




July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Suponha que haja uma equipe A designada para desenvolver um aplicativo RAG para use-case-1, então há a equipe B que está desenvolvendo um aplicativo RAG para use-case-2, e depois há a equipe C, que está apenas planejando seu próximo caso de uso de aplicativo RAG. Você já desejou que a construção de pipelines RAG em várias equipes fosse fácil? Cada equipe não precisaria começar do zero, mas sim de uma forma modular onde cada equipe pudesse usar a mesma funcionalidade base e desenvolver efetivamente seus próprios aplicativos sobre ela sem qualquer interferência?
Não se preocupe!! É por isso que criamos Cognita. Embora o RAG seja inegavelmente impressionante, o processo de criar um aplicativo funcional com ele pode ser assustador. Há uma quantidade significativa a ser compreendida sobre as práticas de implementação e desenvolvimento, desde a seleção dos modelos de IA apropriados para o caso de uso específico até a organização eficaz dos dados para obter os insights desejados. Embora ferramentas como LangChain e LlamaIndex existam para simplificar o processo de design de protótipos, ainda não havia um modelo RAG de código aberto acessível e pronto para uso que incorporasse as melhores práticas e oferecesse suporte modular, permitindo que qualquer pessoa o utilizasse de forma rápida e fácil.
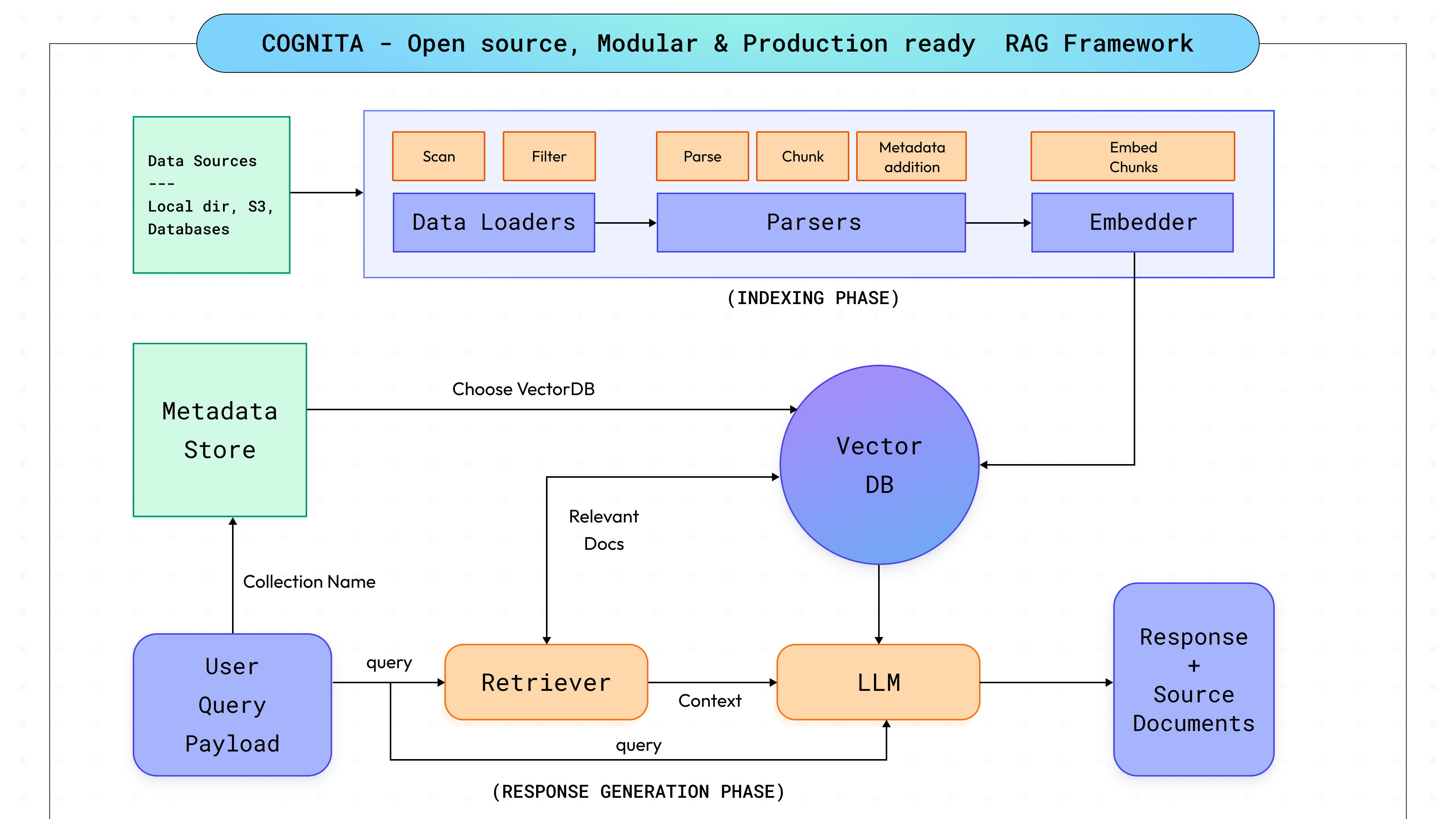
Ao aprofundarmo-nos no funcionamento interno do Cognita, nosso objetivo era encontrar um equilíbrio entre personalização total e adaptabilidade, garantindo ao mesmo tempo a facilidade de uso desde o primeiro momento. Dado o rápido avanço em RAG e IA, era imperativo para nós projetar o Cognita com escalabilidade em mente, permitindo a integração perfeita de novas descobertas e diversos casos de uso. Isso nos levou a dividir o processo RAG em etapas modulares distintas (conforme mostrado no diagrama acima, a ser discutido nas seções subsequentes), facilitando a manutenção do sistema, a adição de novas funcionalidades, como a interoperabilidade com outras bibliotecas de IA, e permitindo que os usuários adaptem a plataforma às suas necessidades específicas. Nosso foco permanece em fornecer aos usuários uma ferramenta robusta que não apenas atenda às suas necessidades atuais, mas também evolua junto com a tecnologia, incluindo mudanças arquitetônicas mais amplas, como MCP vs RAG, garantindo valor a longo prazo.
Cognita é projetado em torno de sete módulos diferentes, cada um personalizável e controlável para atender a diferentes necessidades:
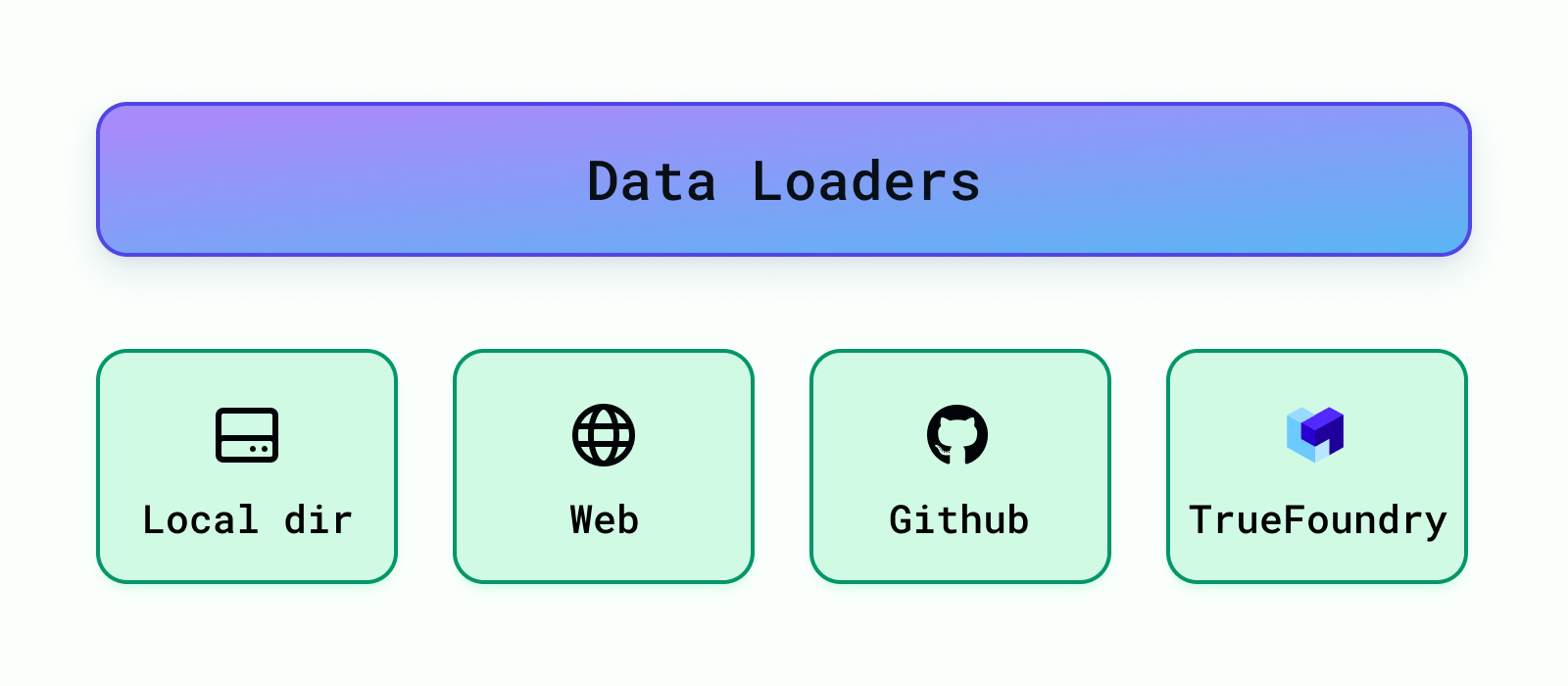
Estes carregam os dados de diferentes fontes, como diretórios locais, buckets S3, bancos de dados, Truefoundry artefatos, etc. Atualmente, o Cognita suporta o carregamento de dados de diretórios locais, URLs da web, repositórios Github e artefatos Truefoundry. Mais carregadores de dados podem ser facilmente adicionados em backend/modules/dataloaders/ . Uma vez que um carregador de dados é adicionado, você precisa registrá-lo para que possa ser usado pela aplicação RAG em backend/modules/dataloaders/__init__.py Para registrar um carregador de dados, adicione o seguinte:
Nesta etapa, lidamos com diferentes tipos de dados, como arquivos de texto comuns, PDFs e até mesmo arquivos Markdown. O objetivo é transformar todos esses tipos diferentes em um formato comum para que possamos trabalhar com eles mais facilmente mais tarde. Esta parte, chamada de análise (parsing), geralmente é a mais demorada e difícil de implementar ao configurar um sistema como este. Mas usar o Cognita pode ajudar, pois ele já lida com o trabalho árduo de gerenciar pipelines de dados para nós.
Depois disso, dividimos os dados analisados em blocos uniformes. Mas por que precisamos disso? O texto que obtemos dos arquivos pode ter comprimentos diferentes. Se usarmos esses textos longos diretamente, acabaremos adicionando um monte de informações desnecessárias. Além disso, como todos os LLMs só conseguem lidar com uma certa quantidade de texto por vez, não seremos capazes de incluir todo o contexto importante necessário para a pergunta. Então, em vez disso, vamos dividir o texto em partes menores para cada seção. Intuitivamente, blocos menores conterão conceitos relevantes e serão menos "barulhentos" em comparação com blocos maiores.
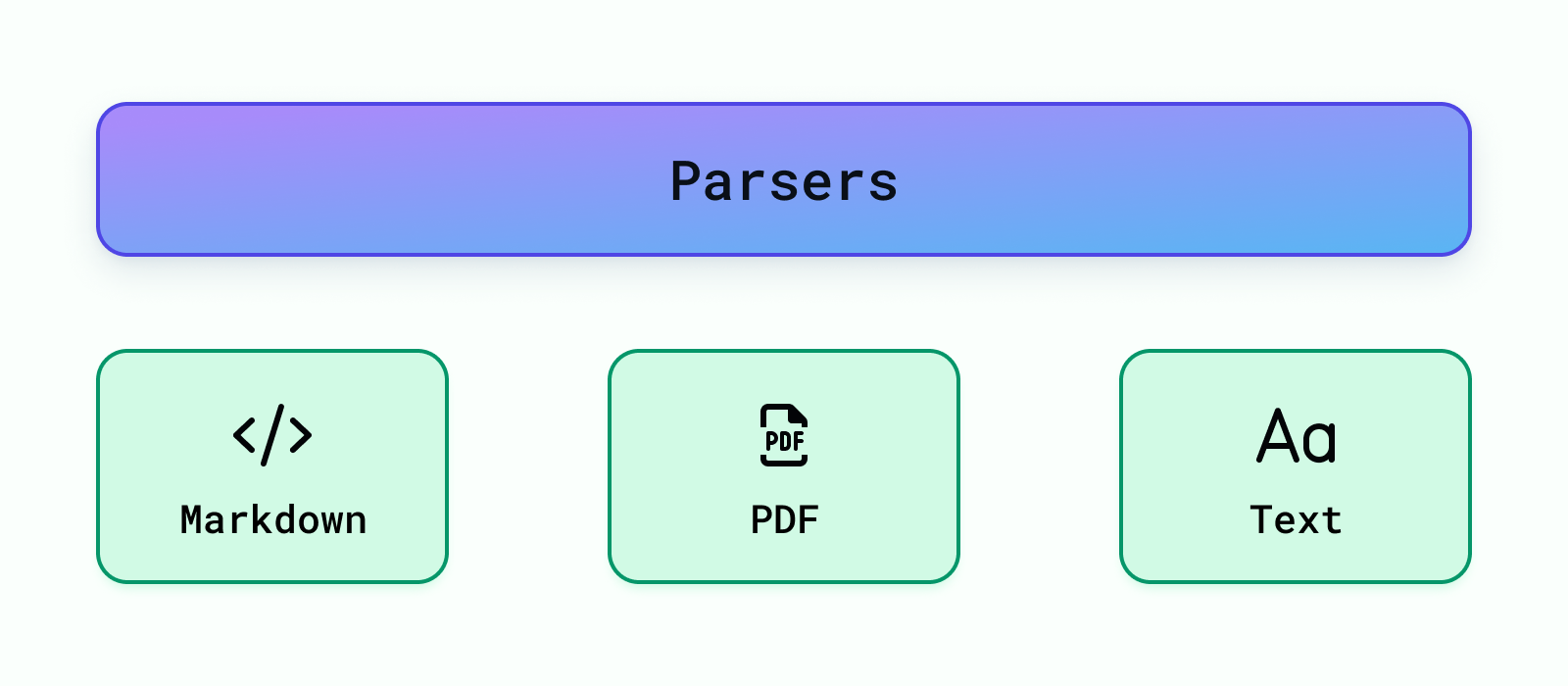
Atualmente, suportamos a análise para Markdown, PDF e Texto arquivos. Mais analisadores de dados podem ser facilmente adicionados em backend/modules/parsers/ . Uma vez que um analisador é adicionado, você precisa registrá-lo para que possa ser usado pela aplicação RAG em backend/modules/parsers/__init__.py Para registrar um parser, adicione o seguinte:
Depois de dividir os dados em partes menores, queremos encontrar os trechos mais importantes para uma pergunta específica. Uma maneira rápida e eficaz de fazer isso é usando um modelo pré-treinado (modelo de embedding) para converter nossos dados e a pergunta em códigos especiais chamados embeddings. Em seguida, comparamos os embeddings de cada trecho de dados com o da pergunta. Ao medir a similaridade de cosseno entre esses embeddings, podemos descobrir quais trechos estão mais intimamente relacionados à pergunta, ajudando-nos a encontrar os melhores para usar.
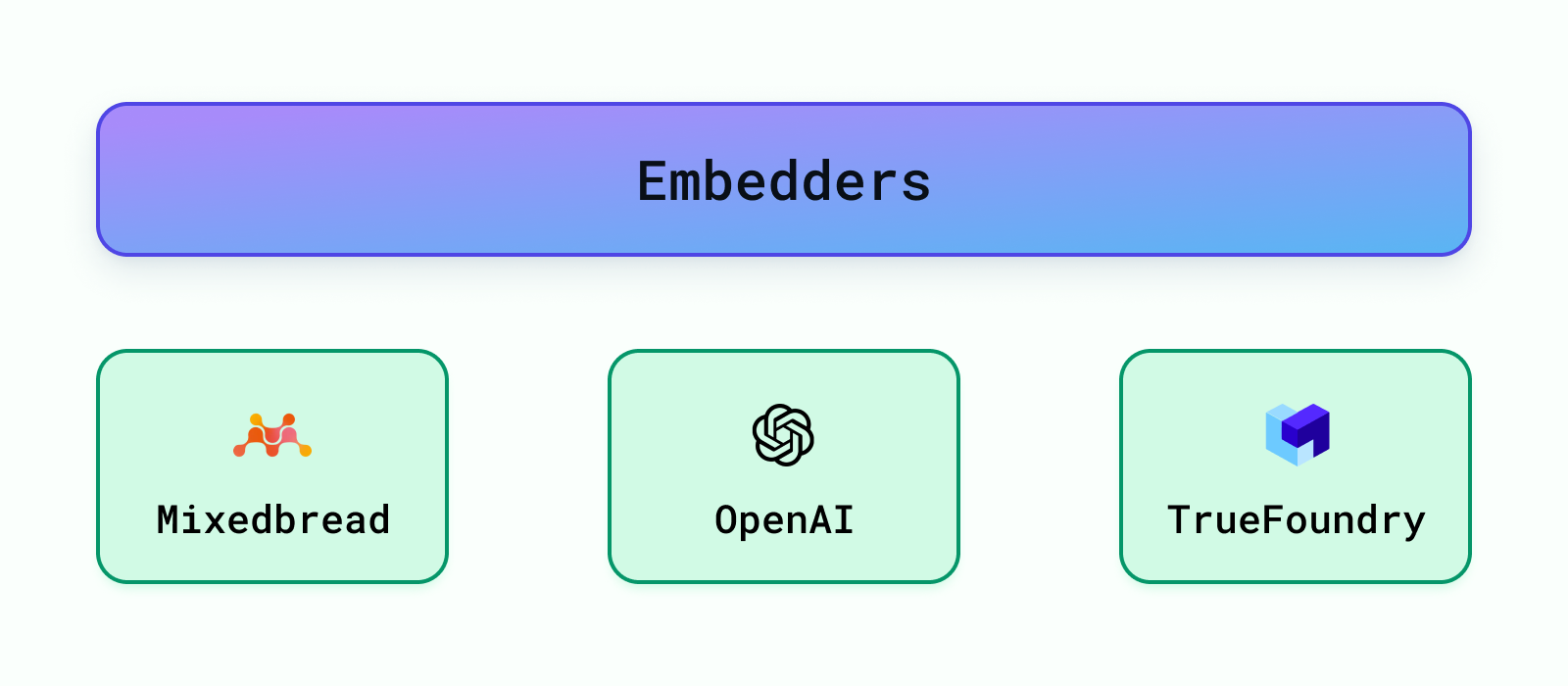
Existem muitos modelos pré-treinados disponíveis para incorporar os dados, como modelos da OpenAI, Cohere, etc. Os mais populares podem ser descobertos através do Massive Text Embedding Benchmark (MTEB) da HuggingFace leaderboard. Oferecemos suporte para OpenAI Embeddings, TrueFoundry Embeddings e também para os embeddings SOTA (a partir de abril de 2024) da mixedbread-ai.
Mais geradores de embeddings podem ser facilmente adicionados em backend/modules/embedder/ . Uma vez que um gerador de embeddings é adicionado, você precisa registrá-lo para que possa ser usado pela aplicação RAG em backend/modules/embedders/__init__.py Para registrar um parser, adicione o seguinte:
Nota: Lembre-se, embeddings não são o único método para encontrar segmentos importantes. Poderíamos também usar um LLM para esta tarefa! No entanto, LLMs são muito maiores que os modelos de embedding e têm um limite na quantidade de texto que podem processar de uma vez. É por isso que é mais inteligente usar embeddings para selecionar os k melhores segmentos primeiro. Depois, podemos usar LLMs nesses poucos segmentos para descobrir os melhores a serem usados como contexto para responder à nossa pergunta.
Uma vez que a etapa de embedding encontra algumas correspondências potenciais, que podem ser muitas, uma etapa de reordenação (reranking) é aplicada. O reranking garante que os melhores resultados estejam no topo. Como resultado, podemos escolher os x melhores documentos, tornando nosso contexto mais conciso e a consulta do prompt mais curta. Oferecemos suporte para SOTA reranker (a partir de abril de 2024) da mixedbread-ai que é implementado em backend/modules/reranker/
Depois de criarmos vetores para textos, nós os armazenamos em algo chamado banco de dados vetorial. Este banco de dados rastreia esses vetores para que possamos encontrá-los rapidamente mais tarde usando diferentes métodos. Bancos de dados regulares organizam dados em tabelas, como linhas e colunas, mas os bancos de dados vetoriais são especiais porque armazenam e encontram dados com base nesses vetores. Isso é super útil para coisas como reconhecimento de imagens, compreensão de linguagem ou recomendação de itens. Por exemplo, em um sistema de recomendação, cada item que você pode querer recomendar (como um filme ou um produto) é transformado em um vetor, com diferentes partes do vetor representando diferentes características do item, como seu gênero ou preço. Da mesma forma, em processamento de linguagem, cada palavra ou documento é transformado em um vetor, com partes do vetor representando características da palavra ou documento, como a frequência com que a palavra é usada ou o que ela significa. Esses bancos de dados vetoriais são projetados para lidar com isso de forma eficiente. Usando diferentes maneiras de medir a proximidade dos vetores entre si, como o quão semelhantes são ou o quão distantes estão, encontramos os vetores mais próximos da consulta do usuário fornecida. As formas mais comuns de medir isso são Distância Euclidiana, Similaridade de Cosseno e Produto Escalar.
Existem vários bancos de dados vetoriais disponíveis no mercado, como Qdrant, SingleStore, Weaviate, etc. Atualmente, oferecemos suporte para Qdrant e SingleStore. A classe do banco de dados vetorial Qdrant é definida em /backend/modules/vector_db/qdrant.py, enquanto a classe do banco de dados vetorial SingleStore é definida em /backend/modules/vector_db/singlestore.py
Outros VectorDBs também podem ser adicionados em vector_db pasta e pode ser registrado em /backend/modules/vector_db/__init__.py
Para adicionar qualquer suporte a DB vetorial no Cognita, o usuário precisa fazer o seguinte:
BaseVectorDB (from backend.modules.vector_db.base import BaseVectorDB) e inicialize-a com VectorDBConfig (from backend.types import VectorDBConfig)create_collection: Para inicializar a coleção/projeto/tabela no DB vetorial.upsert_documents: Para inserir os documentos no DB.get_collections: Obter todas as coleções presentes na base de dados.delete_collection: Para excluir a coleção da base de dados.get_vector_store: Para obter o armazenamento de vetores para a coleção especificada.get_vector_client: Para obter o cliente de vetores para a coleção especificada, se houver.list_data_point_vectors: Para listar os vetores já presentes na base de dados que são semelhantes aos documentos que estão sendo inseridos.delete_data_point_vectors: Para excluir os vetores da base de dados, usado para remover vetores antigos do documento atualizado.Mostramos agora como podemos adicionar uma nova base de dados de vetores ao sistema RAG. Usamos como exemplo tanto Qdrant e SingleStore bancos de dados vetoriais.
Qdrant é um Banco de Dados Vetorial de Código Aberto e um Mecanismo de Busca Vetorial escrito em Rust. Ele oferece busca vetorial rápida e escalável por similaridade com uma API conveniente. Para adicionar o banco de dados vetorial Qdrant ao sistema RAG, siga os passos abaixo:
No arquivo .env você pode adicionar o seguinte
VECTOR_DB_CONFIG = '{"url": "<url_here>", "provider": "qdrant"}' # URL do Qdrant para instância implantadaVECTOR_DB_CONFIG='{"provider":"qdrant","local":"true"}'# Para uma instância Qdrant local baseada em arquivo, sem docker
QdrantVectorDB em backend/modules/vector_db/qdrant.py que herda de BaseVectorDB e inicialize-a com VectorDBConfigcreate_collection método para criar uma coleção no Qdrantupsert_documents método para inserir os documentos na base de dadosget_collections método para obter todas as coleções presentes na base de dadosdelete_collection método para eliminar a coleção da base de dadosget_vector_store método para obter o armazenamento de vetores para a coleção especificadaget_vector_client método para obter o cliente de vetor para a coleção especificada, se existirlist_data_point_vectors método para listar vetores já presentes no banco de dados que são semelhantes aos documentos sendo inseridosdelete_data_point_vectors método para excluir os vetores do banco de dados, usado para remover vetores antigos do documento atualizadoSingleStore oferece uma funcionalidade poderosa de banco de dados vetorial, perfeitamente adequada para aplicações baseadas em IA, chatbots, reconhecimento de imagem e muito mais, eliminando a necessidade de você operar um banco de dados vetorial especializado apenas para suas cargas de trabalho de vetores. Ao contrário dos bancos de dados vetoriais tradicionais, o SingleStore armazena dados vetoriais em tabelas relacionais juntamente com outros tipos de dados. A co-localização de dados vetoriais com dados relacionados permite que você consulte facilmente metadados estendidos e outros atributos de seus dados vetoriais com todo o poder do SQL.
SingleStore oferece um nível gratuito para desenvolvedores começarem a usar seu banco de dados vetorial. Você pode se inscrever para uma conta gratuita aqui. Após o cadastro, vá para Cloud -> workspace -> Criar Usuário. Use as credenciais para se conectar à instância do SingleStore.
No arquivo .env, você pode adicionar o seguinte
VECTOR_DB_CONFIG = '{"url": "<url_aqui>", "provider": "singlestore"}' # url: mysql://{user}:{password}@{host}:{port}/{db}
Para adicionar o banco de dados vetorial SingleStore ao sistema RAG, siga os passos abaixo:
SingleStoreVectorDB em backend/modules/vector_db/singlestore.py que herda de BaseVectorDB e inicialize-a com VectorDBConfigcreate_collection método para criar uma coleção no SingleStoreupsert_documents método para inserir os documentos no banco de dadosget_collections método para obter todas as coleções presentes no banco de dadosdelete_collection método para excluir a coleção do banco de dadosget_vector_store método para obter o armazenamento de vetores para a coleção especificadaget_vector_client método para obter o cliente de vetores para a coleção especificada, se houverlist_data_point_vectors método para listar vetores já presentes no banco de dados que são semelhantes aos documentos a serem inseridosdelete_data_point_vectors método para excluir os vetores do banco de dados, usado para remover vetores antigos do documento atualizadoIsto contém as configurações necessárias que definem de forma única um projeto ou aplicativo RAG. Um aplicativo RAG pode conter um conjunto de documentos de uma ou mais fontes de dados combinados, que denominamos como coleção. Os documentos dessas fontes de dados são indexados no banco de dados de vetores usando métodos de carregamento de dados + análise + incorporação. Para cada caso de uso RAG, o repositório de metadados contém:
Atualmente, definimos duas formas de armazenar esses dados, uma localmente e outra utilizando Truefoudry. Esses armazenamentos são definidos em - backend/modules/metada_store/
Uma vez que os dados são indexados e armazenados no db vetorial, agora é hora de combinar todas as partes para usar nosso aplicativo. Os Controladores de Consulta fazem exatamente isso! Eles nos ajudam a recuperar a resposta para a consulta do usuário correspondente. As etapas típicas de um controlador de consulta são as seguintes:
nome da coleção o db vetorial relevante é buscado com sua configuração como o embedder utilizado, tipo de db vetorial, etc.consulta, documentos relevantes são recuperados utilizando o retriever do db vetorial.contexto e, juntamente com a consulta, também conhecida como pergunta é fornecida ao LLM para gerar a resposta. Esta etapa também pode envolver o ajuste de prompts.Nota: No caso de agentes, as etapas intermediárias também podem ser transmitidas. Cabe à aplicação específica decidir.
Os métodos do controlador de consulta podem ser expostos diretamente como uma API, adicionando decoradores http às funções respetivas.
Para adicionar o seu próprio controlador de consulta, siga os seguintes passos:
app-2. Assim, escreveremos o nosso controlador em /backend/modules/query_controller/app-2/controller.pyquery_controller decorador à sua classe e passe o nome do seu controlador personalizado como argumentopost, get, delete para tornar seus métodos uma APIbackend/modules/query_controllers/__init__.pyUm controlador de consulta de exemplo está escrito em: /backend/modules/query_controller/example/controller.py Para melhor compreensão, consulte
Um processo típico do Cognita consiste em duas fases:
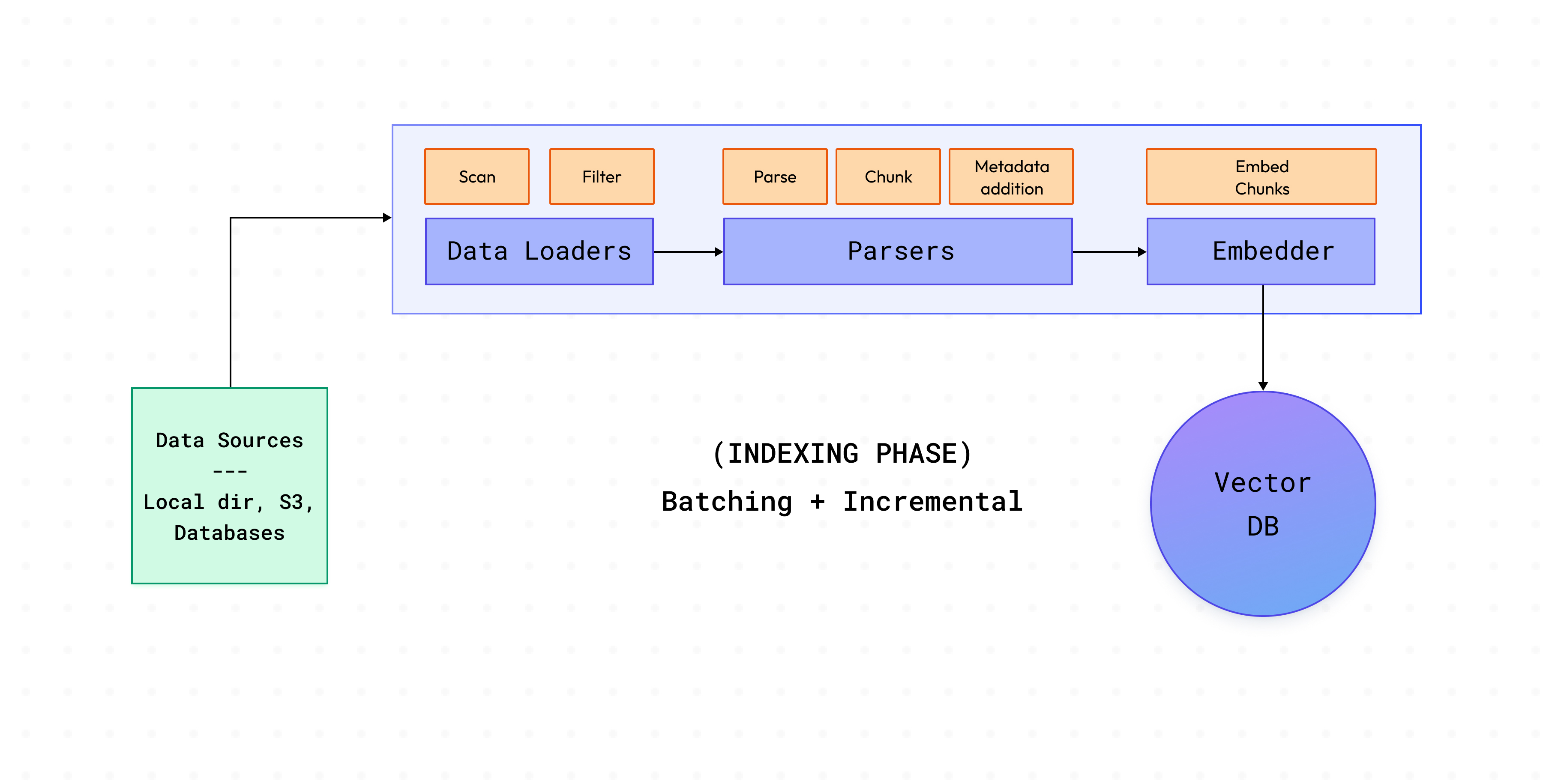
Esta fase envolve o carregamento de dados de fontes, a análise dos documentos presentes nessas fontes e a indexação deles no banco de dados vetorial. Para lidar com grandes quantidades de documentos encontrados em produção, o Cognita vai um passo além.
INCREMENTAL indexação, existe também outro modo suportado no Cognita que é a COMPLETA indexação. A indexação COMPLETA re-ingere os dados para o banco de dados vetorial, independentemente de quaisquer dados vetoriais presentes para a coleção fornecida.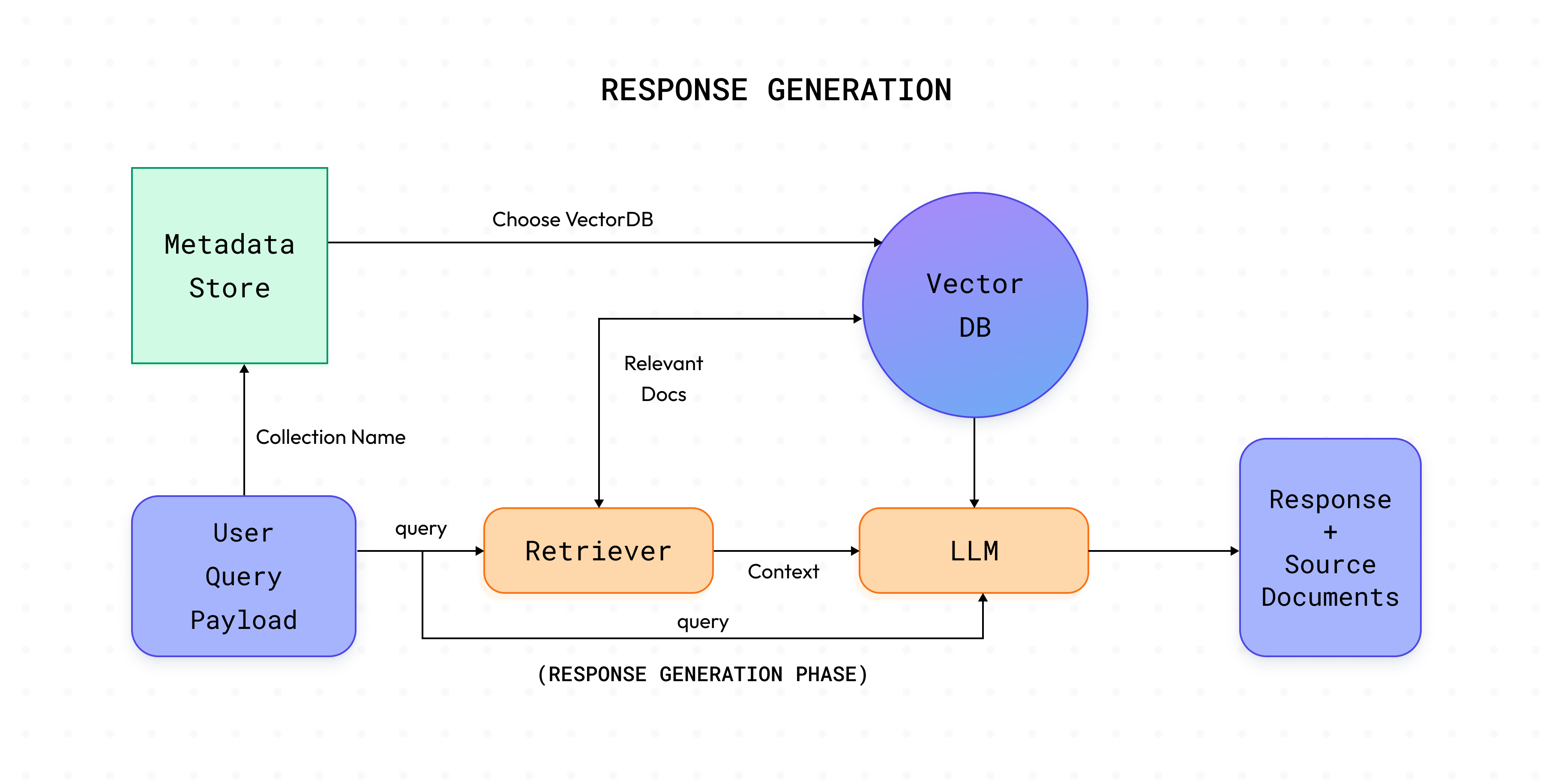
A fase de geração de resposta faz uma chamada para o /answer endpoint do seu QueryController definido e gera a resposta para a consulta solicitada.
Os passos seguintes demonstram como usar a UI do Cognita para consultar documentos:
1. Criar Fonte de Dados
aba Fontes de Dados 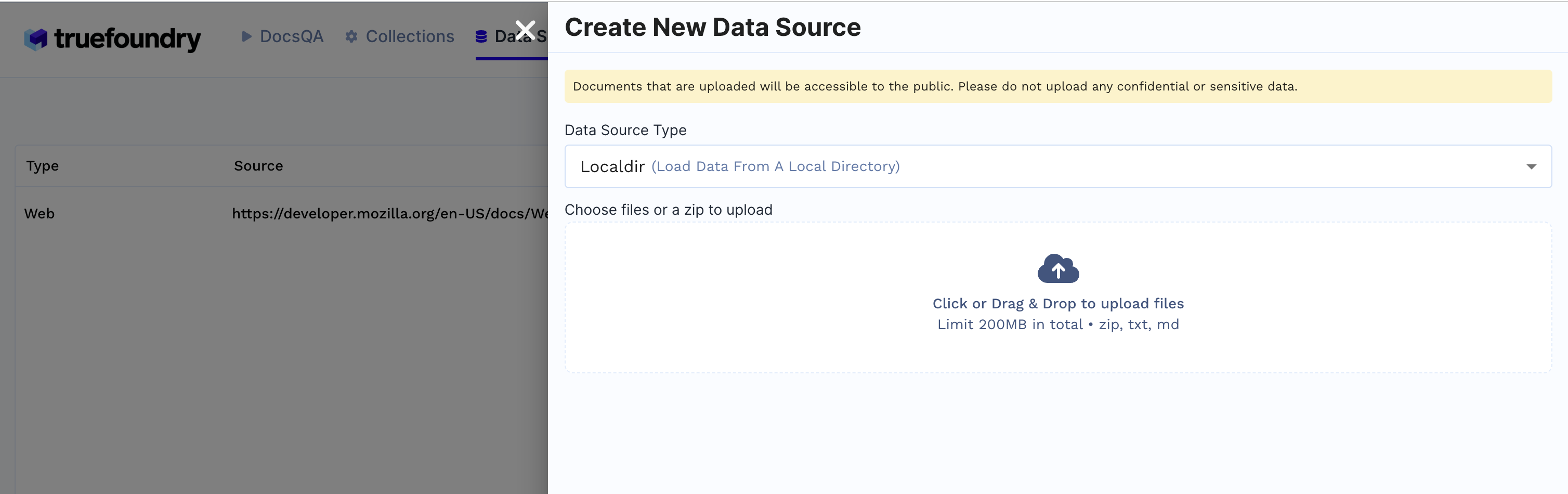
+ Nova Fonte de DadosDiretório local for selecionado, carregue os arquivos da sua máquina e clique em Enviar.
2. Criar Coleção
Coleções aba+ Nova Coleção 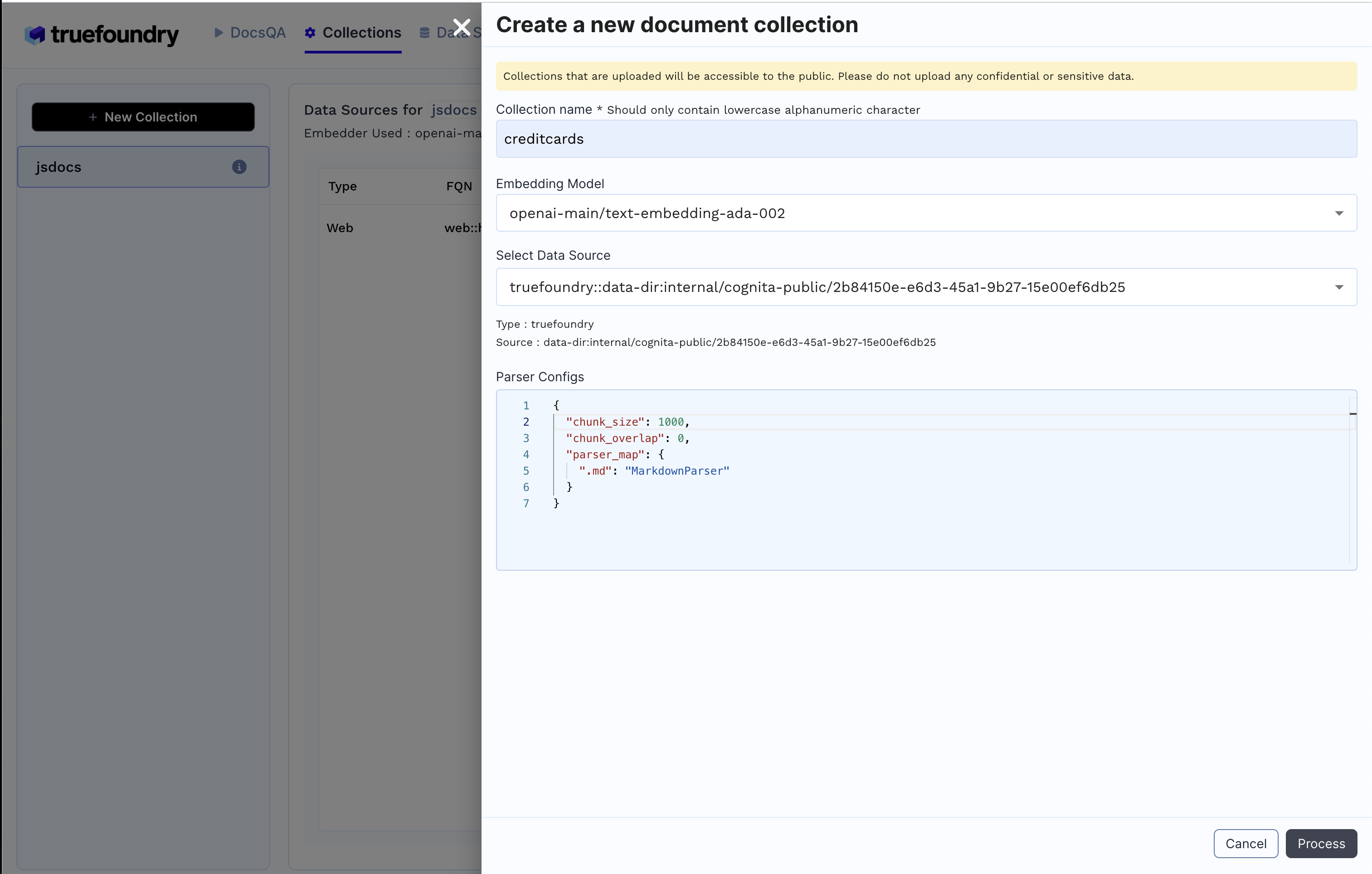
Processar para criar a coleção e indexar os dados. 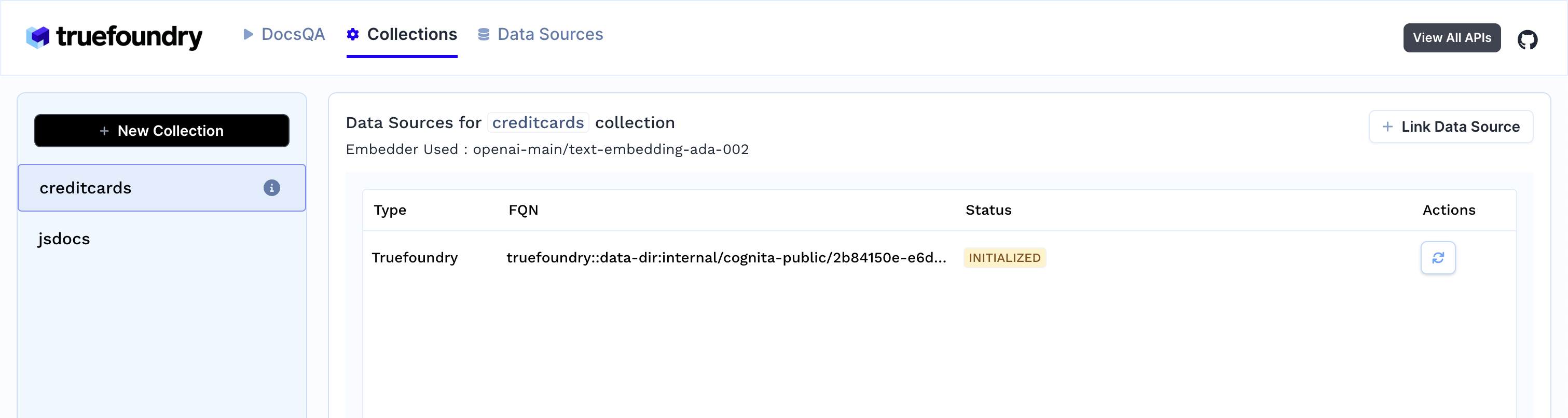
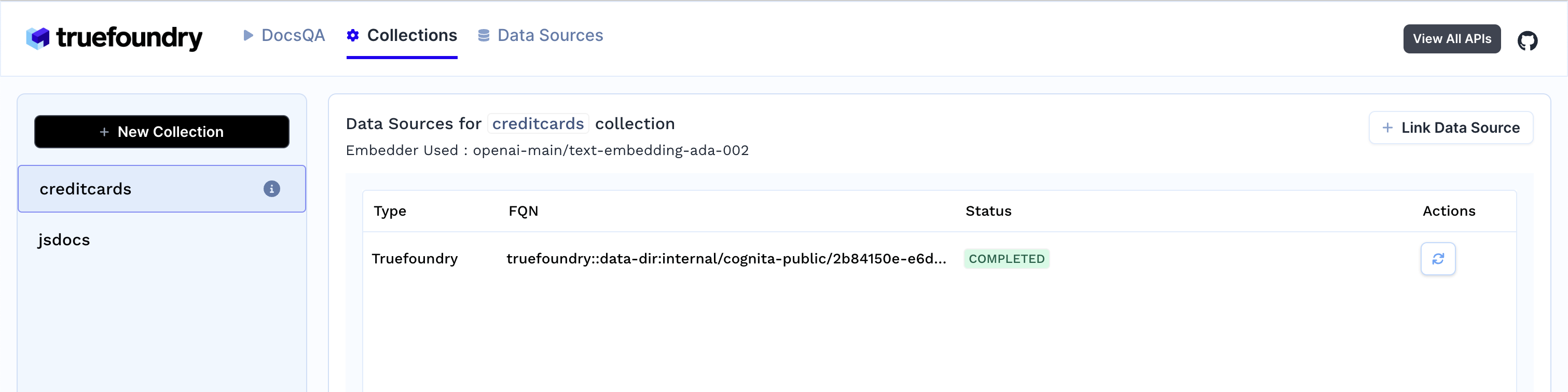
3. Assim que você cria a coleção, a ingestão de dados começa. Você pode ver o status dela selecionando sua coleção na aba de coleções. Você também pode adicionar fontes de dados adicionais mais tarde e indexá-las na coleção.
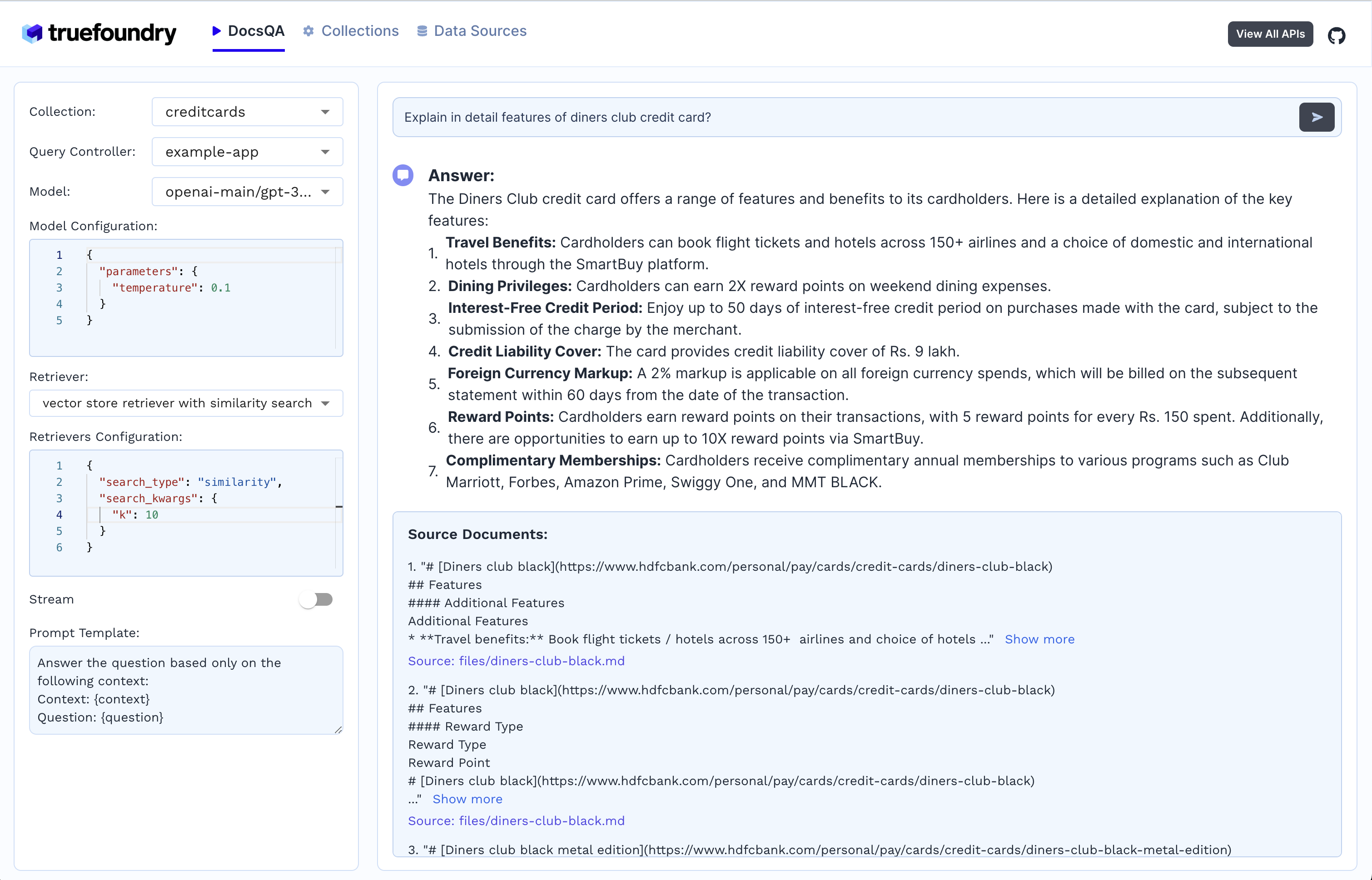
4. Geração de resposta
Agende uma demonstração personalizada ou cadastre-se hoje para começar a construir seus casos de uso RAG.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




