



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 29, 2026

Blazingly fast way to build, track and deploy your models!
A adoção empresarial de IA mudou o foco do risco. As decisões críticas já não se limitam à seleção de modelos ou ao ajuste fino. Em sistemas de produção, o risco é introduzido e, ou controlado, ou amplificado na camada do Gateway de IA. É aqui que a inferência é roteada, os modelos são selecionados, os agentes executam fluxos de trabalho, as ferramentas são invocadas e os dados de observabilidade são emitidos.
Como resultado, conceitos de longa data como residência de dados e soberania de dados já não podem ser tratados como preocupações estáticas de infraestrutura. Em sistemas de IA, são propriedades de tempo de execução, impostas (ou violadas) pelo gateway.
Muitas empresas acreditam ter abordado a governança de dados ao implantar modelos numa região de nuvem específica. Essa premissa cai por terra quando os Gateways de IA introduzem:
Compreendendo soberania de dados vs. residência de dados no contexto de Gateways de IA é, portanto, fundamental para operar IA em conformidade e de nível de produção.
Aplicações tradicionais tinham caminhos de dados relativamente previsíveis. As requisições fluíam dos usuários para os serviços e para os bancos de dados, muitas vezes dentro de uma única região. Gateways de IA alteram fundamentalmente este modelo.
Um Gateway de IA pode, para uma única requisição:
Cada uma dessas ações pode introduzir movimentação ou acesso de dados implícito entre regiões, mesmo quando a própria aplicação parece local.
É por isso que os Gateways de IA se tornam o plano de controle de dados de facto.
Se as restrições de residência e soberania não forem aplicadas no gateway:
Em outras palavras, falhas de governança de dados em sistemas de IA são geralmente falhas de gateway, não falhas de modelo.
É também por isso que garantias genéricas como “implementamos modelos na região” são insuficientes. Sem a aplicação de regras ao nível do gateway, as empresas não podem garantir que:
O restante deste blog examina como a residência de dados e a soberania de dados diferem, por que os Gateways de IA devem aplicar ambos, e como plataformas como a TrueFoundry projetam os seus gateways para tornar estas garantias aplicáveis em vez de aspiracionais.
A residência de dados define onde os dados são fisicamente processados e armazenados.
Em sistemas de IA, esta questão é respondida não apenas pelo modelo, mas pelo Gateway de IA que orquestra a execução em tempo de execução.
Do ponto de vista de um Gateway de IA, a residência de dados aplica-se a:
Crucialmente, a residência é imposta ou violada em tempo de execução.
Em sistemas de IA, a residência de dados não é imposta por uma única configuração. Ela é imposta através de um conjunto de primitivas de tempo de execução dentro do Gateway de IA que coletivamente restringem onde a execução pode ocorrer.
Em plataformas como a TrueFoundry, essas primitivas operam antes e durante a execução da solicitação, garantindo que as garantias de residência se mantenham mesmo sob novas tentativas, falhas e roteamento dinâmico.
As principais primitivas de imposição incluem:
Endpoints de modelo restritos à região
Os modelos são registrados e expostos ao Gateway de IA com afinidade regional explícita. O gateway só pode encaminhar solicitações para endpoints de modelo que pertençam à região permitida. Isso impede o uso acidental de modelos hospedados globalmente ou entre regiões, mesmo quando vários modelos são configurados para a mesma carga de trabalho.
Pools de nova tentativa e failover restritos à região
Novas tentativas e fallback são uma das fontes mais comuns de violações silenciosas de residência de dados. Um Gateway de IA com reconhecimento de residência de dados restringe a lógica de nova tentativa para que:
Isso garante que o comportamento de alta disponibilidade nunca se sobreponha à intenção de conformidade.
Tabelas de roteamento com reconhecimento de residência de dados
As decisões de roteamento no gateway são avaliadas em relação às restrições de região em tempo de execução. Mesmo quando o roteamento é orientado por políticas (para custo, desempenho ou seleção de modelo), o gateway impõe a residência de dados como uma restrição rígida, não uma preferência.
Isso é especialmente importante em configurações com múltiplos modelos, onde diferentes modelos podem estar disponíveis em diferentes geografias.
Exportadores de observabilidade restritos por residência de dados
Logs de inferência, prompts, respostas e rastreamentos geralmente contêm dados regulamentados. Um Gateway de IA com reconhecimento de residência de dados garante que:
Isso fecha uma lacuna comum de conformidade onde a inferência é local, mas os metadados não são.
Enquanto a residência de dados responde onde os dados são tratados, a soberania de dados responde quem, em última instância, controla os dados e sob qual jurisdição legal.
Para Gateways de IA, a soberania é determinada por:
Uma realidade crítica, mas muitas vezes negligenciada, é esta: Os dados podem residir num país enquanto a sua soberania pertence a outro.
Gateways de IA frequentemente interagem com:
Mesmo que a inferência ocorra localmente, a soberania pode ser comprometida se:
Para empresas regulamentadas, a soberania é, portanto, uma questão de controle arquitetônico, não de geografia.
Um Gateway de IA que as empresas não controlam totalmente não pode garantir a soberania, independentemente de onde é executado.
Na camada do Gateway de IA, a diferença entre residência de dados e soberania de dados torna-se operacionalmente visível. Ambos devem ser aplicados em tempo de execução, mas resolvem riscos diferentes.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Estes são padrões de falha recorrentes observados quando Gateways de IA são avaliados sem uma perspetiva que considere a soberania.
As empresas implementam modelos numa região de nuvem local e assumem que a conformidade está garantida. Na realidade, o Gateway de IA ainda pode:
Gateways frequentemente tentam novamente ou fazem failover automaticamente. Sem restrições explícitas:
Mesmo que a inferência seja local, os agentes podem invocar ferramentas através do gateway que:
Prompts, respostas e rastros frequentemente contêm dados regulamentados.
Se o Gateway de IA exportar telemetria para fora dos limites aprovados, a soberania é comprometida silenciosamente.
A maioria das plataformas de IA trata a governança de dados como um(a) problema de implantação. A TrueFoundry trata-o como um(a) problema de aplicação em tempo de execução.
Em escala empresarial, a residência e a soberania dos dados não são garantidas por onde a infraestrutura é implantada, mas por como a execução é controlada. Em sistemas de IA modernos, onde as requisições são roteadas dinamicamente entre modelos, agentes invocam ferramentas e pipelines de observabilidade exportam metadados, a única camada com contexto suficiente para aplicar a governança corretamente é o(a) Gateway de IA.
O TrueFoundry foi projetado com base neste princípio.
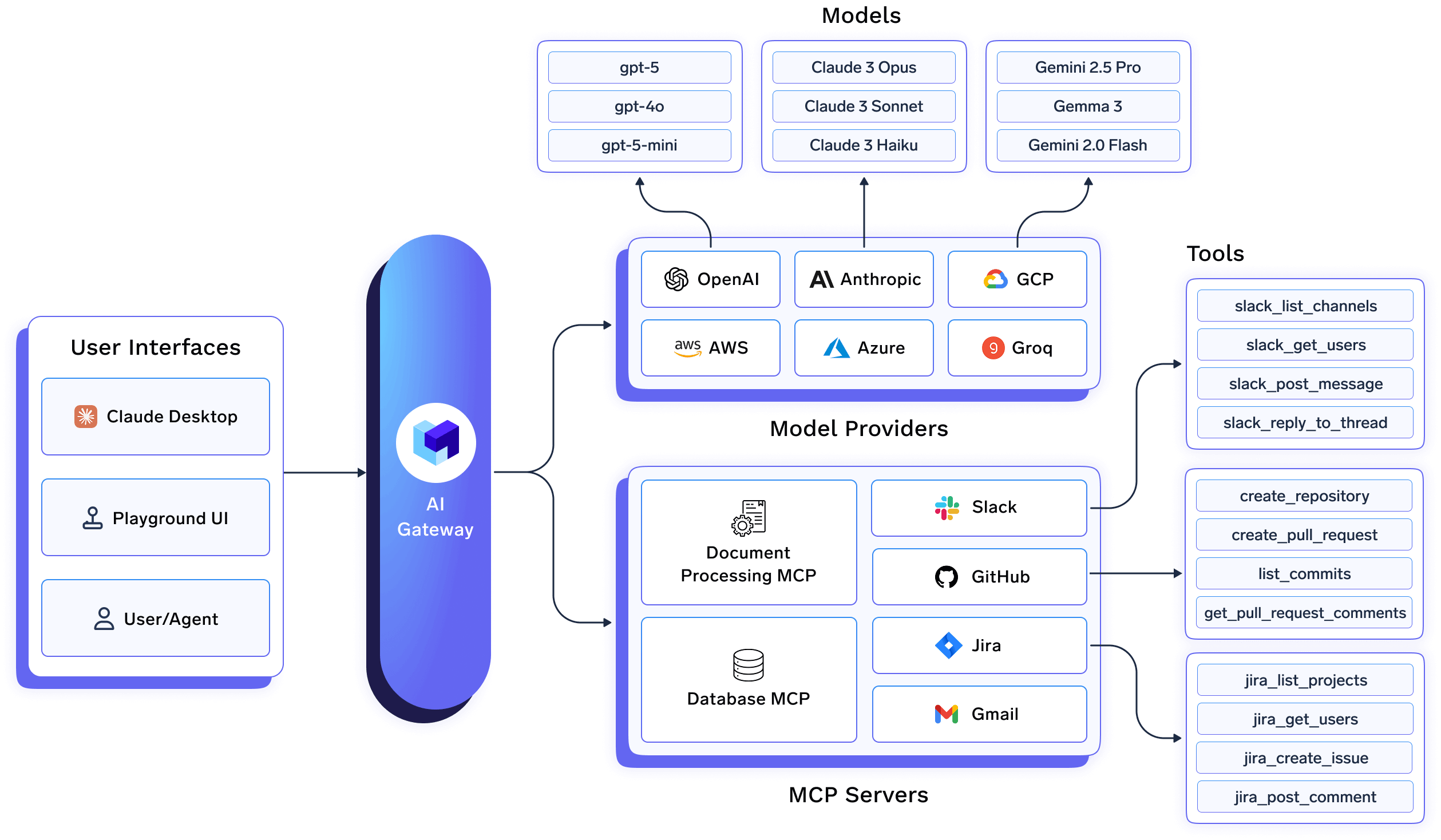
Em TrueFoundry, o Gateway de IA não é um proxy simples na frente dos modelos. É um plano de controle que se encontra no ponto de convergência de:
Como cada solicitação passa por esta camada, o TrueFoundry pode impor tanto a residência quanto a soberania como políticas de tempo de execução de primeira classe, não garantias de melhor esforço.
Esta distinção é importante.
Da TrueFoundry Gateway de IA impõe residência ao limitar os caminhos de execução, em vez de depender da seleção estática de região.
Concretamente, isso significa:
Se uma solicitação não puder ser satisfeita dentro das restrições de residência, ela falha de forma segura (fail-closed) em vez de ser roteada silenciosamente para outro lugar.
Isso elimina uma das falhas de conformidade mais comuns em sistemas de IA: execução entre regiões durante caminhos de exceção.
A soberania dos dados é fundamentalmente sobre quem controla o acesso, não onde o processamento é executado.
A TrueFoundry garante a soberania ao assegurar que as empresas mantêm o controlo sobre:
Como o gateway está sob o controlo da empresa, a soberania não depende de:
Esta é uma diferença crucial em relação aos serviços de IA hospedados, onde a inferência pode ser local, mas o controlo não é.
Uma vantagem fundamental da abordagem da TrueFoundry é a consistência.As políticas de residência e soberania são aplicadas uniformemente em:
Isso evita um modo de falha comum onde:
Ao tratar o AI Gateway como um ponto de aplicação compartilhado, a TrueFoundry garante que a governança seja em todo o sistema, não fragmentada.
Em sistemas de IA modernos, a governança de dados não é mais definida por onde a infraestrutura é implantada, mas sim por como a execução é controlada em tempo de execução. À medida que modelos, agentes e ferramentas interagem dinamicamente, tanto a residência de dados quanto a soberania de dados devem ser aplicadas centralmente para permanecerem significativas.
A residência determina onde os dados são processados. A soberania determina quem os controla. Resolver um sem o outro deixa lacunas, especialmente em Gateways de IA que lidam com roteamento, failover, fluxos de trabalho de agentes e observabilidade.
Como cada solicitação de inferência e invocação de ferramenta passa por eles, Gateways de IA são o único lugar onde essas garantias podem ser aplicadas de forma consistente. A TrueFoundry trata o Gateway de IA como um plano de controle de governança, tornando a residência e a soberania propriedades de sistema aplicáveis, não suposições.
Essa distinção é o que transforma a IA de uma capacidade experimental em um sistema de nível de produção e em conformidade.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




