




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Com a gama de casos de uso para aprendizado de máquina se expandindo muito nos últimos anos, a necessidade de escalar as operações em torno do treinamento, implantação e monitoramento desses modelos também se tornou bastante importante. Muitas dessas preocupações são semelhantes às que foram "resolvidas" para casos de uso de software em geral. O Kubernetes é um desses softwares de código aberto que consolidou o ecossistema nativo da nuvem ao seu redor, servindo como plataforma subjacente.
Portanto, torna-se imperativo explorar se é útil que o Kubernetes seja aproveitado para um caso de uso de aprendizado de máquina. Vamos começar primeiro com o próprio Kubernetes e o que há de tão interessante nele.

Crédito: Kubernetes
💡 Kubernetes é um motor de orquestração de contêineres de código aberto para automatizar a implantação, escalonamento e gerenciamento de aplicações conteinerizadas.
Em termos mais simples, o Kubernetes oferece uma maneira simples e padronizada de executar e operar cargas de trabalho que precisam ser escaladas dinamicamente em várias máquinas.
Vamos analisar algumas das funcionalidades mais populares -
Estas são apenas algumas das funcionalidades disponíveis por padrão. Um grande número de casos de uso são, na verdade, resolvidos pelas ferramentas construídas usando o Kubernetes como camada subjacente. Abordaremos ferramentas específicas em uma edição posterior.
Com o entendimento do que é o Kubernetes e quais são os principais recursos que ele oferece em um cenário de desenvolvimento de software, vamos aprofundar nos problemas específicos que ele pode resolver no fluxo de trabalho de um cientista de dados.
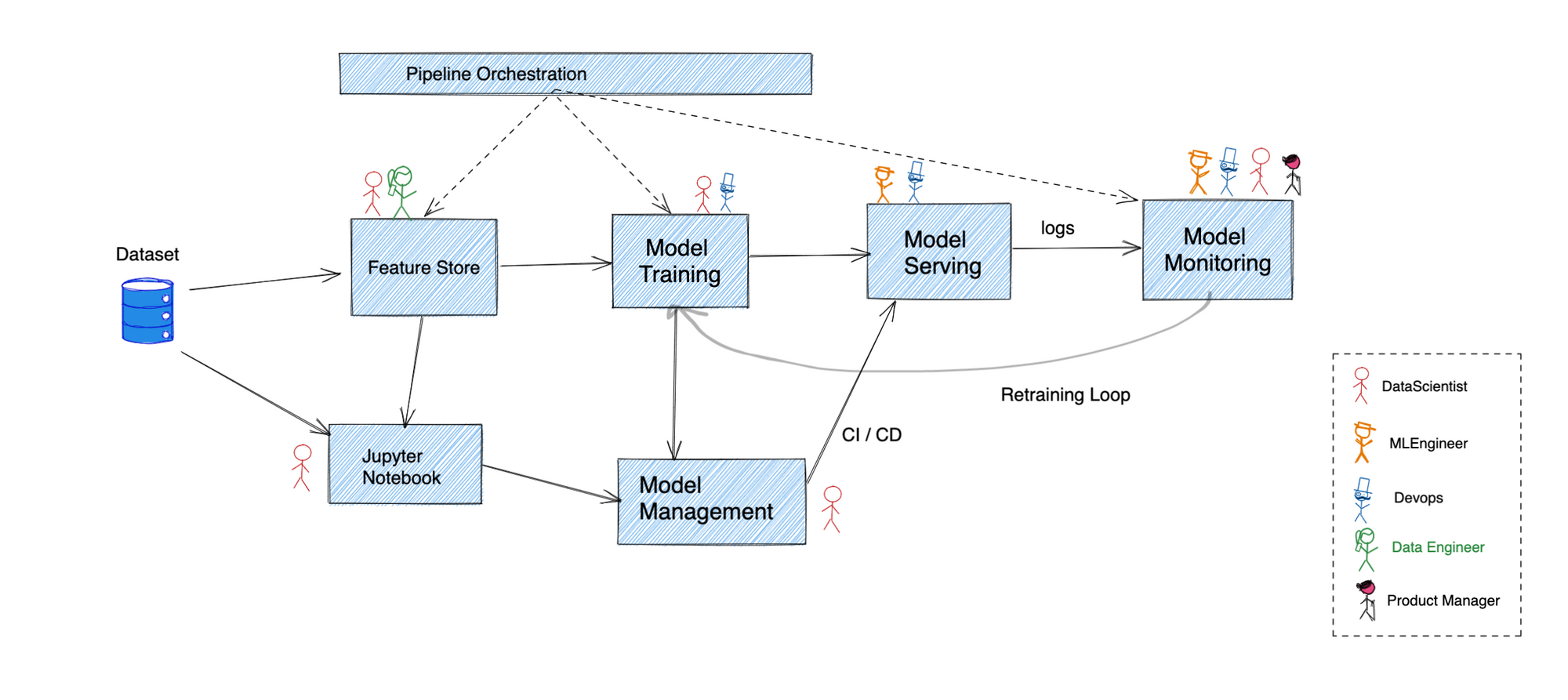
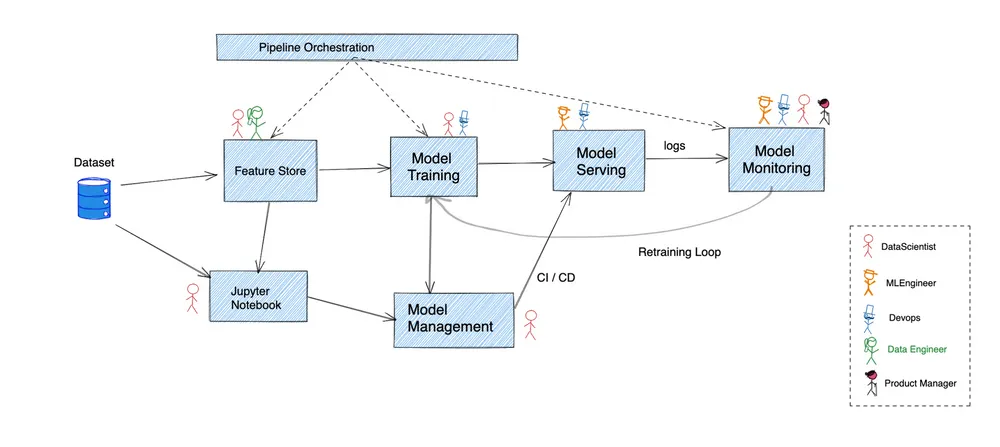
A figura acima oferece um panorama geral de como um pipeline típico de ciência de dados funciona. Muitas empresas optaram por usar uma vasta variedade de soluções personalizadas com recursos sobrepostos para conectar tudo.
Vamos analisar cada uma dessas etapas para tentar entender onde o Kubernetes se encaixa:
Antes que qualquer dado bruto possa ser útil, ele deve primeiro ser transformado em entradas higienizadas para o pipeline de treinamento de modelos. É aqui que os feature stores entram em cena, realizando a transformação, armazenamento e disponibilização dos dados de features.
O Kubernetes suporta a implantação de cargas de trabalho com estado e integra-se muito bem com provedores de nuvem para fornecer persistência de forma contínua.
A maioria do desenvolvimento de modelos começa com um Engenheiro de ML escrevendo código em um notebook Jupyter e, para muitos, isso é quase tudo o que é necessário. Ele fornece uma interface REPL para executar código Python. Isso começa sendo hospedado em laptops pessoais, mas é melhor executar um pool centralizado de notebooks Jupyter hospedados que pode ser usado por vários indivíduos.
O modelo declarativo do Kubernetes, juntamente com o suporte para sistemas de armazenamento persistente, torna trivial hospedar um pool de notebooks e permitir o controle de acesso sobre notebooks individuais para garantir uma colaboração eficaz.
Qualquer algoritmo escrito em um notebook precisa ser alimentado com dados de treinamento para obter um artefato de modelo como saída. Isso pode ser feito no próprio notebook em casos de uso menores, mas requer um pipeline muito mais poderoso para conjuntos de dados maiores. Geralmente, a validação contra o conjunto de dados de teste também é realizada aqui antes que o artefato seja usado para realizar inferências em produção.
Existem várias soluções para orquestrar um pipeline DAG no Kubernetes. O Airflow tem suporte nativo para Kubernetes, enquanto o Kubeflow foi construído completamente sobre o Kubernetes. Todas as principais soluções de monitoramento oferecem integração de primeira classe com o Kubernetes, o que é essencial para executar pipelines de nível de produção.
Esta etapa cuida do armazenamento e versionamento do conjunto de dados e do modelo. Isso garante que qualquer artefato de modelo permaneça reproduzível pelo tempo que for necessário. Um paralelo pode ser traçado com a forma como o gerenciamento de código é realizado usando o Git.
Embora o armazenamento de dados subjacente para esses sistemas de gerenciamento possa ser hospedado no próprio Kubernetes, em muitos casos é melhor usar uma solução gerenciada de um provedor de nuvem. Nesses casos, a maioria dos provedores de nuvem integra perfeitamente seus próprios sistemas IAM com os do Kubernetes, tornando seguro o acesso a dados de fora do cluster sem a necessidade de armazenar as credenciais de acesso.
Finalmente, o artefato do modelo é preparado para que um sistema de produção possa fazer inferências sobre ele. Isso geralmente envolve encapsular um modelo em uma estrutura de API e permitir que outros serviços chamem o modelo para fazer inferências. Preocupações semelhantes às da engenharia de software, como authn/authz, escalabilidade, confiabilidade, etc., entram em cena aqui.
É aqui que o Kubernetes se destaca. A maioria dos recursos que abordamos na seção anterior tornam-se críticos nesta etapa.
Como qualquer sistema de produção, o monitoramento contínuo do modelo atualmente implantado é essencial para garantir que seu sistema esteja se comportando como esperado. As métricas a serem observadas podem incluir desde a precisão real das previsões até a latência e o throughput que o sistema é capaz de suportar.
Muitas soluções de monitoramento se integram de perto com o Kubernetes. Descobrir um alvo para realmente coletar métricas, realizar cálculos sobre elas e armazená-las para uso posterior pode ser feito sem qualquer dependência externa.
Todo o cenário em torno do Kubernetes tem explodido e muitas ferramentas já estão disponíveis. Existem, no entanto, algumas armadilhas que qualquer organização deve ter em mente antes de adotá-lo por completo. Abordaremos essas questões e como elas podem ser mitigadas na próxima edição.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




