



June 25, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 25, 2026

Blazingly fast way to build, track and deploy your models!
Of all the lines the agent glossary draws, the one between tools, skills, and sub-agents is the blurriest — the glossary itself admits the boundary shifts across frameworks. But the spectrum underneath is stable and worth engineering around: a tool is an action, a skill is a packaged procedure, a sub-agent is a delegate that reasons. Those are three different kinds of delegation, and — the part most architectures miss — three different governance problems. Authorize a tool, version a skill, give a sub-agent an identity: get the rung wrong and you'll govern a reasoning delegate like a function call, which is how blast-radius surprises are made.
Ingrid, a staff engineer, was reviewing an agent before it touched production when she hit a line in its tool list that stopped her: one "tool" was not a tool. Nine entries were honest function calls — query the order database, post a Slack message. The tenth, "resolve-customer-issue," was an entire second agent wearing a tool's name tag: it had its own prompt, its own model call budget, its own tool access, and it reasoned for up to fifteen steps before returning a string. It had inherited the parent's permissions wholesale — the failure mode a governed setup avoids by scoping the delegate explicitly rather than letting it inherit the parent's grants — appeared in traces as a single opaque call, and had been security-reviewed as "a tool" — which is to say, not really reviewed at all. Nothing about it was malicious. Everything about it was misfiled.
Misfiling is the failure mode this vocabulary exists to prevent. The Hugging Face agent glossary — whose terms this series follows, mapped to infrastructure in our anchor post — separates the three cleanly while admitting frameworks blur them. This post takes the spectrum rung by rung: what each one is, when to reach for it, and the governance surface each one demands. Because Ingrid's tenth entry wasn't a naming problem. It was a delegation problem filed under the wrong governance regime.
A tool is an action. The model emits a structured request — call this function with these arguments — and the harness executes it: an API call, a database query, a shell command, a web fetch. The result comes back into context and the loop continues. The tool doesn't reason; it runs. Everything the model knows about it is its description, and the call itself is a discrete, inspectable event with arguments in and a result out.
A skill is packaged knowledge. Where a tool is "run this command," a skill bundles what's needed to accomplish a goal — investigate this class of bug, produce this kind of report — typically as structured instructions and procedure (the SKILL.md pattern) loaded into the agent's context on demand. A skill doesn't execute anything by itself; it shapes how the agent uses the tools it has. It's scaffold, made portable and reusable across agents.
A sub-agent is a delegate. The calling agent hands off a subtask to another agent — one with its own model, its own scaffold, its own context window, possibly its own tools — which reasons through the work independently and returns a result. The parent receives the result rather than managing every intermediate step, the way a manager doesn't keystroke for a direct report. That opacity is the point, and also the governance problem. The distinction from a tool is exactly the one Ingrid tripped over: a tool executes; a sub-agent decides, and can itself use tools, and can be wrong in open-ended ways a function cannot.
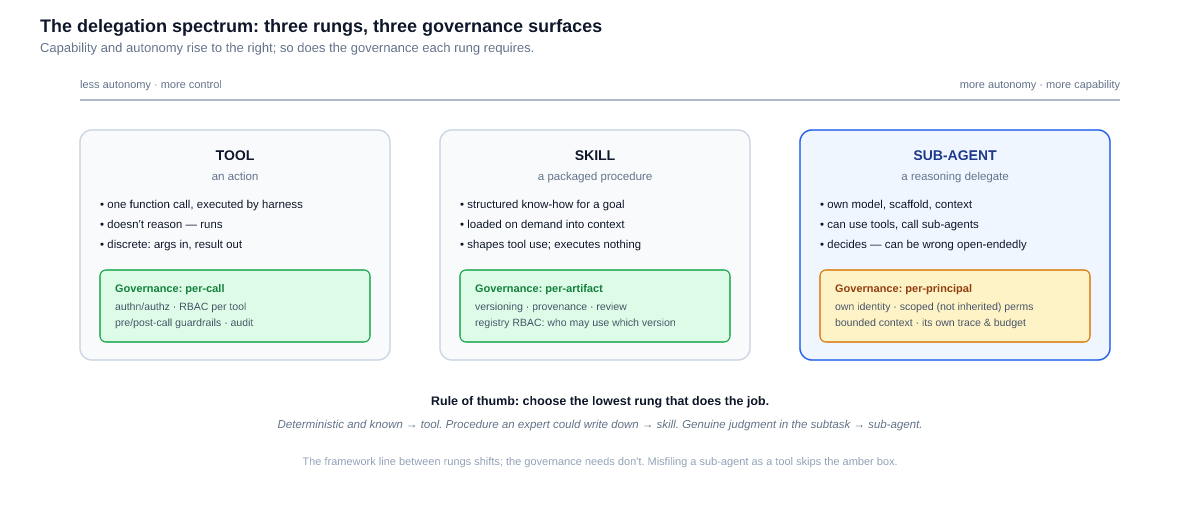
The spectrum trades control for capability as you climb. A tool is maximally legible — its behavior is its implementation, its invocation is one auditable event — and minimally capable: it handles exactly what it was coded for. A sub-agent is maximally capable — it can absorb ambiguity, adapt mid-subtask, recover from surprises — and minimally legible: its behavior emerges from a model reasoning in a context you don't see from the parent. A skill sits between: it raises the agent's competence at a class of task without adding a new delegated principal.
That gives a clean selection heuristic: choose the lowest rung that does the job. If the subtask is deterministic and well-specified — fetch this record, run these tests — it's a tool; wrapping it in a sub-agent adds cost, latency, and an open-ended failure mode for nothing. If the subtask is a procedure a domain expert could write down — triage a bug this way, structure the report like this — it's a skill: the parent agent's own reasoning, upgraded with packaged know-how, no delegation needed. Reserve the sub-agent for subtasks that need genuine judgment with their own working state — deep-dive this log corpus, research this question — where the work would either overwhelm the parent's context or requires reasoning the parent shouldn't interleave with its main thread. Ingrid's misfiled delegate, judged by this heuristic, was legitimately a sub-agent; the error was never the rung, it was the filing.
Because a tool is a discrete executed action, its governance unit is the call. Three questions attach to every invocation: is this caller authenticated, is this caller authorized for this tool, and is this particular call acceptable — the last covering both inbound arguments (an injected instruction smuggled into a parameter) and the outbound result (a secret or PII in the response). That's the per-call surface, and it's exactly what an MCP gateway exists to provide: a registry so agents reach only sanctioned tools, central authentication so agents don't carry per-tool credentials, RBAC per tool, and pre/post-call guardrails with a per-call audit trail. TrueFoundry's MCP Gateway implements this rung end to end, including curated least-privilege tool surfaces per role via virtual MCP servers.
One scaffold-layer note belongs here because it's among the most frequent tool failures in practice: the model selects tools purely from their descriptions, so a vague or overlapping description produces misuse that no per-call check will catch — the call is authorized, well-formed, and wrong. Treat tool descriptions as reviewed, versioned scaffold, and treat a tool that keeps being misused as having a documentation bug before assuming the model has a reasoning one.
A skill executes nothing, so per-call governance has nothing to grab; its governance unit is the artifact. The questions that matter are provenance and versioning: who wrote this procedure, who reviewed it, which version is each agent running, and what changed between versions — because a skill is behavior, and an unreviewed edit to a widely used skill is a silent behavior change across every agent that mounts it. The failure mode of ungoverned skills is the failure mode of ungoverned copy-paste: procedures forked into private variants, stale versions running indefinitely, and no way to answer "which agents are affected?" when a procedure turns out to be wrong.
The fix is the same one code got: a registry. TrueFoundry's Skills Registry treats skills as versioned SKILL.md artifacts with RBAC — published, reviewed, version-pinned by agents, and mounted into context on demand rather than pasted into every definition. On-demand mounting matters twice: it's a context-engineering win (the procedure costs window space only when relevant) and a governance win (the registry knows exactly which agents use which skill at which version, so the "which agents are affected" question has an answer). A skill in a registry is institutional knowledge; a skill in a paste buffer is a rumor.
A sub-agent reasons, so neither the call nor the artifact is the right governance unit — the principal is. Four properties make a sub-agent governable, and all four were missing from Ingrid's tenth entry. Identity: the sub-agent acts as itself, not anonymously inside its parent, so its actions are attributable. Scoped permissions: it gets the tools its subtask needs — not the parent's grants by inheritance; a log-analysis delegate has no business with the parent's write access to the order system. Bounded resources: its own step and token budgets, so a delegate that wanders can't silently consume the parent's run (the loop-prevention concern of our multi-agent post, one level down). Its own trace: the parent's record shows the delegation and the result; the sub-agent's record shows the fifteen steps in between — an opaque single line in a trace is exactly how a misfiled delegate hides.
This is the rung where the harness earns its keep, because these properties are runtime properties. TrueFoundry's Agent Harness runs sub-agents as first-class parts of its context-engineering machinery: each delegate works in an isolated context window and returns conclusions, not transcripts, to the parent — and each appears in the per-step trace with its own model calls, tool calls, and cost. Delegation without per-principal governance is how one agent's permissions quietly become an org chart of unaudited copies; delegation with it is just good decomposition.
There's a second axis running through the spectrum that has nothing to do with safety and everything to do with quality: what each rung costs the parent's context window. A preloaded tool costs its description on every step it’s exposed (each preloaded tool description can ride along in the context) plus its results as they arrive — which is why result handling (truncation, offloading) is harness work, and why an agent with eighty broadly preloaded tools can pay a standing context cost for all of them whether it uses them or not, which is exactly why deferred, on-demand tool loading exists. A skill, mounted on demand, costs nothing until it's relevant and its full procedure only while it is. A sub-agent is the most powerful context instrument of all: it takes the entire subtask out of the parent's window — the delegate burns its own fresh context on the fifteen-step investigation and returns three sentences.
Read this way, the spectrum doubles as a context-engineering toolkit, which is exactly how the harness's context-engineering suite treats it: curated tool surfaces keep the standing description cost down, skills load procedures just-in-time, and sub-agents isolate context-heavy subtasks so the parent's window stays lean across a long run. The same decomposition decision — which rung handles this work — is simultaneously a governance decision and a window-budget decision, and the architectures that feel effortless are the ones where both were made on purpose.
The rungs compose, and a realistic agent uses all three. Take Ingrid's customer-operations agent, refiled properly:
One agent, three rungs — each governed at its own surface (illustrative)
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.










.webp)
.webp)





.webp)
.webp)
.webp)