




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
%20(11).webp)
Blazingly fast way to build, track and deploy your models!
Prompting, Fine-tuning e Geração Aumentada por Recuperação (RAG) são as técnicas de aprendizado de LLM mais populares. Escolher a técnica certa envolve uma avaliação cuidadosa dos requisitos, recursos e resultados desejados do seu projeto.
Nas seções seguintes, aprofundaremos em cada técnica, discutindo suas complexidades, aplicações e como decidir qual é a mais adequada para suas necessidades

O primeiro passo para decidir entre prompting, fine-tuning e RAG é examinar cuidadosamente os dados à sua disposição e o problema específico que você pretende resolver. Considere se sua tarefa envolve conhecimento geral, informações especializadas ou requer dados atualizados de fontes externas. A complexidade do problema, o estilo e o tom da saída desejada, e o nível de personalização necessário também são fatores críticos.
Se você está lidando com tópicos altamente especializados ou de nicho, fine-tuning ou RAG podem ser necessários para atingir o nível desejado de precisão e relevância. Por outro lado, se seu projeto envolve consultas mais gerais ou criação de conteúdo, o prompting pode ser suficiente e mais econômico.
A escolha entre prompting, fine-tuning e RAG também depende de restrições orçamentárias. O prompting é geralmente o menos intensivo em recursos, pois usa o modelo como está. O fine-tuning requer dados adicionais e recursos computacionais para o treinamento, resultando em custos mais altos. O RAG também pode ser intensivo em recursos, especialmente se envolver a configuração e manutenção de um banco de dados externo para recuperação.
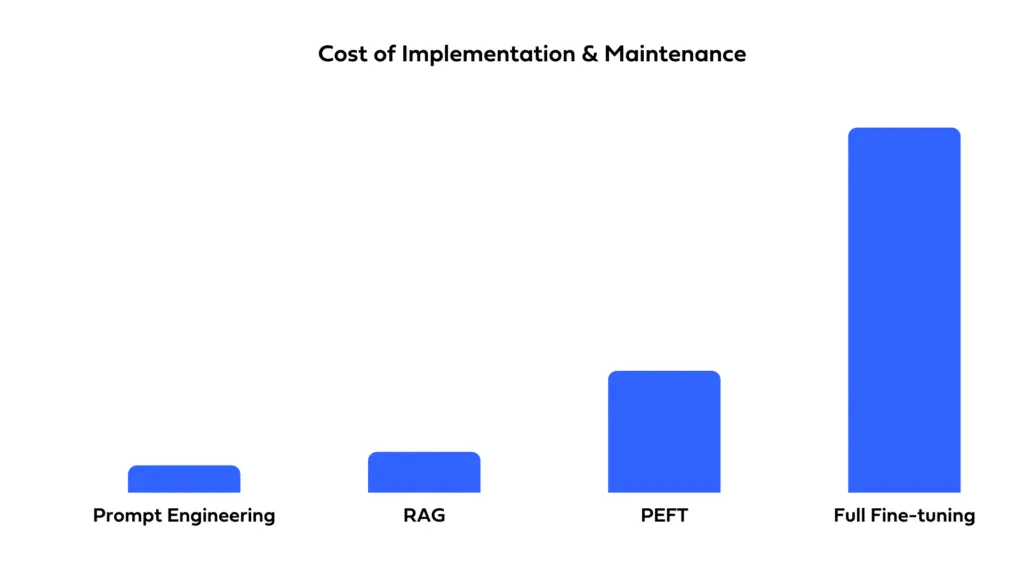
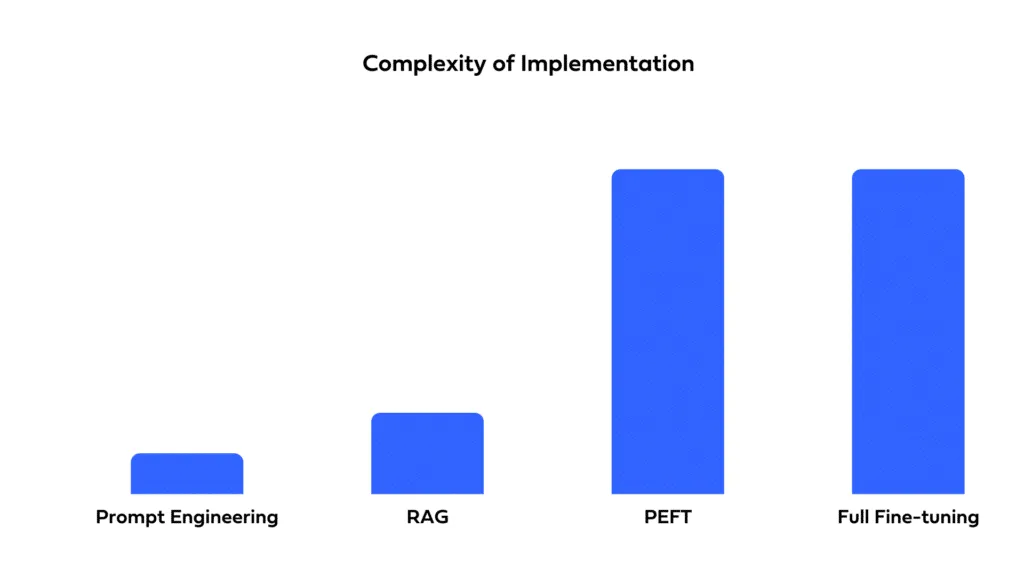
Considere a rapidez com que você precisa implantar sua solução e os recursos disponíveis. O prompting permite uma implantação rápida com tempo mínimo de configuração. O fine-tuning, embora possa oferecer melhor desempenho, requer tempo para treinamento e otimização. O RAG envolve a complexidade de integrar fontes de dados externas, o que pode estender os prazos de desenvolvimento e exigir experiência especializada.
O RAG facilita a atribuição da fonte, capacitando os usuários a discernir a origem das informações utilizadas na geração da resposta. Prompting e Fine-tuning atuam como uma caixa preta, dificultando o rastreamento das respostas.

O prompting é ideal para projetos que exigem soluções rápidas e econômicas e podem contar com a base de conhecimento geral de modelos pré-treinados. É adequado para aplicações como:
Embora a criação de prompts seja altamente acessível, pode nem sempre fornecer a precisão ou personalização necessárias para tarefas especializadas. A qualidade dos resultados pode variar significativamente com base no design do prompt, exigindo uma elaboração e testes cuidadosos.
O fine-tuning é o método de eleição quando o seu projeto exige um alto grau de especificidade ou precisa de se alinhar de perto com estilos, tons ou conhecimentos específicos de um domínio. É particularmente eficaz para:
A decisão de fazer fine-tuning deve considerar a compensação entre o desempenho melhorado e os custos e recursos adicionais necessários. É essencial para projetos onde o valor da personalização e precisão supera estas considerações.
O RAG se destaca em situações onde as respostas precisam ser aumentadas com as informações mais recentes ou dados detalhados de domínios específicos. É particularmente adequado para:
O RAG pode oferecer resultados superiores para consultas complexas e áreas de conhecimento especializadas, mas acarreta maior complexidade e necessidade de recursos. É a escolha certa quando o escopo do projeto justifica o investimento na configuração e manutenção da infraestrutura necessária para a recuperação de dados em tempo real.
O prompting é habilitado pelo nosso LLM Gateway módulo, que suporta fluxos de trabalho frequentemente associados às melhores ferramentas de engenharia de prompts usadas para aplicações LLM em produção. O LLM Gateway oferece uma API unificada que permite aos usuários acessar vários provedores de LLM, incluindo seus próprios modelos auto-hospedados, por meio de uma única plataforma. Ele apresenta funcionalidades centralizadas de gerenciamento de chaves, autenticação e atribuição de custos. Além disso, oferece suporte para fallback, retentativas, bem como integração com guardrails.
Nós padronizamos o fluxo de trabalho para configurar o RAG com apenas alguns cliques. Leia nosso blog sobre como implantar um Chatbot baseado em RAG usando TrueFoundry. Ele gerencia o processo de ponta a ponta de inicialização de um banco de dados vetorial, modelo de embedding, LLMs e assim por diante, ao mesmo tempo que oferece os controles certos para personalizar o fluxo de trabalho de acordo com suas necessidades.
A TrueFoundry simplificou o processo de ajuste fino , abstraindo todas as complexidades e configurando as configurações de recursos adequadas para as técnicas LoRA/QLoRA. Você pode implantar um notebook Jupyter de ajuste fino para experimentação ou iniciar um trabalho de ajuste fino dedicado. Leia o guia detalhado aqui.
Nós da TrueFoundry apoiamos todas as três técnicas de aprendizado de LLM – prompting, RAG e ajuste fino – de maneira extremamente otimizada.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




