



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
O Amazon SageMaker tornou-se efetivamente o sistema operacional padrão para aprendizado de máquina dentro do perímetro da AWS. Lançado em 2017, prometeu industrializar o que era então um ecossistema fragmentado de scripts personalizados e provisionamento manual de servidores. Ao abstrair a configuração subjacente do EC2 e a orquestração de contêineres, permitiu que as organizações padronizassem seus pipelines de ML.
Mas aqui estamos em 2026, e a proposta de valor de um serviço gerenciado de código fechado e nuvem única está sob escrutínio. As reclamações que ouvimos das equipes de engenharia são consistentes: modelos de precificação opacos que levam a surpresas desagradáveis no final do mês, curvas de aprendizado íngremes para quem não é nativo da AWS, e uma arquitetura de "jardim murado" que penaliza estratégias multi-nuvem.
Esta análise técnica vê o SageMaker não como um folheto de marketing, mas como uma peça de infraestrutura. Examinamos a economia unitária, o atrito operacional e as compensações arquitetônicas com base em dados do G2, Gartner Peer Insights e experiência operacional direta. Também avaliaremos se planos de controle desacoplados como TrueFoundry oferecem um caminho viável para evitar o aprisionamento tecnológico (vendor lock-in).
Em sua essência, o Amazon SageMaker é um serviço gerenciado que envolve computação AWS (EC2), armazenamento (S3/EBS) e orquestração de contêineres (EKS/ECS). Ele fornece um ambiente de desenvolvimento integrado (IDE) de ponta a ponta e um plano de controle para o ciclo de vida de ML.
Atualizações recentes, como o "Unified Studio" e a integração com Data Lakehouses, tentam preencher a lacuna entre engenharia de dados e operações de ML. No entanto, para o engenheiro de plataforma, o SageMaker é essencialmente um conjunto de APIs proprietárias usadas para provisionar computação efêmera para treinamento e computação persistente para inferência.
Público-alvo:
Escopo Operacional:
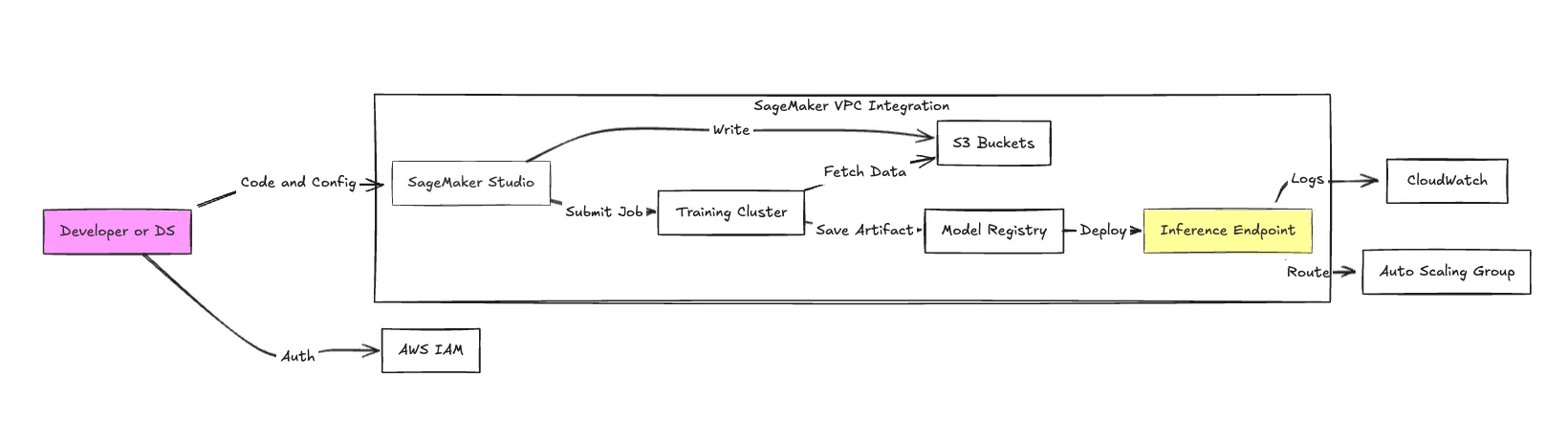
O SageMaker é um monolito. Embora ofereça dezenas de sub-serviços, os seguintes componentes constituem o núcleo da pilha operacional.
O Studio é uma IDE baseada na web, construída sobre o JupyterLab. Embora centralize o acesso, ele introduz latência. Iniciar um aplicativo "KernelGateway" pode levar vários minutos. Ele cria uma camada de abstração sobre a instância EC2 subjacente, o que simplifica o acesso, mas complica a utilização de recursos do sistema local para depuração.
O SageMaker permite o treinamento distribuído em clusters. SageMaker HyperPod é o recurso notável aqui, projetado para ser resiliente a falhas de hardware durante tarefas de treinamento de LLM de longa duração. Ele detecta e substitui automaticamente instâncias com falha — crítico ao alugar clusters de GPU caros, onde uma única falha de nó pode desperdiçar dias de tempo de computação.
O SageMaker oferece Inferência em Tempo Real, Inferência Serverless e Inferência Assíncrona.
Uma solução AutoML que itera sobre algoritmos para encontrar o melhor modelo. Embora útil para prototipagem rápida em dados tabulares, engenheiros experientes frequentemente acham o código gerado difícil de refatorar ou otimizar para restrições de inferência em produção.
Esta é a camada de "cola". O SageMaker Pipelines é um serviço de CI/CD especificamente para ML. Ele se integra fortemente com o Model Registry (versionamento) e o Model Monitor (detecção de desvio). A desvantagem é o forte acoplamento ao fornecedor; migrar um SageMaker Pipeline para Airflow ou Argo Workflows geralmente exige uma reescrita completa.
O Data Wrangler oferece uma interface de usuário para limpeza de dados, gerando código Python. O Feature Store atua como um repositório centralizado para features. Observe que o Feature Store é suportado por Glue e DynamoDB, o que significa que leituras de alto throughput podem incorrer em custos secundários significativos no lado do banco de dados.
A precificação é o ponto de atrito mais comum. O SageMaker opera em um modelo baseado em consumo com uma margem sobre os preços brutos do EC2. Não há taxas iniciais, mas a previsibilidade de custos é baixa devido ao grande número de vetores faturáveis.
Você é cobrado por:
1. Instâncias de Notebook:
Uma instância de notebook ml.t3. medium padrão custa aproximadamente **$0.05/hora**. No entanto, os desenvolvedores frequentemente as deixam em execução durante a noite. Uma equipe de 10 desenvolvedores que deixa as instâncias ligadas por um mês resulta em aproximadamente $360 de "desperdício", excluindo os custos de armazenamento.
2. Endpoints de Inferência (O Assassino Silencioso do Orçamento):
A inferência é onde os custos disparam. Ao contrário do treinamento (que termina), os endpoints funcionam 24 horas por dia, 7 dias por semana.
3. Treinamento e Instâncias Spot:
O Treinamento Spot Gerenciado pode oferecer até 90% de desconto em comparação com as taxas On-Demand. No entanto, as instâncias Spot podem ser preemptadas (interrompidas) pela AWS a qualquer momento. Se a sua lógica de checkpointing de treinamento não for robusta, você perde o progresso.
Cenário Real:
Uma startup de médio porte que treina um LLM personalizado e hospeda 5 modelos em produção pode facilmente ter contas que excedem US$ 25.000/mês. De acordo com Preços da AWS, os custos de processamento de dados para recursos como o Data Wrangler começam em US$ 0,14/hora-nó, o que escala linearmente com o volume de dados.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Analisamos o feedback de G2, Gartner Peer Insights e fóruns de desenvolvedores para identificar o consenso.
Os usuários apreciam a natureza de "conformidade pronta para uso" da plataforma.
O sentimento negativo concentra-se na experiência do desenvolvedor (DX) e na opacidade da cobrança.
Nota sobre "SageMaker Gateway": Frequentemente há confusão em relação a este termo. Refere-se à integração do Amazon API Gateway com endpoints do SageMaker para expor modelos como APIs REST públicas. Embora poderoso, introduz uma camada adicional de latência e custo (o API Gateway cobra por milhão de requisições) que os desenvolvedores devem gerenciar.
A decisão se resume à filosofia arquitetônica da sua organização e à elasticidade do seu orçamento.
Quando o SageMaker faz sentido:
Quando considerar alternativas:
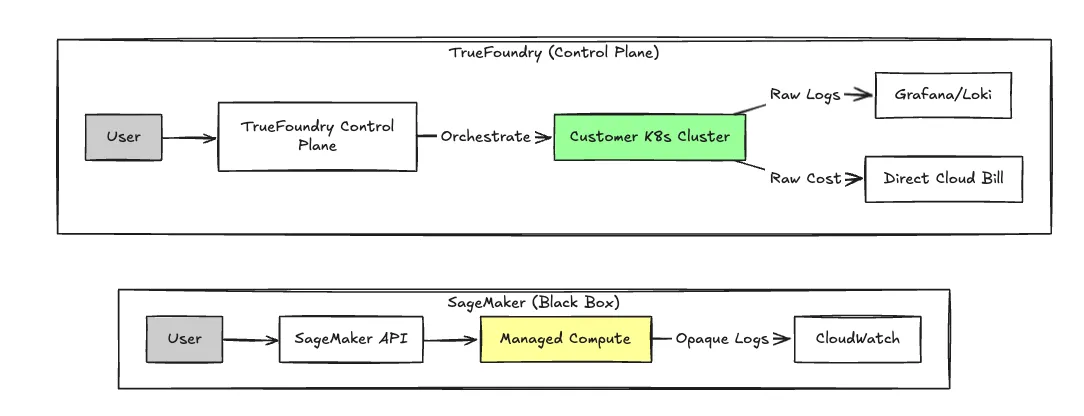
Para equipas que consideram o SageMaker demasiado rígido ou caro, TrueFoundry opera com uma arquitetura fundamentalmente diferente. É um Plano de Controlo que se sobrepõe à sua própria conta de nuvem (AWS, GCP, Azure), em vez de um serviço gerido de caixa preta.
Esta abordagem "Traga a Sua Própria Nuvem" (BYOC) permite que o TrueFoundry orquestre a computação dentro da sua VPC. Obtém a experiência de desenvolvedor de uma plataforma gerida como o Heroku, mas a economia unitária subjacente de instâncias EC2/GKE/AKS puras.
A diferença crucial é onde a computação acontece. No SageMaker, aluga as capacidades de computação da plataforma. No TrueFoundry, a plataforma orquestra as suas funções de computação.
A Whatfix, que atende a mais de 80 empresas da Fortune 500, precisava modernizar o seu ciclo de vida de lançamento em diversos ambientes de nuvem e no local. Ao adotar o TrueFoundry para gerir os seus microsserviços baseados em Kubernetes, eliminaram o atrito das implantações monolíticas. Esta transição reduziu o tempo de implantação no local de três meses para apenas duas semanas.
A Whatfix alcançou um ciclo de lançamento 6x mais curto, permitindo que uma pequena equipa de DevOps apoiasse mais de 150 desenvolvedores com um painel único de controlo para gestão de múltiplos clusters.
Leia a história completa: Estudo de Caso da Whatfix: Migração Kubernetes e Implantação On-premise
O Amazon SageMaker é um conjunto de ferramentas robusto e de nível empresarial. Se sua organização está legal ou tecnicamente vinculada à AWS e você tem uma equipe DevOps dedicada para gerenciar as complexidades de faturamento e configuração, é uma escolha segura e padrão.
No entanto, para equipes que desenvolvem aplicações GenAI modernas, onde a escassez de GPUs e a economia unitária são riscos existenciais, o "imposto AWS" é difícil de justificar.
A TrueFoundry oferece a evolução lógica: a usabilidade de um serviço gerenciado com a liberdade econômica e arquitetônica de possuir sua infraestrutura. Se você precisa implantar LLMs na AWS e GCP para encontrar as GPUs mais baratas, ou se simplesmente deseja um painel que fala a linguagem dos desenvolvedores em vez dos contadores, a TrueFoundry é a escolha arquitetônica superior.
Agende uma Demonstração com a TrueFoundry para ver como você pode reduzir seus custos de inferência em 40% enquanto recupera o controle da sua infraestrutura.
A TrueFoundry é a alternativa ideal ao AWS SageMaker porque oferece controle total da infraestrutura sem a precificação "caixa preta". Ao contrário de um serviço totalmente gerenciado típico, ela capacita os Cientistas de Dados a hospedar Modelos de Machine Learning usando PyTorch ou TensorFlow com esforço mínimo. O TrueFoundry AI Gateway elimina o trabalho pesado de orquestração ao mesmo tempo que oferece a escalabilidade necessária para a IA Generativa.
O SageMaker é tecnicamente maduro e confiável para ML tradicional. Ele se destaca em segurança e conformidade, mas tem uma classificação baixa em usabilidade, experiência de depuração e transparência de custos em comparação com plataformas MLOps modernas.
Depende dos dados. O Databricks (Unified Data Analytics Platform) é superior para cargas de trabalho intensivas em Spark e ML orientado por engenharia de dados. O SageMaker é geralmente preferido para tarefas de deep learning puro e inferência onde os dados já estão preparados no S3.
Sim, ele tem a maior participação de mercado entre os serviços de ML em nuvem pública simplesmente devido ao domínio da AWS. No entanto, a participação de mercado está mudando à medida que o "agnóstico de nuvem" se torna uma prioridade para as pilhas GenAI.
Não. A OpenAI fornece modelos como serviço (API). O SageMaker fornece a infraestrutura para treinar e hospedar seus próprios modelos (incluindo alternativas de código aberto à OpenAI, como Llama 3 ou Mistral).
Eles são funcionalmente semelhantes. O Azure ML é geralmente considerado por ter uma UI mais intuitiva e melhor integração com o VS Code, enquanto o SageMaker oferece um controle mais granular sobre a infraestrutura de baixo nível para usuários avançados.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




