




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
A proliferação de Grandes Modelos de Linguagem (LLMs) e sistemas agentivos marca um momento crucial para a tecnologia empresarial. O potencial de inovação é vasto — mas também os riscos são grandes. Em muitas organizações, a adoção inicial tem sido caótica: fragmentada, não gerenciada e insegura. Equipes individuais criam suas próprias conexões com vários provedores de modelos, resultando em experimentos isolados sem supervisão central, controle de custos ou padrões de segurança.
Para evoluir desta experimentação ad-hoc para uma estratégia de IA coesa e para toda a empresa, precisamos de um paradigma arquitetônico deliberado — um que incorpore segurança, governança e escalabilidade desde o primeiro dia.
Um stack ideal de aplicações agentivas no ambiente atual deve oferecer:
Desenvolvimento rápido de aplicações — a execução federada de baixa latência em agentes e ambientes heterogêneos reduz o tempo de obtenção de valor (TTV), permitindo que as equipes entreguem capacidades prontas para produção rapidamente sem centralizar todos os dados ou o processamento.
Flexibilidade à prova de futuro — um stack modular e interoperável que pode se adaptar a modelos, protocolos e padrões de agentes emergentes à medida que o cenário da IA evolui.
Segurança e conformidade por padrão — Mascaramento de PII, aplicação de políticas e auditabilidade completa.
Operações determinísticas em sistemas não determinísticos — guard-rails, estruturas de avaliação e caminhos de reversão quando as saídas se desviam.
Governança de custos na granularidade de token — orçamentos, showback/chargeback e limites de uso.
Confiabilidade e portabilidade — failover multimodelos, implantação híbrida/on-premise e zero aprisionamento tecnológico via interfaces agnósticas de provedor, artefatos exportáveis e planos de migração com replay para alternância.
Observabilidade profunda — rastreamentos, métricas ao nível do token (TTFT, TPS), taxas de acerto de cache e tendências de uso.
Capacidades componíveis — modelos, ferramentas e agentes conectados através de prompts, não por código de cola frágil.
Velocidade com controle — CI/CD para modelos, agentes e ferramentas; implementações faseadas com testes canary ou A/B.
E devemos projetar tendo em mente as restrições do mundo real, tais como:
É aqui que a arquitetura faz a diferença entre uma demonstração inspiradora e um sistema de nível de produção. O projeto deve ser composto por quatro camadas críticas: Modelos, Servidores MCP, Agentes e Prompts.
1. Modelos — Alimentando a Inteligência Central
No coração de qualquer aplicação de Gen-AI está o próprio modelo — o motor de raciocínio do seu sistema. O desafio não é simplesmente escolher o “melhor” modelo; é projetar para um mundo onde os modelos são numerosos, estão em constante evolução e são adequados para diferentes propósitos.
Uma arquitetura sólida trata os modelos como ativos de software comuns: são versionados, rastreados quanto a alterações de dados e código, e movidos através de desenvolvimento, staging e produção. O roteamento também deve considerar o custo e o desempenho — por vezes, um modelo menor e mais barato é a melhor escolha para uma tarefa específica do que executar tudo num modelo grande e caro.
A armadilha em que muitos caem é a proliferação de modelos: demasiados modelos não rastreados, atualizações opacas e nenhuma rota de reversão quando o desempenho regride. A arquitetura aqui significa disciplina — tratar os modelos com o mesmo rigor que o código da aplicação principal.
2. Servidores MCP — Padronizando Capacidades
Se os modelos são o cérebro, os servidores MCP (Model Context Protocol) são o cinto de ferramentas. Eles fornecem aos seus agentes acesso padronizado e de nível empresarial a sistemas como Jira, GitHub, Postgres ou APIs proprietárias.
Em vez de integrações personalizadas por equipe — cada uma com suas peculiaridades, lacunas de segurança e lógica duplicada — um único servidor MCP certificado por sistema pode ser reutilizado em toda a empresa. I/O tipado, autenticação e cotas tornam-se consistentes, previsíveis e seguras.
Quando as equipes pulam esta etapa, o caos se instala: políticas de segurança inconsistentes, trabalho redundante e integrações frágeis que não podem ser compartilhadas ou mantidas. Os servidores MCP tornam as capacidades componíveis, não acidentais.
3. Agentes — A Força de Trabalho Digital
Os agentes são onde os modelos se tornam operacionais. Não são apenas pipelines — são as contrapartes digitais dos funcionários humanos, capazes de realizar ações, coordenar tarefas e usar ferramentas.
Um bom design de agente significa dar a cada um uma identidade, permissões baseadas no princípio do menor privilégio e um ciclo de vida claro do sandbox à produção. Eles devem ser orquestrados, capazes de colaboração multiagente e portáteis entre ambientes.
O maior risco operacional aqui é o acesso descontrolado: credenciais embutidas nas camadas da interface do usuário, ferramentas acessíveis sem limites e nenhuma propriedade ou SLAs. Agentes bem projetados carregam suas credenciais e escopos consigo — não vinculados ao local onde são invocados.
4. Prompts — A Interface Operacional
Prompts são como dizemos aos modelos e agentes o que fazer. Não são apenas texto simples, podem ser modelos estruturados, incluir etapas de avaliação e ter verificações de política integradas.
Em uma configuração robusta, os prompts são tratados como código: eles têm controle de versão, são testados e protegidos contra injeção de prompt ou alterações não intencionais. Usar cache semântico pode economizar tempo e custo, reutilizando respostas para consultas semelhantes em vez de executar todo o processo novamente.
Se você não gerenciar os prompts adequadamente, corre o risco de problemas de segurança, vazar dados sensíveis ou ter seus prompts mudando lentamente ao longo do tempo de maneiras não planejadas. Gerenciá-los bem garante um comportamento consistente, seguro e confiável.
Quando as camadas principais — Modelos, Servidores MCP, Agentes e Prompts — são construídas e gerenciadas cuidadosamente, o sistema se torna mais confiável, escalável e fácil de manter. Mas em grandes organizações, os problemas geralmente surgem na forma como todas essas partes são coordenadas, não apenas nas próprias partes.
Os registros centralizados são o tecido conjuntivo da pilha de Gen-AI: o memória institucional que mantém todos os componentes detectáveis, compatíveis e interoperáveis. Sem eles, você corre o risco de voltar ao mesmo caos que esta arquitetura deveria evitar — trabalho duplicado, falhas de segurança e desvios invisíveis dos padrões.
Uma camada de registro robusta oferece:
Na prática, esta camada abrange vários registros especializados:
O sistema de registro para seus modelos — rastreando versões, linhagem (dados, código, métricas), status de implantação (desenvolvimento/shadow/produção) e quem pode promover ou usar um modelo. Ele está conectado a pipelines de CI/CD para que novas versões sejam registradas automaticamente e possam ser implementadas com segurança via testes canary ou A/B. Além da detectabilidade, ele impõe disciplina: sem “modelos misteriosos” em produção, sem alterações não rastreadas.
O catálogo de ferramentas certificadas disponíveis para agentes, documentando suas funções, argumentos e esquemas. Também codifica permissões de uso—nem todo agente deve ter acesso aos seus sistemas financeiros ou bancos de dados sensíveis. Construído uma vez, um servidor MCP pode ser reutilizado entre equipes, com o gateway aplicando controle de acesso baseado em função no nível da ferramenta.
Um diretório da sua força de trabalho digital—rastreando a identidade (UUID), proprietário, propósito, habilidades, modelos/ferramentas permitidos e credenciais de cada agente. Ele registra o ciclo de vida completo, da criação à desativação, e garante que o acesso de menor privilégio seja aplicado em tempo real no gateway. Isso evita o modo de falha comum de agentes que retêm privilégios excessivos ou desatualizados.
Um repositório versionado de políticas de segurança de entrada/saída—abrangendo mascaramento de PII, detecção de injeção de prompt, limites de tópico, filtros de toxicidade, e verificação de fatos regras. As políticas são gerenciadas como código, o que significa que podem ser implementadas incrementalmente via canários ou testes A/B. Políticas agrupadas (por exemplo, “Chatbot Compatível com HIPAA”) podem ser aplicadas consistentemente em modelos, agentes e ferramentas.
Registros nos fornecem a estrutura de memória e governança. Mas a governança no papel não significa nada se não for aplicada em runtime—onde prompts são enviados, tokens são consumidos e respostas são entregues.
Mesmo com os componentes certos e registros bem governados, um sistema de IA moderno não funciona no vácuo. Em produção, o verdadeiro teste não é se sua arquitetura parece boa no papel — é se ela continua a entregar resultados sob condições de falha, demanda variável e custos imprevisíveis.
É aqui que entram as “nuances operacionais”. Elas não são componentes autônomos, mas sim padrões transversais que adicionam durabilidade, eficiência e capacidade de resposta a todo o stack.
Padrões de Alta Disponibilidade
Em um sistema de IA em produção, a falha não é uma possibilidade — é uma certeza. Modelos cairão, endpoints mudarão e redes se comportarão mal. O trabalho de um arquiteto é garantir que esses eventos não se traduzam em interrupções para o usuário.
Aprisionamento é evitado pela prática, não pela promessa. Trate a saída como uma disciplina em tempo de execução, não como um projeto de última milha.
Gateway agnóstico de provedor — normalize esquemas de requisição/resposta e tags de capacidade para que os aplicativos nunca se vinculem a um SDK de fornecedor.
Replay para troca — espelhar rotineiramente uma fatia representativa de rastreamentos de produção para um provedor alternativo ou modelo auto-hospedado; monitorar as diferenças de latência, custo e qualidade para manter a rota de fuga operacional.
Artefatos abertos — armazenar prompts, rastreamentos, avaliações, embeddings e conjuntos de dados de fine-tuning em formatos exportáveis; manter os índices vetoriais reconstruíveis a partir da fonte.
Matriz de compatibilidade — manter um scorecard de fornecedor/modelo (latência/custo/qualidade/recursos) para que as políticas de roteamento permaneçam orientadas por dados.
Direitos contratuais e de dados — preferir termos que permitam a substituição de pesos e o retreinamento; rastrear a linhagem do conjunto de dados no Registro de Modelos para que a saída não seja impedida pela proveniência.
Lista de verificação de saída — chaves/configuração desacopladas do código, endpoints secundários pré-aprovados, conjunto de dados de replay mínimo definido, lacunas conhecidas documentadas.
As cargas de trabalho de IA têm custos inerentemente variáveis e, sem uma gestão ativa, os custos podem disparar. O desafio é impor disciplina de custos sem introduzir gargalos que frustrem desenvolvedores ou usuários.
Essas nuances garantem que o sistema continue funcionando sem problemas quando algo dá errado. Elas também ajudam a manter os custos sob controle. Combinar as nuances de fallback, redundância e custo exige um plano de controle unificado; é isso que o AI Gateway faz: ele reúne todas essas partes em um componente único e central da arquitetura GenAI moderna.
AI Gateways governam modelos, agentes, ferramentas, prompts e tokens. É um especializado plano de controle de middleware para tráfego de IA — proxy de saída/reverso que entende tokens, semântica e ferramentas.
O Que Faz
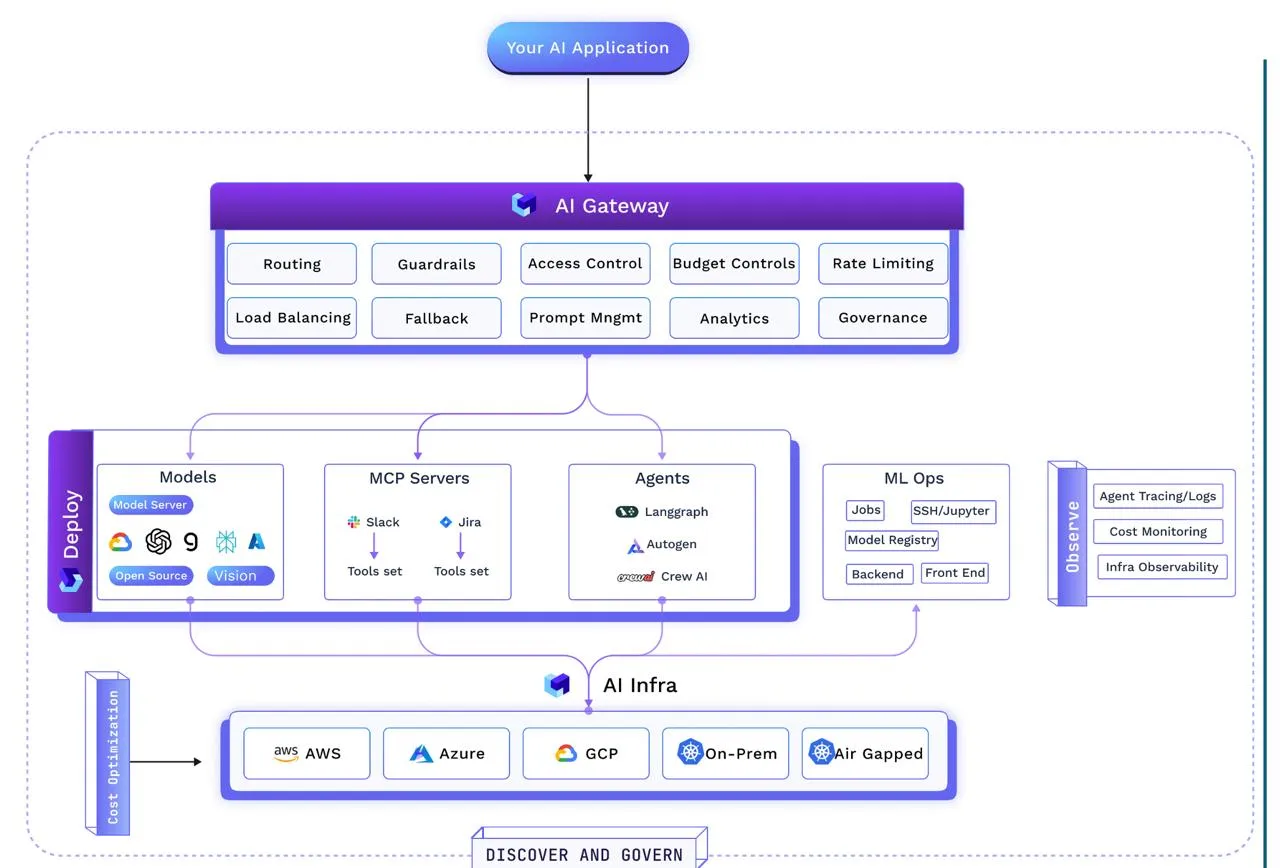
Uma vez que o plano diretor é definido, os registros estão estabelecidos, as salvaguardas operacionais estão incorporadas e o AI Gateway as está aplicando em tempo real, a questão que surge é: como realmente executamos isso?
É aqui que a conversa muda da arquitetura e governança para a execução — a camada de implantação que pode levar código e modelos para produção rapidamente, mantê-los confiáveis, e executá-los de forma econômica—tudo isso sem comprometer a disciplina operacional.
Aqui, velocidade não significa comprometer a qualidade. Um pipeline moderno passa do commit para o cluster em minutos: testes automatizados validam as mudanças, contêineres empacotam modelos, agentes e servidores MCP em imagens imutáveis, e manifestos os implementam em desenvolvimento, staging ou produção com estratégias configuráveis. Atualizações de registro garantem que o Gateway possa descobrir e governar novas versões imediatamente. Aplicações inteiras — modelo, backend, frontend e ferramentas — podem ser implementadas como pilhas pré-configuradas, ou até mesmo iniciadas por agentes de implantação conversacionais.
A confiabilidade é incorporada através de melhores práticas de SRE: autoescalonamento e failover instantâneos, monitoramento proativo, rollback/versionamento sob demanda, logs de auditoria imutáveis e desligamento automático de ambientes ou IDEs ociosos.
As políticas aqui também impõem regras operacionais como “nenhuma implantação em produção sem pelo menos duas réplicas” ou “cargas de trabalho de GPU devem desligar automaticamente quando ociosas.”
A eficiência de custos também é algo a ser considerado: a camada utiliza de forma transparente instâncias spot com fallback sob demanda para economia de custos, escala cargas de trabalho com HPA/VPA e autoescalonamento de cluster, e aproveita o escalonamento orientado a eventos (por exemplo, KEDA) para colocar trabalhadores online instantaneamente quando necessário e de volta a zero quando ociosos. Um recurso estilo AutoPilot aplicaria mudanças de escalonamento ou posicionamento em tempo real, equilibrando a economia de custos com a proteção de SLA.
O pipeline de implantação padrão para uma pilha de IA agêntica é o seguinte:
Artefatos são imagens OCI e manifestos são IaC puro; endpoints e regiões são parametrizados. Isso mantém as cargas de trabalho agnósticas à nuvem e permite uma realocação rápida e orientada por políticas sem tocar no código da aplicação.
Com o sistema em funcionamento — modelos implantados no Kubernetes, agentes registrados e o Gateway aplicando regras em tempo de execução — a arquitetura está operacional. Mas mantê-lo seguro, eficiente e alinhado com as prioridades organizacionais não é um exercício pontual. As cargas de trabalho se moverão entre ambientes, aumentarão e diminuirão de escala e evoluirão com novas ferramentas e modelos.
Se a governança não acompanhar esse movimento, você acaba com comportamentos ocultos: agentes rodando sem salvaguardas, cargas de trabalho implantadas sem redundância ou GPUs ociosas gerando custos. A resposta é simples em princípio, mas poderosa na prática—políticas que acompanham a carga de trabalho.
Além disso, as salvaguardas não podem ser scripts ad-hoc enterrados no código de uma única equipe. Elas devem ser política-como-código—versionadas, revisadas e implantadas como qualquer outro artefato central:
As políticas não se limitam à segurança da IA. Elas podem codificar padrões operacionais de toda a organização:
Estas regras garantem que seus sistemas atendam a padrões básicos de confiabilidade e eficiência por padrão, sem depender de verificações manuais ou da memória da equipe.
Em muitas indústrias regulamentadas ou de alta segurança, executar grandes modelos proprietários em produção torna-se um desafio. O ajuste fino de um modelo menor auto-hospedado contorna essa barreira, preservando a qualidade. E como o Gateway já está no fluxo de tráfego, ele pode gerenciar a migração — comparando o novo modelo com o antigo, realizando testes A/B de saídas e roteando o tráfego de acordo quando o desempenho convergir. O uso de LLMs de código aberto ajustados para casos de uso de IA Generativa em escala também é econômico para as empresas.
O Gateway não se trata apenas de aplicação — é também um motor de evolução de modelos. Ao registrar interações de alta qualidade de um modelo grande e caro como o GPT-4o, ele constrói um conjunto de dados para ajuste fino para um modelo menor e eficiente como o LLaMA.
Esta abordagem permite que você:
Do ponto de vista do arquiteto, isso transforma o Gateway de IA em mais do que uma camada de aplicação — ele se torna um motor de evolução de modelos, transformando silenciosamente dados de tempo de execução na base da sua IA de próxima geração, otimizada em custos e pronta para produção.
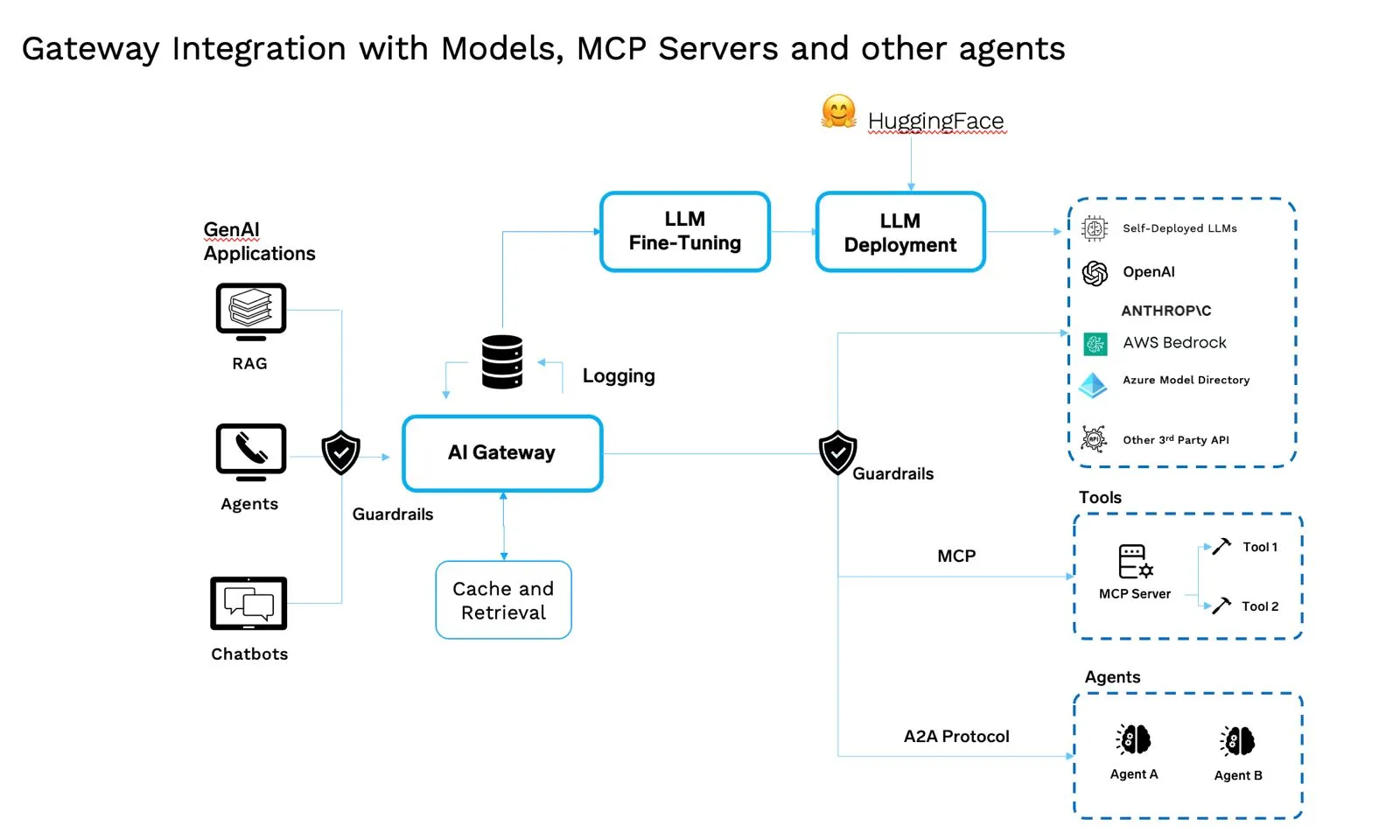
Quando você olha para a pilha como um todo, o valor não está nas peças individuais, mas em como elas trabalham juntas. Os modelos precisam ser rastreados e versionados. Servidores MCP os expõem de forma consistente. Agentes trazem raciocínio e tomada de decisão. Prompts lhes dão instruções claras. Registros garantem que você saiba o que está sendo executado e onde. Políticas operacionais mantêm as coisas seguras e econômicas. Kubernetes oferece a escala e a confiabilidade para executar tudo isso.
O Gateway de IA fica no topo para coordenar esses componentes, mas a verdadeira força vem da integração — cada camada é conectada, gerenciada e observável. É isso que transforma um conjunto de ferramentas em um sistema em que as empresas podem realmente confiar e sobre o qual podem construir.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




