



June 26, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
Braintrust has become a serious observability platform for AI evaluation and production tracing. Its strengths are clear: teams can trace production behavior, run evals, compare prompts and models, manage datasets, and convert real failures into regression checks. For engineering teams that want rigorous evaluation workflows, Braintrust remains a strong option.
Still, teams compare Braintrust alternatives when their needs move beyond evaluation alone. Some need cheaper pricing at high trace volume. Some want open source self-hosting. Others need runtime governance that enforces model access, cost controls, agent policies, MCP permissions, and audit evidence before production traffic reaches providers.
This guide compares seven Braintrust competitors in 2026, explains what each tool does well, and clarifies where each one stops. The goal is not to claim that every team should replace Braintrust. The goal is sharper: help LLM teams choose the right layer for the problem they are solving.
Before comparing tools, define the selection criteria. Braintrust alternatives are not interchangeable because each one solves a different layer in the LLM lifecycle. A strong Braintrust alternative should match the missing capability in your current operating model.
Language and integration coverage also matter. Teams should check support for Python, TypeScript, Ruby, and Java workflows, especially when application code spans several services. A single platform may look attractive until instrumentation, SDK coverage, and team workflows create friction.

The top Braintrust alternatives in 2026 fall into three broad groups. Some focus on evaluation and prompt quality. Some focus on tracing and observability. Others add runtime governance for production traffic, agents, tools, and cost controls.
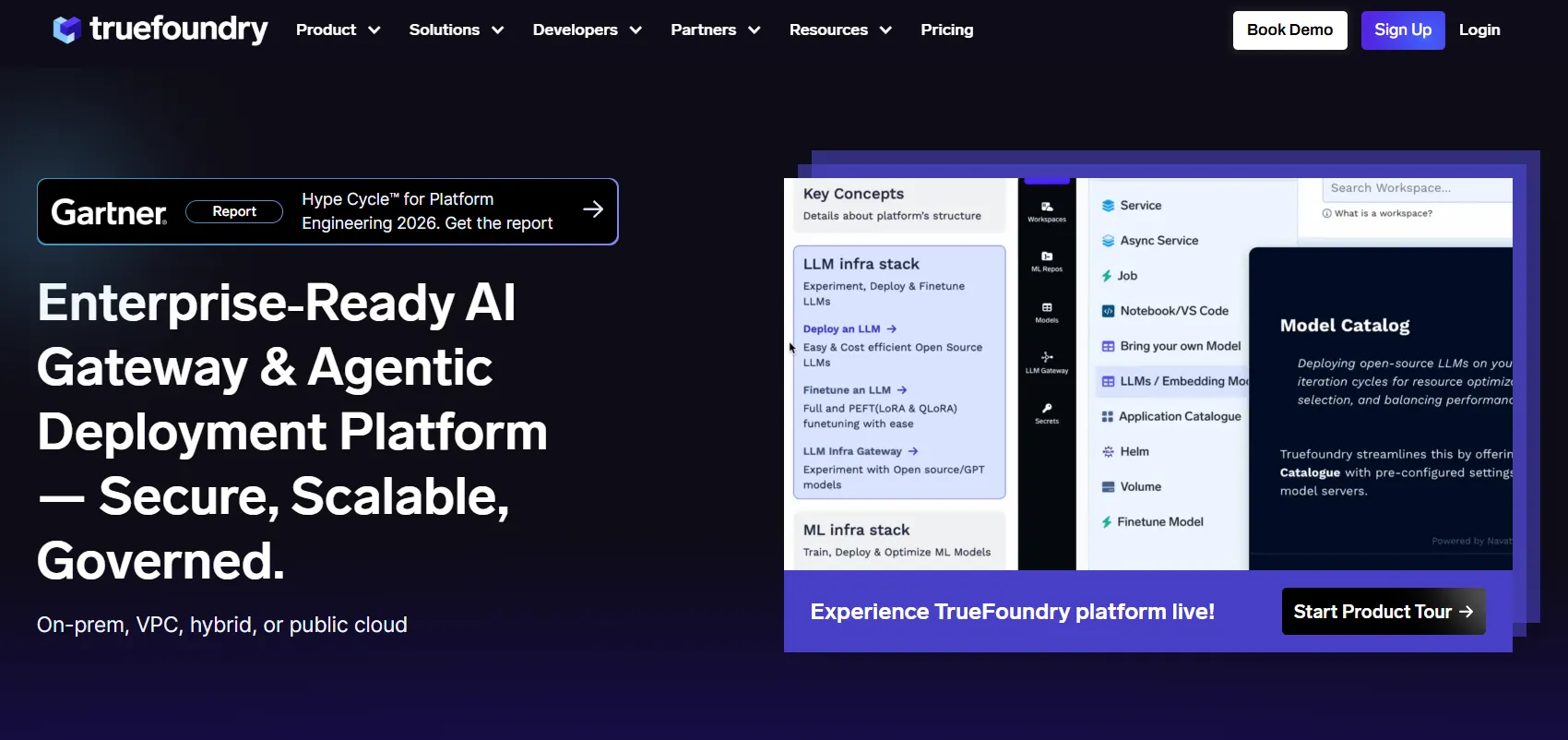
TrueFoundry is the best Braintrust alternative when the main gap is production governance rather than offline evaluation. It approaches the LLM stack from the infrastructure layer, where model access, routing, observability, agent policies, MCP tool control, and cost enforcement happen before production traffic reaches providers.
Unlike pure evaluation tools, TrueFoundry helps teams govern what runs in production. Its AI Gateway centralizes access, policy checks, monitoring, routing, failover, rate limits, and audit evidence. This makes it relevant when evaluation exists, yet runtime governance remains fragmented.
TrueFoundry pricing includes a Developer plan at $0 for early builders, Pro at $499 per month, Pro Plus at $2,999 per month, and custom Enterprise pricing. Enterprise is designed for stricter governance, security, deployment flexibility, and mission-critical reliability.
TrueFoundry is best for enterprise AI platform teams and regulated organizations with multi-team LLM programs. It is especially relevant when evaluation exists, yet production access, identity, cost, and audit controls remain fragmented.
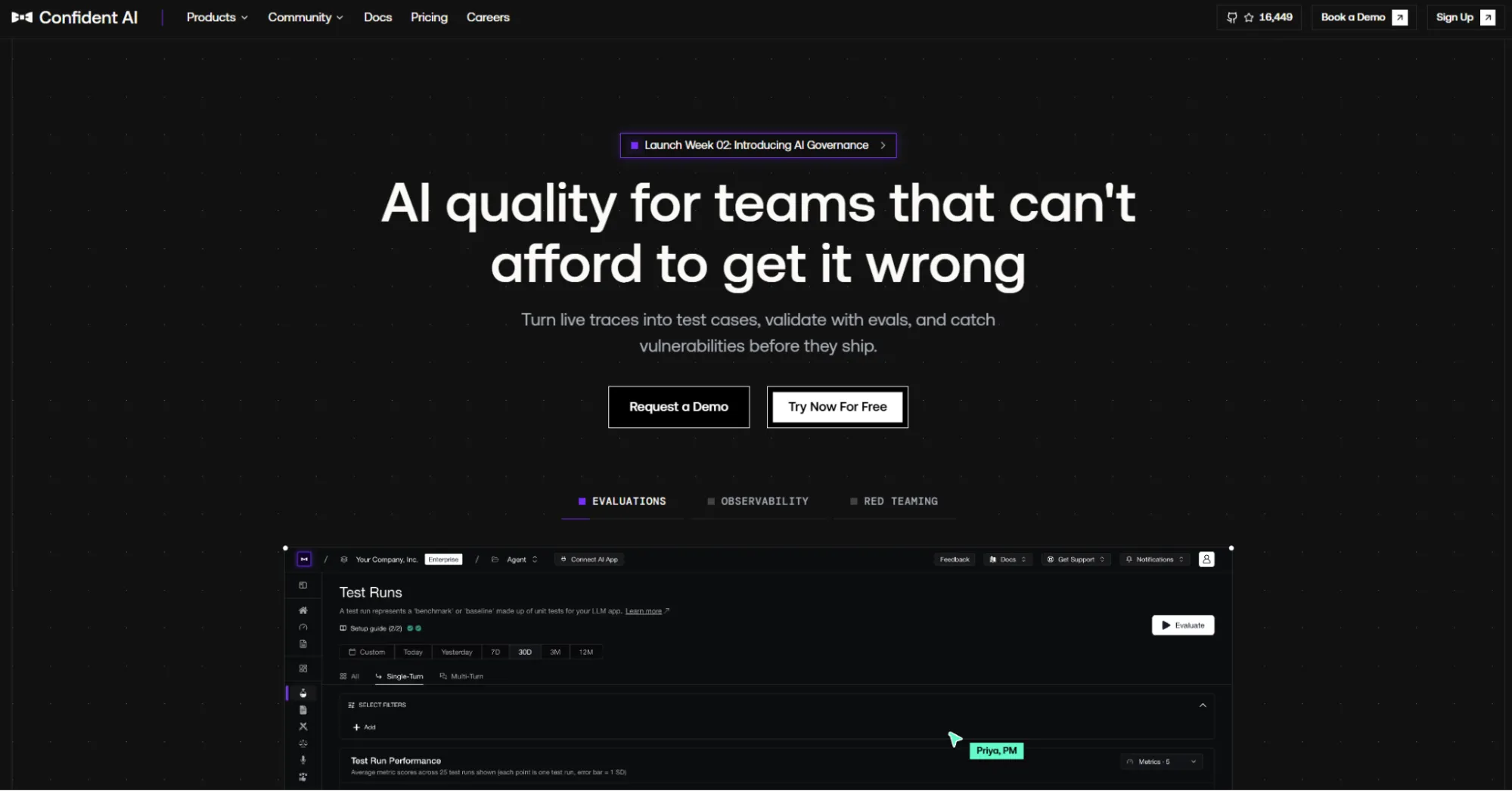
Confident AI is a strong Braintrust alternative for teams that want product-quality evaluation workflows around real LLM applications. It builds on DeepEval, the open-source LLM evaluation framework, and adds collaboration, tracing, monitoring, dashboards, and team workflows.
Confident AI is best for teams that need evaluation depth and broader participation from QA or product teams. It suits groups that connect pre-release tests with production-quality monitoring.
Confident AI is primarily an evaluation and quality platform. Teams should not treat it as a full runtime governance or AI infrastructure control plane without directly validating deployment, access control, and policy needs.
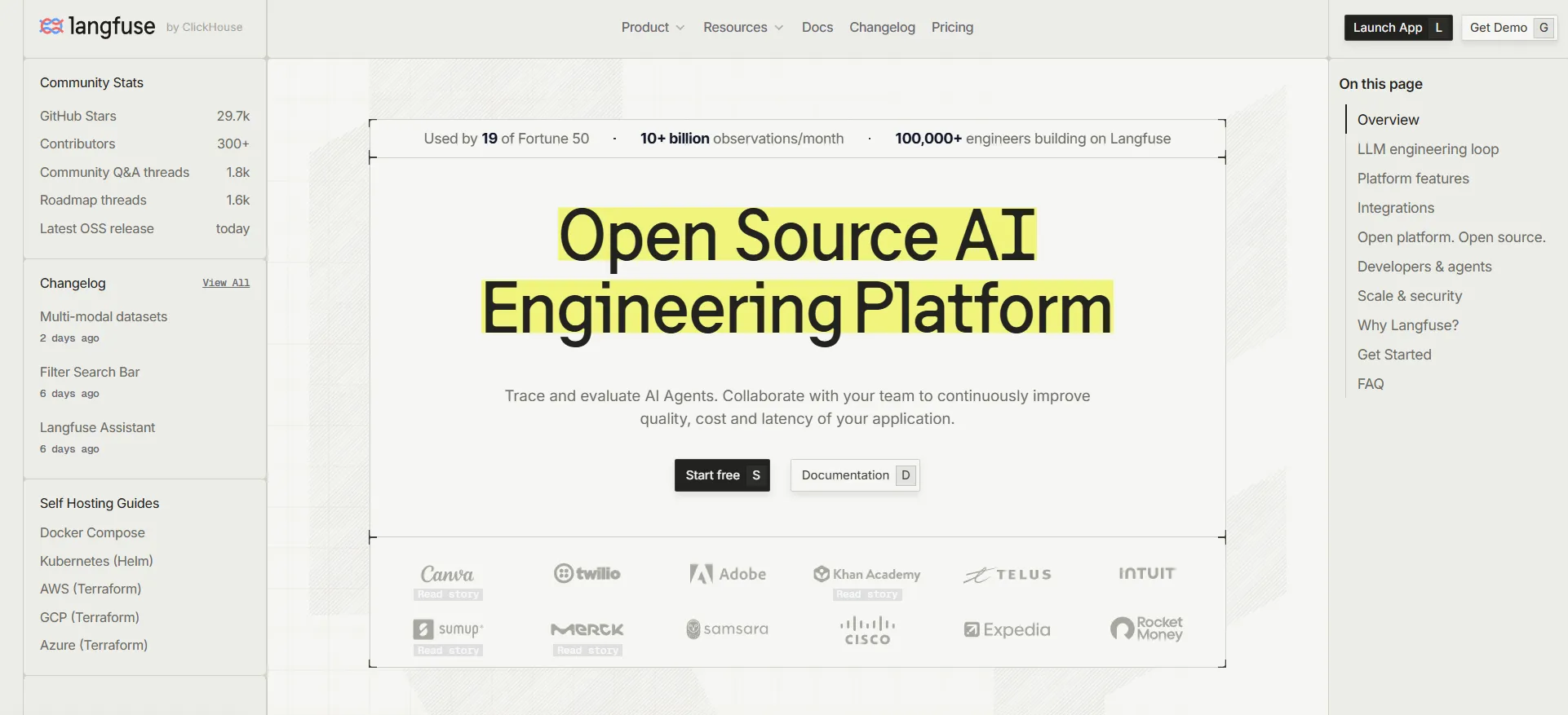
Langfuse is one of the strongest open-source alternatives to Braintrust for teams that want LLM observability, tracing, prompt management, datasets, and evaluation workflows with self-hosting control. It also appeals to teams tracking GitHub stars as a community-adoption signal.
Langfuse is best for platform teams that want open-source control, self-hosting, and broad observability coverage. It fits teams that prefer owning their observability stack.
Self-hosting creates a real operational tradeoff. Teams must own scaling, upgrades, storage, security hardening, incident response, and long-term reliability for the observability stack.
.webp)
.webp)
LangSmith is a practical Braintrust competitor for teams already building with LangChain or LangGraph. It reduces instrumentation friction and gives developers tracing, debugging, datasets, evaluations, and monitoring inside the LangChain ecosystem.
LangSmith is best for teams using LangChain or LangGraph heavily. It fits developers who want minimal integration friction and strong debugging workflows.
LangSmith is less attractive for teams prioritizing vendor-neutral observability, open-source self-hosting, or infrastructure-level governance across non-LangChain systems.
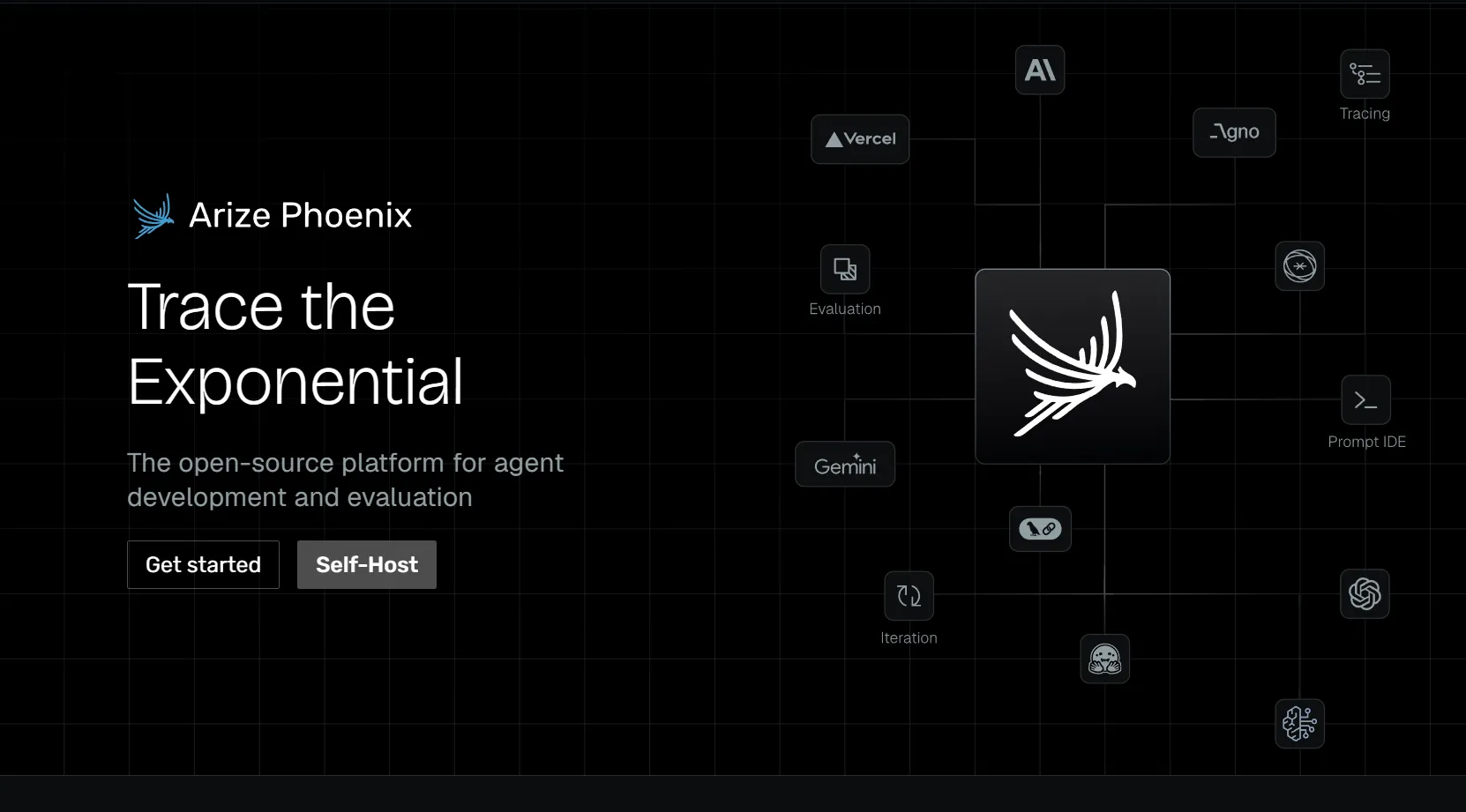
Arize Phoenix is an open-source AI observability and evaluation platform. It is especially relevant for teams that value OpenTelemetry-based instrumentation, RAG evaluation, retrieval debugging, experimentation, and troubleshooting workflows.
Teams with platform engineering capacity that want open-source LLM observability and evaluation tooling with strong trace and experimentation workflows.
Phoenix is powerful, but production-grade enterprise operations may require additional platform work or a commercial Arize deployment, depending on scale, security, and support needs.
W&B Weave is a logical Braintrust alternative for teams already using Weights & Biases for ML experiment tracking. It extends the W&B ecosystem into LLM observability, evaluation, tracing, and agent workflows across production AI systems.
W&B Weave is best for ML teams already standardized on W&B. It also fits teams tracking NVIDIA-backed model workflows and LLM applications in one operating model.
Weave is strongest when W&B already supports the team’s ML operating model. For pure LLM evaluation or self-hosted observability, Langfuse, Phoenix, or Braintrust may be simpler to evaluate.
.webp)
Helicone is a lightweight AI gateway and LLM observability platform. It is a strong option for developer teams that want fast setup, OpenAI-compatible routing, request logging, cost tracking, caching, and rate limits without having to build deep instrumentation from scratch.
Helicone is best for startups and engineering teams that want fast LLM observability and cost tracking. It fits teams avoiding heavy platform implementation work.
Helicone is not primarily a deep offline evaluation workbench or enterprise AI governance platform. Regulated teams should validate identity, audit, data control, and policy enforcement needs before adopting it as the sole layer.
The biggest trap in this category is assuming evaluation, observability, and governance are the same thing. They are related, although they are not identical. That distinction matters when teams evaluate Braintrust alternatives for production AI systems.
The practical question is therefore not “Which tool is best?” It is “Which layer is missing from our current LLM operating model?” If the gap is unified model access and request governance, an LLM Gateway becomes more relevant than another eval workbench.
.webp)
Braintrust is not weak. It is a strong AI observability and evaluation platform, and its gateway adds unified model access, caching, observability, and multi-provider support. A credible comparison should acknowledge Braintrust’s strengths before discussing Braintrust alternatives.
The right alternative depends on which layer is missing. If the gap is self-hosting, Langfuse and Phoenix deserve attention. If the gap is evaluation depth and cross-functional quality workflows, Confident AI is serious. If the team lives in LangChain, LangSmith is the low-friction path.
If the team already uses W&B, Weave is a natural fit. If the need is lightweight gateway observability, Helicone is attractive. Each option is a valid Braintrust competitor when its operating model matches the actual problem.
For enterprise teams whose gap is production governance, TrueFoundry is the strongest fit in this list. It is positioned for teams that need to govern model access, agent actions, MCP tools, cost limits, observability, and audit evidence through an infrastructure control layer.
This does not mean TrueFoundry replaces every evaluation workflow. It means TrueFoundry can complement an existing evaluation stack when production access, cost, identity, and audit controls need stronger enforcement. That is the difference between observing AI quality and governing AI risk.
Book a demo to see how TrueFoundry governs AI workloads before they reach production risk.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.



.webp)

.webp)
.webp)
.webp)
.png)






.webp)
.webp)


