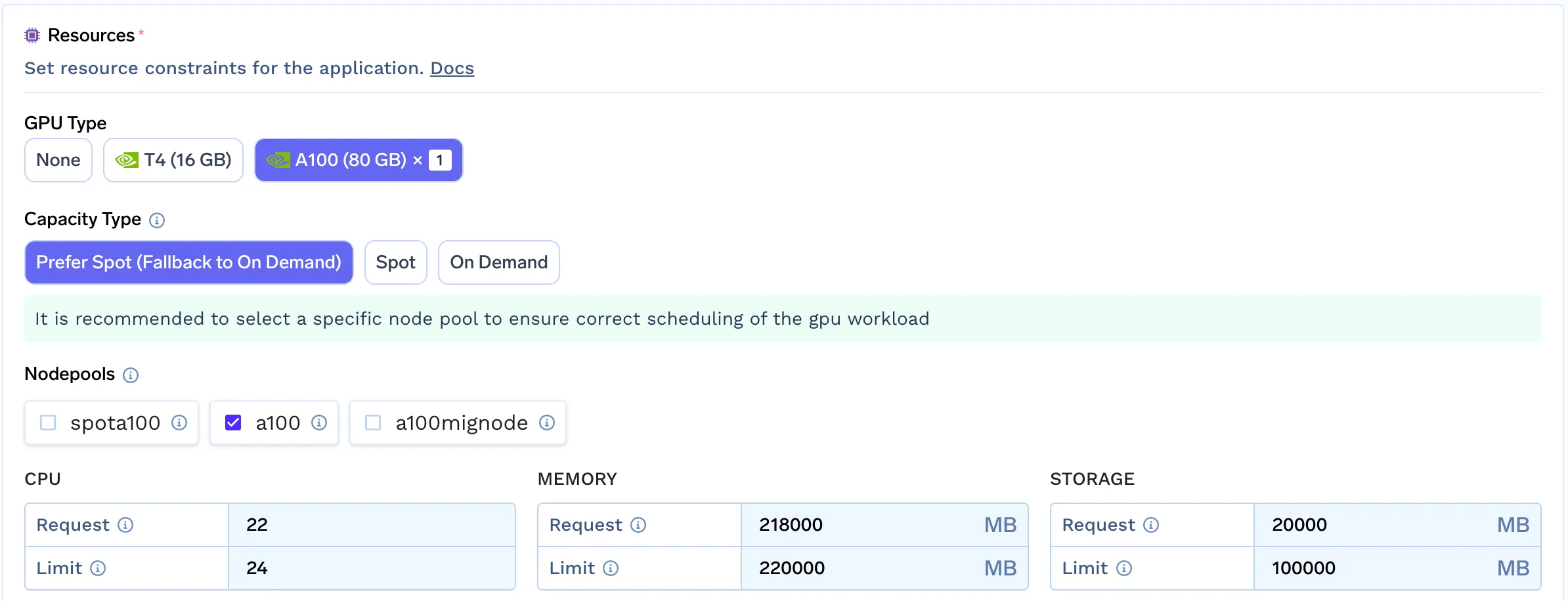
A TrueFoundry oferece recursos avançados de filtragem para pools de nós, simulando a experiência de provisionamento automático de nós.
Para conseguir isso, seguimos alguns passos simples:
Essa abordagem permite que Desenvolvedores/Cientistas de Dados selecionem o melhor pool de nós para sua carga de trabalho, analisando seus requisitos. Esse mecanismo simples nos permite fornecer a mesma experiência para qualquer nuvem que ainda não tenha suporte integrado para provisionadores automáticos.
À medida que os requisitos de infraestrutura continuam a evoluir, os provedores de nuvem dedicam-se a otimizar o processo de seleção da infraestrutura ideal para diversas cargas de trabalho. Na TrueFoundry, compartilhamos este compromisso ao nos esforçarmos para capacitar Desenvolvedores com as ferramentas e o conhecimento de que precisam para implementar as suas cargas de trabalho de forma contínua.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.




.webp)





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




