




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
É com entusiasmo que anunciamos que a TrueFoundry desenvolveu uma solução poderosa, mas fácil de usar, para a implantação e o ajuste de Grandes Modelos de Linguagem (LLM) através do nosso Catálogo de Modelos. Nosso objetivo é ajudar as empresas a auto-hospedar seus LLMs de código aberto no Kubernetes, tornando assim seus custos de inferência 10 vezes mais baratos com 1 clique. Neste blog, mostramos como você pode implantar um Dolly-v2-3b modelo e ajustar um Pythia-70M modelo usando a TrueFoundry.A plataforma TrueFoundry foi projetada para suportar modelos de Machine Learning e Deep Learning de todos os tipos, desde os mais simples, como Regressão Logística, até modelos de ponta como Stable Diffusion. Pode-se pensar, por que ela precisaria construir algo novo quando se trata de Grandes Modelos de Linguagem?
O tamanho e a complexidade desses modelos apresentam desafios significativos quando se trata de implantá-los em aplicações do mundo real. Embora a plataforma TrueFoundry já suportasse a implantação de modelos de todos os tamanhos em escala, percebemos que há mais otimizações (custo+tempo) e melhorias na experiência do usuário que poderíamos fazer para esses modelos.
Grandes modelos de linguagem (LLMs), como o ChatGPT, inquestionavelmente geraram um grande entusiasmo no campo da inteligência artificial.
Mas, ao conversar com mais de 50 empresas que já estão começando a colocá-los em produção, o valor que eles já estão criando é imenso. Acreditamos que o uso de LLMs só vai se expandir à medida que as pessoas descobrem novos casos de uso todos os dias.
Criar um caso de uso de Prova de Conceito com Grandes Modelos de Linguagem e APIs da OpenAI é fácil, mas quando você começa a pensar em produção 🚀, muitas outras considerações entram em jogo.
Para a maioria das empresas, construir a capacidade de engenharia para lidar com a complexa infraestrutura de GPU para servir LLMs de forma confiável é difícil e demorado. Além disso, a maioria das empresas quer modelos específicos que funcionem melhor para o seu caso de uso, para os quais precisam ajustar esses modelos. Isso pode ser tecnicamente desafiador e um empreendimento caro.
Nossa posição sobre o futuro dos LLMs é que os Modelos de Código Aberto serão o caminho a seguir. Leia mais sobre nossas opiniões sobre o assunto aqui. Decidimos aproveitar esta comunidade de inovadores em rápida evolução e ajudar a equipar as empresas para utilizar todo o valor desses LLMs de código aberto em suas organizações.
A TrueFoundry quer que nossos parceiros possam perceber toda a gama de vantagens que os LLMs de Código Aberto, ajustados para seu caso de uso específico, podem trazer para suas organizações:
No entanto, gerenciar e implantar modelos de código aberto em sua própria infraestrutura não é uma tarefa fácil. Embora implantação de LLM on-premise ofereça controle de dados incomparável, prontidão para conformidade e eficiência de custos a longo prazo, requer profunda experiência em orquestração de GPU, gerenciamento de Kubernetes e otimização de modelos.
Mas imagine se fosse tão fácil quanto conectar seus dados e alguns cliques?
Entendemos os desafios que as empresas enfrentam ao fazer a transição de provas de conceito de LLM para produção. Nosso objetivo é construir a camada que torna esse processo super fácil para nossos parceiros. Veja como fazemos isso:
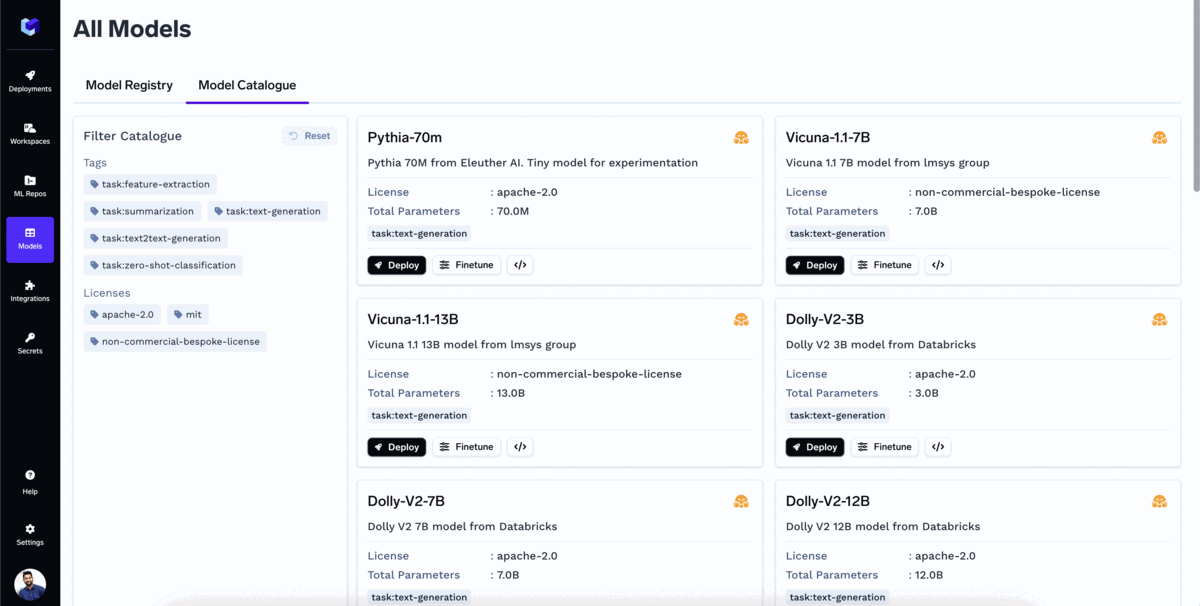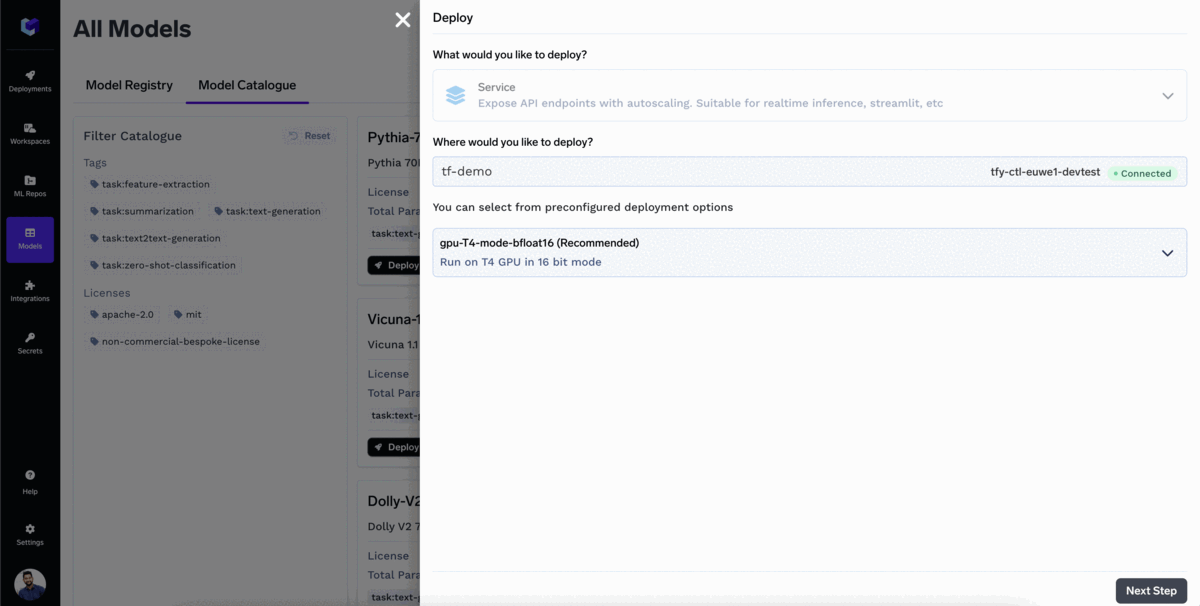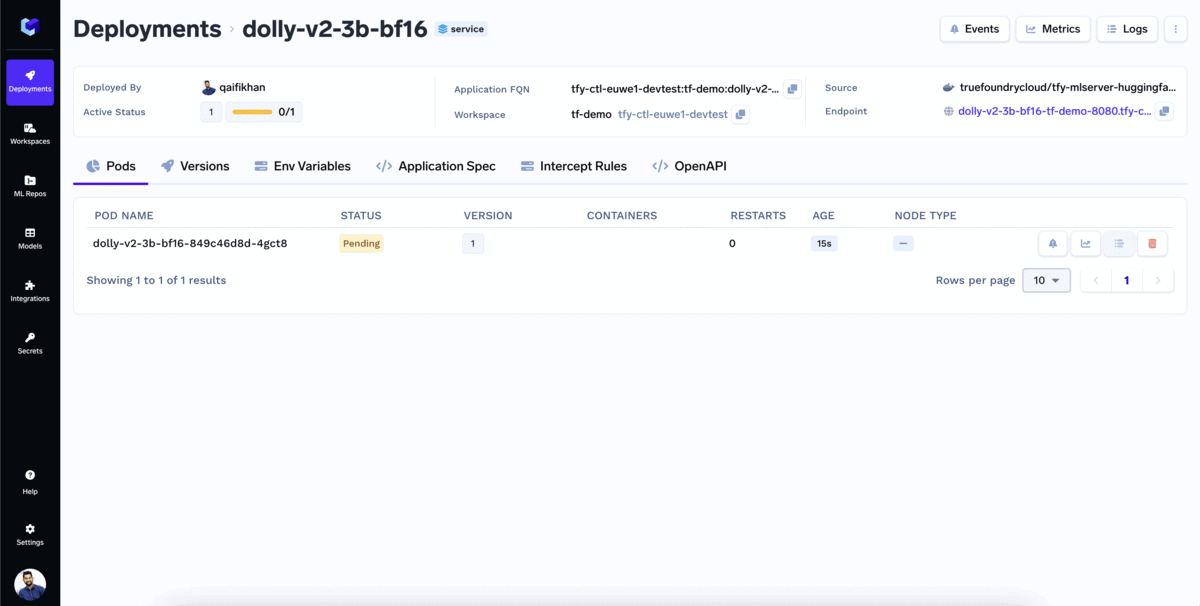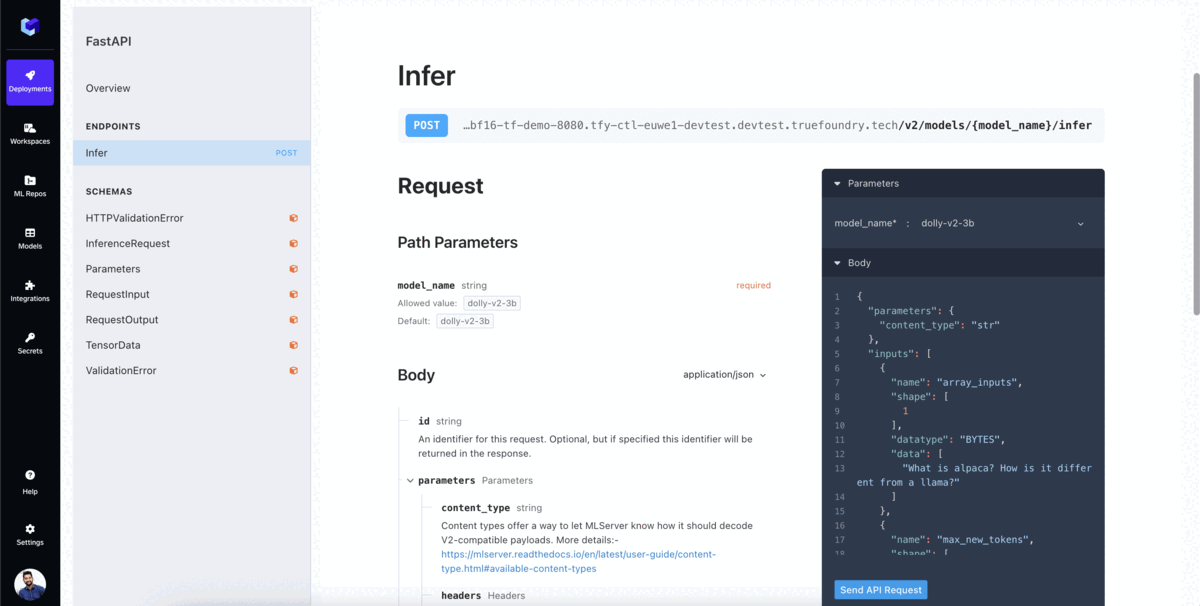
Da TrueFoundry Catálogo de Modelos é um repositório de todos os populares Modelos de Linguagem Grandes de Código Aberto (LLMs) que podem ser implementados com um único clique. O utilizador também pode ajustar o modelo diretamente a partir do catálogo de modelos.
O catálogo já suporta a maioria dos modelos populares, e estamos a adicionar suporte para mais todos os dias. Alguns dos modelos populares que já pode implementar na sua própria nuvem são:
E muitos mais.....
A nossa obsessão é que as empresas consigam lançar no primeiro dia. Para tornar isso possível, estes são os princípios nos quais estamos a construir as nossas capacidades de LLM:
ℹ️
Para um passo a passo detalhado dos fluxos de treinamento e ajuste fino na interface do usuário, consulte este vídeo do YouTube
Implantar seus LLMs é tão fácil quanto clicar três vezes!
🚀
Seu modelo foi implantado!
Iniciar Inferência com o endpoint da API do modelo. A TrueFoundry fornece a você a interface OpenAPI para testar seu modelo e o código de exemplo para chamar o modelo em suas aplicações.
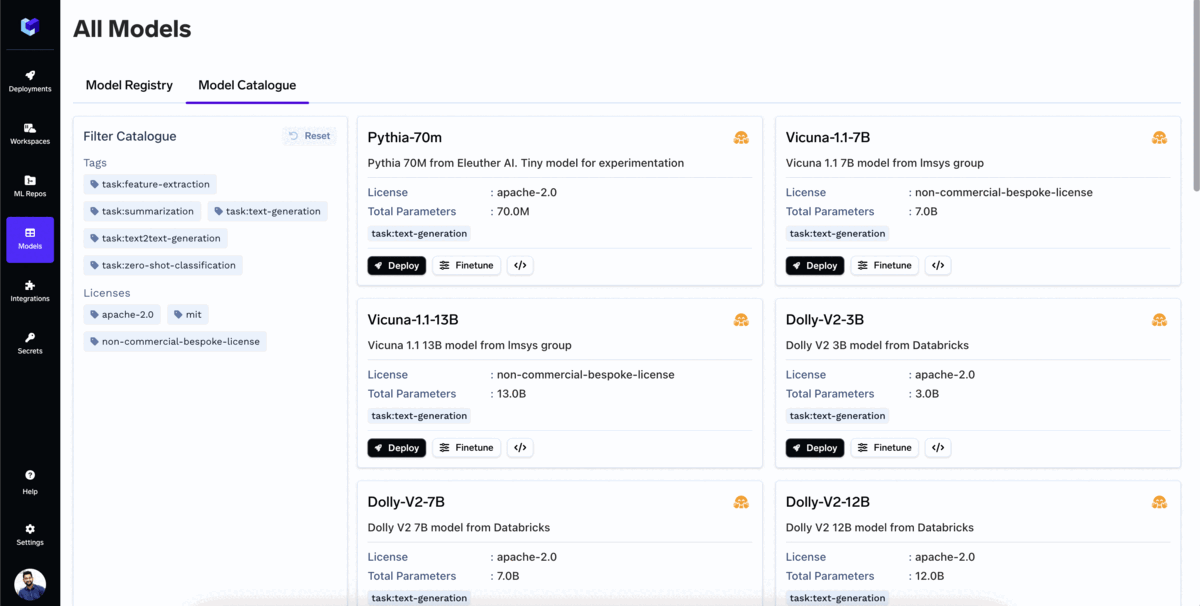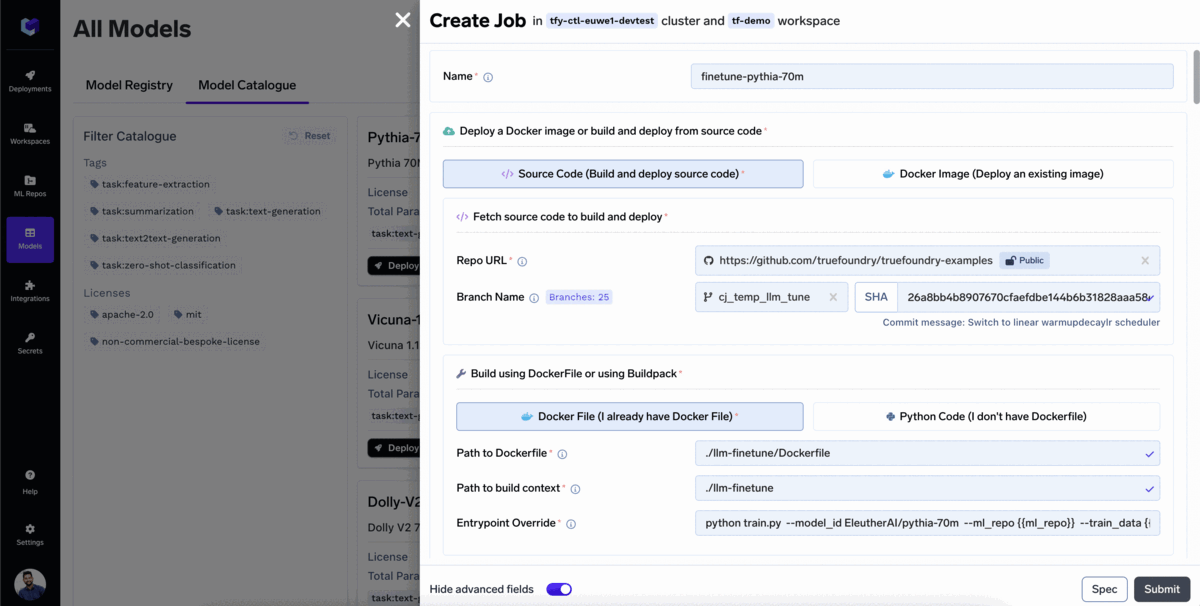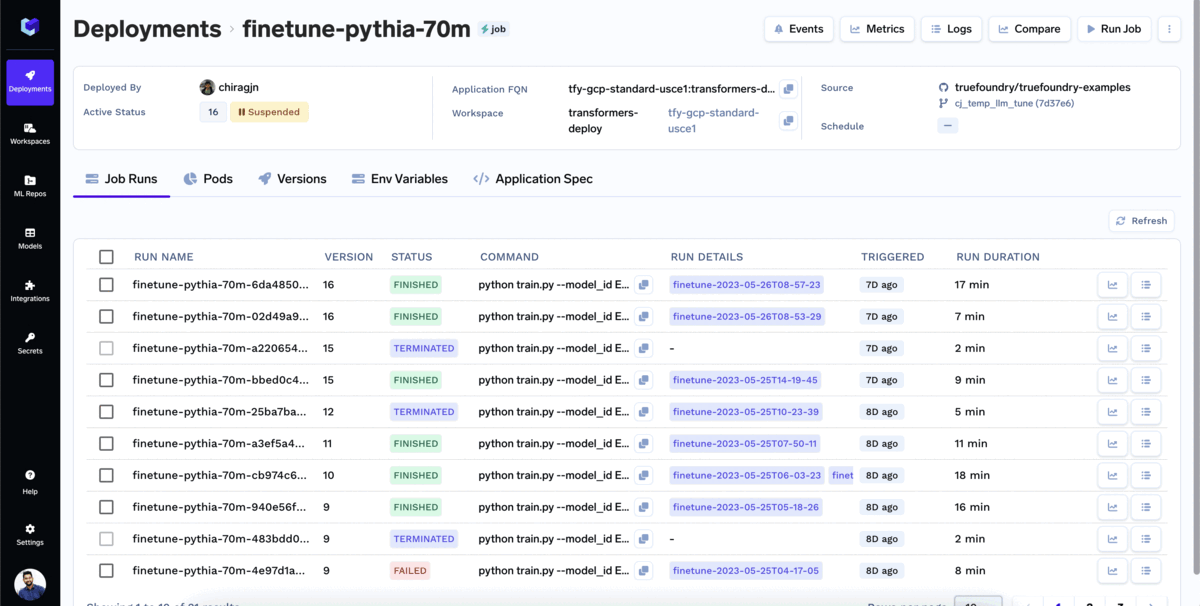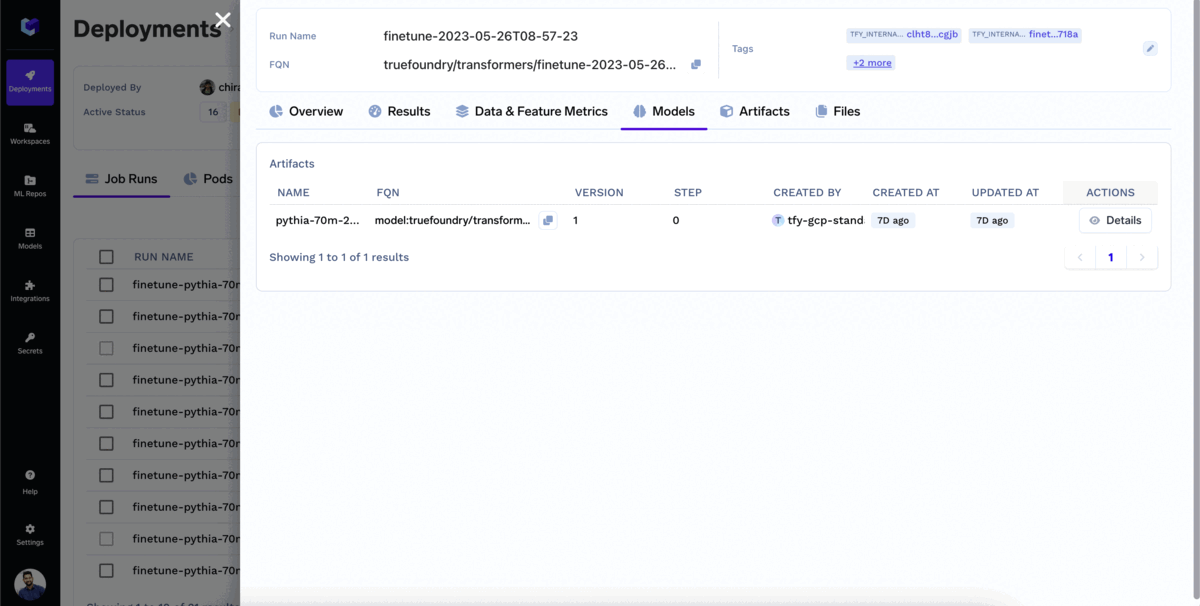
A maioria das empresas desejaria usar modelos com ajuste fino para seu caso de uso específico. Para fazer o ajuste fino de um modelo com TrueFoundry:
🚀
O modelo começou a fazer o ajuste fino!
Você pode monitorar o ajuste fino à medida que ele avança. Na aba de execuções de trabalho, você pode visualizar todas as informações relevantes associadas ao trabalho de treinamento, como métricas de perda, curvas de treinamento e resultados de avaliação. Isso permite que você acompanhe o processo de ajuste fino e tome decisões informadas com base no desempenho do trabalho.
Este é apenas o começo da nossa jornada com Modelos de Linguagem Grandes (LLMs) e IA Generativa. Estamos planejando construir muito mais nos próximos dias e manteremos vocês informados!
Ainda estamos aprendendo sobre este assunto, assim como todos. Caso você esteja buscando aplicar Modelos de Linguagem Grandes na sua organização, adoraríamos conversar e trocar ideias.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




