



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Nas empresas impulsionadas por IA de hoje, medidas robustas de segurança de IA e conformidade de LLMs são cruciais. À medida que as empresas integram poderosos modelos de linguagem grandes (LLMs) em seus fluxos de trabalho, elas precisam de mecanismos para manter esses modelos “no caminho certo” com as regras organizacionais. Os guardrails de IA desempenham esse papel – análogos a barreiras de proteção rodoviárias – garantindo que cada interação de IA reflita os padrões, políticas e valores da empresa. Os guardrails funcionam verificando ou transformando automaticamente os prompts e respostas dos LLMs para aplicar políticas de segurança, privacidade e conteúdo. O AI Gateway da TrueFoundry incorpora esses guardrails no centro do pipeline de IA, validando solicitações e respostas para garantir segurança, qualidade e conformidade. Este artigo oferece uma visão técnica dos guardrails de IA no contexto de um AI Gateway. Definimos o que são guardrails, explicamos como funcionam, destacamos seus componentes essenciais e descrevemos como as organizações podem implementá-los.
Guardrails de IA são controles e filtros baseados em regras colocados em torno de sistemas de IA generativa para aplicar políticas empresariais. Os guardrails ajudam a garantir que uma ferramenta de IA “funcione em alinhamento com os padrões, políticas e valores organizacionais”. Na prática, isso significa que os guardrails podem mascarar ou remover dados sensíveis (para privacidade de dados), bloquear tópicos não permitidos (para conformidade de conteúdo) ou validar formatos de saída (para garantia de qualidade).
Em um AI Gateway (como o da TrueFoundry), os guardrails são aplicados em dois pontos: antes que uma solicitação seja enviada a um LLM (guardrails de entrada) e depois que uma resposta é retornada (barreiras de proteção de saída). Ao intercetar ambas as extremidades da interação do LLM, as barreiras de proteção garantem que cada prompt e resposta adere às regras da empresa.
Exemplos de Barreiras de Proteção de IA em ação:
Em suma, os guardrails de IA são a aplicação técnica das políticas de governança de IA, garantindo que “cada solicitação e resposta atenda aos padrões da organização para segurança, qualidade e conformidade”.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Da TrueFoundry AI Gateway aplica guardrails tanto na entrada quanto na saída de cada chamada de LLM. Os guardrails de entrada são executados antes um prompt chega ao modelo, realizando tarefas como mascarar dados pessoais ou filtrar conteúdo proibido. Os guardrails de saída são executados depois o modelo responde, verificando conteúdo inseguro ou não permitido (e opcionalmente corrigindo-o).
Cada regra de guardrail pode operar em dois modos: validar (bloquear) ou mutar (modificar). No modo de validação, qualquer violação detetada faz com que a solicitação ou resposta seja bloqueada com um erro, aplicando estritamente a conformidade. No modo de mutação, o guardrail altera automaticamente o conteúdo para remover ou transformar o problema (por exemplo, redigir um número de telefone ou substituir uma palavra proibida). Esta abordagem de duas fases (entrada/saída) e dois modos (validar/mutar) garante que nenhum dado sensível ou não conforme passe pelo sistema.
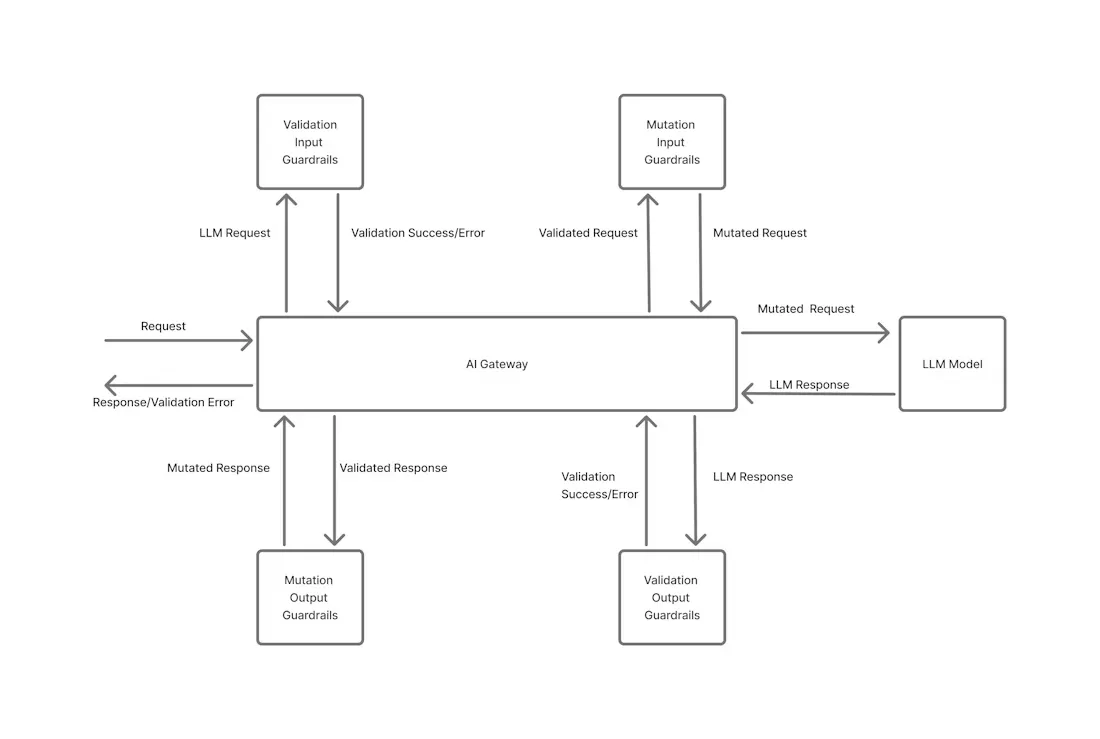
O diagrama acima ilustra como cada mensagem passa pelos filtros de entrada antes de chegar ao modelo e pelos filtros de saída após a resposta, fornecendo uma rede de segurança em ambos os lados da interação de IA.
Da TrueFoundry AI Gateway fornece uma camada de controle unificada onde as empresas podem definir, integrar e gerenciar barreiras de proteção em todas as interações com LLMs—sem modificar a lógica da aplicação. As barreiras de proteção podem ser configuradas de forma declarativa via YAML, APIs ou o Console TrueFoundry, permitindo que as equipes apliquem políticas consistentes em vários provedores de IA (como OpenAI, Anthropic ou Azure OpenAI).
De forma geral, as barreiras de proteção são integradas na camada de Gateway, interceptando o tráfego entre as aplicações e os LLMs subjacentes.
Esta arquitetura garante segurança e conformidade da IA enquanto mantém baixa latência através da execução paralelizada e do cache dos resultados dos guardrails.
Desenvolvedores e equipes de plataforma podem configurar guardrails em vários escopos:
Guardrails Globais: Políticas de toda a organização que se aplicam a todos os modelos e endpoints (por exemplo, redação de PII ou tópicos não permitidos).
Guardrails em Nível de Modelo: Configurações específicas por provedor de LLM (por exemplo, usando detecção de PII do Azure com GPT-4, mas Moderação OpenAI para Claude).
Guardrails em Nível de Rota: Controle granular nas rotas de API — permitindo que diferentes endpoints apliquem diferentes regras de validação ou conformidade.
Um exemplo de configuração simples pode ser assim:

With TrueFoundry’s AI Gateway, organizations can integrate guardrails as a native part of their AI infrastructure, ensuring robust AI safety, data protection, and regulatory alignment—all while maintaining high performance and flexibility.
Without guardrails, enterprise LLM deployments face serious risks. Generative AI models can produce unpredictable or unsafe outputs that expose organizations to legal, reputational, and operational harm. For example, an unfiltered AI chatbot might inadvertently reveal personal user information or use profanity or biased language, eroding customer trust and potentially violating regulations like GDPR or HIPAA. In sensitive domains (e.g. healthcare or finance), even a single hallucinated answer could have disastrous consequences. Lack of real-time checks also means issues are detected only after deployment – for instance, by unhappy users or audit reviews – which is far costlier than catching them early.
In practice, the absence of guardrails leads to security breaches (data leaks), compliance violations (illegal advice or misinformation), brand damage (offensive or inconsistent responses), and unpredictable application behavior. In short, without guardrails to enforce AI safety and compliance, enterprises run the risk of costly mistakes and loss of control over their AI systems.
Effective AI guardrails combine several technical elements to cover different risk areas. A robust system typically includes:
(1) Rule Engine – an ordered set of policy rules that match on user, model, or context, ensuring only the first applicable rule fires
(2) PII & Data Filters – built-in or external detectors that recognize and redact personal and sensitive information (emails, SSNs, credit cards, etc.) in both inputs and outputs
(3) Content Classifiers – semantic filters that check for disallowed topics (medical advice, hate speech, profanity, etc.) or hallucinations against a taxonomy of risks
(4) Custom Keyword Filters – company-specific word or phrase blocklists that can transform or block particular terms in real-time and,
(5) Transformation Actions – the ability to either reject content (validate) or automatically sanitize it (mutate) based on policy.
In TrueFoundry’s platform, these components are implemented as “guardrail integrations” (for example, linking to OpenAI’s moderation API) which the Gateway invokes as needed. Each time a rule is applied, the system logs the event (what was checked, and how it was handled) for auditing and analysis. Combined, these features create a comprehensive safety framework: inputs are pre-scrubbed before they ever reach the LLM, and outputs are checked before they reach the user. In McKinsey’s terms, an effective guardrail system includes “checkers” to flag issues and “correctors” to fix them – exactly the role played by TrueFoundry’s input/output filters and transformation logic.
It is important to distinguish guardrails from governance. AI governance refers to the high-level frameworks, policies, roles, and oversight procedures that define what is acceptable and why – for example, an enterprise’s data privacy policy or AI ethics guidelines. Governance ensures that AI initiatives have clear accountability and align with legal and ethical standards. Guardrails, by contrast, are the technical enforcement mechanisms that implement those policies in real time on each AI request. In other words, governance sets the rules of the road, and guardrails are the barriers and sensors that keep the AI vehicle from veering off course. Having governance without guardrails means policies exist only on paper; having guardrails without governance means there is no clear guidance on what to enforce. In practice, effective AI risk management uses both: strategic governance defines the goals (e.g. “never reveal PII”, “no medical advice”), and guardrails (in the AI Gateway) automatically enforce those rules on every LLM interaction. As one analyst notes, organizations need both AI governance and technical guardrails working together to safely scale AI.
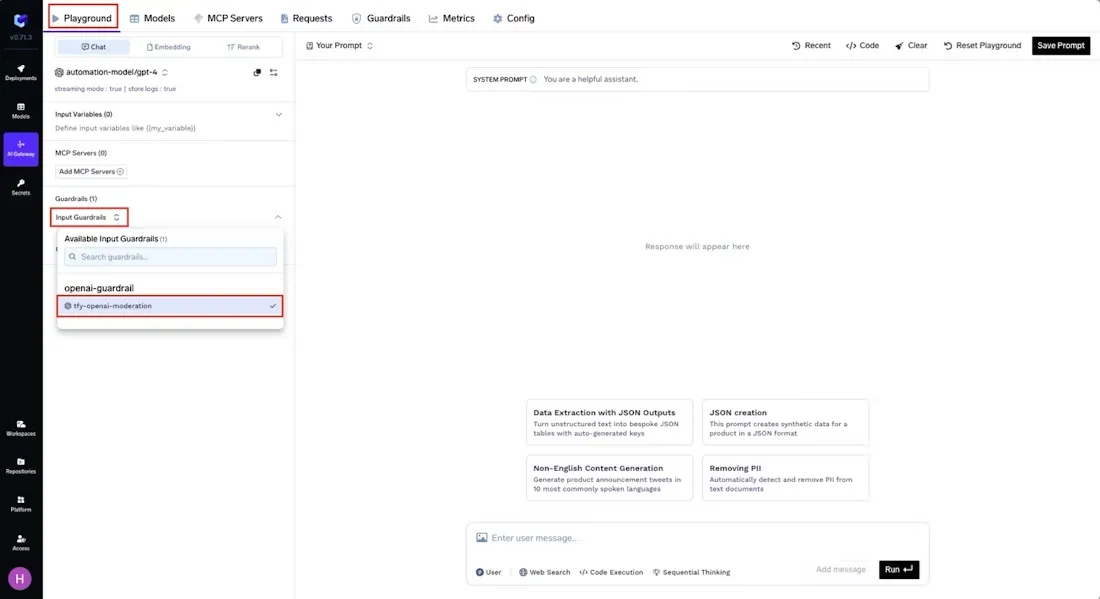
TrueFoundry’s AI Gateway makes it practical to deploy guardrails across an organization. Typically, administrators begin by creating a Guardrails Group in the Gateway UI – a container with defined managers and users – to hold policy integrations. Within that group, they add specific guardrail integrations (for example, OpenAI’s Moderation API for content filtering) by filling in the provider’s configuration form.
Once integrations are defined, teams can immediately test them using TrueFoundry’s Playground. For instance, one can apply an input guardrail and submit an unsafe prompt; the Playground will demonstrate that the guardrail blocks or sanitizes the content as expected.
In production code, developers can enforce guardrails per request by adding the X-TFY-GUARDRAILS header with the chosen rule set. This lets applications dynamically specify which filters to apply on a call-by-call basis.
For enterprise-wide policy, TrueFoundry supports gateway-level guardrail configurations: an administrator creates a YAML config in the AI Gateway’s Config tab specifying rules with when conditions and listing the input_guardrails and output_guardrails to apply. Only the first matching rule is used per request.
Defining guardrails at the gateway level is best for organization-wide enforcement, so that every AI request is automatically checked according to the company’s compliance standards. In this way, the AI Gateway centralizes guardrail management and auditing, eliminating the need to instrument each application separately.
The guardrails landscape is evolving rapidly alongside AI capabilities and regulations. Researchers advocate multi-layer guardrail architectures: for example, a primary input/output “gatekeeper” layer could be complemented by a knowledge-grounding layer that uses retrieval-augmented checks to verify factual accuracy. Organizations are also experimenting with intelligent guardrails – using AI agents to continuously monitor and correct model outputs in real time. On the tooling front, a growing ecosystem of open-source frameworks is emerging. NVIDIA’s NeMo Guardrails toolkit, LangChain’s Guardrails library, and others provide programmable rule engines for LLMs. Cloud providers likewise offer built-in moderation and safety filters for their AI services. Meanwhile, stricter regulations (such as the EU’s proposed AI Act) will drive demand for turnkey guardrail solutions that can demonstrate LLM compliance in real time. Overall, we can expect guardrails to become even more integrated into the AI development lifecycle – incorporating advanced NLP detectors, context-aware policies, and verifiable audit logs – to keep enterprise AI deployments both powerful and safe.
AI guardrails are essential for turning advanced LLMs from unpredictable experiments into reliable, compliant enterprise tools. By sandwiching every AI request between input and output checks, TrueFoundry’s AI Gateway enables organizations to enforce data privacy, content standards, and regulatory requirements automatically. The key is combining flexible, policy-driven filters (for PII masking, topic moderation, etc.) with real-time enforcement (validate or mutate actions) and thorough logging. For CTOs and AI architects, building in guardrails means unlocking generative AI’s potential without sacrificing trust or safety. In the enterprise context, robust guardrails at the gateway level are the backbone of responsible AI – they let businesses innovate confidently with LLMs, knowing that every response has been vetted against their security, quality, and compliance rules.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




