Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Reduza seus Custos de Infraestrutura para modelos de ML / LLM
As cargas de trabalho de machine learning (ML) e de modelos de linguagem grandes (LLM) são notoriamente caras para executar na nuvem. Isso ocorre porque elas exigem quantidades significativas de poder de computação, memória e armazenamento. No entanto, existem maneiras de reduzir seus custos de nuvem para cargas de trabalho de ML/LLM sem sacrificar a escalabilidade ou a confiabilidade.
Princípios Chave para Reduzir Custos
Melhor Visibilidade para Engenheiros DevOps e Desenvolvedores: Obter visibilidade sobre os custos da nuvem é difícil, especialmente quando se tem múltiplos componentes implantados em várias nuvens. A TrueFoundry oferece visibilidade dos custos da nuvem nos níveis de cluster, workspace e implantação, capacitando as equipes DevOps e os desenvolvedores a identificar e otimizar oportunidades de economia de custos ao longo de todo o ciclo de vida de ML/LLM.
Facilidade de Ajuste de Recursos: A TrueFoundry permite que as equipes DevOps e os desenvolvedores ajam com base na visibilidade de custos que obtiveram.
Equipes DevOps podem definir restrições de recursos no nível do projeto, garantindo que as cargas de trabalho de cada equipe tenham acesso aos recursos de que precisam sem exceder o orçamento.
Desenvolvedores também podem ajustar facilmente os recursos em tempo real, com base nos insights que obtêm. Além disso, a TrueFoundry facilita a escalabilidade de aplicações e IDEs para zero em ambientes de não produção, eliminando o custo de recursos ociosos e tornando os ciclos de iteração para redução de custos mais eficientes.
Otimização de Infraestrutura para Custo: A arquitetura baseada em Kubernetes e as otimizações de infraestrutura da TrueFoundry são projetadas para reduzir os custos da nuvem.
No geral, os recursos de economia de custos da TrueFoundry fornecem às equipes DevOps e aos desenvolvedores a visibilidade, o controle e as capacidades de otimização de que precisam para reduzir os custos da nuvem ao longo de todo o ciclo de vida de ML/LLM.
Transição de AMI para Docker: Nossa plataforma facilitou a migração de muitas empresas de AMI para Docker, onde as empresas já experimentaram economias de custo de 30 a 40 por cento.
TrueFoundry: Sua Plataforma Focada em Custos
A Truefoundry é uma "focada em custos" plataforma, construída em torno do Kubernetes, projetada com uma arquitetura que prioriza eficiência, escalabilidade e redução de custos.
Vamos explorar como a arquitetura única da TrueFoundry permite que você economize custos enquanto otimiza a confiabilidade e a escalabilidade. Aqui está a estrutura hierárquica da plataforma:
Clusters: Conecte todos os seus clusters, seja AWS EKS, Azure AKS, GCP GKE ou um cluster on-premise, à plataforma. Isso permite integrar todos os seus clusters em um só lugar de forma contínua. Esses clusters são a base para implantar uma ampla gama de serviços, modelos e tarefas.
Workspaces: Dentro dos clusters, introduzimos workspaces, oferecendo uma abordagem simplificada para adicionar controle de acesso e isolamento, garantindo que cada projeto ou ambiente tenha seus próprios recursos dedicados e seja protegido contra acesso não autorizado. Pense neles como grupos de implantações.
Implantações: Dentro desses workspaces, temos implantações e oferecemos suporte para implantar diferentes tipos de coisas. Com a TrueFoundry, você pode cobrir sem esforço todos os aspectos do seu ciclo de vida de desenvolvimento de ML.
Ambientes de Desenvolvimento Interativos: Implante Jupyter Notebook e VS Code para experimentação colaborativa.
Tarefas de Treinamento e Ajuste Fino: Treine modelos de ML ou ajuste modelos LLM de forma eficiente, implantando-os como uma tarefa.
LLMs Pré-treinados: Implante rapidamente Modelos de Linguagem Grandes pré-treinados para casos de uso específicos usando nosso Catálogo de Modelos.
Serviços e Aplicativos: Implante uma variedade de serviços e aplicativos, incluindo modelos, aplicativos web, etc.
Catálogo de Aplicativos: Implante softwares populares como Label Studio, Redis, Qdrant, etc., com facilidade.
Economia de custos no Nível do Cluster
Infraestrutura baseada em Kubernetes
Kubernetes contribui para a redução de custos ao empregar o empacotamento de bins (bin packing) para otimizar a utilização de recursos, alocando contêineres de forma eficiente e, em última análise, diminuindo os custos de infraestrutura.
Para saber mais sobre como a TrueFoundry aproveita o Kubernetes, leia aqui.
💡
Migração de EC2 para Kubernetes: Muitas empresas migraram com sucesso de máquinas EC2 para Kubernetes após a integração em nossa plataforma, resultando em economia de custos devido à melhor alocação de recursos
[SEG 8]
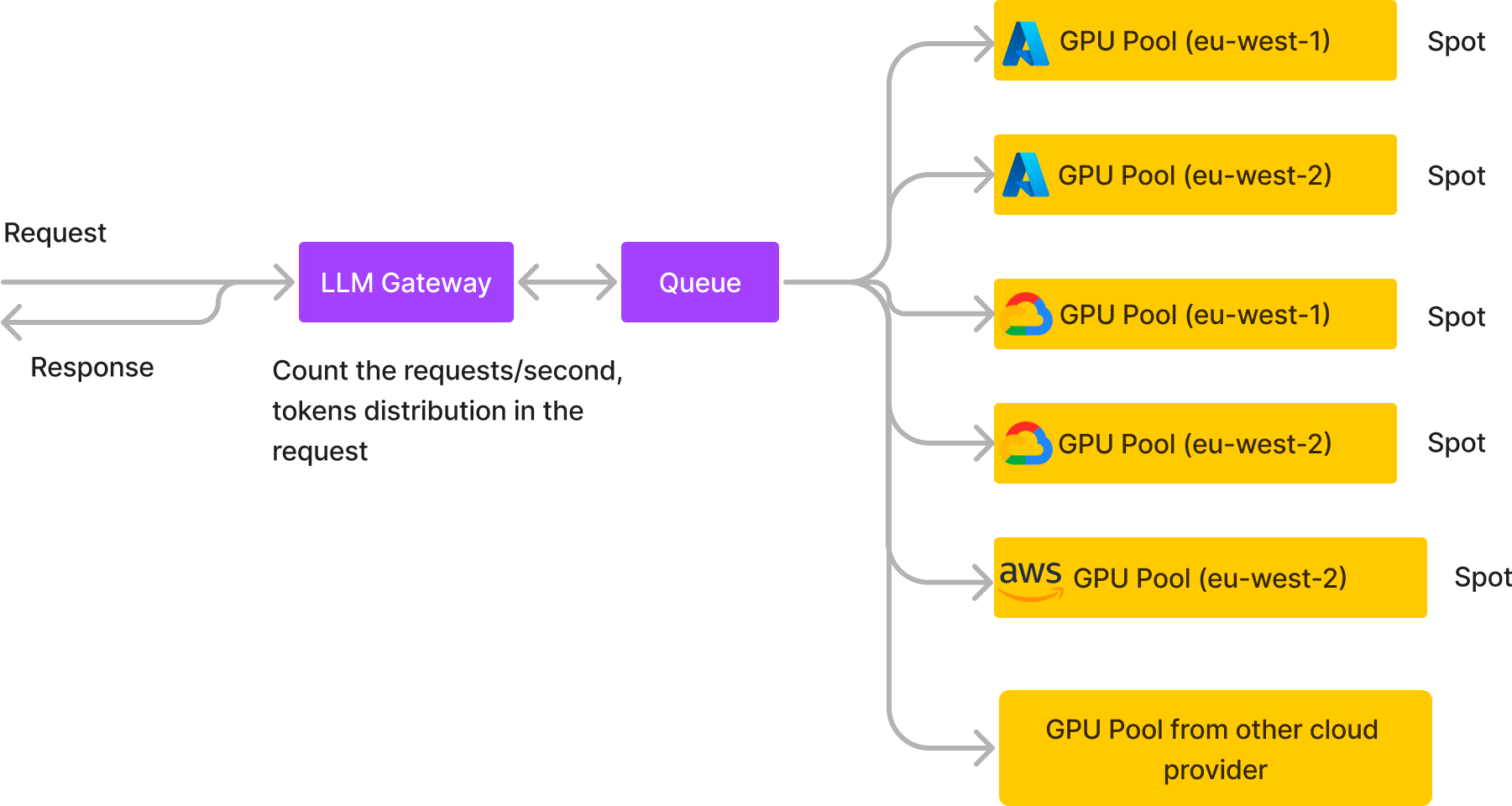
Suporte multi-cloud
A arquitetura multi-cloud da TrueFoundry facilita a conexão com diferentes provedores de nuvem.
Flexibilidade para Alternar Entre Nuvens
: Ao ter a capacidade de alternar facilmente entre diferentes provedores de nuvem, você pode aproveitar os melhores preços e recursos de diferentes provedores.Distribua Cargas de Trabalho Entre Nuvens e Regiões
: Ao distribuir suas cargas de trabalho por vários provedores de nuvem e regiões. Isso pode ajudar a reduzir custos, distribuindo suas cargas de trabalho por diferentes níveis de preços e regiões. Também ajuda a melhorar o desempenho e a confiabilidade, reduzindo sua dependência de um único provedor de nuvem.Alta Disponibilidade de Cota de Instâncias
:Ao usar vários provedores de nuvem, você pode ter acesso a mais recursos. Isso pode ajudar você a economizar dinheiro e evitar quaisquer limitações nos recursos de que precisa. Escalando LLMs em múltiplas nuvens e regiões
💡
Um provedor de chatbot de IA conversacional de médio porte com alto tráfego de usuários (mais de 20 RPS e mais de 2 milhões de solicitações por dia) opera inteiramente em instâncias de GPU spot distribuídas em cinco clusters, em diferentes nuvens e regiões, usando nosso serviço assíncrono. Isso reduz seus custos de infraestrutura em 60%, ao mesmo tempo em que melhora a confiabilidade e o throughput.
Visibilidade Aprimorada
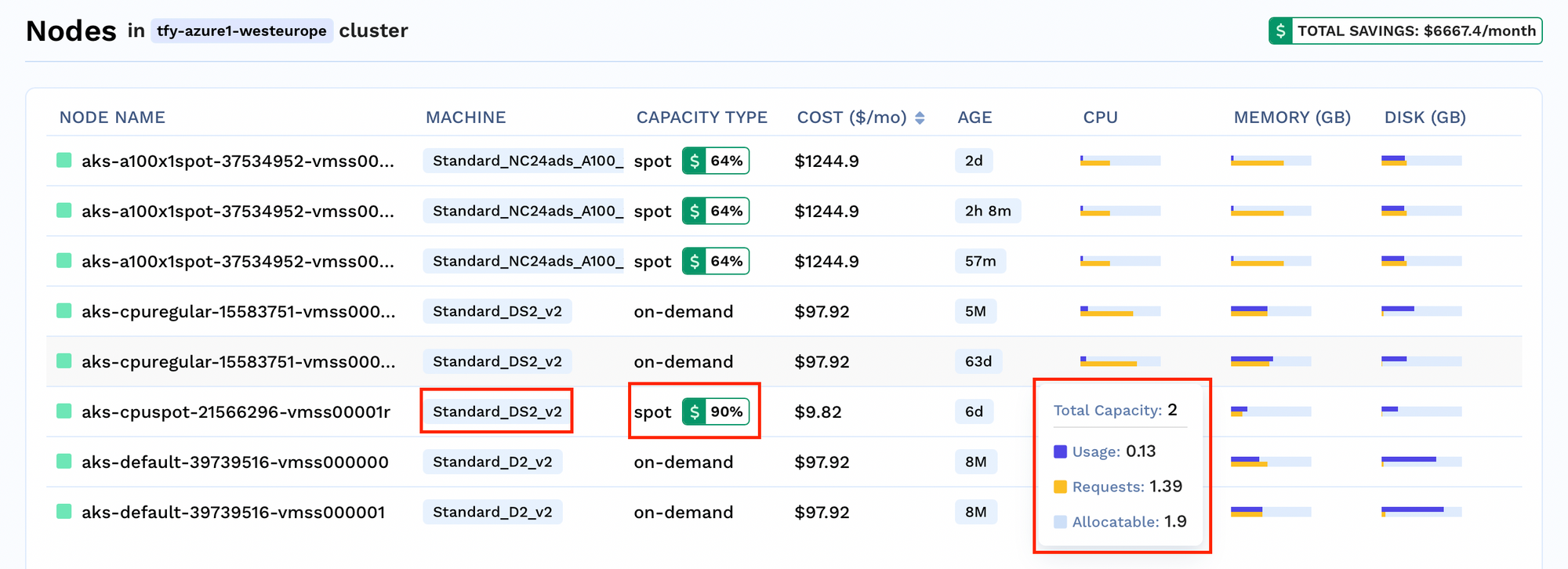
Para cada cluster, você pode visualizar o número de nós em execução no Cluster. Você também pode obter informações detalhadas sobre nós, como
Análise de Economia: Veja a porcentagem de custo economizada para cada nó
Informações sobre Alocação de Recursos: Veja o uso atual, a solicitação de recursos e o limite para tomar decisões informadas.
Informações sobre Tipo de Capacidade: Veja qual tipo de nós está em execução no seu cluster, sejam eles nós spot ou sob demanda.
Economia de Custos no Nível do Workspace
Limites de recursos
O TrueFoundry permite criar múltiplos workspaces dentro de um cluster. Essa segmentação ajuda a organizar suas implantações para diferentes equipes ou ambientes.
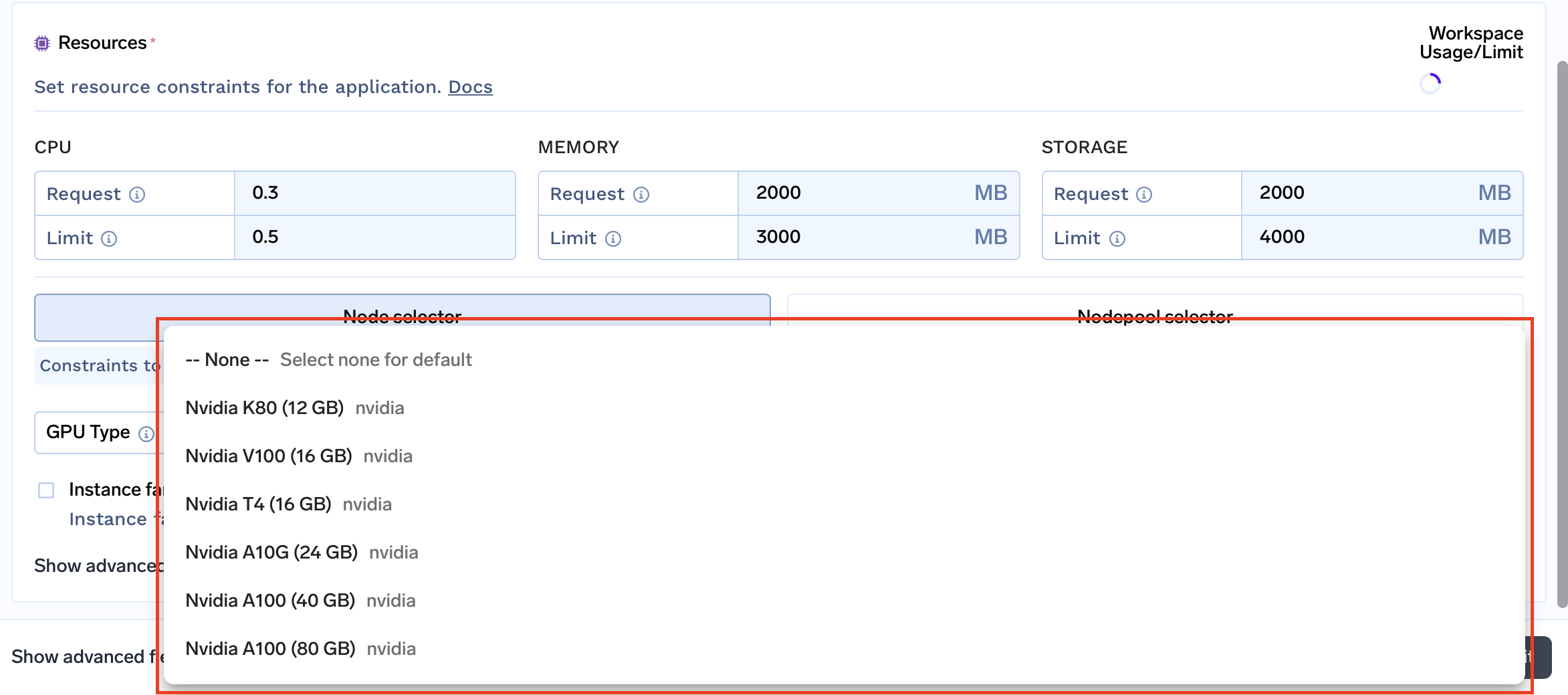
Restrições de Recursos: Personalize as restrições de recursos para cada workspace, incluindo CPU, memória, armazenamento e até mesmo famílias de instâncias. Isso permite alocar os recursos para atender aos requisitos específicos do seu projeto ou ambiente.
Famílias de instâncias suportadas: Adapte seu workspace aos requisitos de desempenho e orçamento específicos, selecionando as famílias de instâncias que ele suportará.
Por exemplo, se um projeto não exige computação de alto desempenho, você pode desabilitar instâncias maiores em seu workspace. Isso ajudará a evitar que os desenvolvedores provisionem recursos em excesso, o que pode gerar economia.
Pools de nós suportados: Pools de nós são grupos de nós que fornecem os recursos computacionais para suas cargas de trabalho. Você pode escolher os pools de nós que melhor se adequam às suas cargas de trabalho e orçamento.
Por exemplo, você pode criar um pool de nós com GPUs A100. Em seguida, você pode habilitar esse pool de nós específico apenas para espaços de trabalho de projeto que exigem acesso a esse tipo de GPU.
Acompanhar o custo em nível de Workspace
Também oferecemos visibilidade para acompanhar o custo do seu workspace com base no uso anterior. Isso permitirá que você identifique quais projetos ou ambientes estão usando mais recursos e onde você pode gerar economias.
Economia de Custos em Nível de Implantação
Oferecemos recursos avançados em nível de aplicação para ajudar você a obter economias de custo significativas:
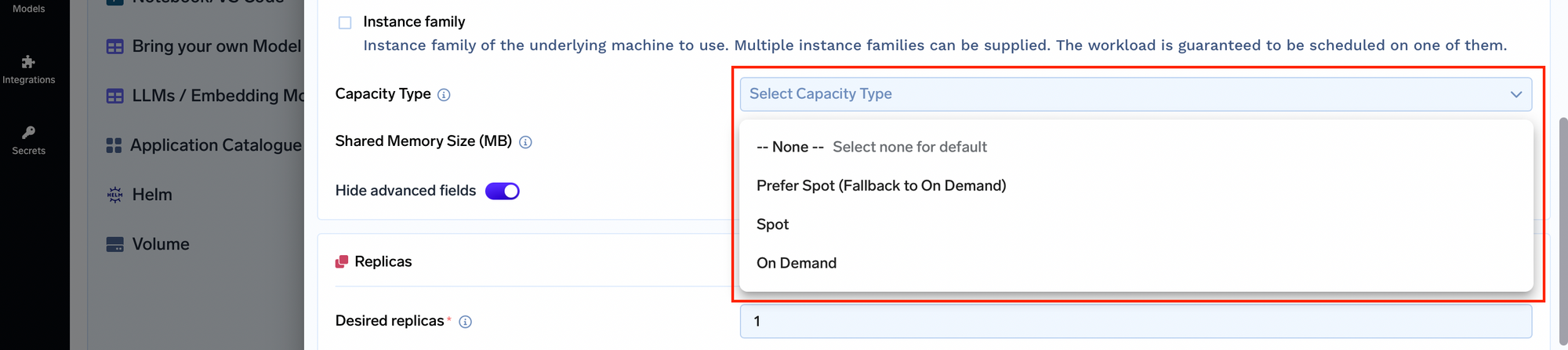
Instâncias Spot com Fallback para Sob Demanda: Geralmente, as aplicações têm dificuldade em equilibrar custo e confiabilidade. TrueFoundry permite que você selecione o tipo de capacidade para seus nós, incluindo instâncias spot com fallback para recursos sob demanda. Isso garante que suas aplicações permaneçam disponíveis mesmo que uma instância spot seja despejada, oferecendo o equilíbrio ideal entre custo e disponibilidade.
Pausar Serviços: Pause os serviços quando não estiverem em uso para economizar custos. Pause ou retome serviços facilmente na página de implantações.
Otimização de Recursos: Garanta que seus recursos sejam alocados de forma otimizada e que seus serviços estejam operando com a capacidade adequada.
Monitoramento de Recursos: Acompanhe a utilização de recursos do seu serviço em tempo real, incluindo alocação de CPU e GPU. Receba alertas sobre superprovisionamento, subprovisionamento e receba recomendações de recursos.
Ajuste Dinâmico de Recursos: Ajuste os níveis de recursos em tempo real para reduzir para um recurso de CPU inferior e reimplantar seu serviço de acordo.
Autoescalonamento Baseado em Tempo: Agende ajustes de recursos com base no tempo para reduzir custos em ambientes de não produção durante períodos de baixo uso.
💡
Muitos dos nossos clientes economizam mais de 60% nos custos de nuvem dos seus ambientes de desenvolvimento ao agendar desligamentos durante o horário não comercial, reduzindo o uso de computação em 128 horas por semana.
Economia de Custos para Editores de Código
Oferecemos certas funcionalidades para Editores de Código, você pode obter economias de custo significativas no nível de Notebook e VSCode:
Volumes Compartilhados: Utilize volumes com base nos requisitos para compartilhar grandes volumes de dados entre Notebooks e Instâncias VSCode e facilitar a colaboração. Volumes compartilhados reduzem a redundância e aumentam a eficiência, especialmente quando vários usuários precisam de acesso a dados substanciais em Notebooks e Instâncias VSCode.
Uso Adaptativo de Recursos: Alterne facilmente entre CPU e GPU na mesma máquina para otimizar a alocação de recursos. Você não precisa manter um recurso de GPU constantemente, apenas quando necessário.
💡
Uma empresa de IA generativa que atua no segmento de geração de vídeo, que executa centenas de Jupyter Notebooks em instâncias spot para cargas de trabalho de não produção, economizou cerca de 50-60% nos custos de nuvem ao ligar as GPUs apenas quando necessário.
Pausa Manual: Pause facilmente instâncias de Notebooks/VSCode quando não estiverem em uso. O código e os dados são persistidos, garantindo uma reinicialização sem interrupções quando necessário.
Pausa Automática: Configure suas instâncias de Notebooks/VSCode para pausar automaticamente após um certo período de inatividade, a fim de economizar recursos valiosos.
💡
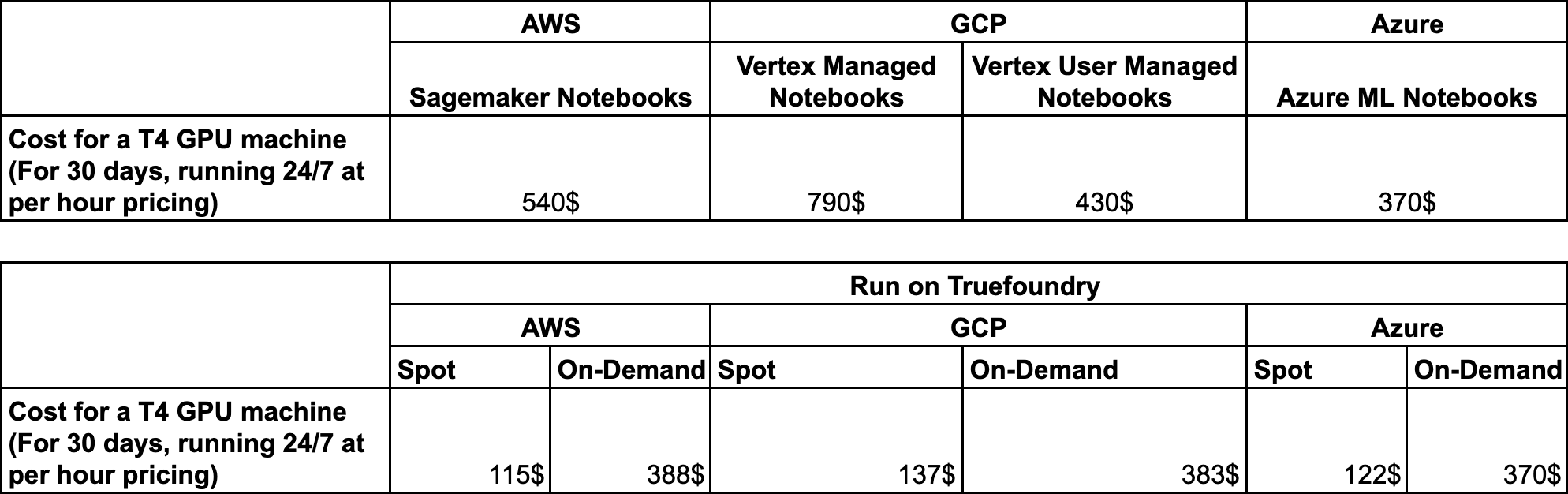
Benchmarking de Custos Realizamos um benchmarking entre AWS, GCP e Azure para comparar a economia de custos de executar Notebooks e VSCode sob demanda ou usando a nuvem correspondente.
Economia de Custos na Implantação e Ajuste Fino de Grandes Modelos de Linguagem (LLMs):
Nosso Catálogo de Modelos oferece uma solução completa e conveniente para implantar e ajustar LLMs pré-treinados conhecidos. Tomamos as seguintes medidas para garantir que a implantação e o ajuste fino desses LLMs sejam o mais eficientes em termos de custo possível:
Configuração Otimizada de Servidor de Modelos: Com base em análises comparativas para diversos servidores de modelos e alocações de recursos, fornecemos configurações pré-preenchidas que oferecem a melhor latência e taxa de transferência. Isso simplifica o processo de implantação de LLMs e ajuda a tornar suas implantações eficientes em termos de recursos e custo.
Configuração Eficiente de Ajuste Fino: Oferecemos métodos eficientes para ajuste fino, como LoRA e Q-LoRA, que ajudam a reduzir o uso de recursos e permitem que você alcance seus objetivos com custos mais baixos.
Implantações Escaláveis com Suporte Assíncrono: Implante LLMs em escala com suporte assíncrono para utilizar suas cotas de GPU nas três nuvens e obter de forma confiável as GPUs de que você precisa para ajuste fino e implantação. Essa confiabilidade adicional permite que você use instâncias spot, economizando dinheiro.
Benchmarking Realizamos um benchmarking de custos para comparar as despesas de implantação de LLMs no AWS EKS versus SageMaker. Você pode ler mais no blog abaixo.
Várias empresas da Fortune 100 e empresas de médio porte economizaram significativamente ao usar nossa plataforma. Algumas até substituíram suas plataformas internas SageMaker ou de nuvem pelo nosso sistema, economizando 30-40%.
Também fizemos o benchmarking do desempenho de muitos LLMs de código aberto comuns nesta série de artigos, sob a perspectiva de latência, custo e requisições por segundo. Você pode conferi-los em Blogs da TrueFoundry
Você também pode assistir a este vídeo para ter uma demonstração ao vivo de todos os recursos que abordamos neste blog:
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, permitindo-lhes total flexibilidade no teste e implantação de modelos, ao mesmo tempo em que garante total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos – permitindo-lhes economizar custos e lançar modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.

















































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




