



.webp)
June 24, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 24, 2026

Blazingly fast way to build, track and deploy your models!
Evaluation platforms solve a real problem for AI teams. Change a prompt, switch a model, or adjust retrieval, and quality may improve or drop. Braintrust reviews are mostly positive because the platform helps teams measure that change before users experience it.
The enterprise question is broader than output evaluation. Evaluation tells teams what their AI produced after inference. It does not decide who can call a model, cap team spending, govern tool use, or keep prompts inside a private environment.
That distinction matters because Braintrust sits downstream of inference. Governance, access control, and request-path policy enforcement happen before inference. Enterprise teams reading Braintrust reviews should understand this boundary before comparing Braintrust with an AI gateway.
There is also a naming issue worth clearing up early. Two unrelated companies use the Braintrust name, so many public reviews describe a recruiting product rather than the AI evaluation platform. This guide separates both, then explains where Braintrust Dev fits.
Braintrust Dev is an AI evaluation and observability platform for engineering teams shipping production LLM applications. It helps teams run evals, inspect traces, compare prompts, and catch regressions before release. Braintrust raised an $80 million Series B in 2026, led by ICONIQ.
Braintrust Dev covers three connected workflows:
The platform is useful for teams that need trace-driven quality workflows. It helps developers connect project management, prompt updates, evals, and release decisions. Buyers should still separate evaluation strength from request-path governance requirements.
Braintrust reviews are positive around one central theme. The platform makes AI development measurable by connecting traces, evals, experiments, and prompt changes. Users value the trace UI, evaluation workflow, playground, and ability to compare model behavior before release.
Public review volume for Braintrust Dev remains thinner than the company’s funding profile suggests. A big reason is the name collision with Braintrust AIR. Searches for Braintrust review or Braintrust AI gateway reviews can mix recruiting feedback with AI evaluation research.
That means enterprise buyers should treat review data carefully. A few positive reviews can confirm that Braintrust works well for evals. They cannot fully answer questions about incident support, multi-team governance, private deployment, and access control at scale.
The practical read is balanced. Braintrust Dev has strong product value for evaluation and observability. It should not be judged as a gateway, security layer, or production inference governance platform because that is outside its core function.
Set the gaps aside for a moment because Braintrust earns its reputation in the evaluation layer. Its best capabilities help teams connect product changes with measurable output quality. These strengths appear across documentation, product positioning, and public user feedback.
Braintrust lets teams turn production traces into evaluation test cases. This means regression suites can grow from real failures instead of artificial examples. When a prompt or model changes, teams can test against inputs that previously exposed issues.
That workflow improves release confidence because testing uses production-like context. Traces remain consistent across offline eval runs and live logging. Developers can debug regressions in the same UI where they tested the fix.
Adoption often stalls when instrumentation requires heavy application changes. Braintrust reduces that barrier through integrations across OpenTelemetry, Vercel AI SDK, OpenAI Agents SDK, LangChain, LangGraph, Google ADK, Mastra, Pydantic AI, and related frameworks.
Most integrations require a wrapper call or exporter configuration. Teams already using OpenTelemetry can add Braintrust as another span exporter. That lowers setup effort and helps developers create repeatable evaluation workflows faster.
Braintrust includes a built-in agent called Loop. It can run evaluations, generate test cases, and automatically iterate on prompts. For teams that find eval setup tedious, this is a useful differentiator from plain logging tools.
There is still an important caveat. Autonomous iteration works best when the scoring rubric is clear. A vague objective will produce vague suggestions, so teams still need disciplined criteria before relying on automation.
Braintrust attributes token cost at the request, user, and feature level. Teams can see which workflow step or user segment drives spend without building a custom attribution pipeline. That visibility is valuable for AI product teams.
The limit is equally important. Braintrust reports costs after activity happens. It does not enforce hard ceilings before inference, which is why teams often pair it with a gateway to control production budgets.

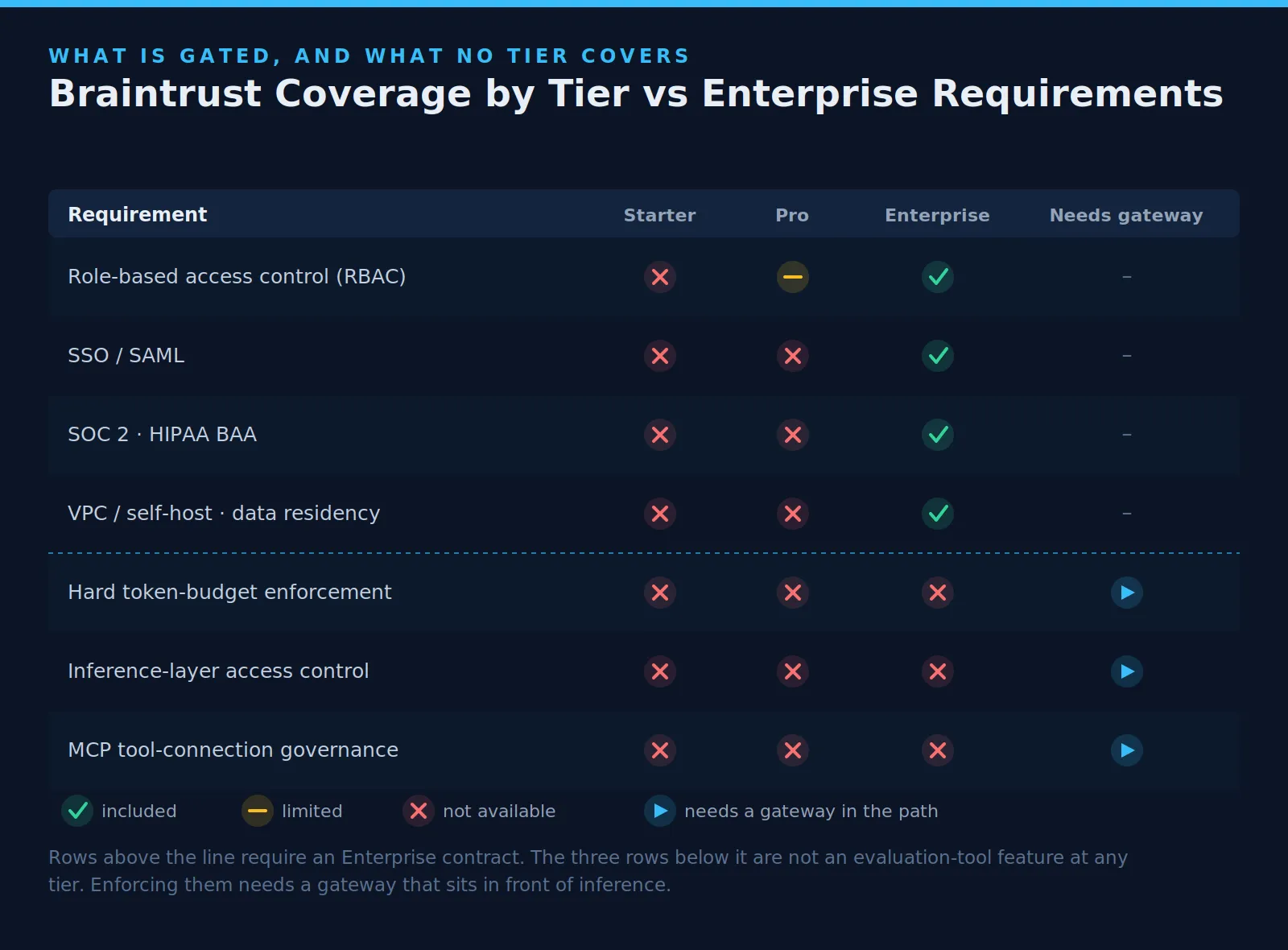
Reading Braintrust reviews fairly means reading pricing and tier limits alongside them. Several controls enterprise teams treat as non-negotiable sit behind Enterprise. This shapes the evaluation, as a positive product review may not align with the tier your organization needs.
Braintrust renamed its free plan to Starter in March 2026 and uses processed data for billing. Processed data includes inputs, outputs, prompts, metadata, and traces ingested into the platform. One gigabyte of processed data roughly maps to about one million spans at typical payload sizes.
Usage beyond included limits is billed through overages. This means a heavy month creates a higher invoice rather than a hard stop. The pricing strength is unlimited users, projects, datasets, playgrounds, and experiments across tiers, which helps larger teams avoid seat-based cost growth.
The main constraint sits in the Enterprise plan. Custom RBAC, SAML SSO, HIPAA BAA, S3 export, custom retention, and on-prem or hosted deployment require the Enterprise plan. Teams with strict compliance, identity, retention, or deployment needs should factor that into evaluation.
None of these gaps weaken Braintrust inside its lane. They are architectural limits. Braintrust receives and analyzes data after inference, which is correct for evaluation and observability. It is the wrong place to enforce policy before a request reaches the model.
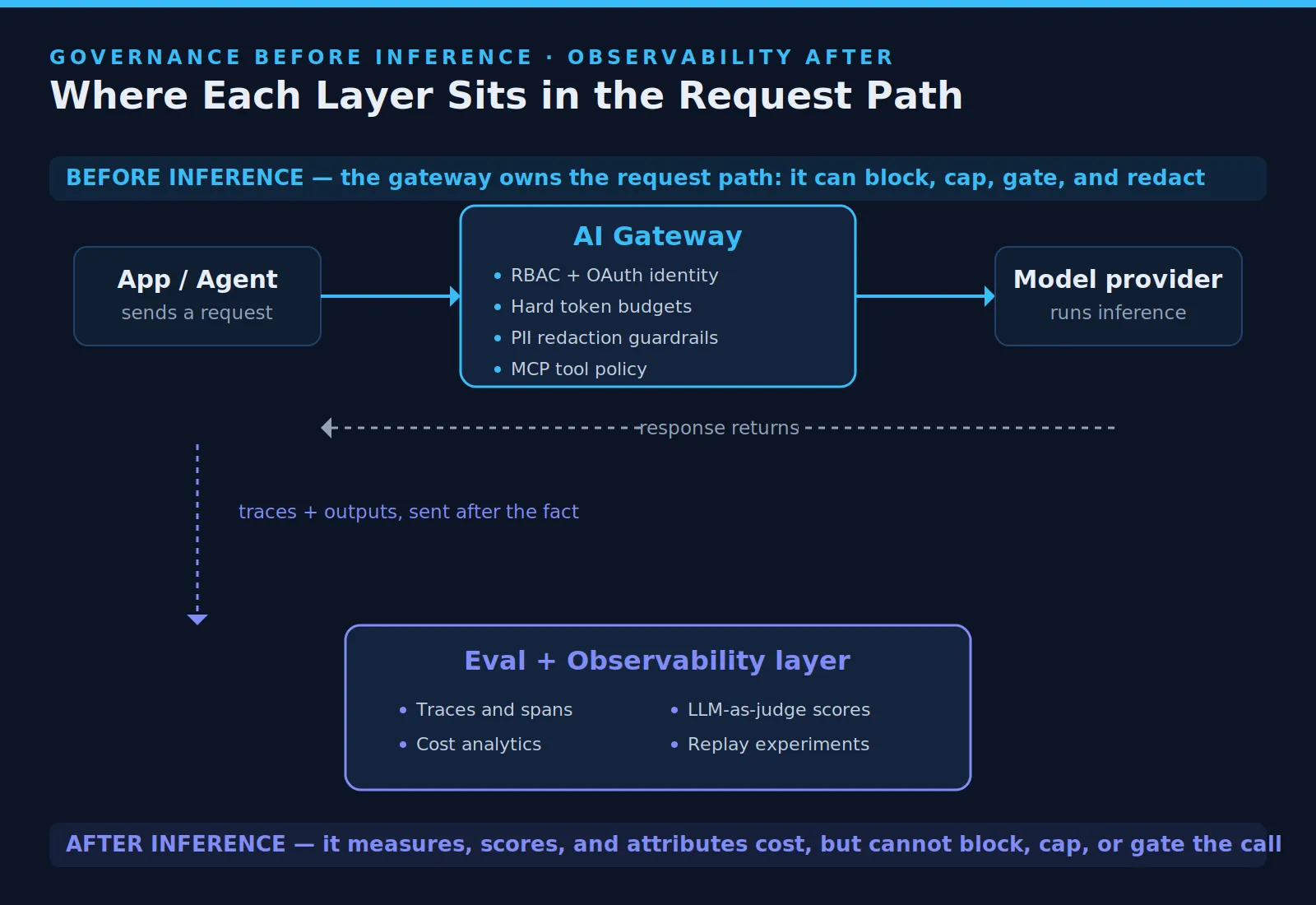
Braintrust observes what model calls produce by receiving trace data from applications. It also offers an optional proxy that can front several providers behind a single OpenAI-compatible endpoint. That can help teams centralize access and cache responses.
The proxy still does not replace identity-aware inference governance. It does not decide which internal user, service, or agent should reach which model. Teams needing request-path access decisions require a separate AI gateway that owns that checkpoint.
Cost analytics and budget enforcement are different jobs. Braintrust does the first by tracking cost per trace and surfacing spend by user or feature. It can also alert teams when usage approaches limits.
An alert does not stop spending. A runaway agent loop or misconfigured batch job can continue while the dashboard updates afterward. Enforcing ceilings requires rejecting or throttling requests before they reach the provider.
On Starter and Pro, trace data runs through Braintrust’s managed cloud. There is no self-hosted option below Enterprise. For organizations with data residency requirements under GDPR, HIPAA, or sector rules, this creates a tier-level limitation.
The fix inside Braintrust is Enterprise, with self-hosting and commercial negotiation. That may work for some buyers. Smaller teams with strict data controls may find the jump difficult.
Agents increasingly connect to external systems through the Model Context Protocol. That connection creates a security boundary because tools can access data, update systems, and trigger actions. Braintrust can trace what happened after the fact.
It does not sit in front of the tool call to approve, block, filter, or apply user identity. As agentic workloads enter regulated environments, the ungoverned MCP surface becomes a significant security gap.
Inside the evaluation and observability category, Braintrust competes most directly with Langfuse, Arize Phoenix, and Helicone. Each platform serves a different buyer profile. The right choice depends on whether the team values open-source control, ML monitoring breadth, low-cost tracing, or deeper eval workflows.
Braintrust's pitch above this group rests on the depth of its eval workflow, the Loop agent, and Brainstore, its purpose-built database. The company reports that Brainstore queries AI traces 80 times faster than a standard data warehouse on its own benchmarks, with median query times under a second across terabytes of data. Take that as a vendor benchmark, which it is, but the architectural point is sound: AI traces have grown to several megabytes each, and general-purpose observability stores strain under that payload.
None of this changes the layer Braintrust operates in. Faster trace queries make a better observability tool. They do not add inference-time governance.
TrueFoundry and Braintrust Dev solve different problems in the AI stack. Braintrust helps teams evaluate outputs after inference and identify quality regressions. TrueFoundry governs what happens before inference, including access, budgets, routing, tool calls, and audit logging.
Teams that need both layers can run them together. TrueFoundry controls the request path through its AI Gateway, while Braintrust evaluates outputs downstream. This provides teams with governance before execution and evaluation after the response is received.
For teams that want fewer systems, TrueFoundry can also directly support observability. It records model calls, agent actions, usage, cost metadata, and policy outcomes. These logs can remain inside the customer’s VPC and connect with existing monitoring tools.
TrueFoundry is especially relevant when teams need:
Braintrust Dev remains useful when the primary needs are output evaluation, score tracking, and regression analysis. TrueFoundry becomes the stronger layer when teams need inference governance, tight budgets, tool control, private deployment, and compliance-ready audit trails.
Book a demo to see TrueFoundry govern inference, budgets, access, and audit logs securely.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.




.webp)





.webp)
.webp)
.webp)
.webp)
.webp)

.webp)