Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Benchmarking de LLM para Produção Empresarial: Como Avaliar Modelos para o Seu Caso de Uso Real
Os benchmarks públicos de LLMs medem o que interessa aos pesquisadores de IA: raciocínio em nível de pós-graduação, geração de código em problemas canônicos, qualidade de tradução multilíngue. Útil para enquadrar capacidades em abstrato. Frequentemente enganosos quando usados para tomar decisões de aquisição empresarial, porque o benchmark mede uma distribuição de tarefas que provavelmente não tem quase nada em comum com a sua carga de trabalho específica. Um modelo que ocupa o primeiro lugar no MMLU pode produzir resultados piores do que um modelo mais barato na sua carga de trabalho de sumarização de documentos, simplesmente porque os seus documentos têm características diferentes do conjunto de testes do benchmark.
A lacuna entre o desempenho de benchmarks públicos e o desempenho em produção não é um problema menor de calibração. É estrutural. Benchmarks usam dados padronizados e limpos. Dados de produção são desorganizados. Específicos do domínio. Seguindo distribuições que os designers de benchmarks não previram. Benchmarks medem a precisão em tarefas canônicas. Sistemas de produção precisam satisfazer requisitos organizacionais de formato de saída, tom e consistência que nenhum benchmark público captura. E benchmarks são instantâneos estáticos, enquanto o desempenho em produção muda à medida que os provedores de modelos atualizam seus modelos e a sua distribuição de dados evolui.
Este guia aborda como construir uma estrutura de avaliação de LLMs para empresas que gera sinais significativos para decisões de seleção e otimização de modelos. Ele cobre as quatro dimensões de benchmark que preveem o desempenho em produção, como construir um conjunto de dados de teste que reflita sua carga de trabalho real, como executar testes A/B em produção sem interromper os usuários e como automatizar a troca de modelos para que o gateway direcione para o melhor modelo por solicitação sem intervenção de engenharia. O AI Gateway da TrueFoundry torna os testes A/B de divisão de tráfego em produção simples de configurar e monitorar.
Stop guessing which model performs best for your use case. Benchmark it in production.
TrueFoundry's AI Gateway handles production traffic splitting, outcome logging, and automatic rollback for live model A/B tests. Book a demo to see how to run your first benchmark in under 30 minutes.
Por Que os Benchmarks Públicos São Pouco Confiáveis para Decisões de Produção Empresarial
As pontuações de benchmarks públicos são os dados mais frequentemente citados e mais frequentemente mal utilizados na aquisição de LLMs para empresas. Eles aparecem em apresentações de fornecedores, memorandos de conselho e planilhas de aquisição. Tratados como verdade absoluta. Compreender por que eles geralmente falham em prever o desempenho em produção é o pré-requisito para investir tempo de engenharia na seleção de modelos orientada por benchmarks.
A contaminação do benchmark inflaciona as pontuações. Grandes modelos de linguagem treinam em enormes quantidades de texto da internet, que inclui cada vez mais perguntas e respostas de benchmarks. Modelos que viram conteúdo de benchmark durante o treinamento pontuam mais alto do que sua capacidade genuína em dados novos preveria. A extensão da contaminação raramente é divulgada e é difícil de medir externamente. Tratar as pontuações publicadas como verdade absoluta superestima a lacuna entre os modelos mais bem classificados e diz muito pouco sobre como eles lidarão com suas entradas.
Tarefas acadêmicas não correspondem às cargas de trabalho empresariais. O MMLU mede o desempenho em questões de conhecimento em nível de pós-graduação em 57 disciplinas. O HumanEval mede a geração de código em problemas de programação canônicos. Nenhum deles mede para o que as equipes empresariais realmente implantam modelos: extração de dados estruturados de PDFs com formatação inconsistente, gerar saída JSON consistente a partir de instruções em linguagem natural, resumir conteúdo técnico específico do domínio sem alucinar terminologia, manter o contexto da conversa ao longo de uma interação de atendimento ao cliente de 20 turnos.
A eficiência de custo é invisível em benchmarks focados em precisão. Um modelo que pontua 95% em um benchmark, mas que usa em média 4.000 tokens para completar sua tarefa típica, pode ter um custo por resultado pior do que um modelo que pontua 88% e usa em média 1.800 tokens por tarefa. O custo por resultado, ou seja, o que realmente custa para produzir uma saída aceitável para o seu caso de uso, quase nunca é relatado em benchmarks públicos. É também frequentemente a métrica mais importante para o planejamento orçamentário empresarial.
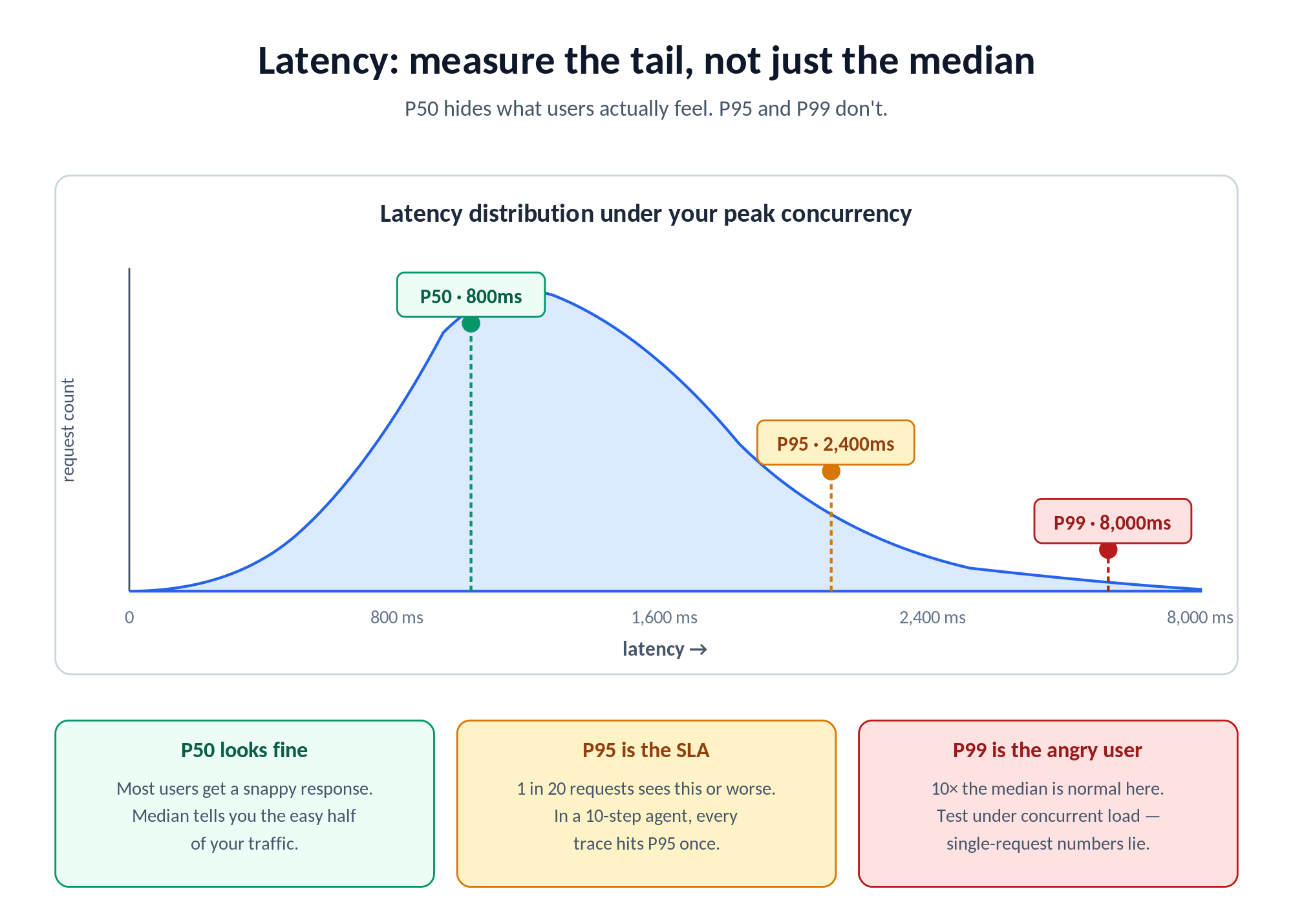
Os valores de latência do benchmark não se aplicam ao seu ambiente. Os valores de latência publicados para APIs de modelos são medidos sob condições específicas: tamanho da solicitação, nível de concorrência e infraestrutura que podem diferir significativamente dos seus. Um modelo que apresenta uma latência mediana de 800ms em condições de benchmark pode entregar uma latência P95 de 2.400ms sob seu volume de concorrência em produção. Isso representa uma experiência de usuário significativamente diferente.
Modelos alteram-se mesmo com números de versão estáveis. Os provedores atualizam o comportamento do modelo sem sempre emitir novos números de versão ou comunicar as mudanças de forma proeminente. Um modelo que teve um bom desempenho em seu benchmark interno há três meses pode se comportar de forma diferente hoje se o provedor atualizou seu ajuste fino (fine-tuning), o tratamento de prompts do sistema ou a filtragem de saída. A avaliação comparativa em produção deve ser contínua, não um exercício único no momento da seleção do modelo.
As Quatro Dimensões da Avaliação Comparativa de LLMs para Empresas
Um benchmark de LLM empresarial útil abrange quatro dimensões distintas. Elas não são independentes. Um modelo que se destaca em qualidade, mas falha no custo por resultado, ainda pode ser a escolha errada se o diferencial de custo não for justificado pela melhoria da qualidade. Todas as quatro devem ser medidas. E ponderadas explicitamente.
Dimensão 1: Qualidade da Saída para Sua Tarefa Específica
Defina critérios de qualidade específicos para a tarefa antes de executar qualquer avaliação. Os critérios de qualidade devem ser mensuráveis, seja por avaliadores humanos usando uma rubrica definida, por um modelo de juiz automatizado com critérios especificados, ou por métricas objetivas onde existam (código: taxa de aprovação de testes; extração estruturada: precisão de campo; classificação: precisão e recall contra um conjunto rotulado). Critérios vagos como "boa saída" produzem avaliações que não são reproduzíveis e não podem justificar uma decisão de fornecedor.
Construa uma rubrica de pontuação que possa ser aplicada consistentemente em todos os modelos em avaliação. Para a sumarização de documentos, uma rubrica pode cobrir a precisão factual (o resumo contém afirmações não suportadas pela fonte?), a cobertura (inclui todos os pontos-chave?), o comprimento apropriado (dentro do intervalo de contagem de palavras alvo?) e a conformidade com o formato (segue a estrutura de saída exigida?). Cada critério deve ser pontuado independentemente para que os modelos possam ser comparados por dimensão, e não apenas no geral.
Realize a avaliação de qualidade às cegas. Avaliadores ou modelos de juiz não devem saber qual modelo produziu qual saída. O viés de identidade do modelo é real: avaliadores que sabem que estão lendo uma saída do GPT-4 a pontuam mais alto, em média, do que um texto idêntico sem essa etiqueta. A avaliação às cegas fornece pontuações que refletem a qualidade real, em vez de efeitos de reputação.
Dimensão 2: Custo Por Resultado
O custo por 1.000 tokens é uma métrica isolada enganosa. A unidade relevante é o custo por tarefa concluída. O custo total (tokens de entrada + tokens de saída, de acordo com o preço do modelo) para produzir uma saída aceitável para o seu caso de uso típico. Um modelo premium precificado, digamos, a US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída pode ser mais ou menos eficiente em termos de custo do que um modelo nominalmente mais barato que precisa de respostas mais longas para atingir qualidade equivalente. O cálculo depende inteiramente da distribuição do comprimento da sua tarefa. Sempre obtenha as taxas atuais por token na página de preços de cada provedor no dia em que você fizer a comparação; os números mudam trimestralmente.
Calcule o custo por tarefa concluída medindo o comprimento médio do prompt (tokens de entrada) e o comprimento médio da resposta (tokens de saída) para o seu conjunto de dados de teste em cada modelo, e então multiplicando pelos preços por token. Quando as pontuações de qualidade são próximas, o custo por tarefa é o desempate. Quando as diferenças de qualidade são reais, a relação custo-qualidade (custo extra por ponto percentual de melhoria de qualidade) determina se o modelo premium vale o preço.
Inclua os efeitos de cache no custo por resultado. O cache semântico retorna respostas geradas anteriormente para solicitações semanticamente semelhantes, pontuadas por similaridade de cosseno sobre um embedding da última mensagem do usuário. Acertos de cache resultam em custo zero do modelo, então o gasto efetivo por solicitação depende da sua taxa de acertos. Se 35% das suas solicitações acertarem o cache, o custo por resultado é materialmente diferente do cálculo por token, e ignorar isso pode inverter uma comparação de modelos.
Dimensão 3: Latência Sob o Seu Padrão de Tráfego Real
Meça a latência em P50, P95 e P99, não apenas a mediana. Aplicações empresariais precisam saber o pior cenário que os usuários verão, não apenas a experiência típica. Um modelo com P50 excelente, mas P99 de 8 segundos, torna o uso interativo inaceitável, mesmo que a mediana pareça boa. O painel de métricas da TrueFoundry expõe seletores P50, P75, P90 e P99 para Latência de Solicitação, Tempo Até o Primeiro Token (TTFT), Latência Inter-Token (ITL) e Tempo Por Token de Saída (TPOT). Todas as quatro métricas são apresentadas porque cada uma oferece uma informação diferente.
Realize testes de carga sob o volume esperado de solicitações concorrentes, não em condições de solicitação única. A maioria dos modelos parece ótima isoladamente e degrada significativamente sob as cargas concorrentes que as aplicações de produção geram. A TrueFoundry oferece uma Ferramenta de Benchmarking de LLM no Catálogo de Aplicações que permite configurar a concorrência de pico, a taxa de aumento, a distribuição do tamanho do prompt e o número máximo de tokens de saída. Ele plota solicitações por segundo, tempo de resposta, TTFT e latência inter-token. Execute-o contra qualquer endpoint compatível com OpenAI, incluindo modelos implantados no TF, provedores externos via chave de API ou qualquer modelo por trás do seu AI Gateway. Teste com aproximadamente 2× a sua concorrência de pico esperada para garantir uma margem de capacidade significativa.
Acompanhe o TTFT separadamente do tempo total de geração para casos de uso de streaming. Aplicações que transmitem a saída do modelo para os usuários experimentam o TTFT como "latência percebida", o tempo antes que algo apareça na tela. Um modelo com maior tempo total de geração, mas menor TTFT, pode oferecer uma experiência melhor do que um modelo tecnicamente mais rápido com um primeiro token lento. O TPOT (tempo total dividido pelos tokens de saída) é o único número que captura a velocidade total de geração e é o que o roteamento baseado em latência da TrueFoundry usa para escolher o alvo mais rápido.
Dimensão 4: Consistência e Confiabilidade
Execute cada prompt do seu conjunto de dados de teste de três a cinco vezes em várias sessões para medir a variância da saída. Alguns modelos produzem saídas dramaticamente diferentes para a mesma entrada em execuções distintas: diferentes afirmações factuais, diferentes estruturas de saída, diferente cobertura dos pontos exigidos. Alta variância cria problemas a jusante para análise (parsing), extração de dados estruturados e consistência da experiência do usuário.
Teste explicitamente o comportamento em modos de falha. O que o modelo retorna quando a entrada excede sua janela de contexto? O que acontece quando a política de conteúdo é acionada por uma entrada limítrofe? Ele segue as instruções de formato explícitas de forma confiável, ou às vezes retorna respostas de formato livre quando uma saída estruturada era necessária? Esses modos de falha estão em grande parte ausentes dos benchmarks públicos, mas é neles que os sistemas de produção falham.
Construindo um Conjunto de Dados de Benchmark Representativo para Sua Empresa
O conjunto de dados de benchmark é o componente mais importante de uma avaliação de LLM empresarial. Um conjunto de dados bem projetado produz previsões confiáveis de desempenho em produção. Um mal projetado produz resultados enganosos que levam a seleções erradas. O design do conjunto de dados merece tanto investimento em engenharia quanto a própria metodologia de avaliação.
Amostras representativas formam o cerne do conjunto de dados. Colete de 100 a 500 exemplos reais da sua carga de trabalho de produção, revisados manualmente por especialistas no assunto para confirmar que representam a distribuição real das entradas que seu sistema processa. Cubra toda a distribuição: casos comuns, casos de borda, a minoria de entradas que são tecnicamente difíceis ou onde os requisitos de qualidade são mais rigorosos. As amostras devem ser extraídas de dados de produção recentes para refletir as distribuições atuais, não dados históricos que podem não ser mais representativos. Se você ativou o rastreamento em seu AI Gateway, o API de Query Spans (via o SDK TrueFoundry) é provavelmente a maneira mais limpa de extrair uma amostra estratificada, filtrando por usuário, equipe, conta virtual ou qualquer chave de metadados personalizada que você tenha anexado.
Casos de borda investigam modos de falha conhecidos do modelo. Projete entradas de teste específicas para revelá-los. Para processamento de documentos: documentos muito longos próximos aos limites da janela de contexto, documentos com formatação inconsistente, documentos com tabelas ou dados estruturados misturados com prosa. Para geração de código: solicitações com especificações ambíguas, solicitações em frameworks incomuns, solicitações que exigem raciocínio sobre implicações de segurança. Para aplicações voltadas para o cliente: entradas com erros gramaticais, entradas em linguagem não padronizada, casos limítrofes de política de conteúdo. O conjunto de casos de borda é onde reside a lacuna entre “95% no benchmark” e “quebrado em produção”.
Casos de regressão previnem regressões de capacidade. Mantenha um conjunto de 20 a 50 exemplos extraídos de incidentes passados: casos em que seu modelo atual produziu saída incorreta, casos em que uma atualização de modelo anterior causou regressões de qualidade, casos em que padrões de entrada específicos causaram problemas consistentemente. Qualquer novo modelo em avaliação deve passar pelo conjunto de regressão antes de ser considerado para produção. Isso torna as atualizações mais seguras porque você não pode reintroduzir silenciosamente problemas previamente resolvidos.
A verdade fundamental rotulada permite a pontuação automatizada. Para casos de uso onde a pontuação automatizada é viável (extração estruturada, classificação, geração de código), inclua rótulos de verdade fundamental criados por especialistas humanos para cada caso de teste. A pontuação automatizada contra a verdade fundamental escala melhor do que a avaliação humana para grandes conjuntos de teste. Os rótulos devem ser revisados por pelo menos dois avaliadores independentes para resolver desacordos antes de serem definidos como o padrão de avaliação.
Executando Testes A/B em Produção: O Benchmark Mais Confiável
O benchmarking offline em um conjunto de dados de teste é um primeiro passo necessário. O sinal mais confiável geralmente vem do tráfego de produção. Usuários reais geram uma distribuição de entradas que é, segundo relatos, mais variada e mais desafiadora do que qualquer conjunto de teste curado manualmente. O teste A/B em produção, que direciona uma porcentagem do tráfego ao vivo para um novo modelo enquanto compara os resultados com o modelo atual, é o que torna uma decisão de modelo defensável.
Comece com 1-5% do tráfego de produção. Direcione uma pequena porcentagem de solicitações ao vivo para o modelo candidato enquanto o restante permanece no modelo atual. Monitore a qualidade da saída, latência, custo e taxa de erro por um mínimo de duas semanas, tempo suficiente para capturar a distribuição completa de suas entradas de produção, incluindo padrões semanais e casos de borda que aparecem apenas ocasionalmente. No TrueFoundry, isso é um único campo em uma Modelo Virtual configuração: peso: 5 no candidato, peso: 95 no titular.
Defina os critérios de sucesso antes do início do teste. Articule as condições específicas sob as quais o novo modelo será aceito para implantação em produção completa. Exemplo: o novo modelo deve atingir pelo menos 97% da pontuação de qualidade do modelo atual, com um custo por tarefa não superior a 110% do modelo atual, e com uma latência P95 não pior do que a do modelo atual. Critérios predefinidos evitam a racionalização post-hoc, onde as equipes aceitam um modelo com desempenho inferior porque outras métricas parecem boas.
Use a camada de roteamento do AI Gateway para divisão de tráfego. Configure o gateway para dividir o tráfego entre modelos por porcentagem sem modificar nenhum código da aplicação. A aplicação envia uma solicitação padrão para um nome de modelo virtual (algo como support-bot/summarize), e o gateway decide qual modelo real usar com base na divisão configurada. Isso elimina a sobrecarga de engenharia de implantar branches de código específicos do modelo para avaliação. A configuração de balanceamento de carga do TrueFoundry é um YAML declarativo, editável na UI ou enviado via tfy CLI para fluxos de trabalho GitOps.
Defina gatilhos de reversão automática. Configure condições que automaticamente removem o candidato da rotação: limite de taxa de erro, teto de latência, piso de pontuação de qualidade. A configuração de tolerância a falhas do TrueFoundry (allowed_failures_per_minute, cooldown_period_minutes, failure_status_codes) é definida por modelo, e um alvo que excede o limite é marcado como não saudável e excluído do roteamento durante o período de resfriamento. O blog sobre balanceamento de carga mostra uma configuração típica com três falhas por minuto acionando um período de resfriamento de cinco minutos para [429, 500, 502, 503, 504]. Para latência, o roteamento baseado em prioridade suporta um corte de SLA no TPOT: configure time_per_output_token_ms por alvo, e o gateway monitora uma janela deslizante de 3 minutos com até 10 amostras (mínimo de 3) para decidir se o candidato está atendendo ao seu limite de latência. Os testes A/B de produção falham de forma segura. O pior cenário é uma pequena porcentagem de tráfego sendo atendida por um modelo ruim antes que a recuperação automática seja acionada.
Registre métricas de resultado que vão além dos sinais técnicos. Além da latência e da taxa de erro, registre sinais de resultados de negócios onde mensuráveis: o usuário aceitou ou rejeitou a saída do modelo? A tarefa do agente foi concluída com sucesso? A interação de atendimento ao cliente foi resolvida na sessão? Essas métricas downstream são mais significativas para a seleção de modelos do que apenas a qualidade técnica, e exigem instrumentação em nível de aplicação para serem coletadas. O metadados personalizados (enviados via cabeçalho X-TFY-METADATA) permite que você marque cada solicitação com recurso, ambiente, ID do cliente ou qualquer dimensão que seu negócio considere importante, e detalhe o painel de métricas ao longo dessa dimensão posteriormente.
Automatizando a Seleção de Modelos: Além dos Testes A/B Manuais
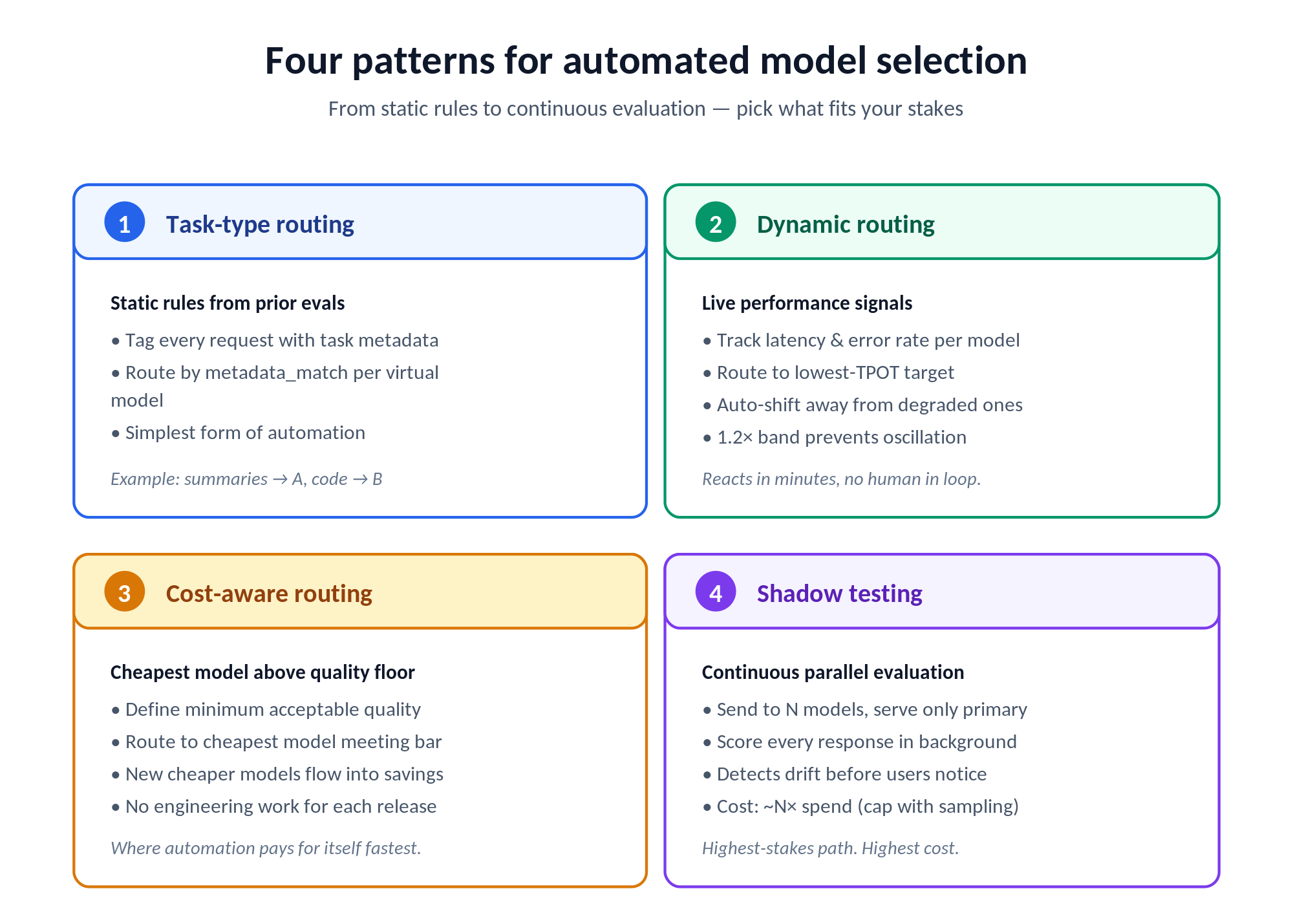
O objetivo final de um programa maduro de avaliação de LLM empresarial é remover completamente a seleção de modelos do caminho crítico das decisões de engenharia. Em vez de executar testes A/B manuais toda vez que um novo modelo é lançado, o gateway aplica critérios de seleção configurados automaticamente. Cada solicitação vai para o modelo que provavelmente produz o melhor resultado, dados os dados de desempenho atuais.
Roteamento por tipo de tarefa com base nos resultados da avaliação. Uma vez que as avaliações tenham estabelecido que o Modelo A é melhor para sumarização de documentos e o Modelo B é melhor para geração de código, configure o gateway para rotear por tag de tipo de tarefa anexada a cada solicitação. Este é um roteamento estático baseado em avaliação prévia, a forma mais simples de seleção automatizada de modelos. Nos modelos virtuais do TrueFoundry, isso é um bloco metadata_match em cada alvo: envie solicitações {task: "summarize"} para um provedor, {task: "code_gen"} para outro, com metadados preenchidos pela sua aplicação via cabeçalho X-TFY-METADATA.
Roteamento dinâmico baseado em sinais de desempenho em tempo real. Um roteamento mais sofisticado usa os dados de latência e taxa de erro em tempo real do gateway para desviar o tráfego de modelos que estão atualmente degradados. Quando a API de um provedor está experimentando latência elevada, o gateway redireciona o tráfego para o próximo melhor modelo para aquele tipo de tarefa sem esperar que um humano perceba. O TrueFoundry Roteamento baseado em latência encaminha para o TPOT mais baixo nos últimos 20 minutos (ou nas últimas 100 requisições, o que for menor), com uma banda de 1,2x para que os modelos dentro dessa faixa sejam tratados como igualmente rápidos e o tráfego não oscile devido a pequenas diferenças.
Roteamento otimizado para custo com pisos de qualidade. Configure regras que enviem requisições para o modelo mais barato que atenda a um limite de qualidade definido. Para tarefas em que qualquer modelo acima de um piso é aceitável, o gateway gera economia de custos à medida que modelos mais baratos atingem o nível exigido sem trabalho de engenharia. É aqui que o roteamento automatizado se paga mais rapidamente: cada modelo mais novo e mais barato que atinge seu piso de qualidade se traduz diretamente em economia.
Avaliação contínua com testes de sombra. O teste de sombra encaminha cada requisição de produção para múltiplos modelos simultaneamente, serve a resposta do modelo primário e avalia as saídas de todos os candidatos. Isso cria um fluxo de avaliação contínua que detecta mudanças no desempenho do modelo em tempo real, antes que causem degradações visíveis para o usuário. O custo adicional é aproximadamente N vezes o gasto com o modelo se você usar N modelos em modo sombra, o que é significativo, mas muitas vezes menor do que o custo de implantar um modelo regressivo em produção. Você pode gerenciar esse custo adicional usando o modo sombra apenas para uma fração do tráfego, ou apenas para modelos menores e mais baratos que estão sendo avaliados como candidatos à redução de custos.
Como a TrueFoundry Resolve o Benchmarking de LLMs Empresariais e a Seleção de Modelos
O AI Gateway da TrueFoundry foi desenvolvido para tornar a avaliação de modelos em produção uma capacidade contínua para equipes de plataforma empresariais, e não um projeto pontual. Os componentes abaixo estão documentados na documentação ao vivo do AI Gateway e foram verificados em relação ao produto implantado.
Divisão de tráfego sem alterações no código.Modelos Virtuais lidam com a divisão do tráfego de produção entre qualquer número de alvos reais por porcentagem. As equipes de engenharia configuram a divisão no editor YAML da interface do usuário ou via tfy apply -f loadbalancer-config.yaml para GitOps. O código da aplicação permanece inalterado: ele chama um nome de modelo virtual como support-bot/summarize, e o gateway decide qual provedor real lida com cada requisição. As divisões podem ser ajustadas em tempo real, de 1% para 10% para 50%, à medida que a confiança no candidato aumenta.
Gatilhos de rollback automático integrados. Dois mecanismos complementares governam quando um alvo é retirado de rotação. A configuração de tolerância a falhas (configurável por modelo via allowed_failures_per_minute, cooldown_period_minutes e uma lista de failure_status_codes) marca um alvo como não saudável assim que a taxa de erro excede o limite, e então o restaura automaticamente após o período de resfriamento. O corte de SLA (apenas para roteamento baseado em prioridade) permite definir um limite de TPOT por alvo; o gateway monitora uma janela deslizante de 3 minutos e rebaixa um alvo que o excede. Testes A/B em produção falham de forma segura sem exigir monitoramento humano fora do horário comercial.
Rastreamento de custo por resultado em todos os modelos.Rastreamento de custos suporta tanto Custo Público (preenchido automaticamente a partir das taxas do provedor) quanto Custo Privado (contratos personalizados, modelos ajustados). O painel de Métricas detalha os custos por usuário, modelo, equipe ou conta virtual, com uma opção “Visualizar por metadados” que permite segmentar os gastos por qualquer tag personalizada anexada pela sua aplicação. A exportação CSV e uma API HTTP para métricas brutas e agregadas facilitam o envio dos dados para sua pilha de finanças ou business intelligence.
Cache semântico que sobrevive a mudanças de roteamento.Cache semântico retorna respostas geradas anteriormente para requisições semanticamente semelhantes, utilizando similaridade de cosseno no embedding da última mensagem do usuário com um limiar configurável (ponto de partida recomendado é 0.9). Outros parâmetros da requisição (modelo, mensagens anteriores, temperatura) são hashados separadamente e precisam corresponder exatamente, portanto, os acertos de cache têm um escopo restrito. As entradas de cache são isoladas por usuário/conta virtual por padrão, com namespaces personalizados opcionais para aplicações multi-tenant. Acertos de cache retornam uma resposta em milissegundos com custo zero de modelo, independentemente de qual alvo a camada de roteamento teria selecionado.
Abrangência de provedores em uma única avaliação. A TrueFoundry oferece roteamento para OpenAI, Anthropic (direto e via AWS Bedrock), Azure OpenAI, AWS Bedrock, AWS SageMaker, GCP Vertex AI, Cohere, Together AI, Mistral, Groq, Cerebras, xAI, Databricks, modelos auto-hospedados e outros (a lista completa está na página de visão geral do AI Gateway). As equipes podem comparar o AWS Bedrock Claude Sonnet 4.5 com equivalentes do Azure OpenAI em um único teste A/B sem trabalho de integração separado para cada provedor. A sobrecarga declarada do gateway é “tipicamente inferior a 5ms” com uma taxa de transferência sustentada de mais de 350 RPS em 1 vCPU, o que mantém o gateway fora do caminho crítico mesmo em escala de produção.
Run your first production model A/B test in under 30 minutes with TrueFoundry.
TrueFoundry's AI Gateway handles traffic splitting, cost-per-outcome tracking, and automatic rollback for live model evaluations. Book a demo to see the setup.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Como projetamos um conjunto de testes de benchmark para um caso de uso onde ainda não temos dados de produção para coletar amostras?
Inicialize com dados sintéticos mais um pequeno conjunto inicial curado por especialistas. Peça a especialistas no assunto para escreverem manualmente 30-50 entradas representativas, depois expanda com variações sintéticas: paráfrases, casos extremos, variações de formato, variações de comprimento. Valide as entradas sintéticas em relação à sua distribuição de produção esperada da melhor forma possível. A primeira onda de tráfego de produção real fornece os dados de que você precisa para refinar o conjunto de dados, então planeje revisar o conjunto de testes após o primeiro mês de dados de produção estar disponível. Trate o conjunto de dados inicial como uma v0, não como uma verdade fundamental permanente, e use os logs de requisição do TrueFoundry para coletar uma amostra estratificada de entradas reais assim que elas existirem.
Qual é a duração mínima para um teste A/B em produção antes que os resultados sejam confiáveis o suficiente para tomar uma decisão de seleção de modelo?
Duas semanas é um período mínimo defensável para a maioria das aplicações empresariais. A justificativa é que duas semanas abrangem tanto os ciclos semanais (padrões de tráfego diferentes de segunda a sexta-feira versus fim de semana) quanto um ciclo completo de implantação da aplicação que faz a chamada. Para garantir confiança estatística na comparação, o ideal é que o modelo candidato atenda a pelo menos alguns milhares de requisições: isso geralmente é suficiente para distinguir uma diferença real de qualidade ou latência do ruído, assumindo que seu tráfego gere uma distribuição significativa de entradas. Decisões de maior impacto (substituir um modelo em uma aplicação voltada para o cliente) geralmente exigem quatro semanas. Para decisões de menor impacto (troca de modelo em uma ferramenta interna), uma semana com volume adequado pode ser suficiente.
Como o TrueFoundry lida com o rollback automático, o que o aciona e com que rapidez o tráfego retorna ao modelo original?
Dois mecanismos cobrem o caminho de rollback em caso de falha. A configuração de tolerância a falhas é definida por modelo com três parâmetros: falhas_permitidas_por_minuto (quantos erros são tolerados), período_de_resfriamento_minutos (por quanto tempo o modelo é excluído após exceder o limite) e códigos_de_status_de_falha (quais códigos HTTP são considerados falhas). Um alvo que excede o limite é marcado como não saudável e excluído do roteamento durante o período de resfriamento, sendo então automaticamente restaurado. O corte de SLA está disponível para roteamento baseado em prioridade: defina time_per_output_token_ms em um alvo, e se a média móvel de 3 minutos exceder o limite (com pelo menos 3 amostras), o alvo é movido para o final da cadeia de fallback. Ambos os mecanismos funcionam sem intervenção humana. O efeito prático é que, durante uma implantação problemática, uma pequena porcentagem do tráfego recebe o modelo defeituoso antes que ele seja automaticamente removido, e os alvos saudáveis continuam a servir.
A TrueFoundry consegue rotear diferentes tipos de solicitação para modelos distintos simultaneamente, de modo que possamos fazer um teste A/B em um caso de uso sem afetar os outros?
Sim. Duas abordagens tornam isso possível. Primeiro, crie um modelo virtual por caso de uso: por exemplo, support-bot/summarize, code-bot/generate, extraction-bot/parse são modelos virtuais independentes com suas próprias regras de roteamento e pesos, de modo que um teste A/B no fluxo de trabalho de sumarização não afete a geração de código. Segundo, use filtros `metadata_match` em destinos individuais dentro de um modelo virtual para restringi-los a tipos de solicitação específicos: um destino com `metadata_match: {task: "code_gen"}` só recebe tráfego onde os metadados da solicitação incluem esse par chave-valor. A mesma abordagem funciona para roteamento sensível à região ou ao ambiente: marque as solicitações com `X-TFY-METADATA: {"region": "eu-west"}` a partir da sua aplicação, e adicione blocos `metadata_match` nos destinos que devem atender apenas a essa região.
Como devemos fazer o benchmark de modelos para cargas de trabalho de IA agentivas, onde a qualidade de uma tarefa de agente multi-etapas é mais difícil de medir do que uma resposta de uma única interação?
A qualidade do agente deve ser medida no nível do resultado final, e não no nível de cada interação. Defina o que significa sucesso para a tarefa de ponta a ponta (o negócio foi fechado, o ticket foi resolvido, o documento foi extraído corretamente) e use isso como o principal indicador. Métricas por interação são importantes para depuração, mas não para a seleção de modelos. Para visibilidade em nível de rastreamento, o rastreamento de requisições da TrueFoundry registra o prompt e a resposta completos para cada etapa da cadeia, com um trace_id que os correlaciona, permitindo que você reproduza uma execução de agente falha e veja onde a cadeia foi interrompida. Para pontuação automatizada, uma abordagem de modelo avaliador é frequentemente a mais prática: defina uma rubrica para “este rastreamento atingiu o objetivo declarado do usuário?” e avalie os rastreamentos com base nela. Execute o mesmo ciclo do agente em vários modelos candidatos e compare as taxas de sucesso de ponta a ponta, em vez da precisão por etapa. Seja mais conservador com as porcentagens de lançamento de testes A/B para cargas de trabalho agentivas (comece com 1% em vez de 5%), pois os modos de falha podem se acumular em várias etapas.
Qual é o custo adicional de executar testes de sombra e vale a pena para a maioria dos casos de uso empresariais?
Os testes de sombra aproximadamente dobram o gasto com o modelo se você espelhar cada requisição contra uma alternativa, então o custo adicional inicial é significativo. Existem três maneiras de torná-lo econômico. Primeiro, espelhe apenas uma fração do tráfego: uma taxa de espelhamento de 10% oferece um fluxo contínuo de avaliação com um décimo do custo adicional de um espelhamento completo. Segundo, espelhe contra candidatos menores e mais baratos, em vez de modelos premium: se você está avaliando se um modelo menor poderia substituir o seu atual modelo premium, o próprio espelhamento é barato. Terceiro, execute os espelhamentos de forma assíncrona, onde a aplicação não precisa esperar, para que o orçamento de latência não seja duplicado. Se vale a pena, depende do custo de uma implantação de modelo ruim no seu contexto. Para aplicações de alto risco, o gasto geralmente se justifica ao evitar até mesmo um incidente de regressão. Para casos de uso de menor risco, testes A/B periódicos no conjunto de candidatos provavelmente fornecem sinal suficiente com um custo operacional muito menor.




.webp)































.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




